Sensory-Aware Sequential Recommendation via Review-Distilled Representations
Pith reviewed 2026-05-15 17:32 UTC · model grok-4.3
The pith
Sensory attributes extracted from reviews and distilled into fixed embeddings improve sequential recommendation accuracy in most tested cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
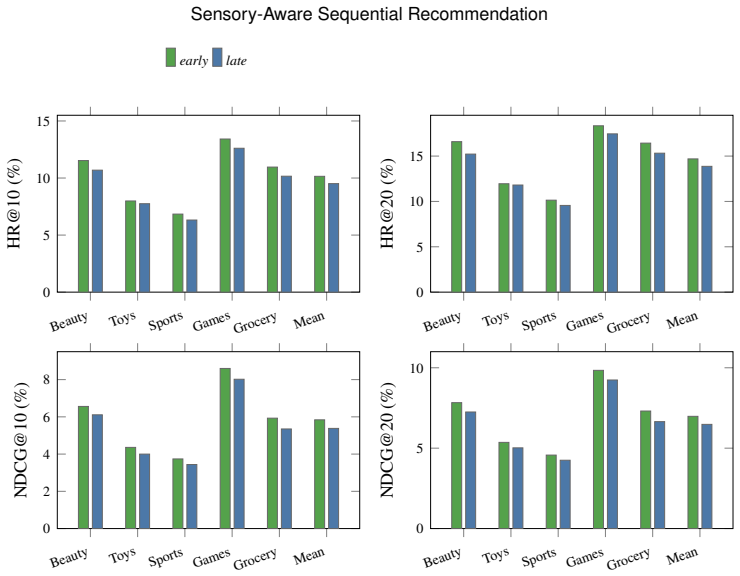
An offline pipeline first fine-tunes a large language model to extract structured sensory attribute-value pairs from review text and then distills those pairs into fixed-dimensional embeddings via a student transformer; when these embeddings are concatenated with item representations inside existing sequential architectures, the resulting models achieve higher HR@10 and NDCG@10 scores than their non-sensory counterparts in 19 of 20 domain-backbone combinations, with average relative gains of 7.9 percent in HR@10 and 11.2 percent in NDCG@10.
What carries the argument
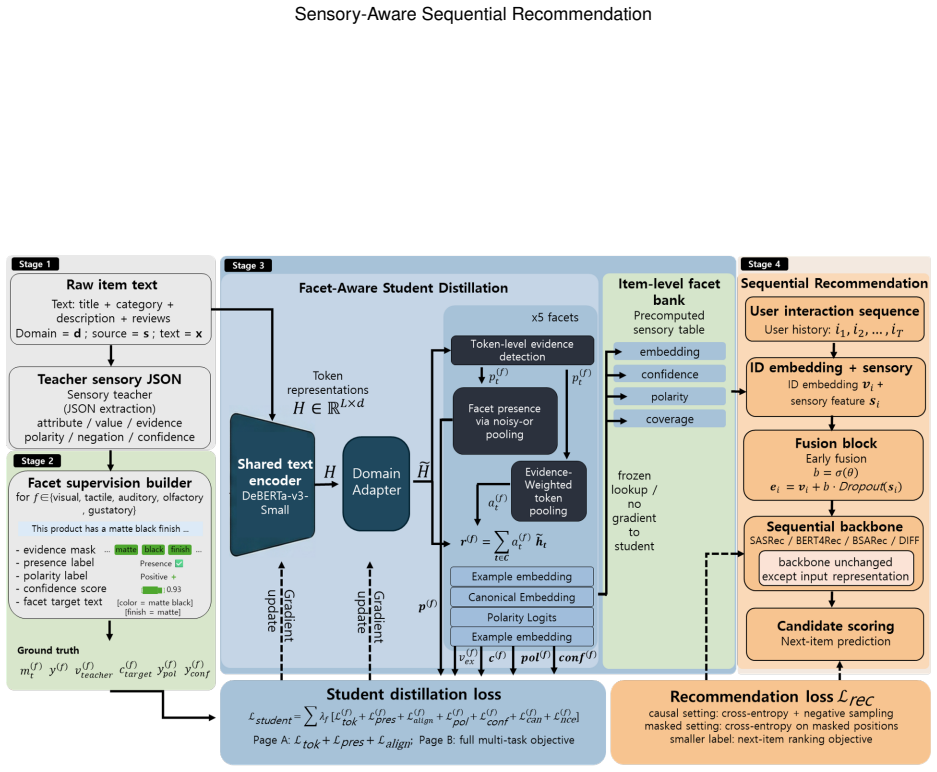
The ASER offline extraction-and-distillation pipeline that produces fixed sensory embeddings from review-derived attribute-value pairs and injects them into item representations.
If this is right
- Sensory-enhanced versions outperform matched baselines in 19 of 20 domain-backbone combinations on both HR@10 and NDCG@10.
- Average relative gains reach 7.9 percent in HR@10 and 11.2 percent in NDCG@10 across the tested Amazon domains.
- The extracted attributes align closely enough with human judgments to support interpretable links between review language and recommendation outputs.
- The same distillation process integrates with multiple existing sequential backbones including SASRec, BERT4Rec, BSARec, and DIFF without architectural changes.
Where Pith is reading between the lines
- The same extraction-and-distillation pattern could be applied to other review-derived signals such as durability or fit, not just sensory ones.
- Fixed sensory embeddings could be used after training to surface which sensory features explain why an item is recommended to a given user.
- The method leaves open the question of whether the embeddings remain useful when new reviews arrive after initial training.
- Domains outside e-commerce where sensory language appears in text, such as restaurant or travel reviews, could test the same pipeline.
Load-bearing premise
The attribute-value pairs extracted from reviews genuinely reflect the sensory qualities that matter to users rather than noise or model artifacts.
What would settle it
A controlled run in which the same pipeline is trained on randomly shuffled or non-sensory attributes from the identical reviews and still produces comparable accuracy gains would show that the sensory content itself is not driving the reported improvements.
Figures


read the original abstract
We propose a novel framework for sensory-aware sequential recommendation that enriches item representations with linguistically extracted sensory attributes from product reviews. Our approach, ASER (Attribute-based Sensory-Enhanced Representation), introduces an offline extraction-and-distillation pipeline in which a large language model is first fine-tuned as a teacher to extract structured sensory attribute-value pairs, such as color: matte black and scent: vanilla, from unstructured review text. The extracted structures are then distilled into a compact student transformer that produces fixed-dimensional sensory embeddings for each item. These embeddings encode experiential semantics in a reusable form and are incorporated into standard sequential recommender architectures as additional item-level representations. We evaluate our method on five Amazon domains and integrate the learned sensory embeddings into SASRec, BERT4Rec, BSARec, and DIFF. Across 20 domain-backbone combinations, sensory-enhanced models improve over matched non-sensory counterparts in 19 cases for both HR@10 and NDCG@10, with average relative gains of 7.9% in HR@10 and 11.2% in NDCG@10. Qualitative analysis further shows that the extracted attributes align closely with human perceptions of products, enabling interpretable connections between natural language descriptions and recommendation behavior. Overall, this work demonstrates that sensory attribute distillation offers a principled and scalable way to bridge information extraction and sequential recommendation through structured semantic representation learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ASER, a framework that fine-tunes an LLM teacher to extract structured sensory attribute-value pairs from product reviews, distills them via a student transformer into fixed-dimensional item embeddings, and fuses these embeddings into standard sequential recommenders (SASRec, BERT4Rec, BSARec, DIFF). Across five Amazon domains and 20 domain-backbone combinations, the sensory-enhanced models outperform their non-sensory counterparts in 19 cases on both HR@10 and NDCG@10, with average relative gains of 7.9% and 11.2%, respectively; qualitative analysis claims the extracted attributes align with human perceptions.
Significance. If the gains prove attributable to the semantic content of the distilled sensory representations rather than incidental capacity increases, the work supplies a practical, reusable pipeline for injecting experiential review-derived signals into sequential recommendation, with potential benefits for both accuracy and interpretability.
major comments (2)
- [Experiments] Experiments section: no ablation injects random vectors of identical dimensionality under the same fusion scheme (concatenation or otherwise) used for the sensory embeddings. Because the added representations necessarily increase input dimensionality and parameter count relative to the matched baselines, the 19/20 win rate and 7.9–11.2% relative gains could arise from extra capacity rather than the claimed sensory semantics.
- [Results] Results section: performance tables report point estimates only, with no error bars, standard deviations across runs, or statistical significance tests (e.g., paired t-test or Wilcoxon signed-rank). In addition, data-split protocol (leave-one-out, temporal, etc.), validation procedure, and hyperparameter search details are not provided, rendering the central outperformance claim only partially verifiable.
minor comments (2)
- [Abstract and §3.2] The abstract and §3.2 should explicitly list the five Amazon domains and the exact attribute-value extraction prompt template used for the teacher LLM.
- [§3.3] Notation for the fusion operation (e.g., how the student embedding is concatenated or projected before being fed to the backbone) is described at a high level; a precise equation or diagram would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our experimental validation and result reporting. We address each major comment below and will make the necessary revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: no ablation injects random vectors of identical dimensionality under the same fusion scheme (concatenation or otherwise) used for the sensory embeddings. Because the added representations necessarily increase input dimensionality and parameter count relative to the matched baselines, the 19/20 win rate and 7.9–11.2% relative gains could arise from extra capacity rather than the claimed sensory semantics.
Authors: We agree that an ablation with random vectors of identical dimensionality is required to isolate the contribution of sensory semantics from capacity increases. In the revised manuscript we will add this control under the exact same fusion schemes (concatenation) used for the sensory embeddings across all 20 domain-backbone combinations. The results will be reported alongside the original tables to demonstrate whether performance gains persist when the added vectors carry no semantic information. revision: yes
-
Referee: [Results] Results section: performance tables report point estimates only, with no error bars, standard deviations across runs, or statistical significance tests (e.g., paired t-test or Wilcoxon signed-rank). In addition, data-split protocol (leave-one-out, temporal, etc.), validation procedure, and hyperparameter search details are not provided, rendering the central outperformance claim only partially verifiable.
Authors: We acknowledge that the current version lacks error bars, standard deviations, statistical tests, and full experimental protocol details. The revised manuscript will report mean and standard deviation over five random seeds for all metrics, include paired t-tests (or Wilcoxon signed-rank where appropriate) between sensory-enhanced and baseline models, and add a dedicated subsection describing the leave-one-out data split, validation procedure, and hyperparameter search protocol. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central claims consist of empirical improvements from adding distilled sensory embeddings to standard sequential models (SASRec, BERT4Rec, etc.). These gains are measured directly against non-sensory baselines using HR@10 and NDCG@10 on Amazon domains. No equations, self-citations, or definitions reduce the reported relative gains (7.9% HR@10, 11.2% NDCG@10) to quantities defined by the same fitted parameters or prior self-referential results. The teacher-student distillation pipeline follows standard practices without self-definitional loops or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can reliably extract accurate structured sensory attribute-value pairs from unstructured review text
Reference graph
Works this paper leans on
-
[1]
W.-C. Kang, J. McAuley, Self-attentive sequential recommendation, in: 2018 IEEE international conference on data mining (ICDM), IEEE, pp. 197–206
work page 2018
-
[2]
F. Sun, J. Liu, J. Wu, C. Pei, X. Lin, W. Ou, P. Jiang, Bert4rec: Sequential recommendation with bidirectional encoder representations from transformer, in: Proceedings of the 28th ACM international conference on information and knowledge management, pp. 1441–1450
-
[3]
Y . Shin, J. Choi, H. Wi, N. Park, An attentive inductive bias for sequential recommendation beyond the self-attention, in: Proceedings of the AAAI conference on artificial intelligence, volume 38, pp. 8984–8992
-
[4]
H.-y. Kim, M. Choi, S. Lee, I. Baek, J. Lee, Diff: Dual side-information filtering and fusion for sequential recommendation, in: Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 1624–1633
-
[5]
Session-based Recommendations with Recurrent Neural Networks
B. Hidasi, A. Karatzoglou, L. Baltrunas, D. Tikk, Session-based recommendations with recurrent neural networks, arXiv preprint arXiv:1511.06939 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[6]
J. Zhang, R. Xie, W. Sun, L. Lin, W. X. Zhao, J.-R. Wen, Aurisrec: Adversarial user intention learning in sequential recommendation, in: Findings of the Association for Computational Linguistics: EMNLP 2024, pp. 12580–12592. Y .-C. Y oon, C. Park and K. Koh:Preprint submitted to ElsevierPage 34 of 39 Sensory-Aware Sequential Recommendation
work page 2024
-
[7]
H. Qu, Y . Zhang, L. Ning, W. Fan, Q. Li, SSD4Rec: A structured state space duality model for efficient sequential recommendation, ACM Transactions on Information Systems 44 (2026) 29:1–29:26
work page 2026
-
[8]
H. Fan, M. Zhu, Y . Hu, H. Feng, Z. He, H. Liu, Q. Liu, TiM4Rec: An efficient sequential recommendation model based on time-aware structured state space duality model, Neurocomputing 654 (2025) 131270
work page 2025
-
[9]
Z. Song, G. Li, M. Song, HeteroTempRec: Temporally-aware heterogeneous architecture with sparse block attention for efficient sequential recommendation, Information Sciences 728 (2026) 122703
work page 2026
-
[10]
K. Zhu, J. Li, Y . He, M. Wang, J. Yu, J. Chang, J. Wan, JCLRec: Joint diffusion model and dual contrastive learning for sequential recommendation, Knowledge-Based Systems 333 (2026) 114888
work page 2026
-
[11]
J. McAuley, J. Leskovec, Hidden factors and hidden topics: understanding rating dimensions with review text, in: Proceedings of the 7th ACM conference on Recommender systems, pp. 165–172
- [12]
-
[13]
C. Chen, M. Zhang, Y . Liu, S. Ma, Neural attentional rating regression with review-level explanations, in: Proceedings of the 2018 world wide web conference, pp. 1583–1592
work page 2018
-
[14]
L. Li, Y . Zhang, L. Chen, Personalized transformer for explainable recommendation, in: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (V olume 1: Long Papers), pp. 4947–4957
- [15]
-
[16]
Q. Ma, X. Ren, C. Huang, Xrec: Large language models for explainable recommendation, in: Findings of the Association for Computational Linguistics: EMNLP 2024, pp. 391–402
work page 2024
-
[17]
C.-W. Yang, Z.-Q. Feng, Y .-J. Lin, C. W. Chen, K.-d. Wu, H. Xu, Y . Jui-Feng, H.-Y . Kao, Maple: Enhancing review generation with multi-aspect prompt learning in explainable recommendation, in: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pp. 31803–31821
-
[18]
Y . Lu, Q. Liu, D. Dai, X. Xiao, H. Lin, X. Han, L. Sun, H. Wu, Unified structure generation for universal information extraction, in: Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers), pp. 5755–5772
-
[19]
Y . Qi, H. Peng, X. Wang, B. Xu, L. Hou, J. Li, Adelie: Aligning large language models on information extraction, in: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 7371–7387
work page 2024
-
[20]
F. Bai, J. Kang, G. Stanovsky, D. Freitag, M. Dredze, A. Ritter, Schema-driven information extraction from heterogeneous tables, in: Findings of the Association for Computational Linguistics: EMNLP 2024, pp. 10252–10273
work page 2024
-
[21]
Y . Ren, Z. Chen, X. Yang, L. Li, C. Jiang, L. Cheng, B. Zhang, L. Mo, J. Zhou, Enhancing sequential recommenders with augmented knowledge from aligned large language models, in: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 345–354
-
[22]
S. Yang, W. Ma, P. Sun, Q. Ai, Y . Liu, M. Cai, M. Zhang, Sequential recommendation with latent relations based on large language model, in: Proceedings of the 47th International ACM SIGIR conference on research and development in information retrieval, pp. 335–344
-
[23]
J. Tan, S. Xu, W. Hua, Y . Ge, Z. Li, Y . Zhang, Idgenrec: Llm-recsys alignment with textual id learning, in: Proceedings of the 47th international ACM SIGIR conference on research and development in information retrieval, pp. 355–364
-
[24]
H. Na, M. Gang, Y . Ko, J. Seol, S.-g. Lee, Enhancing large language model based sequential recommender systems with pseudo labels reconstruction, in: Findings of the Association for Computational Linguistics: EMNLP 2024, pp. 7213–7222
work page 2024
-
[25]
Y . He, X. Liu, A. Zhang, Y . Ma, T.-S. Chua, Llm2rec: Large language models are powerful embedding models for sequential recommendation, in: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pp. 896–907
-
[26]
J. Liao, R. Xie, S. Li, X. Wang, X. Sun, Z. Kang, X. He, Multi-grained patch training for efficient llm-based recommendation, in: Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 1572–1581
-
[27]
Y . Cui, F. Liu, P. Wang, B. Wang, H. Tang, Y . Wan, J. Wang, J. Chen, Distillation matters: empowering sequential recommenders to match the performance of large language models, in: Proceedings of the 18th ACM Conference on Recommender Systems, pp. 507–517
- [28]
- [29]
-
[30]
X. Zhang, L. Hu, L. Zhang, W. Cheng, Y . Wang, G. Shi, C. Feng, L. Nie, Bi-tuning with collaborative information for controllable llm-based sequential recommendation, in: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pp. 19340–19351
-
[31]
X. Wang, J. Cui, F. Fukumoto, Y . Suzuki, Agrec: Adapting autoregressive decoders with graph reasoning for llm-based sequential recommendation, in: Findings of the Association for Computational Linguistics: ACL 2025, pp. 7076–7090
work page 2025
-
[32]
X. Wang, J. Cui, Y . Suzuki, F. Fukumoto, Rdrec: Rationale distillation for llm-based recommendation, in: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 2: Short Papers), pp. 65–74
-
[33]
A. Boz, W. Zorgdrager, Z. Kotti, J. Harte, P. Louridas, V . Karakoidas, D. Jannach, M. Fragkoulis, Improving sequential recommendations with LLMs, ACM Transactions on Recommender Systems 4 (2025) 19:1–19:35
work page 2025
- [34]
-
[35]
Z. Hu, Y . Pan, Z. Li, J. Huang, S. Nakagawa, J. Deng, S. Cai, F. Ren, Retrieval-enhanced, adaptively collaborative, and temporal-aware user behavior comprehension for LLM-based sequential recommendation, Information Processing & Management 63 (2026) 104354. Y .-C. Y oon, C. Park and K. Koh:Preprint submitted to ElsevierPage 35 of 39 Sensory-Aware Sequent...
work page 2026
- [36]
-
[37]
H. Kim, J. Kim, M. Choi, S. Lee, J. Lee, Mars: Matching attribute-aware representations for text-based sequential recommendation, in: Proceedings of the 33rd ACM International Conference on Information and Knowledge Management, pp. 3822–3826
-
[38]
G. Liu, F. Yang, Y . Jiao, A. Bagheri Garakani, T. Tong, Y . Gao, M. Jiang, Learning attribute as explicit relation for sequential recommendation, in: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pp. 800–811
- [39]
-
[40]
J. J. Peper, W. Qiu, R. Bruggeman, Y . Han, E. C. Chehade, L. Wang, Shoes-acosi: A dataset for aspect-based sentiment analysis with implicit opinion extraction, in: Findings of the Association for Computational Linguistics: EMNLP 2024, pp. 15477–15490
work page 2024
- [41]
- [42]
-
[43]
H. Fang, J. Liang, L. Sha, Enhanced multimodal recommendation systems through reviews integration, Knowledge and Information Systems 67 (2025) 3459–3486
work page 2025
-
[44]
Q. Hao, C. Wang, Y . Xiao, W. Zheng, Iregnn: Implicit review-enhanced graph neural network for explainable recommendation, Knowledge- Based Systems 311 (2025) 113113
work page 2025
-
[45]
N. C. Hellwig, J. Fehle, C. Wolff, Exploring large language models for the generation of synthetic training samples for aspect-based sentiment analysis in low resource settings, Expert Systems with Applications 261 (2025) 125514
work page 2025
-
[46]
R. Fan, T. He, M. Dong, Multi-faceted data augmentation for aspect-based sentiment analysis via large language models, Knowledge-Based Systems (2025) 114827
work page 2025
-
[47]
B. Gundersen, S. Kalloori, A. Srivastava, Emotion aware session based news recommender systems, Decision Support Systems (2025) 114540
work page 2025
-
[48]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al., Qwen3 technical report, arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
P. He, J. Gao, W. Chen, Debertav3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing, arXiv preprint arXiv:2111.09543 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[50]
J. McAuley, C. Targett, Q. Shi, A. Van Den Hengel, Image-based recommendations on styles and substitutes, in: Proceedings of the 38th international ACM SIGIR conference on research and development in information retrieval, pp. 43–52. Y .-C. Y oon, C. Park and K. Koh:Preprint submitted to ElsevierPage 36 of 39 Sensory-Aware Sequential Recommendation Append...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.