A Detection-Gated Pipeline for Robust Glottal Area Waveform Extraction and Clinical Pathology Assessment
Pith reviewed 2026-05-15 17:44 UTC · model grok-4.3
The pith
A detection-gated pipeline segments glottal areas from high-speed videoendoscopy videos, achieving Dice scores up to 0.856 and distinguishing healthy from pathological function via coefficient of variation in a 40-subject study.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
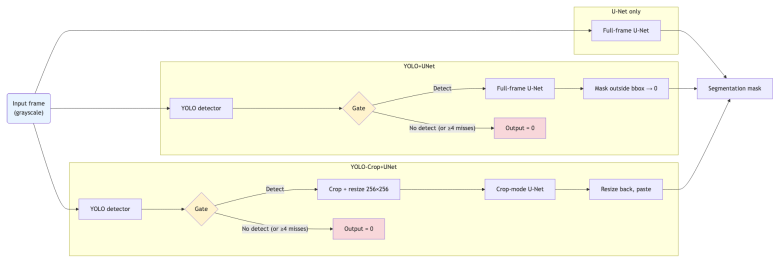
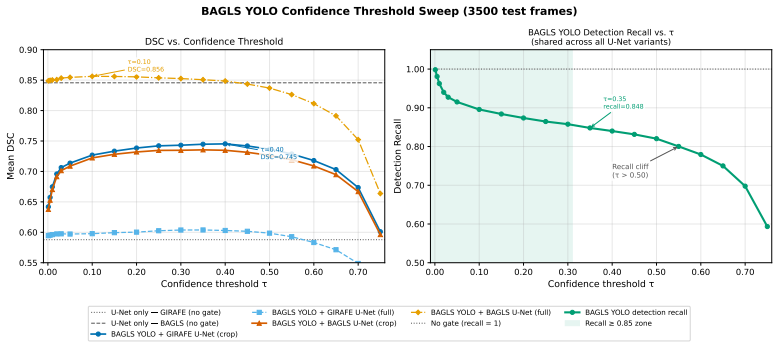
The detection-gated pipeline combines a YOLOv8n glottis localizer with a U-Net segmenter to produce robust glottal area segmentations from high-speed videoendoscopy, achieving Dice similarity coefficients of 0.81 on the GIRAFE dataset, 0.856 on the BAGLS dataset, and 0.745 in cross-dataset testing without fine-tuning, while an exploratory study of 40 subjects shows that the resulting glottal area coefficient of variation distinguishes healthy from pathological function at p=0.006.
What carries the argument
The detection-gated pipeline, in which the YOLOv8n localizer supplies a tight crop and gates the U-Net output to suppress spurious segmentations during glottal closure.
If this is right
- The system produces glottal area waveforms at approximately 35 frames per second on commodity hardware, supporting interactive clinical review.
- Cross-dataset performance reaches 87 percent of the in-domain ceiling without retraining, indicating portability across acquisition settings.
- Glottal area coefficient of variation provides a quantitative distinction between healthy and pathological laryngeal function.
- The modular two-stage design enables uniform extraction of laryngeal kinematic measures from videos recorded under varying conditions.
Where Pith is reading between the lines
- If the coefficient of variation marker proves stable in larger cohorts, it could be embedded directly into clinical review software for rapid screening.
- The gating mechanism may transfer to other medical video segmentation tasks where transient occlusions or closure phases create noise.
- Real-time speed opens the possibility of live feedback during endoscopic procedures rather than only post hoc analysis.
- Extending the pipeline to additional laryngeal measures beyond area could strengthen its role in comprehensive kinematic assessment.
Load-bearing premise
The glottal area coefficient of variation serves as a clinically meaningful marker of pathology, based on an exploratory study of only 40 subjects.
What would settle it
A larger controlled study that finds no statistically significant difference in glottal area coefficient of variation between healthy and pathological groups would undermine the clinical utility claim.
Figures




read the original abstract
We present a fully automated, two-stage modular glottal area segmentation framework for high-speed videoendoscopy (HSV) designed for accuracy, generalizability, and real-time playback. Our detection-gated pipeline combines a YOLOv8n glottis localizer with a U-Net segmenter; the localizer defines a tight crop to ensure a consistent field of view and gates the output to reduce spurious segmentations during glottal closure. The models were trained on the GIRAFE (N=600) and BAGLS (N=55,750) datasets. Cross-dataset portability was evaluated by benchmarking GIRAFE-trained models on the BAGLS test set without fine-tuning. In these evaluations, the pipeline achieved a Dice Similarity Coefficient (DSC) of 0.745 (87% of the in-domain ceiling). On in-distribution test sets, the system achieved DSCs of 0.81 (GIRAFE) and 0.856 (BAGLS), outperforming or competing with state-of-the-art methods. An exploratory clinical study of 40 subjects demonstrated that the glottal area Coefficient of Variation (CV distinguished healthy from pathological function (p=0.006). The system processes ~35 frames per second on commodity hardware, enabling interactive clinical review. This design supports uniform extraction of laryngeal kinematic measures across varying acquisition settings. Code, weights, and software are available at https://github.com/hari-krishnan/openglottal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a two-stage detection-gated pipeline combining YOLOv8n glottis localization with U-Net segmentation for automated glottal area waveform extraction from high-speed videoendoscopy. It reports in-domain DSCs of 0.81 (GIRAFE, N=600) and 0.856 (BAGLS, N=55,750), cross-dataset DSC of 0.745 without fine-tuning, real-time performance of ~35 fps, and an exploratory clinical result on 40 subjects where glottal-area coefficient of variation distinguished healthy from pathological cases (p=0.006). Code, weights, and software are released.
Significance. If the results hold, the work supplies a practical, modular, and portable tool for consistent extraction of laryngeal kinematic measures across acquisition settings, with potential to support clinical review. The open release of code and weights is a clear strength for reproducibility. Cross-dataset generalization is a substantive contribution, though the clinical marker's status as a generalizable pathology indicator rests on limited evidence.
major comments (2)
- [Abstract / Clinical Evaluation] Abstract / Clinical Evaluation section: The headline claim that the pipeline enables clinical pathology assessment rests on the glottal-area CV distinguishing healthy from pathological subjects (p=0.006) in an exploratory n=40 cohort. No information is supplied on age/sex matching, acquisition-parameter stratification, power calculation, or comparison against other kinematic features; this is load-bearing for the title and abstract claim and must be addressed with additional controls or explicit qualification as preliminary.
- [Methods / Results] Methods / Results: Training hyperparameters, the precise cross-validation protocol, and error bars (or confidence intervals) on the DSC values and clinical CV comparison are not reported. This leaves the central performance numbers only partially supported, as the soundness assessment notes.
minor comments (1)
- [Abstract] Abstract: Adding standard deviations or confidence intervals to the reported DSC figures would improve interpretability of the performance claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for clarification, particularly around the exploratory nature of the clinical evaluation and the need for additional methodological details. We address each point below and have revised the manuscript accordingly to strengthen the presentation while maintaining the integrity of our findings.
read point-by-point responses
-
Referee: [Abstract / Clinical Evaluation] Abstract / Clinical Evaluation section: The headline claim that the pipeline enables clinical pathology assessment rests on the glottal-area CV distinguishing healthy from pathological subjects (p=0.006) in an exploratory n=40 cohort. No information is supplied on age/sex matching, acquisition-parameter stratification, power calculation, or comparison against other kinematic features; this is load-bearing for the title and abstract claim and must be addressed with additional controls or explicit qualification as preliminary.
Authors: We agree that the clinical results are exploratory and based on a modest cohort size. In the revised manuscript, we have explicitly qualified these findings as preliminary in the abstract, results, and discussion sections, emphasizing the need for larger validation studies. We added available subject demographics (age range and sex distribution) and acquisition parameters where recorded. A formal power calculation was not performed a priori, which we now state as a limitation; however, the reported p=0.006 remains indicative of a detectable difference. We have also included a brief comparison of the CV metric against other kinematic features (e.g., glottal gap index) in the supplementary material. The title has been softened to 'and Preliminary Clinical Pathology Assessment' to better reflect the evidence level. revision: partial
-
Referee: [Methods / Results] Methods / Results: Training hyperparameters, the precise cross-validation protocol, and error bars (or confidence intervals) on the DSC values and clinical CV comparison are not reported. This leaves the central performance numbers only partially supported, as the soundness assessment notes.
Authors: We appreciate this observation and have expanded the Methods section with a new subsection on experimental setup. This includes all training hyperparameters (initial learning rate of 1e-4 with cosine annealing, batch size 16, 100 epochs, AdamW optimizer, and data augmentations), the cross-validation protocol (5-fold stratified cross-validation on each dataset with subject-level splits to avoid leakage), and statistical reporting. All DSC values now include mean ± standard deviation across folds, and the clinical CV comparison includes 95% bootstrap confidence intervals. These additions directly address the soundness concerns and improve reproducibility. revision: yes
Circularity Check
No circularity: standard held-out evaluation and independent clinical statistic
full rationale
The paper presents a standard supervised segmentation pipeline (YOLOv8n localizer + U-Net) trained on the public GIRAFE and BAGLS datasets and evaluated via Dice scores on held-out test splits, including a cross-dataset transfer test. The clinical claim rests on a simple two-group comparison of glottal-area coefficient of variation (p=0.006) computed directly from the extracted waveforms in an exploratory cohort of 40 subjects. No equations, fitted parameters, or self-citations are used to derive the reported metrics or the statistical distinction; both are independent measurements on external data. No self-definitional, fitted-input-called-prediction, or uniqueness-imported patterns appear.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of convolutional neural networks for medical image segmentation hold across the GIRAFE and BAGLS acquisition protocols
Reference graph
Works this paper leans on
-
[1]
D. D. Deliyski, Clinical implementation of laryngeal high-speed videoen- doscopy: Challenges and evolution, Folia Phoniatrica et Logopaedica 60 (1) (2008) 33–44.doi:10.1159/000111802
-
[2]
M. A. Little, P. E. McSharry, S. J. Roberts, D. A. E. Costello, I. M. Moroz, Exploiting nonlinear recurrence and fractal scaling properties for voice disorder detection, BioMedical Engineering OnLine 6 (2007) 23. doi:10.1186/1475-925X-6-23
-
[3]
J. Lohscheller, U. Eysholdt, H. Toy, M. Döllinger, Phonovibrography: Mapping high-speed movies of vocal fold vibrations into 2-D diagrams for visualizing and analyzing the underlying laryngeal dynamics, IEEE Transactions on Medical Imaging 27 (3) (2008) 300–309.doi:10.1109/ TMI.2007.903690
-
[4]
R. R. Patel, K. D. Donohue, H. Unnikrishnan, R. J. Kryscio, Effects of vocal fold nodules on glottal cycle measurements derived from high- speed videoendoscopy in children, PLOS ONE 11 (4) (2016) e0154586, nodules vs. typically developing children; kinematic features.doi:10. 1371/journal.pone.0154586
work page 2016
-
[5]
P. Gómez, A. M. Kist, P. Schlegel, D. A. Berry, D. K. Chhetri, R. Mon- taño, F. Müller, A. Schützenberger, M. Semmler, S. Dürr, D. Eytan, J. Lohscheller, M. Echternach, M. Döllinger, BAGLS, a multihospital benchmark for automatic glottis segmentation, Scientific Data 7 (2020) 186.doi:10.1038/s41597-020-0526-3
-
[6]
F. J. P. Montalbo, S3AR U-Net: A separable squeezed simi- larity attention-gated residual U-Net for glottis segmentation, 26 Biomedical Signal Processing and Control 92 (2024) 106047. doi:10.1016/j.bspc.2024.106047. URL https://www.sciencedirect.com/science/article/pii/ S1746809424001058
-
[7]
G. Andrade-Miranda, M. Hernández-Álvarez, J. I. Godino-Llorente, GIRAFE: Glottal imaging dataset for advanced segmentation, analysis, and facilitative playbacks evaluation, Data in Brief 59 (2025) 111376. doi:10.1016/j.dib.2025.111376. URLhttps://doi.org/10.1016/j.dib.2025.111376
-
[8]
R.R.Patel, H.Unnikrishnan, K.D.Donohue, Effectsofvocalfoldnodules on glottal cycle measurements derived from high-speed videoendoscopy in children, PloS one 11 (4) (2016) e0154586
work page 2016
-
[9]
H. Unnikrishnan, K. D. Donohue, R. R. Patel, Analysis of high-speed digital phonoscopy pediatric images, in: Photonic Therapeutics and Diagnostics VIII, Vol. 8207, SPIE, 2012, pp. 328–340
work page 2012
-
[10]
R. R. Patel, K. D. Donohue, H. Unnikrishnan, R. J. Kryscio, Kinematic measurements of the vocal-fold displacement waveform in typical children and adult populations: quantification of high-speed endoscopic videos, Journal of Speech, Language, and Hearing Research 58 (2) (2015) 227–240. doi:10.1044/2015_JSLHR-S-14-0242
-
[11]
M. K. Fehling, F. Grosch, M. E. Schuster, B. Schick, J. Lohscheller, Fully automatic segmentation of glottis and vocal folds in endoscopic laryngeal high-speed videos using a deep convolutional LSTM network, PLOS ONE 15 (2) (2020) e0227791.doi:10.1371/journal.pone.0227791
-
[12]
S.M.N.Nobel, S.M.M.R.Swapno, M.R.Islam, M.Safran, S.Alfarhood, M. F. Mridha, A machine learning approach for vocal fold segmentation and disorder classification based on ensemble method, Scientific Reports 14, pMCID: PMC11758383; PMID: 38910146. Ensemble UNet-BiGRU segmentation (IoU 87.46%); no evaluation on public BAGLS or GIRAFE benchmarks. (2024).doi:1...
-
[13]
M. Döllinger, T. Schraut, L. A. Henrich, D. Chhetri, M. Echternach, A. M. Johnson, M. Kunduk, Y. Maryn, R. R. Patel, R. Samlan, et al., 27 Re-training of convolutional neural networks for glottis segmentation in endoscopic high-speed videos, Applied Sciences 12 (19) (2022) 9791. doi:10.3390/app12199791. URLhttps://doi.org/10.3390/app12199791
- [14]
-
[15]
U-Net: Convolutional networks for biomedical image segmentation
O. Ronneberger, P. Fischer, T. Brox, U-Net: Convolutional net- works for biomedical image segmentation, in: Medical Image Com- puting and Computer-Assisted Intervention (MICCAI), Vol. 9351 of Lecture Notes in Computer Science, Springer, 2015, pp. 234–241. doi:10.1007/978-3-319-24574-4_28
-
[16]
F. Milletari, N. Navab, S.-A. Ahmadi, V-Net: Fully convolutional neu- ral networks for volumetric medical image segmentation, in: Fourth International Conference on 3D Vision (3DV), 2016, pp. 565–571. doi:10.1109/3DV.2016.79
-
[17]
I. Loshchilov, F. Hutter, Decoupled weight decay regularization, in: International Conference on Learning Representations (ICLR), 2019, pp. 1–22. URLhttps://openreview.net/forum?id=Bkg6RiCqY7
work page 2019
-
[18]
I. Loshchilov, F. Hutter, SGDR: Stochastic gradient descent with warm restarts, in: International Conference on Learning Representations (ICLR), 2017, pp. 1–16. URLhttps://openreview.net/forum?id=Skq89Scxx
work page 2017
-
[19]
N. Otsu, A threshold selection method from gray-level histograms, IEEE Transactions on Systems, Man, and Cybernetics 9 (1) (1979) 62–66. doi:10.1109/TSMC.1979.4310076
-
[20]
J. Wu, R. Fu, H. Fang, Y. Zhang, Y. Yang, H. Xiong, H. Liu, Y. Xu, MedSegDiff: Medical image segmentation with diffusion probabilistic model, in: Medical Imaging with Deep Learning, Vol. 227 of Proceedings of Machine Learning Research, PMLR, 2024, pp. 1623–1639. URLhttps://proceedings.mlr.press/v227/wu24a.html 28
work page 2024
-
[21]
D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, in: International Conference on Learning Representations (ICLR), 2015, pp. 1–15. URLhttps://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[22]
In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV)
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, P. Dollár, R. Girshick, Segment anything, in: IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 4015–4026.doi:10.1109/ICCV51070.2023. 00371
-
[23]
J. Ma, Y. He, F. Li, L. Han, C. You, B. Wang, Segment anything in medical images, Nature Communications 15 (2024) 654.doi:10.1038/ s41467-024-44824-z. 29
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.