Recognition: 2 theorem links
· Lean TheoremEvoESAP: Non-Uniform Expert Pruning for Sparse MoE
Pith reviewed 2026-05-15 14:31 UTC · model grok-4.3
The pith
Evolutionary search finds non-uniform layer budgets that improve pruned sparse MoE generation performance
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Decoupling within-layer expert ranking from across-layer budget allocation allows an evolutionary search, guided by the bounded Expected Speculative Acceptance Proxy, to locate non-uniform sparsity patterns that preserve more of the original model's open-ended generation behavior than uniform patterns at identical global sparsity.
What carries the argument
EvoESAP evolutionary search over layer-wise sparsity allocations, which ranks candidates using the Expected Speculative Acceptance Proxy (ESAP) while keeping the within-layer expert order fixed.
If this is right
- At fixed total sparsity the model retains higher accuracy on math and open-ended generation than uniform pruning allows.
- Multiple-choice accuracy remains competitive, so the gains do not trade off one capability for another.
- Any existing within-layer pruning criterion can be paired with the non-uniform allocation search without modification.
- Search cost stays low because ESAP is stable and bounded and does not require running full autoregressive decoding for every candidate.
Where Pith is reading between the lines
- The same proxy-guided search could be applied at finer granularity to choose both which experts and how many per layer in a single joint optimization.
- Allocations discovered on general data might be further tuned on task-specific validation sets for additional targeted gains.
- Similar bounded proxies could be derived for other MoE compression axes such as expert capacity or routing temperature.
Load-bearing premise
The ESAP proxy computed from teacher-forced speculative acceptance ranks pruning allocations in the same order as their actual performance under full autoregressive open-ended generation.
What would settle it
Full autoregressive evaluation on the allocations returned by EvoESAP shows no gain or a loss relative to uniform pruning on the same open-ended generation tasks and model sizes.
Figures


read the original abstract
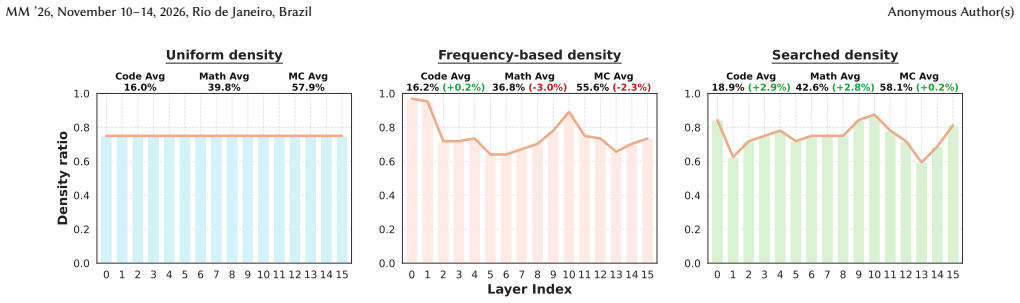
Sparse Mixture-of-Experts (SMoE) language models achieve strong capability at low per-token compute, yet deployment remains constrained by memory footprint and throughput because the full expert pool must still be stored and served. Post-training expert pruning reduces this cost, but most methods focus on which experts to prune within each layer and default to a uniform layer-wise sparsity allocation, even though the layer-wise allocation can strongly affect performance. We decouple pruning into within-layer expert ranking and across-layer budget allocation, and introduce \textbf{E}xpected \textbf{S}peculative \textbf{A}cceptance \textbf{P}roxy (\textbf{ESAP}), a speculative-decoding-inspired, teacher-forced metric that measures how well a pruned model matches the full model without costly autoregressive decoding. ESAP is bounded and stable, enabling cheap comparison of many candidates. Building on ESAP, we propose EvoESAP, an evolutionary search framework that finds an improved non-uniform layer-wise sparsity allocation under a fixed global budget while holding the within-layer pruning order fixed, making it a plug-and-play method for criteria such as Frequency, EAN, SEER, and REAP. Across 7B--30B SMoE LLMs at 25\% and 50\% sparsity, EvoESAP consistently discovers non-uniform allocations that improve open-ended generation (up to \textbf{+19.6\%} on MATH-500 at 50\% sparsity) while preserving competitive multiple-choice accuracy compared with uniform pruning at the same sparsity. Code is available at https://github.com/ZongfangLiu/EvoESAP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript decouples expert pruning in Sparse Mixture-of-Experts (SMoE) models into within-layer ranking and across-layer budget allocation. It introduces the Expected Speculative Acceptance Proxy (ESAP), a teacher-forced, speculative-decoding-inspired metric for cheaply ranking pruning allocations, and EvoESAP, an evolutionary search that optimizes non-uniform layer-wise sparsity budgets under a fixed global sparsity target while holding within-layer expert order fixed. The central claim is that EvoESAP yields allocations that improve open-ended generation (up to +19.6% on MATH-500 at 50% sparsity) relative to uniform pruning across 7B–30B models while preserving competitive multiple-choice accuracy; the method is presented as plug-and-play for existing ranking criteria such as Frequency, EAN, SEER, and REAP.
Significance. If the reported gains are robust, the work provides a practical, low-cost way to improve post-training pruning of deployed SMoE models by optimizing layer-wise budgets rather than defaulting to uniformity. The bounded, stable ESAP proxy and code release are concrete strengths that lower the barrier to adoption. The decoupling insight is useful even if the specific search algorithm is later refined.
major comments (3)
- [Abstract] Abstract and results section: the headline +19.6% MATH-500 gain at 50% sparsity is presented without reported run counts, standard deviations, or multiple-testing correction; because this number is the primary evidence for the superiority of non-uniform allocations, the absence of these controls makes the central empirical claim difficult to assess.
- [ESAP definition] ESAP definition and validation: the manuscript defines ESAP via teacher-forced speculative acceptance but provides no quantitative correlation (e.g., rank correlation or scatter plot) between ESAP scores and full autoregressive open-ended metrics; if this correlation is weak, the evolutionary search may be optimizing a misaligned objective.
- [Method] Separability assumption in the method: the paper fixes within-layer expert ranking order and searches only over layer-wise budgets, yet offers no ablation comparing this to joint optimization of ranking and allocation; the reported gains could be capped by this design choice.
minor comments (2)
- [Notation] Clarify the precise mathematical definition of ESAP (including any temperature or acceptance threshold) in the main text rather than relying solely on the high-level abstract description.
- [Experiments] Add a brief table or figure caption note on the exact sparsity targets (25% and 50%) and model sizes used for each reported number.
Simulated Author's Rebuttal
Thank you for the detailed and constructive review. We address each major comment point by point below and will revise the manuscript to strengthen the empirical claims and add requested analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract and results section: the headline +19.6% MATH-500 gain at 50% sparsity is presented without reported run counts, standard deviations, or multiple-testing correction; because this number is the primary evidence for the superiority of non-uniform allocations, the absence of these controls makes the central empirical claim difficult to assess.
Authors: We agree that reporting run counts, standard deviations, and addressing multiple-testing concerns would strengthen the central claim. In the revised manuscript we will rerun the key open-ended generation experiments (including MATH-500 at 50% sparsity) over at least three independent random seeds, report means with standard deviations, and update both the abstract and results section. We will also note the total number of configurations evaluated to contextualize the headline figure. revision: yes
-
Referee: [ESAP definition] ESAP definition and validation: the manuscript defines ESAP via teacher-forced speculative acceptance but provides no quantitative correlation (e.g., rank correlation or scatter plot) between ESAP scores and full autoregressive open-ended metrics; if this correlation is weak, the evolutionary search may be optimizing a misaligned objective.
Authors: We acknowledge that explicit validation of the ESAP proxy against full autoregressive metrics is important. In the revision we will add a new analysis (in Section 3 and the appendix) that reports Spearman rank correlation and a scatter plot between ESAP scores and actual open-ended generation performance (MATH-500 and GSM8K) across a diverse set of pruning allocations on the 7B model. This will quantify the alignment of the proxy objective. revision: yes
-
Referee: [Method] Separability assumption in the method: the paper fixes within-layer expert ranking order and searches only over layer-wise budgets, yet offers no ablation comparing this to joint optimization of ranking and allocation; the reported gains could be capped by this design choice.
Authors: The separability assumption is intentional to preserve plug-and-play compatibility with any existing within-layer ranking criterion. We will add an ablation study in the revised manuscript that compares the current EvoESAP approach against a joint optimization of both ranking and allocation on the 7B model, reporting the additional performance delta (if any) to quantify the potential cap on gains. revision: yes
Circularity Check
No significant circularity: ESAP proxy and final benchmarks are independent
full rationale
The paper defines ESAP as a standalone teacher-forced speculative acceptance metric, employs it only to guide evolutionary search over layer-wise budgets (with within-layer order held fixed), and then measures the resulting allocations on external benchmarks (MATH-500, multiple-choice accuracy). These benchmark numbers are not computed from the ESAP objective or any fitted parameter; they are direct evaluations. No self-citation chain, ansatz smuggling, or renaming of known results appears in the derivation. The central claim therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
Foundation.RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Across 7B–30B SMoE LLMs at 25% and 50% sparsity, EvoESAP consistently discovers non-uniform allocations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
HodgeCover: Higher-Order Topological Coverage Drives Compression of Sparse Mixture-of-Experts
HodgeCover isolates the harmonic kernel of a simplicial Laplacian on an expert 2-complex to identify irreducible merge cycles and selects experts for aggressive compression, matching or exceeding baselines on open-wei...
-
Model Compression with Exact Budget Constraints via Riemannian Manifolds
The budget constraint in discrete model compression defines a Riemannian manifold allowing exact-constraint first-order optimization via Riemannian Constrained Optimization (RCO) without extra hyperparameters.
Reference graph
Works this paper leans on
- [1]
-
[2]
Luisa Bentivogli, Peter Clark, Ido Dagan, and Danilo Giampiccolo. 2009. The Fifth PASCAL Recognizing Textual Entailment Challenge.TAC7, 8 (2009), 1
work page 2009
-
[3]
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Lau- rent Sifre, and John Jumper. 2023. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [4]
- [5]
-
[6]
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. Boolq: Exploring the surprising difficulty of natural yes/no questions.arXiv preprint arXiv:1905.10044(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[7]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
DeepSeek-AI. 2024. DeepSeek-V2: A Strong, Economical, and Efficient Mixture- of-Experts Language Model. arXiv:2405.04434 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research23, 120 (2022), 1–39
work page 2022
-
[11]
Leo Gao, Jonathan Tow, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Kyle McDonell, Niklas Muennighoff, et al
-
[12]
A framework for few-shot language model evaluation.Zenodo(2021)
work page 2021
- [13]
- [14]
-
[15]
Shwai He, Run-Ze Fan, Liang Ding, Li Shen, Tianyi Zhou, and Dacheng Tao
- [16]
- [17]
-
[18]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[19]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022), 3
work page 2022
- [21]
-
[22]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. 2024. Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [23]
-
[24]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al . 2024. Mixtral of experts.arXiv preprint arXiv:2401.04088(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Yeskendir Koishekenov, Alexandre Berard, and Vassilina Nikoulina. 2023. Memory-efficient nllb-200: Language-specific expert pruning of a massively mul- tilingual machine translation model. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 3567–3585
work page 2023
-
[26]
Mike Lasby, Ivan Lazarevich, Nish Sinnadurai, Sean Lie, Yani Ioannou, and Vithur- san Thangarasa. 2025. REAP the Experts: Why Pruning Prevails for One-Shot MoE compression.arXiv preprint arXiv:2510.13999(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Jaeseong Lee, Seung-won Hwang, Aurick Qiao, Daniel F Campos, Zhewei Yao, and Yuxiong He. 2025. Stun: Structured-then-unstructured pruning for scalable moe pruning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 13660–13676
work page 2025
- [28]
-
[29]
Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2023. Fast inference from transformers via speculative decoding. InInternational Conference on Machine Learning. PMLR, 19274–19286
work page 2023
-
[30]
Lujun Li, Zhu Qiyuan, Jiacheng Wang, Wei Li, Hao Gu, Sirui Han, and Yike Guo
- [31]
- [32]
-
[33]
Wei Li, Lujun Li, Hao Gu, You-Liang Huang, Mark G Lee, Shengjie Sun, Wei Xue, and Yike Guo. 2025. MoE-SVD: Structured Mixture-of-Experts LLMs Compres- sion via Singular Value Decomposition. InInternational Conference on Machine Learning. PMLR, 35209–35230
work page 2025
-
[34]
Bill Yuchen Lin, Yuntian Deng, Khyathi Chandu, Faeze Brahman, Abhilasha Ravichander, Valentina Pyatkin, Nouha Dziri, Ronan Le Bras, and Yejin Choi
- [35]
-
[36]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Enshu Liu, Junyi Zhu, Zinan Lin, Xuefei Ning, Matthew B Blaschko, Shengen Yan, Guohao Dai, Huazhong Yang, and Yu Wang. 2024. Efficient expert pruning for sparse mixture-of-experts language models: Enhancing performance and reducing inference costs.arXiv preprint arXiv:2407.00945(2024)
- [38]
-
[39]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2023. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation.Advances in Neural Information Processing Systems 36 (2023), 21558–21572
work page 2023
-
[40]
Shiwei Liu, Tianlong Chen, Xiaohan Chen, Li Shen, Decebal Constantin Mocanu, Zhangyang Wang, and Mykola Pechenizkiy. 2022. The unreasonable effectiveness of random pruning: Return of the most naive baseline for sparse training.arXiv MM ’26, November 10–14, 2026, Rio de Janeiro, Brazil Anonymous Author(s) preprint arXiv:2202.02643(2022)
-
[41]
Haiquan Lu, Yefan Zhou, Shiwei Liu, Zhangyang Wang, Michael W Mahoney, and Yaoqing Yang. 2024. Alphapruning: Using heavy-tailed self regularization theory for improved layer-wise pruning of large language models.Advances in neural information processing systems37 (2024), 9117–9152
work page 2024
- [42]
-
[43]
Meta AI. 2025. The Llama 4 Herd: The Beginning of a New Era of Natively Multi- modal AI Innovation. https://ai.meta.com/blog/llama-4-multimodal-intelligence/
work page 2025
-
[44]
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. 2018. Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv preprint arXiv:1809.02789(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [45]
- [46]
-
[47]
OpenAI. 2025. gpt-oss-120b & gpt-oss-20b Model Card. arXiv:2508.10925 [cs.CL] https://arxiv.org/abs/2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2021. Winogrande: An adversarial winograd schema challenge at scale.Commun. ACM 64, 9 (2021), 99–106
work page 2021
-
[49]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [50]
-
[51]
Shengkun Tang, Oliver Sieberling, Eldar Kurtic, Zhiqiang Shen, and Dan Alistarh
-
[52]
arXiv preprint arXiv:2502.07780(2025)
Darwinlm: Evolutionary structured pruning of large language models. arXiv preprint arXiv:2502.07780(2025)
-
[53]
Baidu ERNIE Team. 2025. ERNIE 4.5 Technical Report
work page 2025
-
[54]
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al . 2025. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
ModelScope Team. 2024. EvalScope: Evaluation Framework for Large Models. https://github.com/modelscope/evalscope
work page 2024
-
[56]
Qwen Team. 2024. Qwen1.5-MoE: Matching 7B Model Performance with 1/3 Activated Parameters. https://qwenlm.github.io/blog/qwen-moe/
work page 2024
-
[57]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
work page 2017
- [58]
-
[59]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [60]
- [61]
-
[62]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi
-
[63]
Hellaswag: Can a machine really finish your sentence?arXiv preprint arXiv:1905.07830(2019)
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[64]
Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al. 2025. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models.arXiv preprint arXiv:2508.06471 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Zeliang Zhang, Xiaodong Liu, Hao Cheng, Chenliang Xu, and Jianfeng Gao
-
[66]
InFindings of the Association for Computational Linguistics: ACL 2025
Diversifying the expert knowledge for task-agnostic pruning in sparse mixture-of-experts. InFindings of the Association for Computational Linguistics: ACL 2025. 86–102
work page 2025
-
[67]
Yixiao Zhou, Ziyu Zhao, Dongzhou Cheng, Jie Gui, Yi Yang, Fei Wu, Yu Cheng, Hehe Fan, et al. 2025. Dropping Experts, Recombining Neurons: Retraining-Free Pruning for Sparse Mixture-of-Experts LLMs.arXiv preprint arXiv:2509.10377 (2025). EvoESAP: Non-Uniform Expert Pruning for Sparse MoE MM ’26, November 10–14, 2026, Rio de Janeiro, Brazil A Evolutionary S...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.