Recognition: 1 theorem link
· Lean TheoremFast and memory-efficient classical simulation of quantum machine learning via forward and backward gate fusion
Pith reviewed 2026-05-15 17:09 UTC · model grok-4.3
The pith
Fusing consecutive gates in forward and backward passes cuts memory traffic and speeds classical simulation of quantum machine learning circuits by roughly 20 times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
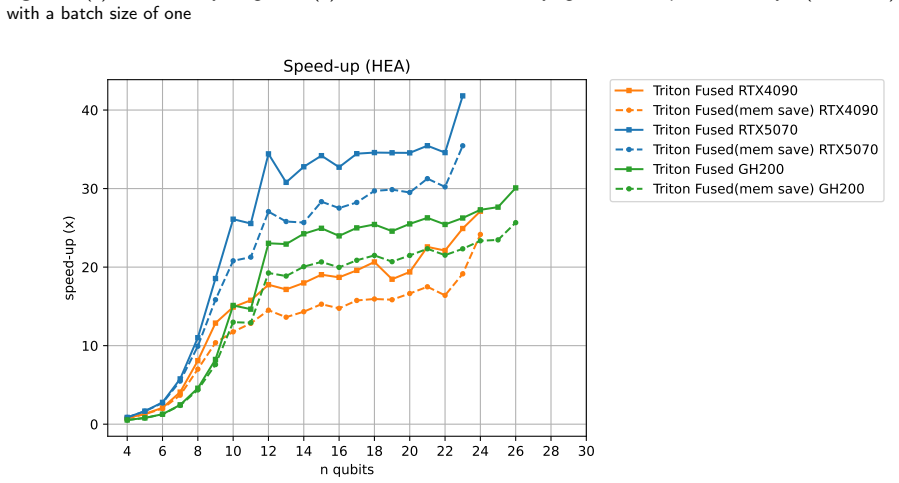
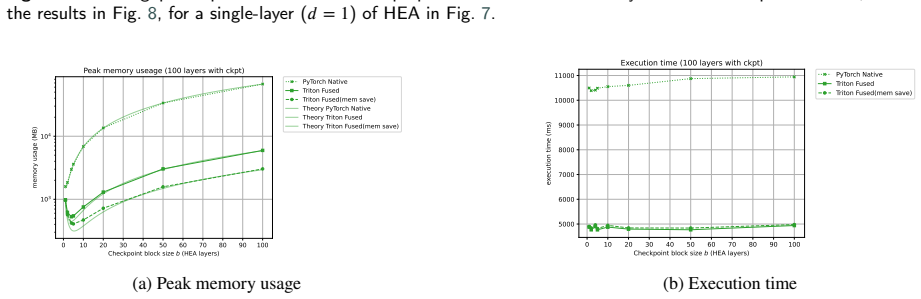
By fusing consecutive gates in the forward and backward paths, the simulation minimizes global memory accesses during circuit evaluation and gradient calculation. This produces approximately 20 times higher throughput for hardware-efficient ansatz circuits with 12 or more qubits, more than 30 times on mid-range consumer GPUs, and, together with checkpointing, permits training of a 20-qubit, 1,000-layer model containing 60,000 parameters on 1,000 samples in about 20 minutes per epoch, thereby enabling large-dataset experiments on classical machines.
What carries the argument
Forward-and-backward gate fusion, which merges sequences of consecutive gates before they are applied to state vectors or gradients so that intermediate results stay in fast on-chip memory instead of being written to and read from global memory.
If this is right
- Throughput rises by a factor of about 20 for hardware-efficient ansatz circuits of 12 or more qubits.
- Speedups exceed 30 times on GPUs whose performance is limited by memory bandwidth.
- Memory footprint shrinks enough to fit and train 20-qubit circuits with 1,000 layers and 60,000 parameters on 1,000 samples in 20 minutes per epoch.
- Training on datasets of tens of thousands of samples becomes practical within roughly 20 hours per epoch.
- Verification of quantum machine learning algorithms and study of deep-circuit phenomena such as barren plateaus can be performed on realistic data volumes.
Where Pith is reading between the lines
- The same fusion strategy could be applied to other variational quantum algorithms that rely on repeated circuit evaluations, such as quantum approximate optimization or quantum chemistry simulations.
- Combining gate fusion with tensor-network or low-rank approximations might allow scaling beyond 20 qubits while keeping memory usage manageable.
- The reduced per-epoch time could make systematic hyperparameter searches over circuit depth or ansatz structure feasible on single-GPU workstations.
- Empirical checks of learning-theory predictions for very deep quantum circuits become experimentally accessible on standard hardware.
Load-bearing premise
Gate fusion works for typical quantum machine learning circuits without introducing numerical inaccuracies or extra overhead that would cancel the memory-access savings.
What would settle it
Measuring wall-clock time and peak memory for the exact 20-qubit, 1,000-layer, 60,000-parameter training run on the same GPU hardware without any gate fusion and finding that it either exceeds available memory or takes longer than 20 minutes per epoch.
Figures









read the original abstract
While real quantum devices have been increasingly used to conduct research focused on achieving quantum advantage or quantum utility in recent years, executing deep quantum circuits or performing quantum machine learning with large-scale data on current noisy intermediate-scale quantum devices remains challenging, making classical simulation essential for quantum machine learning research. However, such classical simulation often suffers from the cost of gradient calculations, requiring enormous memory or computational time. To address these problems, we propose a method to fuse multiple consecutive gates in each of the forward and backward paths to improve throughput by minimizing global memory accesses. As a result, we achieved approximately $20$ times throughput improvement for a Hardware-Efficient Ansatz with $12$ or more qubits, reaching over $30$ times improvement on a mid-range consumer GPU with limited memory bandwidth. By combining our proposed method with gradient checkpointing, we drastically reduced memory usage, making it possible to train a large-scale quantum machine learning model, a $20$-qubit, $1{,}000$-layer model with $60{,}000$ parameters, using $1{,}000$ samples in approximately $20$ minutes per epoch. This implies that we can train the model on large datasets, comprising tens of thousands of samples, like MNIST or CIFAR-10, within a realistic time frame (e.g., $20$ hours per epoch). Thus, our proposed method significantly accelerates such classical simulations, making a significant contribution to advancing research in quantum machine learning and variational quantum algorithms, such as verifying algorithms on large datasets or investigating learning theories of deep quantum circuits like barren plateaus.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes fusing consecutive gates in the forward and backward passes of classical quantum circuit simulation to minimize global memory accesses, reporting ~20x throughput gains for Hardware-Efficient Ansatz circuits (12+ qubits) and >30x on bandwidth-limited GPUs. Combined with gradient checkpointing, the method enables training a 20-qubit, 1000-layer model (60k parameters) on 1000 samples in ~20 minutes per epoch, with implications for scaling to datasets like MNIST.
Significance. If the performance numbers hold under broader testing, the work could meaningfully expand the feasible scale of classical QML simulations, supporting verification of variational algorithms and studies of phenomena like barren plateaus on larger instances. The fusion-plus-checkpointing combination directly targets the memory-compute tradeoff in gradient evaluation.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experimental Results): the ~20x and >30x throughput claims are presented without specifying the baseline simulator implementation, exact gate counts, hardware specifications beyond 'mid-range consumer GPU', or statistical error bars on timings, preventing independent verification of the central performance result.
- [§3 and §5] §3 (Proposed Method) and §5 (Generalization discussion): the fusion opportunities are shown to exploit the regular layered structure of the Hardware-Efficient Ansatz; for ansatze with irregular gate sequences (e.g., QAOA or UCCSD), the number of fusible blocks may be smaller, so the reported speedups cannot be assumed to transfer without additional overhead analysis.
minor comments (2)
- [Tables in §4] Ensure all timing tables include the precise number of shots, batch size, and compiler flags used for the baseline to allow reproducibility.
- [Introduction] Add a short paragraph contrasting the proposed fusion with existing tensor-network or state-vector optimizations in the literature.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help improve the clarity and scope of our work. We address each major point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Results): the ~20x and >30x throughput claims are presented without specifying the baseline simulator implementation, exact gate counts, hardware specifications beyond 'mid-range consumer GPU', or statistical error bars on timings, preventing independent verification of the central performance result.
Authors: We agree that these details are essential for verification. In the revised manuscript we will explicitly identify the baseline as our own unfused simulator implementation, report the precise gate counts for each tested circuit (e.g., 12-qubit HEA), provide the full GPU model name together with its memory bandwidth, and include standard deviations from repeated timing measurements. revision: yes
-
Referee: [§3 and §5] §3 (Proposed Method) and §5 (Generalization discussion): the fusion opportunities are shown to exploit the regular layered structure of the Hardware-Efficient Ansatz; for ansatze with irregular gate sequences (e.g., QAOA or UCCSD), the number of fusible blocks may be smaller, so the reported speedups cannot be assumed to transfer without additional overhead analysis.
Authors: The referee is correct that the largest gains occur with the regular layered structure of the Hardware-Efficient Ansatz. Our fusion procedure itself is agnostic to circuit regularity and can be applied to arbitrary gate sequences. We will expand the generalization discussion in §5 with a short overhead analysis for irregular ansatze (QAOA and UCCSD), showing that moderate speedups remain available even when fewer fusion opportunities exist. revision: yes
Circularity Check
No circularity: empirical performance gains from implemented gate fusion
full rationale
The paper describes an algorithmic technique (forward/backward gate fusion plus checkpointing) and reports measured speedups and memory reductions on Hardware-Efficient Ansatz circuits. No mathematical derivation chain exists that reduces a claimed result to its own inputs by construction, self-definition, or self-citation load-bearing. Throughput figures are direct experimental outcomes of reduced global memory traffic, not predictions fitted to the same data or renamed known results. The work is self-contained against external benchmarks (GPU timings) and contains no uniqueness theorems or ansatze smuggled via prior self-citation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we propose a method to fuse multiple consecutive gates in each of the forward and backward paths to improve throughput by minimizing global memory accesses
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Classification with Quantum Neural Networks on Near Term Processors
E. Farhi, H. Neven, Classification with quantum neural networks on near term processors, arXiv preprint arXiv:1802.06002 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
K. Mitarai, M. Negoro, M. Kitagawa, K. Fujii, Quantum circuit learning, Physical Review A 98 (2018) 032309
work page 2018
- [3]
-
[4]
A.Peruzzo,J.McClean,P.Shadbolt,M.-H.Yung,X.-Q.Zhou,P.J.Love,A.Aspuru-Guzik,J.L.O’brien, Avariationaleigenvaluesolveron a photonic quantum processor, Nature communications 5 (2014) 4213
work page 2014
-
[5]
A.Kandala,A.Mezzacapo,K.Temme,M.Takita,M.Brink,J.M.Chow,J.M.Gambetta, Hardware-efficientvariationalquantumeigensolver for small molecules and quantum magnets, nature 549 (2017) 242–246
work page 2017
-
[6]
A Quantum Approximate Optimization Algorithm
E. Farhi, J. Goldstone, S. Gutmann, A quantum approximate optimization algorithm, arXiv preprint arXiv:1411.4028 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[7]
J. R. McClean, S. Boixo, V. N. Smelyanskiy, R. Babbush, H. Neven, Barren plateaus in quantum neural network training landscapes, Nature communications 9 (2018) 4812
work page 2018
-
[8]
S.Wang,E.Fontana,M.Cerezo,K.Sharma,A.Sone,L.Cincio,P.J.Coles, Noise-inducedbarrenplateausinvariationalquantumalgorithms, Nature communications 12 (2021) 6961
work page 2021
- [9]
-
[10]
X. You, X. Wu, Exponentially many local minima in quantum neural networks, in: International Conference on Machine Learning, PMLR, 2021, pp. 12144–12155
work page 2021
- [11]
-
[12]
E. Pednault, J. A. Gunnels, G. Nannicini, L. Horesh, R. Wisnieff, Leveraging secondary storage to simulate deep 54-qubit sycamore circuits, arXiv preprint arXiv:1910.09534 (2019)
-
[13]
J.Tindall,M.Fishman,E.M.Stoudenmire,D.Sels, Efficienttensornetworksimulationofibm’seaglekickedisingexperiment, Prxquantum 5 (2024) 010308
work page 2024
-
[14]
F.Arute,K.Arya,R.Babbush,D.Bacon,J.C.Bardin,R.Barends,R.Biswas,S.Boixo,F.G.Brandao,D.A.Buell,etal., Quantumsupremacy using a programmable superconducting processor, Nature 574 (2019) 505–510
work page 2019
-
[15]
G. Q. AI, Collaborators, Observation of constructive interference at the edge of quantum ergodicity, Nature 646 (2025) 825–830
work page 2025
-
[16]
Y. Kim, A. Eddins, S. Anand, K. X. Wei, E. Van Den Berg, S. Rosenblatt, H. Nayfeh, Y. Wu, M. Zaletel, K. Temme, et al., Evidence for the utility of quantum computing before fault tolerance, Nature 618 (2023) 500–505
work page 2023
- [17]
-
[18]
A. Javadi-Abhari, M. Treinish, K. Krsulich, C. J. Wood, J. Lishman, J. Gacon, S. Martiel, P. D. Nation, L. S. Bishop, A. W. Cross, B. R. Johnson, J. M. Gambetta, Quantum computing with Qiskit, 2024. doi:10.48550/arXiv.2405.08810.arXiv:2405.08810. Y. Kawase:Preprint submitted to ElsevierPage 16 of 17 Fast memory-efficient classical simulation of QML
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.08810.arxiv:2405.08810 2024
-
[19]
H. De Raedt, F. Jin, D. Willsch, M. Willsch, N. Yoshioka, N. Ito, S. Yuan, K. Michielsen, Massively parallel quantum computer simulator, eleven years later, Computer Physics Communications 237 (2019) 47–61
work page 2019
-
[20]
C. Kim, E. Sohn, S. Kim, A. Sim, K. Wu, H. Tang, Y. Son, S. Kim, Scaleqsim: Highly scalable quantum circuit simulation framework for exascale hpc systems, Proceedings of the ACM on Measurement and Analysis of Computing Systems 9 (2025) 1–28
work page 2025
- [21]
-
[22]
qHiPSTER: The Quantum High Performance Software Testing Environment
M. Smelyanskiy, N. P. Sawaya, A. Aspuru-Guzik, qhipster: The quantum high performance software testing environment, arXiv preprint arXiv:1601.07195 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[23]
D. Park, H. Kim, J. Kim, T. Kim, J. Lee, Snuqs: scaling quantum circuit simulation using storage devices, in: Proceedings of the 36th ACM International Conference on Supercomputing, 2022, pp. 1–13
work page 2022
-
[24]
T. Jones, J. Gacon, Efficient calculation of gradients in classical simulations of variational quantum algorithms, arXiv preprint arXiv:2009.02823 (2020)
- [25]
-
[26]
P. Tillet, H. T. Kung, D. Cox, Triton: an intermediate language and compiler for tiled neural network computations, in: Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, MAPL 2019, Association for Computing Machinery, New York, NY, USA, 2019, p. 10–19. URL:https://doi.org/10.1145/3315508.3329973. doi:...
-
[27]
J. Ansel, E. Yang, H. He, N. Gimelshein, A. Jain, M. Voznesensky, B. Bao, P. Bell, D. Berard, E. Burovski, G. Chauhan, A. Chourdia, W. Constable, A. Desmaison, Z. DeVito, E. Ellison, W. Feng, J. Gong, M. Gschwind, B. Hirsh, S. Huang, K. Kalambarkar, L. Kirsch, M. Lazos, M. Lezcano, Y. Liang, J. Liang, Y. Lu, C. Luk, B. Maher, Y. Pan, C. Puhrsch, M. Reso, ...
-
[28]
URL:https://github.com/mit-han-lab/torchquantum
Torchquantum, 2024. URL:https://github.com/mit-han-lab/torchquantum. Y. Kawase:Preprint submitted to ElsevierPage 17 of 17 Fast memory-efficient classical simulation of QML 2 4 6 8 10 12 14 16 18 20 m (the number of consecutive gates) 0 100 200 300 400 500mean execution time per m-gate sequence (ms) Forward performance comparison: PyT orch Native vs Fused...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.