Recognition: no theorem link
Decoding the Pulse of Reasoning VLMs in Multi-Image Understanding Tasks
Pith reviewed 2026-05-15 16:00 UTC · model grok-4.3
The pith
Reasoning VLMs show diffuse attention pulses and positional bias during multi-image CoT, which PulseFocus fixes by structuring reasoning into plan-focus blocks with soft attention gating.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
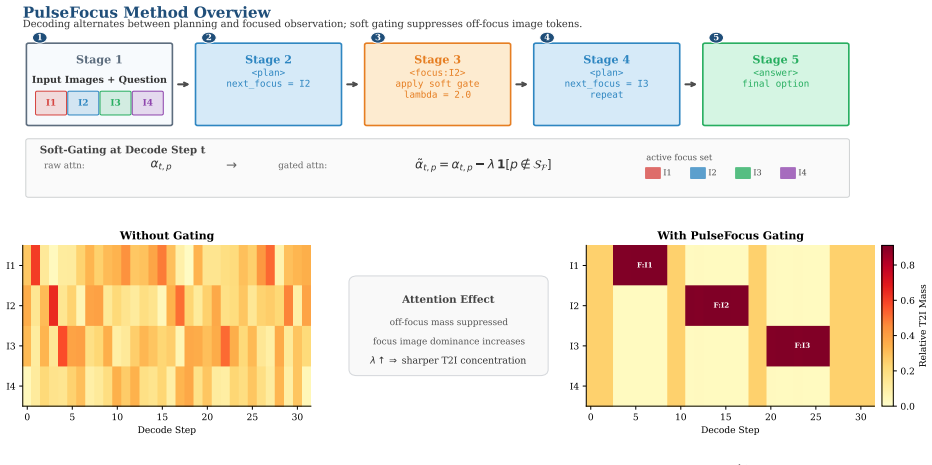
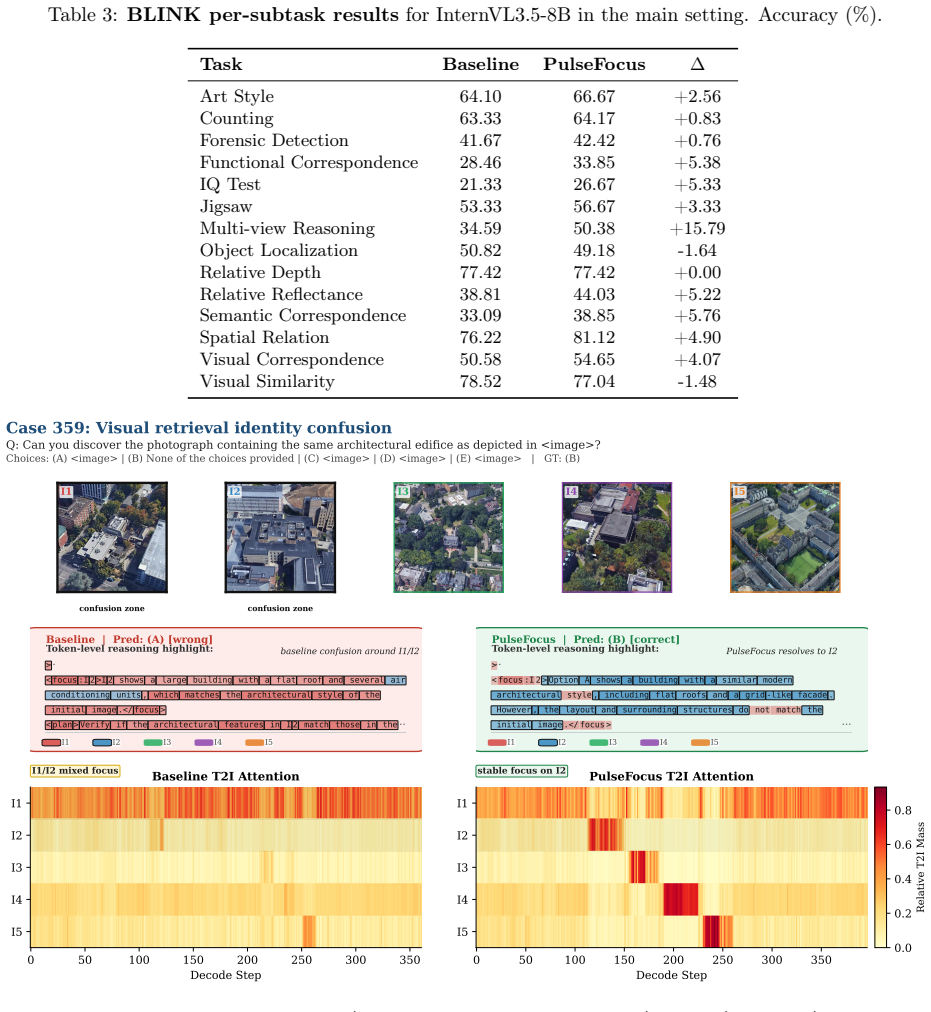
During chain-of-thought generation, the text-to-image attention of reasoning VLMs exhibits diffuse pulses that fail to concentrate on task-relevant images and a systematic positional bias in attention allocation across images. PulseFocus structures CoT reasoning into interleaved plan/focus blocks with soft attention gating. By forcing the model to explicitly plan which image to examine and then gating decode-time attention to the referenced image, PulseFocus sharpens attention focus and yields consistent improvements on multi-image benchmarks like BLINK benchmark (+3.7%) and MuirBench (+1.07%).
What carries the argument
PulseFocus, a method that interleaves explicit planning steps specifying which image to examine next with focus steps that apply soft gating to restrict decode-time attention to the referenced image.
If this is right
- Multi-image benchmark scores rise without any model retraining.
- Attention maps during decoding become more concentrated on the images the model claims to be examining.
- The same structure can be applied at inference time to existing reasoning VLMs.
- Explicit planning steps reduce the effect of positional bias in attention allocation.
- The approach works by modifying only the generation process rather than the model weights.
Where Pith is reading between the lines
- Similar plan-focus structuring could be tested on video or sequential visual inputs where attention also tends to drift.
- The pulse phenomenon may serve as a diagnostic signal for identifying when a VLM is likely to make reasoning errors on complex visual inputs.
- Combining the gating step with other inference-time interventions, such as self-consistency checks, might produce additive gains.
- The finding suggests that many current VLM failures stem from how attention is scheduled rather than from missing visual knowledge.
Load-bearing premise
The diffuse attention pulses and positional bias are the main causes of poor multi-image performance, and forcing the plan-focus structure with gating will fix them without creating new errors or hurting other capabilities.
What would settle it
Applying PulseFocus to a multi-image reasoning task and measuring no accuracy gain or the appearance of new error patterns that are not explained by attention diffusion.
Figures



read the original abstract
Multi-image reasoning remains a significant challenge for vision-language models (VLMs). We investigate a previously overlooked phenomenon: during chain-of-thought (CoT) generation, the text-to-image (T2I) attention of reasoning VLMs exhibits diffuse "pulses": sporadic and unfocused attention patterns that fail to concentrate on task-relevant images. We further reveal a systematic positional bias in attention allocation across images. Motivated by these observations, we propose PulseFocus, a training-free, inference-time method that structures CoT reasoning into interleaved plan/focus blocks with soft attention gating. By forcing the model to explicitly plan which image to examine and then gating decode-time attention to the referenced image, PulseFocus sharpens attention focus and yields consistent improvements on multi-image benchmarks like BLINK benchmark (+3.7%) and MuirBench (+1.07%).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper observes diffuse 'pulses' and positional bias in text-to-image attention during chain-of-thought reasoning in VLMs on multi-image tasks. It proposes PulseFocus, a training-free inference-time intervention that structures CoT into interleaved plan/focus blocks and applies soft attention gating to the referenced image, reporting gains of +3.7% on BLINK and +1.07% on MuirBench.
Significance. If the central claim holds after detailed verification, the work would establish a lightweight, no-training method for improving multi-image reasoning by directly modulating attention patterns, offering practical value for existing VLMs and empirical insight into how attention diffusion contributes to errors.
major comments (2)
- Abstract: the description of the soft attention gating mechanism provides no implementation details, mathematical formulation, or specification of required model internals, which is load-bearing for reproducing the method and confirming it addresses the observed pulses without introducing coherence artifacts.
- §4 (Experiments): the reported benchmark improvements lack ablation controls isolating the gating component from the plan/focus structure, as well as statistical significance tests, undermining attribution of gains specifically to the proposed mechanism.
minor comments (1)
- Abstract: the term 'soft attention gating' is used without a formal definition or pseudocode, which would aid clarity even if the full implementation is deferred to a later section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript to improve reproducibility and experimental rigor.
read point-by-point responses
-
Referee: Abstract: the description of the soft attention gating mechanism provides no implementation details, mathematical formulation, or specification of required model internals, which is load-bearing for reproducing the method and confirming it addresses the observed pulses without introducing coherence artifacts.
Authors: We agree that the abstract should include more specifics on the gating mechanism. In the revised version we have expanded the abstract to state that soft attention gating is implemented as a multiplicative mask G on the T2I attention matrix at each decode step, where G is derived from the plan block's image reference and applied as A' = softmax((QK^T / sqrt(d_k)) ⊙ G). The method requires only access to the model's internal cross-attention weights during inference (standard in open VLMs) and does not alter the underlying model parameters. Qualitative checks in the appendix confirm no coherence degradation. revision: yes
-
Referee: §4 (Experiments): the reported benchmark improvements lack ablation controls isolating the gating component from the plan/focus structure, as well as statistical significance tests, undermining attribution of gains specifically to the proposed mechanism.
Authors: We acknowledge this limitation in the original submission. The revised manuscript adds a dedicated ablation subsection (4.3) that evaluates (i) plan/focus structure alone, (ii) gating alone, and (iii) the full PulseFocus combination. Results show gating contributes the majority of the gain (+2.4% on BLINK). We also report bootstrap-based statistical significance (p < 0.05) for all main results across 5 random seeds, now included in Table 2. revision: yes
Circularity Check
No significant circularity: empirical observation followed by training-free intervention
full rationale
The paper's chain consists of direct observational claims about diffuse T2I attention pulses and positional bias during CoT, followed by a proposed training-free method (PulseFocus) that interleaves plan/focus blocks and applies soft gating at decode time. No equations, parameter fits, or predictions are presented that reduce to the inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The reported gains (+3.7% on BLINK, +1.07% on MuirBench) are framed as empirical outcomes of the intervention, not as derivations that presuppose the result. The argument is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs exhibit modifiable attention mechanisms during CoT that can be intervened upon at inference time via gating without retraining
invented entities (1)
-
PulseFocus method
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Multi-layer learnable attention mask for multimodal tasks.arXiv preprint arXiv:2406.02761, 2024
Wayner Barrios and SouYoung Jin. Multi-layer learnable attention mask for multimodal tasks.arXiv preprint arXiv:2406.02761, 2024
-
[3]
Anurag Das, Adrian Bulat, Alberto Baldrati, Ioannis Maniadis Metaxas, Bernt Schiele, Georgios Tzimiropoulos, and Brais Martinez. More images, more problems? a controlled analysis of vlm failure modes.arXiv preprint arXiv:2601.07812, 2026
-
[4]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Computer Vision, pages 148–166. Springer, 2024
work page 2024
-
[5]
Junqi Ge, Ziyi Chen, Jintao Lin, Jinguo Zhu, Xihui Liu, Jifeng Dai, and Xizhou Zhu. V2pe: Improving multimodal long-context capability of vision-language models with variable visual position encoding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 21070–21084, 2025
work page 2025
-
[6]
Mantis: Interleaved multi-image instruction tuning
Dongfu Jiang, Xuan He, Huaye Zeng, Cong Wei, Max Ku, Qian Liu, and Wenhu Chen. Mantis: Interleaved multi-image instruction tuning.arXiv preprint arXiv:2405.01483, 2024
-
[7]
Control large language models via divide and conquer
Bingxuan Li, Yiwei Wang, Tao Meng, Kai-Wei Chang, and Nanyun Peng. Control large language models via divide and conquer. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 15240–15256, 2024
work page 2024
-
[8]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Divide and conquer: Exploring language-centric tree reasoning for video question-answering
Zhaohe Liao, Jiangtong Li, Siyu Sun, Qingyang Liu, Fengshun Xiao, Tianjiao Li, Qiang Zhang, Guang Chen, Li Niu, Changjun Jiang, et al. Divide and conquer: Exploring language-centric tree reasoning for video question-answering. InForty-second International Conference on Machine Learning, 2025. 8
work page 2025
-
[10]
Mibench: Evaluating multimodal large language models over multiple images
Haowei Liu, Xi Zhang, Haiyang Xu, Yaya Shi, Chaoya Jiang, Ming Yan, Ji Zhang, Fei Huang, Chunfeng Yuan, Bing Li, et al. Mibench: Evaluating multimodal large language models over multiple images. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 22417–22428, 2024
work page 2024
-
[11]
Fanqing Meng, Jin Wang, Chuanhao Li, Quanfeng Lu, Hao Tian, Jiaqi Liao, Xizhou Zhu, Jifeng Dai, Yu Qiao, Ping Luo, et al. Mmiu: Multimodal multi-image understanding for evaluating large vision-language models.arXiv preprint arXiv:2408.02718, 2024
-
[12]
Rethinking causal mask attention for vision-language inference.arXiv preprint arXiv:2505.18605, 2025
Xiaohuan Pei, Tao Huang, YanXiang Ma, and Chang Xu. Rethinking causal mask attention for vision-language inference.arXiv preprint arXiv:2505.18605, 2025
-
[13]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaugh- lin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding
Fei Wang, Xingyu Fu, James Y Huang, Zekun Li, Qin Liu, Xiaogeng Liu, Mingyu Derek Ma, Nan Xu, Wenxuan Zhou, Kai Zhang, et al. Muirbench: A comprehensive benchmark for robust multi-image understanding.arXiv preprint arXiv:2406.09411, 2024
work page internal anchor Pith review arXiv 2024
-
[15]
Internvl: Scaling up vision foundation models and aligning for generic visual- linguistic tasks
Wenhai Wang, Zhe Chen, Yangzhou Liu, Yue Cao, Weiyun Wang, Xizhou Zhu, Lewei Lu, Tong Lu, Yu Qiao, and Jifeng Dai. Internvl: Scaling up vision foundation models and aligning for generic visual- linguistic tasks. InLarge Vision-Language Models: Pre-training, Prompting, and Applications, pages 23–57. Springer, 2025
work page 2025
-
[16]
Tsung-Han Wu, Giscard Biamby, Jerome Quenum, Ritwik Gupta, Joseph E Gonzalez, Trevor Darrell, and David M Chan. Visual haystacks: A vision-centric needle-in-a-haystack benchmark.arXiv preprint arXiv:2407.13766, 2024
-
[17]
Roy Xie, David Qiu, Deepak Gopinath, Dong Lin, Yanchao Sun, Chong Wang, Saloni Potdar, and Bhuwan Dhingra. Interleaved reasoning for large language models via reinforcement learning.arXiv preprint arXiv:2505.19640, 2025
-
[18]
MMSI-Bench: A benchmark for multi-image spatial intelligence.arXiv preprint arXiv:2505.23764, 2025
Sihan Yang, Runsen Xu, Yiman Xie, Sizhe Yang, Mo Li, Jingli Lin, Chenming Zhu, Xiaochen Chen, Haodong Duan, Xiangyu Yue, et al. Mmsi-bench: A benchmark for multi-image spatial intelligence. arXiv preprint arXiv:2505.23764, 2025
-
[19]
Idealgpt: Iteratively decomposing vision and language reasoning via large language models
Haoxuan You, Rui Sun, Zhecan Wang, Long Chen, Gengyu Wang, Hammad Ayyubi, Kai-Wei Chang, and Shih-Fu Chang. Idealgpt: Iteratively decomposing vision and language reasoning via large language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 11289–11303, 2023
work page 2023
-
[20]
Guanghao Zhang, Tao Zhong, Yan Xia, Mushui Liu, Zhelun Yu, Haoyuan Li, Wanggui He, Fangxun Shu, Dong She, Yi Wang, et al. Cmmcot: Enhancing complex multi-image comprehension via multi-modal chain-of-thought and memory augmentation.arXiv preprint arXiv:2503.05255, 2025. 9
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.