Recognition: no theorem link
IMSE: Intrinsic Mixture of Spectral Experts Fine-tuning for Test-Time Adaptation
Pith reviewed 2026-05-15 15:22 UTC · model grok-4.3
The pith
Adapting only singular values in Vision Transformers enables efficient test-time adaptation to distribution shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The singular values obtained from SVD of each linear layer function as intrinsic spectral experts. Adapting solely these values, together with a diversity maximization loss and domain-aware spectral code retrieval, allows the model to adapt to new test distributions, avoid collapse onto domain-specific cues, and retain class-discriminative features from pretraining, resulting in state-of-the-art accuracy under standard and continual TTA with 385 times fewer parameters.
What carries the argument
Singular values from SVD decomposition of linear layers treated as a mixture of spectral experts, adapted via entropy minimization plus diversity maximization loss and retrieved by domain-aware spectral code detection.
If this is right
- State-of-the-art accuracy is reached on multiple distribution-shift benchmarks under the TTA protocol.
- Accuracy rises by 3.4 percentage points in continual TTA and 2.4 points in gradual CTTA.
- Only 1/385 as many parameters are updated compared with conventional fine-tuning.
- Knowledge from earlier domains is reused by retrieving the corresponding adapted singular values.
- Diverse expert utilization prevents the model from collapsing to domain-specific rather than class-discriminative features.
Where Pith is reading between the lines
- The same SVD-only update pattern could be tested on non-ViT architectures to check whether the benefit generalizes.
- Low-parameter continual adaptation of this form would lower the cost of maintaining models in environments where data distributions evolve gradually.
- The reliability of domain-shift detection directly governs how often the retrieval step can reuse prior adaptations without error.
- Extreme shifts where singular vectors themselves encode domain-specific information might require relaxing the fixed-vector constraint.
Load-bearing premise
Adapting only the singular values while keeping singular vectors fixed is sufficient to leverage pretrained representations without losing critical class-discriminative information.
What would settle it
If full-parameter or singular-vector adaptation produces markedly higher accuracy than singular-value-only adaptation on a held-out distribution-shift benchmark, the sufficiency of fixing the vectors would be disproved.
Figures


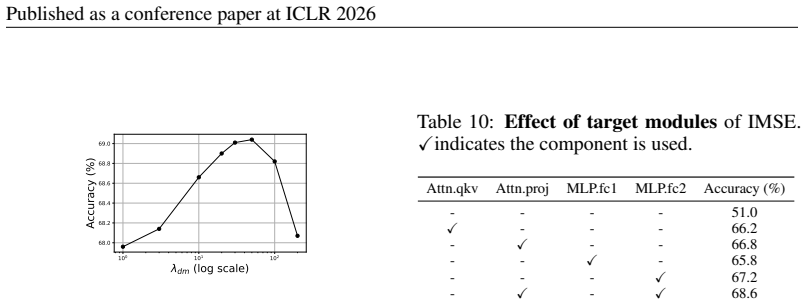


read the original abstract
Test-time adaptation (TTA) has been widely explored to prevent performance degradation when test data differ from the training distribution. However, fully leveraging the rich representations of large pretrained models with minimal parameter updates remains underexplored. In this paper, we propose Intrinsic Mixture of Spectral Experts (IMSE) that leverages the spectral experts inherently embedded in Vision Transformers. We decompose each linear layer via singular value decomposition (SVD) and adapt only the singular values, while keeping the singular vectors fixed. We further identify a key limitation of entropy minimization in TTA: it often induces feature collapse, causing the model to rely on domain-specific features rather than class-discriminative features. To address this, we propose a diversity maximization loss based on expert-input alignment, which encourages diverse utilization of spectral experts during adaptation. In the continual test-time adaptation (CTTA) scenario, beyond preserving pretrained knowledge, it is crucial to retain and reuse knowledge from previously observed domains. We introduce Domain-Aware Spectral Code Retrieval, which estimates input distributions to detect domain shifts, and retrieves adapted singular values for rapid adaptation. Consequently, our method achieves state-of-the-art performance on various distribution-shift benchmarks under the TTA setting. In CTTA and Gradual CTTA, it further improves accuracy by 3.4 percentage points (pp) and 2.4 pp, respectively, while requiring 385 times fewer trainable parameters. Our code is available at https://github.com/baek85/IMSE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Intrinsic Mixture of Spectral Experts (IMSE) for test-time adaptation (TTA) of Vision Transformers. Each linear layer is decomposed via SVD; only the singular values are updated while the singular vectors remain fixed. A diversity-maximization loss based on expert-input alignment is added to counteract feature collapse induced by entropy minimization. For continual TTA, a Domain-Aware Spectral Code Retrieval module detects shifts and re-uses previously adapted singular values. The method reports state-of-the-art accuracy on standard distribution-shift benchmarks, with gains of 3.4 pp on CTTA and 2.4 pp on Gradual CTTA, while using 385× fewer trainable parameters than competing approaches.
Significance. If the empirical claims hold, the work demonstrates a practical route to parameter-efficient TTA that preserves most of a large pretrained model’s capacity. The combination of spectral decomposition, diversity regularization, and retrieval-based reuse could influence deployment of ViTs under non-stationary conditions where full fine-tuning or prompt-based methods are prohibitive.
major comments (3)
- [§3.1] §3.1 (SVD adaptation): The central efficiency claim rests on the premise that source-domain singular vectors remain sufficient for target domains. No theoretical argument or targeted ablation is supplied showing when principal-subspace misalignment occurs and whether value-only scaling can recover class-discriminative directions; the skeptic concern therefore directly challenges a load-bearing assumption.
- [§4.2, Table 3] §4.2 and Table 3 (CTTA results): The reported 3.4 pp gain and 385× parameter reduction are presented without per-run standard deviations, number of random seeds, or statistical tests against the strongest baseline. Without these, it is impossible to judge whether the improvement is robust or sensitive to post-hoc hyper-parameter choices.
- [§3.3] §3.3 (diversity loss): The diversity-maximization term is motivated as a remedy for entropy-minimization collapse, yet no ablation isolates its contribution versus simply increasing the entropy weight or using other regularizers. The interaction between this loss and the fixed-vector constraint is therefore not fully characterized.
minor comments (2)
- [Abstract] The abstract lists “various distribution-shift benchmarks” without naming them; the introduction or experimental section should enumerate the exact datasets and protocols used for the TTA, CTTA, and Gradual CTTA settings.
- [§3.4] Notation for the retrieved spectral codes (e.g., how domain estimation maps to a code index) is introduced without a compact equation; a single-line definition would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and have revised the manuscript to incorporate additional ablations, statistical reporting, and clarifications where feasible.
read point-by-point responses
-
Referee: [§3.1] §3.1 (SVD adaptation): The central efficiency claim rests on the premise that source-domain singular vectors remain sufficient for target domains. No theoretical argument or targeted ablation is supplied showing when principal-subspace misalignment occurs and whether value-only scaling can recover class-discriminative directions; the skeptic concern therefore directly challenges a load-bearing assumption.
Authors: We acknowledge the value of a theoretical analysis of subspace misalignment. Our work is primarily empirical; the fixed singular vectors from the source domain are shown to capture general low-rank structure that remains useful across shifts, with adaptation occurring via singular-value scaling. In the revised manuscript we have added a targeted ablation that varies domain-shift severity, reports principal-subspace cosine similarity between source and target, and visualizes how value scaling recovers class-discriminative directions, thereby characterizing the operating regime of the method. revision: yes
-
Referee: [§4.2, Table 3] §4.2 and Table 3 (CTTA results): The reported 3.4 pp gain and 385× parameter reduction are presented without per-run standard deviations, number of random seeds, or statistical tests against the strongest baseline. Without these, it is impossible to judge whether the improvement is robust or sensitive to post-hoc hyper-parameter choices.
Authors: We agree that statistical rigor is required. We have re-executed the CTTA experiments over five independent random seeds, updated Table 3 to report mean accuracy ± standard deviation, and added paired t-test p-values against the strongest baseline to confirm statistical significance of the reported gains. revision: yes
-
Referee: [§3.3] §3.3 (diversity loss): The diversity-maximization term is motivated as a remedy for entropy-minimization collapse, yet no ablation isolates its contribution versus simply increasing the entropy weight or using other regularizers. The interaction between this loss and the fixed-vector constraint is therefore not fully characterized.
Authors: The diversity loss is specifically designed to promote distinct utilization of spectral experts under the fixed-vector constraint. In the revised manuscript we have added an ablation that directly compares the full IMSE objective against (i) entropy minimization with increased weighting and (ii) alternative regularizers (e.g., orthogonality penalties). The results isolate the benefit of the expert-alignment diversity term in mitigating collapse while preserving adaptation performance. revision: yes
Circularity Check
No circularity: empirical TTA method with external benchmark validation
full rationale
The paper presents IMSE as an empirical technique: SVD decomposition of linear layers with adaptation restricted to singular values, plus a diversity-maximization loss and domain-aware retrieval. No equations, predictions, or first-principles derivations are shown that reduce to fitted inputs or self-citations by construction. Performance numbers (SOTA, +3.4 pp, 385x fewer params) are measured against external distribution-shift benchmarks rather than being forced by internal fits. No self-citation load-bearing steps, uniqueness theorems, or ansatzes imported from prior author work appear in the provided text. The method is self-contained against external evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SVD decomposition of linear layers in Vision Transformers yields an intrinsic expert structure that can be adapted by changing only singular values while preserving useful representations.
Reference graph
Works this paper leans on
-
[1]
Visual prompt tuning for test-time domain adaptation.arXiv preprint arXiv:2210.04831,
Yunhe Gao, Xingjian Shi, Yi Zhu, Hao Wang, Zhiqiang Tang, Xiong Zhou, Mu Li, and Dimitris N Metaxas. Visual prompt tuning for test-time domain adaptation.arXiv preprint arXiv:2210.04831,
-
[2]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
Dan Hendrycks and Thomas Dietterich. Benchmarking neural network robustness to common corruptions and perturbations.arXiv preprint arXiv:1903.12261,
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[3]
The many faces of robustness: A critical analysis of out-of-distribution generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, et al. The many faces of robustness: A critical analysis of out-of-distribution generalization. InProceedings of the IEEE/CVF international conference on computer vision, pp. 8340–8349, 2021a. Dan Hendrycks, Kevin Zhao, St...
work page 2026
-
[4]
Takeshi Kojima, Yutaka Matsuo, and Yusuke Iwasawa. Robustifying vision transformer with- out retraining from scratch by test-time class-conditional feature alignment.arXiv preprint arXiv:2206.13951,
-
[5]
Daeun Lee, Jaehong Yoon, and Sung Ju Hwang. Becotta: Input-dependent online blending of experts for continual test-time adaptation.arXiv preprint arXiv:2402.08712,
-
[6]
arXiv preprint arXiv:2302.12400 (2023)
Shuaicheng Niu, Jiaxiang Wu, Yifan Zhang, Zhiquan Wen, Yaofo Chen, Peilin Zhao, and Mingkui Tan. Towards stable test-time adaptation in dynamic wild world.arXiv preprint arXiv:2302.12400,
-
[7]
Dual-path adversarial lifting for domain shift correction in online test-time adaptation
12 Published as a conference paper at ICLR 2026 Yushun Tang, Shuoshuo Chen, Zhihe Lu, Xinchao Wang, and Zhihai He. Dual-path adversarial lifting for domain shift correction in online test-time adaptation. InEuropean Conference on Computer Vision, pp. 342–359. Springer,
work page 2026
-
[8]
Tent: Fully Test-time Adaptation by Entropy Minimization
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization.arXiv preprint arXiv:2006.10726,
work page internal anchor Pith review arXiv 2006
-
[9]
Milora: Harnessing minor singular components for parameter-efficient llm finetuning
Hanqing Wang, Yixia Li, Shuo Wang, Guanhua Chen, and Yun Chen. Milora: Harnessing minor singular components for parameter-efficient llm finetuning. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), pp. 4823–4836,
work page 2025
-
[10]
URLhttps://openreview.net/forum?id=eGm22rqG93. 13 Published as a conference paper at ICLR 2026 A IMPLEMENTATION DETAILS Single-domain test-time adaptation (TTA).We use a batch size of 64 for all experiments. We employ Adam as an optimizer with Sharpness-Aware Minimization (SAM) (Foret et al., 2021). We apply a learning rate of 3e-3 for ImageNet-C (Hendryc...
work page 2026
-
[11]
Results of Supervised ViT-Base are taken from the DPAL (Tang et al., 2024)
(Hendrycks et al., 2021a) and ImageNet-R, and 4e-3 for ImageNet-A (Hendrycks et al., 2021b). Results of Supervised ViT-Base are taken from the DPAL (Tang et al., 2024). We exclude the final three transformer blocks of ViT from training, following the protocol established by SAR and DPAL. Table 11: Learning rates for each method across different pretrained...
-
[12]
under test-time adaptation setting (using supervised pretrained ViT-Base). In our experiments, we use 126 categories from DomainNet, selecting Real, Clipart, Painting, and Sketch as the evaluation domains following MME (Saito et al., 2019). For OfficeHome, we use all 65 categories and include Real World, Art, Clipart, and Product as domains. Domain adapta...
work page 2019
-
[13]
into 10 datasets of different 5,000 images. This setup reflects realistic deployment scenarios where the same domain recurs multiple times with different samples. As shown in Table 17, the proposed method maintains strong and stable performance across all rounds and consistently outperforms prior approaches. These results demonstrate that IMSE-Retrieval i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.