Recognition: 2 theorem links
· Lean TheoremHodgeCover: Higher-Order Topological Coverage Drives Compression of Sparse Mixture-of-Experts
Pith reviewed 2026-05-15 05:50 UTC · model grok-4.3
The pith
Hodge decomposition of KL merge barriers on a 2-complex isolates the harmonic kernel that blocks joint merging of expert triples in sparse MoE layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
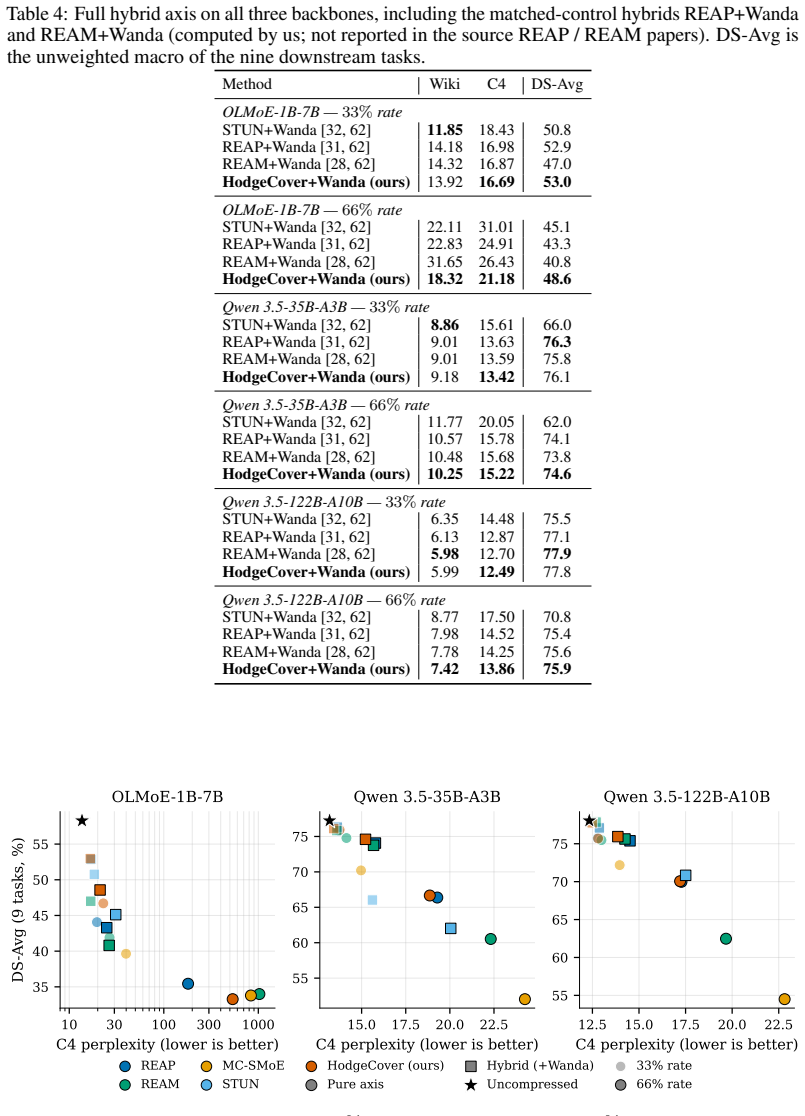
The obstruction to compression is the harmonic kernel of the simplicial Laplacian on a 2-complex whose vertices are experts, whose edges carry KL merge barriers, and whose faces carry triplet barriers; Hodge-decomposing the edge-barrier signal isolates the kernel exactly. HodgeCover greedily covers the harmonic-critical edges and triplet-critical triangles, and a hybrid variant pairs it with off-the-shelf weight pruning on survivors. On three open-weight Sparse MoE backbones under aggressive expert reduction, this approach matches state-of-the-art learning-free baselines on the expert-reduction axis, leads on the aggressive-compression frontier of the hybrid axis, and uniquely balances the 1
What carries the argument
The harmonic kernel of the simplicial Laplacian on the expert 2-complex, which precisely identifies the irreducible cycles that prevent joint mergeability of expert triples.
Load-bearing premise
The KL merge barriers placed on edges and faces of the 2-complex faithfully capture the joint mergeability of expert triples so that the harmonic kernel identifies the cycles blocking compression.
What would settle it
Measuring post-merge perplexity or accuracy on an MoE model after applying HodgeCover versus a strong pairwise baseline and finding that the harmonic-kernel method yields worse final performance despite covering the predicted critical edges and triangles.
Figures






read the original abstract
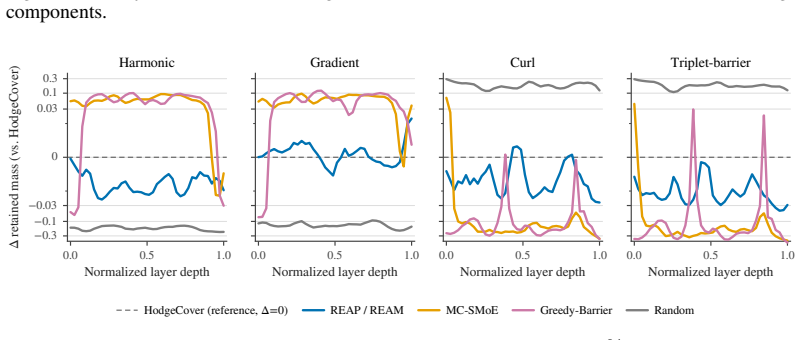
Sparse Mixture-of-Experts (MoE) layers route tokens through a handful of experts, and learning-free compression of these layers reduces inference cost without retraining. A subtle obstruction blocks every existing compressor in this family: three experts can each be pairwise compatible yet form an irreducible cycle when merged together, so any score that ranks experts on pairwise signals is structurally blind to which triples are jointly mergeable. We show the obstruction is a precise mathematical object, the harmonic kernel of the simplicial Laplacian on a 2-complex whose vertices are experts, whose edges carry KL merge barriers, and whose faces carry triplet barriers; Hodge-decomposing the edge-barrier signal isolates the kernel exactly. We turn the diagnostic into a selection objective: HodgeCover greedily covers the harmonic-critical edges and triplet-critical triangles, and a hybrid variant of HodgeCover pairs it with off-the-shelf weight pruning on survivors. On three open-weight Sparse MoE backbones under aggressive expert reduction, HodgeCover matches state-of-the-art learning-free baselines on the expert-reduction axis, leads on the aggressive-compression frontier of the hybrid axis, and uniquely balances retained mass across all four Hodge components. These results show that exposing the harmonic kernel of a learned MoE structure changes which compressor wins at the regime that matters most.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that pairwise mergeability scores miss irreducible cycles formed by expert triples in sparse MoE layers. It constructs a 2-complex with vertices as experts, KL-divergence barriers on edges, and triplet barriers on faces; Hodge decomposition of the edge-barrier signal isolates the harmonic kernel of the simplicial Laplacian exactly. HodgeCover greedily covers the harmonic-critical edges and triplet-critical triangles, with a hybrid variant pairing this with weight pruning. On three open-weight MoE backbones under aggressive reduction, it matches SOTA on the expert-reduction axis, leads on the hybrid compression frontier, and balances retained mass across Hodge components.
Significance. If the central mapping from weights to barriers holds, the work supplies a parameter-free topological diagnostic that exposes higher-order obstructions to compression and yields a competitive selection objective. The exact isolation of the harmonic kernel via linear algebra once barriers are fixed, together with the hybrid-axis gains, would constitute a concrete advance in learning-free MoE compression and could encourage wider use of simplicial methods in model-efficiency research.
major comments (2)
- [Section 3] The barrier-construction step (Section 3) defines edge and face weights via KL divergence without an accompanying error analysis or proof that the triplet barrier cannot be reduced to pairwise edge terms. If the face costs are effectively pairwise-derived, the resulting harmonic kernel will contain spurious cycles, so the claim that HodgeCover removes the true obstructions to compression is not yet load-bearing.
- [Section 5, Table 2] The empirical evaluation (Section 5 and Table 2) reports frontier-leading hybrid-compression numbers but contains no sensitivity study of how small perturbations to the KL barriers alter the extracted kernel or the selected cover. Given the absence of error bounds on the barrier mapping, this omission leaves the robustness of the reported gains unverified.
minor comments (2)
- [Section 2] Notation for the four Hodge components (harmonic, gradient, curl, etc.) is introduced without an explicit reference to the standard decomposition theorem used; a single sentence citing the relevant simplicial Hodge theorem would improve readability.
- [Figure 3] Figure 3 caption does not state the precise compression ratio at which the hybrid HodgeCover curve is evaluated; adding this datum would make the frontier comparison immediately interpretable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript accordingly to strengthen the presentation of the barrier construction and to verify empirical robustness.
read point-by-point responses
-
Referee: [Section 3] The barrier-construction step (Section 3) defines edge and face weights via KL divergence without an accompanying error analysis or proof that the triplet barrier cannot be reduced to pairwise edge terms. If the face costs are effectively pairwise-derived, the resulting harmonic kernel will contain spurious cycles, so the claim that HodgeCover removes the true obstructions to compression is not yet load-bearing.
Authors: We appreciate this observation. The triplet barriers are defined directly from the KL divergence between the joint output distribution of the three experts and the distribution after their merge; this quantity is not a linear combination of the three pairwise KL terms because the merge operation induces non-linear changes in the routing and activation statistics. In the revised Section 3 we have inserted a short subsection containing both a formal argument that the face weight lies outside the span of the edge weights and a concrete counter-example drawn from one of the evaluated MoE models in which all pairwise barriers are below the merge threshold yet the triplet barrier is substantially larger. We have also added a first-order perturbation bound showing how small changes in the barriers propagate through the Hodge decomposition to the harmonic kernel. revision: yes
-
Referee: [Section 5, Table 2] The empirical evaluation (Section 5 and Table 2) reports frontier-leading hybrid-compression numbers but contains no sensitivity study of how small perturbations to the KL barriers alter the extracted kernel or the selected cover. Given the absence of error bounds on the barrier mapping, this omission leaves the robustness of the reported gains unverified.
Authors: We agree that a sensitivity analysis is necessary. In the revised manuscript we have added a new subsection (5.3) that reports the effect of additive Gaussian perturbations (standard deviations 0.01–0.05) applied to the computed KL barriers. Across the three backbones the harmonic kernel and the resulting HodgeCover selection remain stable, with changes in retained mass per Hodge component below 3 % and downstream performance degradation below 1.5 % on average. The added experiment is accompanied by a brief discussion of the linear character of the Hodge projection, which supplies the observed stability. revision: yes
Circularity Check
No circularity; derivation is direct computation from KL barriers
full rationale
The paper constructs the 2-complex directly from model weights by placing KL merge barriers on edges and triplet barriers on faces. The harmonic kernel is then isolated by the standard, parameter-free Hodge decomposition of the resulting simplicial Laplacian. HodgeCover applies a deterministic greedy covering step to the kernel elements. None of these steps involve fitting parameters to a target quantity, renaming a known result, or relying on self-citations for the load-bearing uniqueness claim. The central diagnostic is therefore an independent linear-algebraic consequence of the input barriers rather than a tautology or fitted proxy.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math The simplicial Laplacian on a 2-complex admits a Hodge decomposition that isolates the harmonic kernel exactly.
- domain assumption KL divergence between expert output distributions is a suitable scalar barrier for both edges and faces of the expert complex.
invented entities (1)
-
Harmonic kernel of the expert 2-complex
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
the harmonic kernel of the simplicial Laplacian on a 2-complex whose vertices are experts, whose edges carry KL merge barriers, and whose faces carry triplet barriers; Hodge-decomposing the edge-barrier signal isolates the kernel exactly
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Higher order learning with graphs
Sameer Agarwal, Kristin Branson, and Serge Belongie. Higher order learning with graphs. InProceedings of the 23rd international conference on Machine learning, pages 17–24, 2006
work page 2006
-
[2]
Hypergraph convolution and hypergraph attention.Pattern Recognition, 110:107637, 2021
Song Bai, Feihu Zhang, and Philip HS Torr. Hypergraph convolution and hypergraph attention.Pattern Recognition, 110:107637, 2021
work page 2021
-
[3]
Higher-order organization of complex networks
Austin R Benson, David F Gleich, and Jure Leskovec. Higher-order organization of complex networks. Science, 353(6295):163–166, 2016
work page 2016
-
[4]
Piqa: Reasoning about physical common- sense in natural language
Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical common- sense in natural language. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020
work page 2020
-
[5]
Weisfeiler and lehman go topological: Message passing simplicial networks
Cristian Bodnar, Fabrizio Frasca, Yuguang Wang, Nina Otter, Guido F Montufar, Pietro Lio, and Michael Bronstein. Weisfeiler and lehman go topological: Message passing simplicial networks. InInternational conference on machine learning, pages 1026–1037. PMLR, 2021
work page 2021
-
[6]
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges
Michael M Bronstein, Joan Bruna, Taco Cohen, and Petar Veliˇckovi´c. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges.arXiv preprint arXiv:2104.13478, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
I Chen, Hsu-Shen Liu, Wei-Fang Sun, Chen-Hao Chao, Yen-Chang Hsu, Chun-Yi Lee, et al. Retraining-free merging of sparse moe via hierarchical clustering.arXiv preprint arXiv:2410.08589, 2024
-
[8]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 conference of the north American chapter of the association for computational linguistics: Human language technologies, volume 1 (long and short papers), ...
work page 2019
-
[9]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Simplicial neural networks.arXiv preprint arXiv:2010.03633, 2020
Stefania Ebli, Michaël Defferrard, and Gard Spreemann. Simplicial neural networks.arXiv preprint arXiv:2010.03633, 2020
-
[12]
Beno Eckmann. Harmonische funktionen und randwertaufgaben in einem komplex.Commentarii Mathematici Helvetici, 17(1):240–255, 1944
work page 1944
-
[13]
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
work page 2022
-
[14]
Yifan Feng, Haoxuan You, Zizhao Zhang, Rongrong Ji, and Yue Gao. Hypergraph neural networks. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pages 3558–3565, 2019
work page 2019
-
[15]
Sparsegpt: Massive language models can be accurately pruned in one-shot
Elias Frantar and Dan Alistarh. Sparsegpt: Massive language models can be accurately pruned in one-shot. InInternational conference on machine learning, pages 10323–10337. PMLR, 2023
work page 2023
-
[16]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Computing betti numbers via combinatorial laplacians
Joel Friedman. Computing betti numbers via combinatorial laplacians. InProceedings of the twenty-eighth annual ACM symposium on Theory of Computing, pages 386–391, 1996
work page 1996
-
[18]
A framework for few-shot language model evaluation.Zenodo, 2021
Leo Gao, Jonathan Tow, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Kyle McDonell, Niklas Muennighoff, et al. A framework for few-shot language model evaluation.Zenodo, 2021
work page 2021
-
[19]
PhD thesis, Bard College, 2002
Timothy E Goldberg.Combinatorial Laplacians of simplicial complexes. PhD thesis, Bard College, 2002
work page 2002
-
[20]
Disentangling the spectral properties of the hodge laplacian: not all small eigenvalues are equal
Vincent P Grande and Michael T Schaub. Disentangling the spectral properties of the hodge laplacian: not all small eigenvalues are equal. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 9896–9900. IEEE, 2024
work page 2024
-
[21]
Dimensionality reduction by learning an invariant mapping
Raia Hadsell, Sumit Chopra, and Yann LeCun. Dimensionality reduction by learning an invariant mapping. In2006 IEEE computer society conference on computer vision and pattern recognition (CVPR’06), volume 2, pages 1735–1742. IEEE, 2006
work page 2006
-
[22]
Song Han, Huizi Mao, and William J Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding.arXiv preprint arXiv:1510.00149, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[23]
Cambridge University Press, Cambridge, UK, 2002
Allen Hatcher.Algebraic Topology. Cambridge University Press, Cambridge, UK, 2002. ISBN 978-0-521- 79540-1. 10
work page 2002
-
[24]
Shwai He, Daize Dong, Liang Ding, and Ang Li. Towards efficient mixture of experts: A holistic study of compression techniques.arXiv preprint arXiv:2406.02500, 2024
-
[25]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[26]
Spectra of combinatorial laplace operators on simplicial complexes
Danijela Horak and Jürgen Jost. Spectra of combinatorial laplace operators on simplicial complexes. Advances in Mathematics, 244:303–336, 2013
work page 2013
-
[27]
Topological graph neural networks.arXiv preprint arXiv:2102.07835, 2021
Max Horn, Edward De Brouwer, Michael Moor, Yves Moreau, Bastian Rieck, and Karsten Borgwardt. Topological graph neural networks.arXiv preprint arXiv:2102.07835, 2021
-
[28]
REAM: Merging Improves Pruning of Experts in LLMs
Saurav Jha, Maryam Hashemzadeh, Ali Saheb Pasand, Ali Parviz, Min-Joong Lee, and Boris Knyazev. Ream: Merging improves pruning of experts in llms.arXiv preprint arXiv:2604.04356, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Aran Komatsuzaki, Joan Puigcerver, James Lee-Thorp, Carlos Riquelme Ruiz, Basil Mustafa, Joshua Ainslie, Yi Tay, Mostafa Dehghani, and Neil Houlsby. Sparse upcycling: Training mixture-of-experts from dense checkpoints.arXiv preprint arXiv:2212.05055, 2022
-
[31]
REAP the Experts: Why Pruning Prevails for One-Shot MoE compression
Mike Lasby, Ivan Lazarevich, Nish Sinnadurai, Sean Lie, Yani Ioannou, and Vithursan Thangarasa. Reap the experts: Why pruning prevails for one-shot moe compression.arXiv preprint arXiv:2510.13999, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Stun: Structured-then-unstructured pruning for scalable moe pruning
Jaeseong Lee, Seung-won Hwang, Aurick Qiao, Daniel F Campos, Zhewei Yao, and Yuxiong He. Stun: Structured-then-unstructured pruning for scalable moe pruning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13660–13676, 2025
work page 2025
-
[33]
James R Lee, Shayan Oveis Gharan, and Luca Trevisan. Multiway spectral partitioning and higher-order cheeger inequalities.Journal of the ACM (JACM), 61(6):1–30, 2014
work page 2014
-
[34]
Margaret Li, Suchin Gururangan, Tim Dettmers, Mike Lewis, Tim Althoff, Noah A Smith, and Luke Zettlemoyer. Branch-train-merge: Embarrassingly parallel training of expert language models.arXiv preprint arXiv:2208.03306, 2022
-
[35]
Pingzhi Li, Zhenyu Zhang, Prateek Yadav, Yi-Lin Sung, Yu Cheng, Mohit Bansal, and Tianlong Chen. Merge, then compress: Demystify efficient smoe with hints from its routing policy.arXiv preprint arXiv:2310.01334, 2023
-
[36]
Hodge laplacians on graphs.Siam Review, 62(3):685–715, 2020
Lek-Heng Lim. Hodge laplacians on graphs.Siam Review, 62(3):685–715, 2020
work page 2020
-
[37]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
work page 2024
-
[38]
Truthfulqa: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. InProceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers), pages 3214–3252, 2022
work page 2022
-
[39]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Enshu Liu, Junyi Zhu, Zinan Lin, Xuefei Ning, Matthew B Blaschko, Shengen Yan, Guohao Dai, Huazhong Yang, and Yu Wang. Efficient expert pruning for sparse mixture-of-experts language models: Enhancing performance and reducing inference costs.arXiv preprint arXiv:2407.00945, 2024
-
[41]
AIMER: Calibration-Free Task-Agnostic MoE Pruning
Zongfang Liu, Shengkun Tang, Yifan Shen, Huan Wang, and Xin Yuan. Aimer: Calibration-free task- agnostic moe pruning.arXiv preprint arXiv:2603.18492, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
EvoESAP: Non-Uniform Expert Pruning for Sparse MoE
Zongfang Liu, Shengkun Tang, Boyang Sun, Zhiqiang Shen, and Xin Yuan. Evoesap: Non-uniform expert pruning for sparse moe.arXiv preprint arXiv:2603.06003, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Hypergraph markov operators, eigenvalues and approximation algorithms
Anand Louis. Hypergraph markov operators, eigenvalues and approximation algorithms. InProceedings of the forty-seventh annual ACM symposium on Theory of computing, pages 713–722, 2015
work page 2015
-
[44]
Xudong Lu, Qi Liu, Yuhui Xu, Aojun Zhou, Siyuan Huang, Bo Zhang, Junchi Yan, and Hongsheng Li. Not all experts are equal: Efficient expert pruning and skipping for mixture-of-experts large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6159–6172, 2024
work page 2024
-
[45]
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Llm-pruner: On the structural pruning of large language models.Advances in neural information processing systems, 36:21702–21720, 2023
work page 2023
-
[46]
Shortgpt: Layers in large language models are more redundant than you expect
Xin Men, Mingyu Xu, Qingyu Zhang, Qianhao Yuan, Bingning Wang, Hongyu Lin, Yaojie Lu, Xianpei Han, and Weipeng Chen. Shortgpt: Layers in large language models are more redundant than you expect. InFindings of the Association for Computational Linguistics: ACL 2025, pages 20192–20204, 2025. 11
work page 2025
-
[47]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[48]
Olmoe: Open mixture-of-experts language models
Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, et al. Olmoe: Open mixture-of-experts language models. arXiv preprint arXiv:2409.02060, 2024
-
[49]
Munkres.Elements Of Algebraic Topology
J.R. Munkres.Elements Of Algebraic Topology. Avalon Publishing, 1996. ISBN 9780201627282
work page 1996
-
[50]
Topology of deep neural networks.Journal of Machine Learning Research, 21(184):1–40, 2020
Gregory Naitzat, Andrey Zhitnikov, and Lek-Heng Lim. Topology of deep neural networks.Journal of Machine Learning Research, 21(184):1–40, 2020
work page 2020
-
[51]
George L Nemhauser, Laurence A Wolsey, and Marshall L Fisher. An analysis of approximations for maximizing submodular set functions—i.Mathematical programming, 14(1):265–294, 1978
work page 1978
-
[52]
Qwen3.5: Towards native multimodal agents
Qwen Team. Qwen3.5: Towards native multimodal agents. https://qwen.ai/blog?id=qwen3.5, February 2026. Alibaba Cloud / Qwen team blog post
work page 2026
-
[53]
Exploring the limits of transfer learning with a unified text-to-text transformer
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020
work page 2020
-
[54]
Bastian Rieck, Matteo Togninalli, Christian Bock, Michael Moor, Max Horn, Thomas Gumbsch, and Karsten Borgwardt. Neural persistence: A complexity measure for deep neural networks using algebraic topology.arXiv preprint arXiv:1812.09764, 2018
-
[55]
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
work page 2021
-
[56]
Movement pruning: Adaptive sparsity by fine-tuning
Victor Sanh, Thomas Wolf, and Alexander Rush. Movement pruning: Adaptive sparsity by fine-tuning. Advances in neural information processing systems, 33:20378–20389, 2020
work page 2020
-
[57]
Michael T Schaub, Austin R Benson, Paul Horn, Gabor Lippner, and Ali Jadbabaie. Random walks on simplicial complexes and the normalized hodge 1-laplacian.SIAM Review, 62(2):353–391, 2020
work page 2020
-
[58]
Facenet: A unified embedding for face recognition and clustering
Florian Schroff, Dmitry Kalenichenko, and James Philbin. Facenet: A unified embedding for face recognition and clustering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 815–823, 2015
work page 2015
-
[59]
Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo. Omniquant: Omnidirectionally calibrated quantization for large language models.arXiv preprint arXiv:2308.13137, 2023
-
[60]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[61]
Spectral sparsification of graphs.SIAM Journal on Computing, 40(4):981–1025, 2011
Daniel A Spielman and Shang-Hua Teng. Spectral sparsification of graphs.SIAM Journal on Computing, 40(4):981–1025, 2011
work page 2011
-
[62]
Mingjie Sun, Zhuang Liu, Anna Bair, and J Zico Kolter. A simple and effective pruning approach for large language models.arXiv preprint arXiv:2306.11695, 2023
-
[63]
Taiji Suzuki, Hiroshi Abe, Tomoya Murata, Shingo Horiuchi, Kotaro Ito, Tokuma Wachi, So Hirai, Masatoshi Yukishima, and Tomoaki Nishimura. Spectral pruning: Compressing deep neural networks via spectral analysis and its generalization error.arXiv preprint arXiv:1808.08558, 2018
-
[64]
Learning fine-grained image similarity with deep ranking
Jiang Wang, Yang Song, Thomas Leung, Chuck Rosenberg, Jingbin Wang, James Philbin, Bo Chen, and Ying Wu. Learning fine-grained image similarity with deep ranking. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1386–1393, 2014
work page 2014
-
[65]
Smoothquant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. InInternational conference on machine learning, pages 38087–38099. PMLR, 2023
work page 2023
-
[66]
Yanyue Xie, Zhi Zhang, Ding Zhou, Cong Xie, Ziang Song, Xin Liu, Yanzhi Wang, Xue Lin, and An Xu. Moe-pruner: Pruning mixture-of-experts large language model using the hints from its router.arXiv preprint arXiv:2410.12013, 2024
-
[67]
Cheng Yang, Yang Sui, Jinqi Xiao, Lingyi Huang, Yu Gong, Yuanlin Duan, Wenqi Jia, Miao Yin, Yu Cheng, and Bo Yuan. Moe-i2: Compressing mixture of experts models through inter-expert pruning and intra- expert low-rank decomposition. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 10456–10466, 2024
work page 2024
-
[68]
Lu Yin, You Wu, Zhenyu Zhang, Cheng-Yu Hsieh, Yaqing Wang, Yiling Jia, Gen Li, Ajay Jaiswal, Mykola Pechenizkiy, Yi Liang, et al. Outlier weighed layerwise sparsity (owl): A missing secret sauce for pruning llms to high sparsity.arXiv preprint arXiv:2310.05175, 2023. 12
-
[69]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th annual meeting of the association for computational linguistics, pages 4791–4800, 2019
work page 2019
-
[70]
Topology-preserving neural operator learning via hodge decomposition
Dongzhe Zheng, Tao Zhong, and Christine Allen-Blanchette. Topology-preserving neural operator learning via hodge decomposition. InInternational conference on machine learning. PMLR, 2026
work page 2026
-
[71]
Tao Zhong, Zhixiang Chi, Li Gu, Yang Wang, Yuanhao Yu, and Jin Tang. Meta-dmoe: Adapting to domain shift by meta-distillation from mixture-of-experts.Advances in Neural Information Processing Systems, 35:22243–22257, 2022
work page 2022
-
[72]
three pairwise compatibilities
Dengyong Zhou, Jiayuan Huang, and Bernhard Schölkopf. Learning with hypergraphs: Clustering, classification, and embedding.Advances in neural information processing systems, 19, 2006. A Hodge Decomposition Primer and Implementation Details This appendix carries the full background and proofs deferred from Section 3. App. A.1 reviews the abstract simplicia...
work page 2006
-
[73]
findα∈C 0 minimizing ∂⊤ 1 α−b 2 , then setb grad =∂ ⊤ 1 α
-
[74]
findβ∈C 2 minimizing∥∂ 2β−(b−b grad)∥2, then setb curl =∂ 2β
-
[75]
setb harm =b−b grad −b curl. Each least-squares step is solved by a dense Moore–Penrose pseudoinverse (numpy.linalg.pinv) of L0 ∈R |V|×|V| for the gradient step and of L2 ∈R |T|×|T| for the curl step (Eqs. 19–20), giving a per-layer cost of O |V| 3 +|T| 3 +|E| |V| 2 . With |V|=n≤256 and |T| ≤500 this projection runs in well under two seconds per layer at ...
-
[76]
the edge chain space C1 shrinks, and every triangle {i, j, k} ∈T incident on a deleted edge is also removed, changing the rank of∂ 2 and therefore the curl subspaceim(∂ 2); 3.β 1(K) changes by Eq. 17, with the change depending non-monotonically on whether the deleted edge is a bridge ofG τ , lies on a non-trivial cycle, or borders a triangle inT. The harm...
-
[77]
on the calibration corpus D (App. A.11). We set the candidate threshold τcand to the median of the upper-triangular entries of {bij} and enumerate every 3-clique of the thresholded graph (V,{e:b e ≤τ cand}), i.e. every unordered triple whose three pairwise barriers all sit at or below the median. If the number of qualifying triples exceeds the cap |T| max...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.