Recognition: 2 theorem links
· Lean TheoremReflective Flow Sampling Enhancement
Pith reviewed 2026-05-15 15:27 UTC · model grok-4.3
The pith
RF-Sampling lets flow models like FLUX climb text-image alignment scores at inference time by combining textual representations and flow inversion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RF-Sampling implicitly performs gradient ascent on the text-image alignment score by leveraging a linear combination of textual representations and integrating them with flow inversion, allowing the model to explore noise spaces more consistent with the input prompt.
What carries the argument
Reflective Flow Sampling, which applies a linear combination of textual representations together with flow inversion to perform the implicit ascent.
If this is right
- Generation quality rises consistently across multiple text-to-image benchmarks.
- Prompt alignment improves without any model retraining or fine-tuning.
- Test-time scaling becomes observable to a limited degree on FLUX.
- The same procedure extends to other CFG-distilled flow variants.
Where Pith is reading between the lines
- Similar derivations may be attempted for non-distilled flow models by relaxing the CFG assumption.
- The linear-text-combination step could be tested as a modular add-on inside existing flow samplers.
- If the ascent property generalizes, inference-time alignment gains might appear in related generative tasks such as video or audio synthesis.
Load-bearing premise
The formal derivation that RF-Sampling performs gradient ascent holds only for CFG-distilled flow models such as FLUX.
What would settle it
A measurement that records no increase in the text-image alignment score across sampling steps on a CFG-distilled flow model would falsify the central derivation.
Figures

















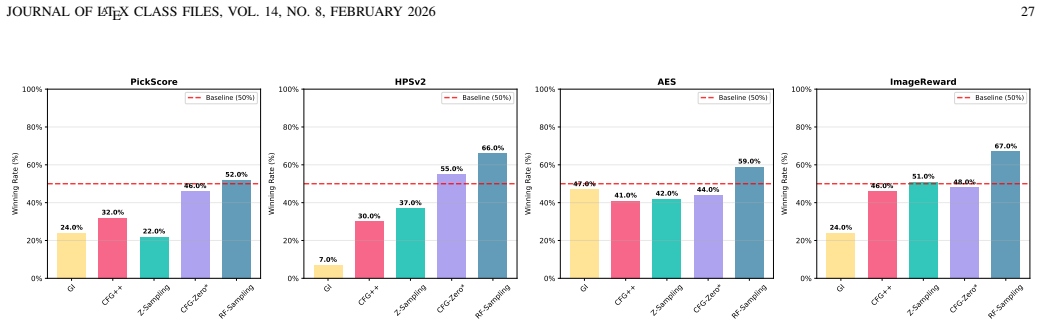
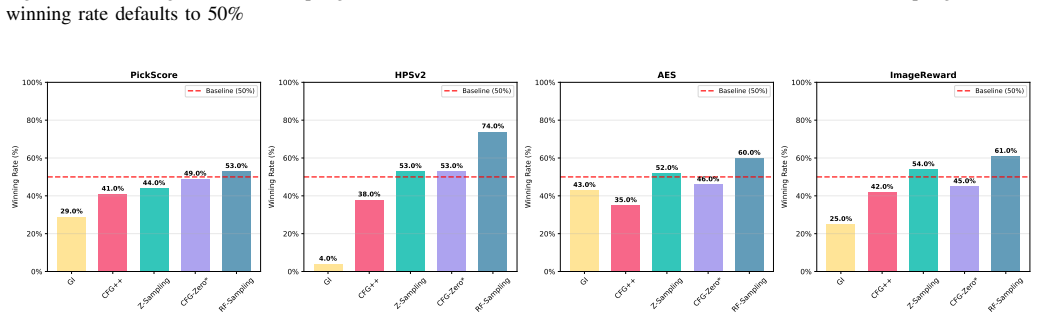


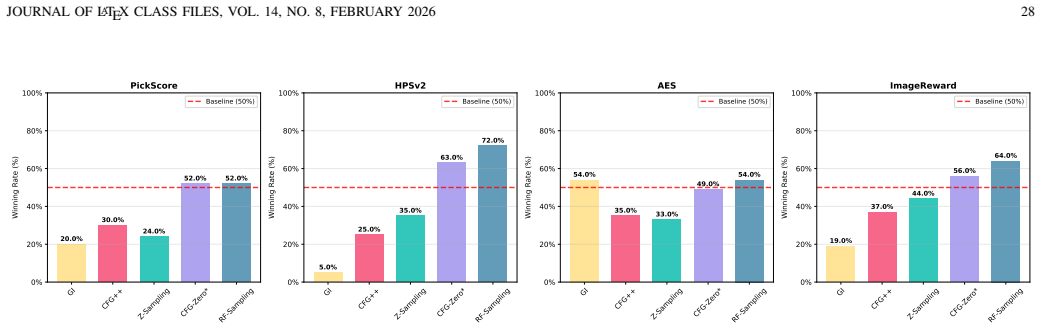
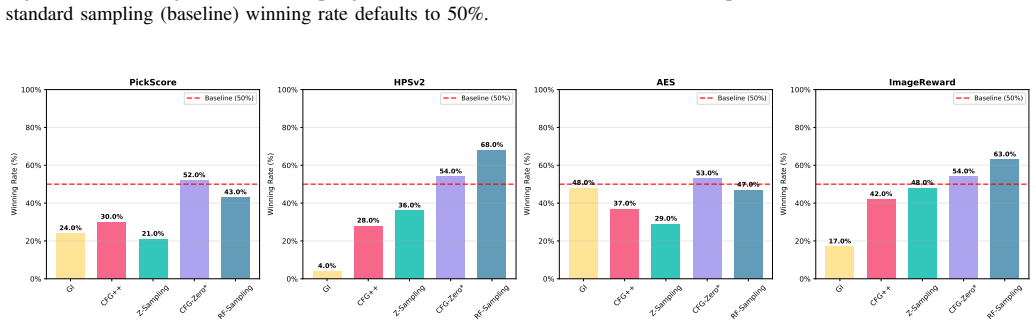
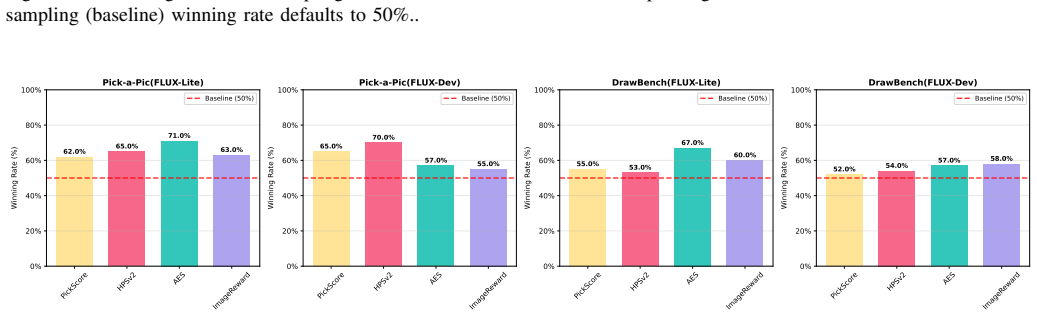
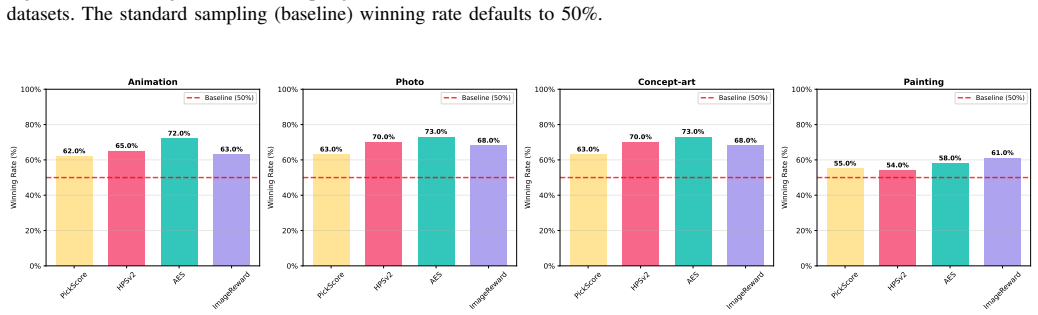













read the original abstract
The growing demand for text-to-image generation has led to rapid advances in generative modeling. Recently, text-to-image diffusion models trained with flow matching algorithms, such as FLUX, have achieved remarkable progress and emerged as strong alternatives to conventional diffusion models. At the same time, inference-time enhancement strategies have been shown to improve the generation quality and text-prompt alignment of text-to-image diffusion models. However, these techniques are mainly applicable to conventional diffusion models and usually fail to perform well on flow models. To bridge this gap, we propose Reflective Flow Sampling (RF-Sampling), a theoretically-grounded and training-free inference enhancement framework explicitly designed for flow models, especially for the CFG-distilled variants (i.e., models distilled from CFG guidance techniques), like FLUX. Departing from heuristic interpretations, we provide a formal derivation proving that RF-Sampling implicitly performs gradient ascent on the text-image alignment score. By leveraging a linear combination of textual representations and integrating them with flow inversion, RF-Sampling allows the model to explore noise spaces that are more consistent with the input prompt. Extensive experiments across multiple benchmarks demonstrate that RF-Sampling consistently improves both generation quality and prompt alignment. Moreover, RF-Sampling is also the first inference enhancement method that can exhibit test-time scaling ability to some extent on FLUX.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Reflective Flow Sampling (RF-Sampling), a training-free inference enhancement framework for flow-matching text-to-image models such as FLUX. It claims a formal derivation showing that RF-Sampling implicitly performs gradient ascent on the text-image alignment score by combining textual representations linearly and integrating them with flow inversion. Experiments across benchmarks report consistent gains in generation quality, prompt alignment, and limited test-time scaling behavior.
Significance. If the central derivation is rigorous, the work would be significant for supplying the first theoretically motivated inference-time method tailored to CFG-distilled flow models, filling a gap left by techniques developed primarily for diffusion models. The reported test-time scaling observation, even if partial, is a concrete strength that could inform future scaling analyses in generative sampling.
major comments (2)
- [Abstract / formal derivation] Abstract and formal derivation section: the claim that RF-Sampling exactly performs gradient ascent on the alignment score rests on an unverified equivalence between the sampling update and the gradient of an alignment objective; the derivation must explicitly address discretization error from numerical ODE solvers and non-differentiability introduced by CFG distillation, or quantify the approximation gap.
- [Abstract] Abstract: the text-image alignment score underlying the gradient-ascent interpretation is never defined; if this score is computed from quantities internal to the same model, the argument risks circularity and the proof must state the objective function explicitly.
minor comments (2)
- [Experiments] Experiments section: supply the precise list of benchmarks, quantitative prompt-alignment metrics, and statistical significance tests so that the reported consistent gains can be reproduced and compared.
- [Method] Method section: clarify the exact coefficients and normalization used in the linear combination of textual representations.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, agreeing where the manuscript requires clarification and outlining the specific revisions we will make to strengthen the formal claims.
read point-by-point responses
-
Referee: [Abstract / formal derivation] Abstract and formal derivation section: the claim that RF-Sampling exactly performs gradient ascent on the alignment score rests on an unverified equivalence between the sampling update and the gradient of an alignment objective; the derivation must explicitly address discretization error from numerical ODE solvers and non-differentiability introduced by CFG distillation, or quantify the approximation gap.
Authors: We agree that the current derivation is stated in the continuous-time limit and does not explicitly bound the practical errors. In the revised manuscript we will expand the formal derivation section to (i) derive the gradient-ascent equivalence under the flow ODE, (ii) introduce an error term for discretization using standard numerical ODE solvers (e.g., Euler or Heun), and (iii) analyze the effect of CFG distillation non-differentiability. We will provide a concrete approximation bound showing that the implicit ascent property holds with an additive error controlled by step size and model Lipschitz constants, thereby quantifying the gap rather than claiming exact equivalence. revision: yes
-
Referee: [Abstract] Abstract: the text-image alignment score underlying the gradient-ascent interpretation is never defined; if this score is computed from quantities internal to the same model, the argument risks circularity and the proof must state the objective function explicitly.
Authors: We thank the referee for highlighting this omission. The alignment score is defined as the inner product between the text embedding and the image features obtained from the model's velocity prediction at each flow step; this objective is grounded in the pre-trained flow-matching loss and is therefore independent of the reflective sampling procedure itself. In the revised abstract and derivation we will state the objective function explicitly as the maximization of this score and clarify that the linear textual combinations and flow inversion implement an approximate gradient step on it, removing any appearance of circularity. revision: yes
Circularity Check
No circularity: formal derivation stands on flow-matching mathematics independent of fitted inputs
full rationale
The paper's central claim rests on a formal derivation showing RF-Sampling performs implicit gradient ascent on an alignment score via linear combination of text embeddings plus flow inversion. This derivation is presented as following directly from the continuous ODE structure of flow models and the properties of CFG-distilled variants (e.g., FLUX), without reducing any predicted quantity to a parameter fitted on the target data or to a self-citation chain. The alignment score is treated as an external objective (text-image consistency), and the proof is not shown to be tautological with the sampling rule itself. No self-definitional steps, fitted-input predictions, or ansatz smuggling via prior author work are exhibited in the derivation chain. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Flow matching models admit a well-defined inversion operation that preserves the ability to explore prompt-consistent noise spaces.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
we provide a formal derivation proving that RF-Sampling implicitly performs gradient ascent on the text-image alignment score... ∇xJ(xt) ∝ vθ(xt,c) − vθ(xt,∅)... Δ_RF = δt · [vθ(xt,t,chigh) − vθ(xt−δt,t−δt,clow)]... J(x''t) > J(xt) ⇔ ⟨Δ_RF, ∇xJ(xt)⟩ > 0
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Theorem 2 (Second-Order Optimality)... ΔJ(γ) ≈ γ⟨Δ_RF,∇xJ⟩ − ½γ²|Δ⊤_RF H(xt)Δ_RF|... γ* = ⟨Δ_RF,∇xJ⟩ / |Δ⊤_RF H Δ_RF|
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 10 684–10 695
work page 2022
-
[2]
B. F. Labs, “Flux,” https://github.com/black-forest-labs/flux, 2024
work page 2024
-
[3]
Flux.1 lite: Distilling flux1.dev for efficient text-to- image generation,
J. M. Daniel Verdú, “Flux.1 lite: Distilling flux1.dev for efficient text-to- image generation,” 2024
work page 2024
-
[4]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. Müller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boesel, D. Podell, T. Dockhorn, Z. English, K. Lacey, A. Goodwin, Y . Marek, and R. Rombach, “Scaling rectified flow transformers for high-resolution image synthesis,” 2024. [Online]. Available: https://arxiv.org/abs/2403.03206
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Diffusion models: A comprehensive survey of methods and applications,
L. Yang, Z. Zhang, Y . Song, S. Hong, R. Xu, Y . Zhao, W. Zhang, B. Cui, and M.-H. Yang, “Diffusion models: A comprehensive survey of methods and applications,”ACM computing surveys, vol. 56, no. 4, pp. 1–39, 2023
work page 2023
-
[6]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inNeural Information Processing Systems. Virtual Event: NeurIPS, Dec. 2020, pp. 6840–6851
work page 2020
-
[9]
Golden noise for diffusion models: A learning framework,
Z. Zhou, S. Shao, L. Bai, S. Zhang, Z. Xu, B. Han, and Z. Xie, “Golden noise for diffusion models: A learning framework,” 2025. [Online]. Available: https://arxiv.org/abs/2411.09502
-
[10]
A general framework for inference-time scaling and steering of diffusion models,
R. Singhal, Z. Horvitz, R. Teehan, M. Ren, Z. Yu, K. McKeown, and R. Ranganath, “A general framework for inference-time scaling and steering of diffusion models,”arXiv preprint arXiv:2501.06848, 2025
-
[12]
Classifier-Free Diffusion Guidance
J. Ho and T. Salimans, “Classifier-free diffusion guidance,”arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Zigzag diffusion sampling: Diffusion models can self-improve via self-reflection,
L. Bai, S. Shao, Z. Qi, H. Xiong, Z. Xieet al., “Zigzag diffusion sampling: Diffusion models can self-improve via self-reflection,” inThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[14]
Guidance matters: Rethinking the evaluation pitfall for text-to-image generation,
D. Xie, S. Shao, L. Bai, Z. Zhou, B. Cheng, S. Yang, J. Wu, and Z. Xie, “Guidance matters: Rethinking the evaluation pitfall for text-to-image generation,” inThe Fourteenth International Conference on Learning Representations
-
[15]
Coreˆ 2: Collect, reflect and refine to generate better and faster,
S. Shao, Z. Zhou, D. Xie, Y . Fang, T. Ye, L. Bai, and Z. Xie, “Coreˆ 2: Collect, reflect and refine to generate better and faster,”arXiv preprint arXiv:2503.09662, 2025
-
[16]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” inInternational Conference on Learning Representations. kigali, rwanda: OpenReview.net, May. 2023
work page 2023
-
[17]
Cfg-zero*: Improved classifier-free guidance for flow matching models,
W. Fan, A. Y . Zheng, R. A. Yeh, and Z. Liu, “Cfg-zero*: Improved classifier-free guidance for flow matching models,”arXiv preprint arXiv:2503.18886, 2025
-
[18]
On distillation of guided diffusion models,
C. Meng, R. Rombach, R. Gao, D. Kingma, S. Ermon, J. Ho, and T. Salimans, “On distillation of guided diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 14 297–14 306
work page 2023
-
[19]
The silent assistant: Noisequery as implicit guidance for goal-driven image generation,
R. Wang, H. Huang, Y . Zhu, O. Russakovsky, and Y . Wu, “The silent assistant: Noisequery as implicit guidance for goal-driven image generation,”arXiv preprint arXiv:2412.05101, 2024
-
[20]
Synthetic shifts to initial seed vector exposes the brittle nature of latent-based diffusion models,
M. Po-Yuan, S. Kotyan, T. Y . Foong, and D. V . Vargas, “Synthetic shifts to initial seed vector exposes the brittle nature of latent-based diffusion models,”arXiv preprint arXiv:2312.11473, 2023
-
[21]
Weak-to-strong diffusion with reflection,
L. Bai, M. Sugiyama, and Z. Xie, “Weak-to-strong diffusion with reflection,”arXiv preprint arXiv:2502.00473, 2025
-
[22]
T. Salimans, A. Karpathy, X. Chen, and D. P. Kingma, “Pixelcnn++: Improving the pixelcnn with discretized logistic mixture likelihood and other modifications,” inInternational Conference on Learning Representations, 2017
work page 2017
-
[23]
Generative pretraining from pixels,
M. Chen, A. Radford, R. Child, J. Wu, H. Jun, D. Luan, and I. Sutskever, “Generative pretraining from pixels,” inInternational conference on machine learning. PMLR, 2020, pp. 1691–1703
work page 2020
-
[24]
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. C. Courville, and Y . Bengio, “Generative adversarial nets.” Palais des Congrès de Montréal, Montréal CANADA: NeurIPS, Dec. 2014
work page 2014
-
[25]
Conditional Generative Adversarial Nets
M. Mirza and S. Osindero, “Conditional generative adversarial nets,” arXiv preprint arXiv:1411.1784, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[26]
Classifier-free diffusion guidance,
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” inNeural Information Processing Systems Workshop. Virtual Event: NeurIPS, Dec. 2021
work page 2021
-
[27]
Snapfusion: Text-to-image diffusion model on mobile devices within two seconds,
Y . Li, H. Wang, Q. Jin, J. Hu, P. Chemerys, Y . Fu, Y . Wang, S. Tulyakov, and J. Ren, “Snapfusion: Text-to-image diffusion model on mobile devices within two seconds,” inThirty-seventh Conference on Neural Information Processing Systems
-
[28]
Guided flows for generative modeling and decision making,
Q. Zheng, M. Le, N. Shaul, Y . Lipman, A. Grover, and R. T. Chen, “Guided flows for generative modeling and decision making,”arXiv preprint arXiv:2311.13443, 2023
-
[29]
Generative modeling by estimating gradients of the data distribution,
Y . Song and S. Ermon, “Generative modeling by estimating gradients of the data distribution,” inNeural Information Processing Systems, vol. 32. NeurIPS, 2019
work page 2019
-
[30]
X. Wu, Y . Hao, K. Sun, Y . Chen, F. Zhu, R. Zhao, and H. Li, “Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis,” 2023
work page 2023
-
[31]
T. Kynkäänniemi, M. Aittala, T. Karras, S. Laine, T. Aila, and J. Lehtinen, “Applying guidance in a limited interval improves sample and distribution quality in diffusion models,”Advances in Neural Information Processing Systems, 2024
work page 2024
-
[32]
Cfg++: Manifold-constrained classifier free guidance for diffusion models,
H. Chung, J. Kim, G. Y . Park, H. Nam, and J. C. Ye, “Cfg++: Manifold-constrained classifier free guidance for diffusion models,”
-
[33]
Available: https://arxiv.org/abs/2406.08070
[Online]. Available: https://arxiv.org/abs/2406.08070
-
[34]
Pick-a-pic: An open dataset of user preferences for text-to-image generation,
Y . Kirstain, A. Polyak, U. Singer, S. Matiana, J. Penna, and O. Levy, “Pick-a-pic: An open dataset of user preferences for text-to-image generation,” 2023
work page 2023
-
[35]
Photorealistic text-to-image diffusion models with deep language understanding,
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gontijo Lopes, B. Karagol Ayan, T. Salimans et al., “Photorealistic text-to-image diffusion models with deep language understanding,”Advances in Neural Information Processing Systems, vol. 35, pp. 36 479–36 494, 2022
work page 2022
-
[36]
Geneval: An object-focused framework for evaluating text-to-image alignment,
D. Ghosh, H. Hajishirzi, and L. Schmidt, “Geneval: An object-focused framework for evaluating text-to-image alignment,” 2023. [Online]. Available: https://arxiv.org/abs/2310.11513
-
[37]
T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation,
K. Huang, K. Sun, E. Xie, Z. Li, and X. Liu, “T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation,”Advances in Neural Information Processing Systems, vol. 36, pp. 78 723–78 747, 2023
work page 2023
-
[38]
Chronomagic-bench: A benchmark for metamor- phic evaluation of text-to-time-lapse video generation,
S. Yuan, J. Huang, Y . Xu, Y . Liu, S. Zhang, Y . Shi, R. Zhu, X. Cheng, J. Luo, and L. Yuan, “Chronomagic-bench: A benchmark for metamor- phic evaluation of text-to-time-lapse video generation,”arXiv preprint arXiv:2406.18522, 2024
-
[39]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
B. F. Labs, S. Batifol, A. Blattmann, F. Boesel, S. Consul, C. Diagne, T. Dockhorn, J. English, Z. English, P. Esser, S. Kulal, K. Lacey, Y . Levi, C. Li, D. Lorenz, J. Müller, D. Podell, R. Rombach, H. Saini, A. Sauer, and L. Smith, “Flux.1 kontext: Flow matching for in-context image generation and editing in latent space,” 2025. [Online]. Available: htt...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Imagereward: Learning and evaluating human preferences for text-to- image generation,
J. Xu, X. Liu, Y . Wu, Y . Tong, Q. Li, M. Ding, J. Tang, and Y . Dong, “Imagereward: Learning and evaluating human preferences for text-to- image generation,” 2023
work page 2023
-
[41]
C. Schuhmann, “Improved aesthetic predictor.” [Online]. Available: https://github.com/christophschuhmann/improved-aesthetic-predictor
-
[42]
Wan: Open and Advanced Large-Scale Video Generative Models
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, J. Zeng, J. Wang, J. Zhang, J. Zhou, J. Wang, J. Chen, K. Zhu, K. Zhao, K. Yan, L. Huang, M. Feng, N. Zhang, P. Li, P. Wu, R. Chu, R. Feng, S. Zhang, S. Sun, T. Fang, T. Wang, T. Gui, T. Weng, T. Shen, W. Lin, W. Wang, W. Wang, W. Zhou, W. Wang, W. Shen, W. Yu, X. Shi, X....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Svdquant: Absorbing outliers by low-rank components for 4-bit diffusion models,
M. Li*, Y . Lin*, Z. Zhang*, T. Cai, X. Li, J. Guo, E. Xie, C. Meng, J.-Y . Zhu, and S. Han, “Svdquant: Absorbing outliers by low-rank components for 4-bit diffusion models,” inThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[44]
Imagenet large scale visual recognition challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernsteinet al., “Imagenet large scale visual recognition challenge,”International Journal of Computer Vision, vol. 115, no. 3, pp. 211–252, 2015
work page 2015
-
[45]
Bag of design choices for inference of high-resolution masked generative transformer,
S. Shao, Z. Zhou, T. Ye, L. Bai, Z. Xu, and Z. Xie, “Bag of design choices for inference of high-resolution masked generative transformer,”
-
[46]
Available: https://arxiv.org/abs/2411.10781 JOURNAL OF LATEX CLASS FILES, VOL
[Online]. Available: https://arxiv.org/abs/2411.10781 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, FEBRUARY 2026 14
-
[47]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” 2018
work page 2018
-
[48]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, L. Bourdev, R. Girshick, J. Hays, P. Perona, D. Ramanan, C. L. Zitnick, and P. Dollár, “Microsoft coco: Common objects in context,” 2015
work page 2015
-
[49]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” 2021
work page 2021
-
[50]
Improved techniques for training gans,
T. Salimans, I. Goodfellow, W. Zaremba, V . Cheung, A. Radford, and X. Chen, “Improved techniques for training gans,” inNeural Information Processing Systems, vol. 29. Centre Convencions Internacional Barcelona, Barcelona SPAIN: NeurIPS, Dec. 2016
work page 2016
-
[51]
Scaling Instruction-Finetuned Language Models
H. W. Chung, L. Hou, S. Longpre, B. Zoph, Y . Tay, W. Fedus, Y . Li, X. Wang, M. Dehghani, S. Brahma, A. Webson, S. S. Gu, Z. Dai, M. Suzgun, X. Chen, A. Chowdhery, A. Castro-Ros, M. Pellat, K. Robinson, D. Valter, S. Narang, G. Mishra, A. Yu, V . Zhao, Y . Huang, A. Dai, H. Yu, S. Petrov, E. H. Chi, J. Dean, J. Devlin, A. Roberts, D. Zhou, Q. V . Le, and...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[52]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
X. Liu, C. Gong, and Q. Liu, “Flow straight and fast: Learning to generate and transfer data with rectified flow,”arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[53]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” 2023
work page 2023
-
[54]
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
J. Hessel, A. Holtzman, M. Forbes, R. L. Bras, and Y . Choi, “Clipscore: A reference-free evaluation metric for image captioning,”arXiv preprint arXiv:2104.08718, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[55]
Score-based generative modeling through stochastic differential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,” inInternational Conference on Learning Representations. kigali, rwanda: OpenReview.net, May. 2023
work page 2023
-
[56]
Inference-time scaling for diffusion models beyond scaling denoising steps,
N. Ma, S. Tong, H. Jia, H. Hu, Y .-C. Su, M. Zhang, X. Yang, Y . Li, T. Jaakkola, X. Jia, and S. Xie, “Inference-time scaling for diffusion models beyond scaling denoising steps,” 2025. [Online]. Available: https://arxiv.org/abs/2501.09732 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, FEBRUARY 2026 15 APPENDIX A. Benchmark Pick-a-Pic.Pick-a-Pic [33] is an...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.