Recognition: 2 theorem links
· Lean TheoremTagaVLM: Topology-Aware Global Action Reasoning for Vision-Language Navigation
Pith reviewed 2026-05-15 16:50 UTC · model grok-4.3
The pith
Injecting topological edges and nodes into VLMs enables global action reasoning for vision-language navigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
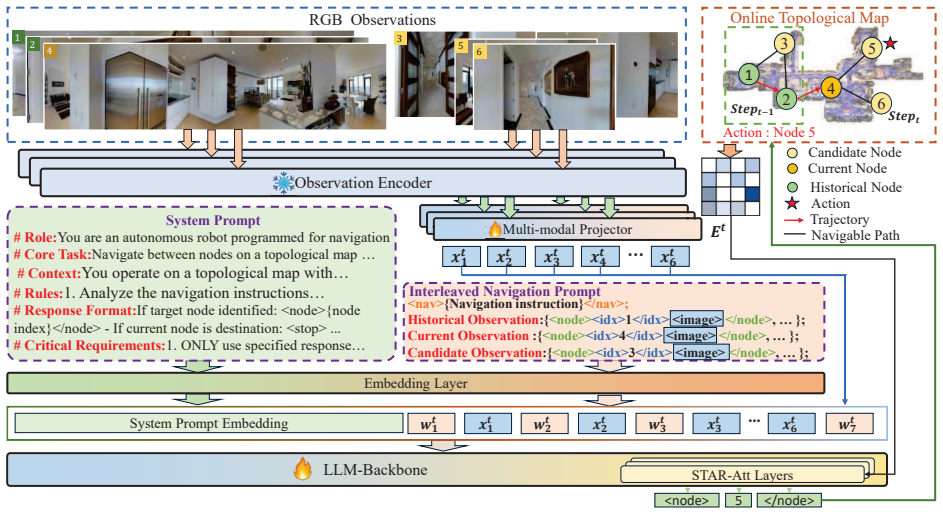
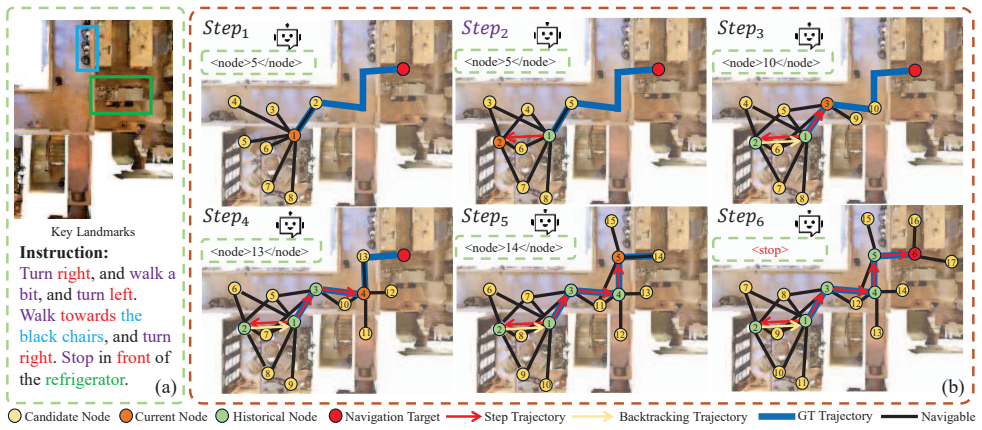
TagaVLM embeds a topological graph directly into a VLM backbone: Spatial Topology Aware Residual Attention integrates edge information into self-attention to support intrinsic spatial reasoning while preserving pretrained weights, and interleaved navigation prompts strengthen node-level visual-text alignment. The resulting model performs global action reasoning that enables robust path correction on embodied navigation tasks.
What carries the argument
Spatial Topology Aware Residual Attention (STAR-Att), which adds topological edge information directly into the VLM self-attention mechanism, together with interleaved navigation prompts that align node features.
If this is right
- The model can use the embedded graph to correct trajectories mid-episode instead of committing to locally greedy actions.
- Pretrained VLM knowledge remains intact because topology is added as a residual modification rather than by converting visuals to text.
- Targeted structure injection on modest-sized VLMs produces higher navigation accuracy than further scaling model size alone.
Where Pith is reading between the lines
- The same residual topology injection pattern could be tested on other embodied tasks that require long-horizon spatial planning.
- Dynamic graphs updated during navigation might further improve performance in changing environments.
- The efficiency argument implies that research effort on explicit spatial priors may yield larger gains than continued growth in parameter count for embodied VLMs.
Load-bearing premise
Adding topological edge and node signals through attention changes and prompts will improve navigation reasoning without disrupting the VLM's existing knowledge or creating new errors.
What would settle it
Training and evaluating the identical VLM backbone on the R2R unseen validation split with the STAR-Att module and interleaved prompts removed and finding no drop or an increase in success rate and SPL would falsify the benefit of the topology injection.
Figures


read the original abstract
Vision-Language Navigation (VLN) presents a unique challenge for Large Vision-Language Models (VLMs) due to their inherent architectural mismatch: VLMs are primarily pretrained on static, disembodied vision-language tasks, which fundamentally clash with the dynamic, embodied, and spatially-structured nature of navigation. Existing large-model-based methods often resort to converting rich visual and spatial information into text, forcing models to implicitly infer complex visual-topological relationships or limiting their global action capabilities. To bridge this gap, we propose TagaVLM (Topology-Aware Global Action reasoning), an end-to-end framework that explicitly injects topological structures into the VLM backbone. To introduce topological edge information, Spatial Topology Aware Residual Attention (STAR-Att) directly integrates it into the VLM's self-attention mechanism, enabling intrinsic spatial reasoning while preserving pretrained knowledge. To enhance topological node information, an Interleaved Navigation Prompt strengthens node-level visual-text alignment. Finally, with the embedded topological graph, the model is capable of global action reasoning, allowing for robust path correction. On the R2R benchmark, TagaVLM achieves state-of-the-art performance among large-model-based methods, with a Success Rate (SR) of 51.09% and SPL of 47.18 in unseen environments, outperforming prior work by 3.39% in SR and 9.08 in SPL. This demonstrates that, for embodied spatial reasoning, targeted enhancements on smaller open-source VLMs can be more effective than brute-force model scaling. The code can be found on our project page: https://apex-bjut.github.io/Taga-VLM
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TagaVLM, an end-to-end framework for Vision-Language Navigation that explicitly injects topological structures into a VLM backbone. Spatial Topology Aware Residual Attention (STAR-Att) integrates edge information directly into the self-attention mechanism, while Interleaved Navigation Prompts enhance node-level visual-text alignment. With the embedded topological graph, the model performs global action reasoning for path correction. On the R2R benchmark, it reports state-of-the-art results among large-model-based methods with 51.09% Success Rate and 47.18 SPL in unseen environments, outperforming prior work by 3.39% SR and 9.08 SPL. The work concludes that targeted enhancements on smaller open-source VLMs can be more effective than brute-force scaling for embodied spatial reasoning.
Significance. If the reported gains are attributable to the topology-injection mechanisms rather than training variations, the result is significant because it provides evidence that smaller VLMs with targeted architectural changes can achieve superior embodied navigation performance compared to larger models, supporting more efficient and deployable systems. The public code link further strengthens the contribution by enabling direct reproducibility.
major comments (3)
- [Results / Experimental section] The central performance claim (abstract) attributes the 3.39% SR and 9.08 SPL gains to STAR-Att and interleaved prompts, yet the manuscript provides no ablation studies that isolate these components from the training schedule, data choices, or standard fine-tuning; without such controls, it remains possible that the improvements arise from factors unrelated to topology injection.
- [Method / STAR-Att subsection] The description of STAR-Att asserts that it integrates topological edges while preserving pretrained VLM knowledge and avoiding new failure modes in dynamic navigation, but no supporting analysis (e.g., attention-map comparisons before/after modification or evaluation on static VLM tasks) is presented to verify that the residual attention change leaves original patterns intact.
- [Experiments] Full training protocol details—including exact hyperparameters, number of random seeds or runs for statistical significance, and precise baseline re-implementations—are absent, which prevents independent verification of the R2R unseen numbers and the claim that the topology mechanism is the source of the observed margins.
minor comments (2)
- [Abstract] The abstract states that the method outperforms 'prior work' but does not name the specific competing large-model methods or quote their exact scores, which would improve immediate readability.
- [Method] A schematic diagram showing the precise modification to the self-attention computation inside STAR-Att (e.g., how the residual topology term is added to the attention matrix) would clarify the architectural change.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and will revise the paper to provide the requested ablations, analyses, and experimental details.
read point-by-point responses
-
Referee: [Results / Experimental section] The central performance claim (abstract) attributes the 3.39% SR and 9.08 SPL gains to STAR-Att and interleaved prompts, yet the manuscript provides no ablation studies that isolate these components from the training schedule, data choices, or standard fine-tuning; without such controls, it remains possible that the improvements arise from factors unrelated to topology injection.
Authors: We agree that explicit ablations are needed to isolate the contributions of STAR-Att and interleaved prompts. In the revised manuscript we will add a dedicated ablation section reporting results for variants trained with identical schedules and data but with each component removed individually. These controls will directly attribute the observed margins to the topology-injection mechanisms. revision: yes
-
Referee: [Method / STAR-Att subsection] The description of STAR-Att asserts that it integrates topological edges while preserving pretrained VLM knowledge and avoiding new failure modes in dynamic navigation, but no supporting analysis (e.g., attention-map comparisons before/after modification or evaluation on static VLM tasks) is presented to verify that the residual attention change leaves original patterns intact.
Authors: To substantiate the claim that STAR-Att preserves pretrained knowledge, the revision will include attention-map visualizations comparing the original VLM and the modified model on both navigation trajectories and static VLM tasks. We will also report performance on standard non-navigation VLM benchmarks to confirm that original patterns remain intact and no new failure modes are introduced. revision: yes
-
Referee: [Experiments] Full training protocol details—including exact hyperparameters, number of random seeds or runs for statistical significance, and precise baseline re-implementations—are absent, which prevents independent verification of the R2R unseen numbers and the claim that the topology mechanism is the source of the observed margins.
Authors: We will expand the Experiments section with the complete training protocol, listing all hyperparameters, the number of random seeds (three seeds were used for statistical significance), and exact details on baseline re-implementations. The publicly released code already contains the full implementation, enabling direct reproduction of the reported R2R numbers. revision: yes
Circularity Check
No circularity: empirical benchmark results independent of internal definitions
full rationale
The paper's central claims consist of an architectural proposal (STAR-Att residual attention and interleaved node prompts) whose effectiveness is asserted via measured success rates on the external R2R benchmark. No equations, fitted parameters, or predictions are presented that reduce by construction to the inputs; the reported SR/SPL numbers are observed outcomes rather than self-referential derivations. Self-citations, if present, are not load-bearing for the performance numbers themselves.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained VLMs retain useful visual-text alignment when additional attention layers are inserted
invented entities (1)
-
STAR-Att module
no independent evidence
Lean theorems connected to this paper
-
Foundation/AlexanderDualityalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Spatial Topology Aware Residual Attention (STAR-Att) directly integrates [topological edge information] into the VLM's self-attention mechanism... pairwise distance matrix Dt ... Linear(−Dt̂)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
P . Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. S¨ un derhauf, I. Reid, S. Gould, and A. V an Den Hengel, “Vision-and-langua ge nav- igation: Interpreting visually-grounded navigation inst ructions in real environments,” in Proceedings of the IEEE conference on computer vision and pattern recognition , 2018, pp. 3674–3683
work page 2018
-
[2]
The Reg retful Agent: Heuristic-Aided Navigation Through Progress Estim ation
C.-Y . Ma, Z. Wu, G. AlRegib, C. Xiong, and Z. Kira, “The Reg retful Agent: Heuristic-Aided Navigation Through Progress Estim ation.” in Computer Vision and Pattern Recognition (CVPR) , 2019, pp. 6732– 6740
work page 2019
-
[3]
Structu red Scene Memory for Vision-Language Navigation
H. Wang, W. Wang, W. Liang, C. Xiong, and J. Shen, “Structu red Scene Memory for Vision-Language Navigation.” in Computer Vision and Pattern Recognition (CVPR) , 2021, pp. 8455–8464
work page 2021
-
[4]
Think global, act local: Dual-scale graph transformer for vision -and-language navigation,
S. Chen, P .-L. Guhur, M. Tapaswi, C. Schmid, and I. Laptev , “Think global, act local: Dual-scale graph transformer for vision -and-language navigation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2022, pp. 16 537–16 547
work page 2022
-
[5]
B evbert: Multimodal map pre-training for language-guided navigati on,
D. An, Y . Qi, Y . Li, Y . Huang, L. Wang, T. Tan, and J. Shao, “B evbert: Multimodal map pre-training for language-guided navigati on,” Pro- ceedings of the IEEE/CVF International Conference on Compu ter Vision, 2023
work page 2023
-
[6]
Etpnav: Evolving topological planning for vision-langua ge navigation in continuous environments,
D. An, H. Wang, W. Wang, Z. Wang, Y . Huang, K. He, and L. Wang , “Etpnav: Evolving topological planning for vision-langua ge navigation in continuous environments,” IEEE Transactions on Pattern Analysis and Machine Intelligence , 2024
work page 2024
-
[7]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. , “Gpt-4 technical report,” arXiv preprint arXiv:2303.08774 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Q. Team, “Qwen2 technical report,” arXiv preprint arXiv:2407.10671 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)
Z. Y ang, L. Li, K. Lin, J. Wang, C.-C. Lin, Z. Liu, and L. Wan g, “The dawn of lmms: Preliminary explorations with gpt-4v (is ion),” arXiv preprint arXiv:2309.17421 , 2023
work page internal anchor Pith review arXiv 2023
-
[10]
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrap ping language- image pre-training with frozen image encoders and large lan guage models,” in International conference on machine learning . PMLR, 2023, pp. 19 730–19 742
work page 2023
-
[11]
Thinking in space: How multimodal large language models se e, remember, and recall spaces,
J. Y ang, S. Y ang, A. W. Gupta, R. Han, L. Fei-Fei, and S. Xi e, “Thinking in space: How multimodal large language models se e, remember, and recall spaces,” in Proceedings of the Computer Vision and Pattern Recognition Conference , 2025, pp. 10 632–10 643
work page 2025
-
[12]
Navgpt: Explicit reasoning in vision- and-language navigation with large language models,
G. Zhou, Y . Hong, and Q. Wu, “Navgpt: Explicit reasoning in vision- and-language navigation with large language models,” in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 38, no. 7, 2024, pp. 7641–7649
work page 2024
-
[13]
Langnav: Language as a perceptual representation for navi gation,
B. Pan, R. Panda, S. Jin, R. Feris, A. Oliva, P . Isola, and Y . Kim, “Langnav: Language as a perceptual representation for navi gation,” arXiv preprint arXiv:2310.07889 , 2023
-
[14]
Navcot: Boosting llm-based vision-and-lang uage nav- igation via learning disentangled reasoning,
B. Lin, Y . Nie, Z. Wei, J. Chen, S. Ma, J. Han, H. Xu, X. Chan g, and X. Liang, “Navcot: Boosting llm-based vision-and-lang uage nav- igation via learning disentangled reasoning,” IEEE Transactions on Pattern Analysis and Machine Intelligence , 2025
work page 2025
-
[15]
Mapgpt: Map-Guided Prompting with Adaptive Path Planning for Vision-and-Language Navigation,
J. Chen, B. Lin, R. Xu, Z. Chai, X. Liang, and K.-Y . K. Wong , “Mapgpt: Map-Guided Prompting with Adaptive Path Planning for Vision-and-Language Navigation,” in Annual Meeting of the Associa- tion for Computational Linguistics , 2024, pp. 9796–9810
work page 2024
-
[16]
Towar ds learn- ing a generalist model for embodied navigation,
D. Zheng, S. Huang, L. Zhao, Y . Zhong, and L. Wang, “Towar ds learn- ing a generalist model for embodied navigation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni tion, 2024, pp. 13 624–13 634
work page 2024
-
[17]
Obje ct- and-action aware model for visual language navigation,
Y . Qi, Z. Pan, S. Zhang, A. van den Hengel, and Q. Wu, “Obje ct- and-action aware model for visual language navigation,” in European conference on computer vision . Springer, 2020, pp. 303–317
work page 2020
-
[18]
Langua ge and visual entity relationship graph for agent navigation,
Y . Hong, C. Rodriguez, Y . Qi, Q. Wu, and S. Gould, “Langua ge and visual entity relationship graph for agent navigation,” Advances in Neural Information Processing Systems, vol. 33, pp. 7685–7696, 2020
work page 2020
-
[19]
Neighbo r-view enhanced model for vision and language navigation,
D. An, Y . Qi, Y . Huang, Q. Wu, L. Wang, and T. Tan, “Neighbo r-view enhanced model for vision and language navigation,” in Proceedings of the 29th ACM International Conference on Multimedia , 2021, pp. 5101–5109
work page 2021
-
[20]
X. Wang, Q. Huang, A. Celikyilmaz, J. Gao, D. Shen, Y .-F. Wang, W. Y . Wang, and L. Zhang, “Reinforced cross-modal matching a nd self-supervised imitation learning for vision-language n avigation,” in Proceedings of the IEEE/CVF conference on computer vision a nd pattern recognition, 2019, pp. 6629–6638
work page 2019
-
[21]
Learning to Navigate Unseen Environments: Back Translation with Environmental Dropout
H. Tan, L. Y u, and M. Bansal, “Learning to navigate unsee n environ- ments: Back translation with environmental dropout,” arXiv preprint arXiv:1904.04195, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[22]
Scaling data generation in vision-and- language navigation,
Z. Wang, J. Li, Y . Hong, Y . Wang, Q. Wu, M. Bansal, S. Gould , H. Tan, and Y . Qiao, “Scaling data generation in vision-and- language navigation,” in Proceedings of the IEEE/CVF international conference on computer vision , 2023, pp. 12 009–12 020
work page 2023
-
[23]
Towards learni ng a generic agent for vision-and-language navigation via pre- training,
W. Hao, C. Li, X. Li, L. Carin, and J. Gao, “Towards learni ng a generic agent for vision-and-language navigation via pre- training,” in Proceedings of the IEEE/CVF conference on computer vision a nd pattern recognition, 2020, pp. 13 137–13 146
work page 2020
-
[24]
Envedit: Environment Edit ing for Vision-and-Language Navigation
J. Li, H. Tan, and M. Bansal, “Envedit: Environment Edit ing for Vision-and-Language Navigation.” in Computer Vision and Pattern Recognition (CVPR) , 2022, pp. 15 386–15 396
work page 2022
-
[25]
Hop: His tory- and-order aware pre-training for vision-and-language nav igation,
Y . Qiao, Y . Qi, Y . Hong, Z. Y u, P . Wang, and Q. Wu, “Hop: His tory- and-order aware pre-training for vision-and-language nav igation,” in Proceedings of the IEEE/CVF Conference on Computer Vision a nd Pattern Recognition, 2022, pp. 15 418–15 427
work page 2022
-
[26]
History aware multimodal transformer for vision-and-language navigation,
S. Chen, P .-L. Guhur, C. Schmid, and I. Laptev, “History aware multimodal transformer for vision-and-language navigation,” Advances in neural information processing systems , vol. 34, pp. 5834–5847, 2021
work page 2021
-
[27]
Target-driven structured transformer planner for vision- language navigation,
Y . Zhao, J. Chen, C. Gao, W. Wang, L. Y ang, H. Ren, H. Xia, and S. Liu, “Target-driven structured transformer planner for vision- language navigation,” in Proceedings of the 30th ACM international conference on multimedia , 2022, pp. 4194–4203
work page 2022
-
[28]
Discuss before movin g: Visual language navigation via multi-expert discussions,
Y . Long, X. Li, W. Cai, and H. Dong, “Discuss before movin g: Visual language navigation via multi-expert discussions, ” in 2024 IEEE International Conference on Robotics and Automation ( ICRA). IEEE, 2024, pp. 17 380–17 387
work page 2024
-
[29]
Visual simultaneous localization and mapping: a survey,
J. Fuentes-Pacheco, J. Ruiz-Ascencio, and J. M. Rend´ o n-Mancha, “Visual simultaneous localization and mapping: a survey,” Artificial intelligence review, vol. 43, no. 1, pp. 55–81, 2015
work page 2015
-
[30]
Visual odometry and mapping for autonomous fligh t using an rgb-d camera,
A. S. Huang, A. Bachrach, P . Henry, M. Krainin, D. Matura na, D. Fox, and N. Roy, “Visual odometry and mapping for autonomous fligh t using an rgb-d camera,” in Robotics Research: The 15th International Symposium ISRR . Springer, 2016, pp. 235–252
work page 2016
-
[31]
Chasing ghosts: Instruction following as bayesian state tracking,
P . Anderson, A. Shrivastava, D. Parikh, D. Batra, and S. Lee, “Chasing ghosts: Instruction following as bayesian state tracking, ” Advances in neural information processing systems , vol. 32, 2019
work page 2019
-
[32]
Navig ation in hy- brid metric-topological maps,
K. Konolige, E. Marder-Eppstein, and B. Marthi, “Navig ation in hy- brid metric-topological maps,” in 2011 IEEE International Conference on Robotics and Automation . IEEE, 2011, pp. 3041–3047
work page 2011
-
[33]
Cross-modal map learning for vi sion and language navigation,
G. Georgakis, K. Schmeckpeper, K. Wanchoo, S. Dan, E. Mi ltsakaki, D. Roth, and K. Daniilidis, “Cross-modal map learning for vi sion and language navigation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , 2022, pp. 15 460–15 470
work page 2022
-
[34]
Topological planning with transformers for vision-and-l anguage nav- igation,
K. Chen, J. K. Chen, J. Chuang, M. V´ azquez, and S. Savare se, “Topological planning with transformers for vision-and-l anguage nav- igation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2021, pp. 11 276–11 286
work page 2021
-
[35]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. La chaux, T. Lacroix, B. Rozi` ere, N. Goyal, E. Hambro, F. Azhar, et al., “Llama: Open and efficient foundation language models,” arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
LLaVA-OneVision: Easy Visual Task Transfer
B. Li, Y . Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang , P . Zhang, Y . Li, Z. Liu, et al. , “Llava-onevision: Easy visual task transfer,” arXiv preprint arXiv:2408.03326 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenbor n, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gel ly, J. Uszkoreit, and N. Houlsby, “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” in International Con- ference on Learning Representations , vol. abs/2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[38]
S peaker- follower models for vision-and-language navigation,
D. Fried, R. Hu, V . Cirik, A. Rohrbach, J. Andreas, L.-P . Morency, T. Berg-Kirkpatrick, K. Saenko, D. Klein, and T. Darrell, “S peaker- follower models for vision-and-language navigation,” Advances in neural information processing systems , vol. 31, 2018
work page 2018
-
[39]
Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
S. K. Ramakrishnan, A. Gokaslan, E. Wijmans, O. Maksyme ts, A. Clegg, J. Turner, E. Undersander, W. Galuba, A. Westbury, A. X. Chang, et al., “Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai,” arXiv preprint arXiv:2109.08238 , 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[40]
Sigmo id loss for language image pre-training,
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmo id loss for language image pre-training,” in Proceedings of the IEEE/CVF international conference on computer vision , 2023, pp. 11 975–11 986
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.