Recognition: no theorem link
The Differential Effects of Agreeableness and Extraversion on Older Adults' Perceptions of Conversational AI Explanations in Assistive Settings
Pith reviewed 2026-05-15 14:58 UTC · model grok-4.3
The pith
High agreeableness in an LLM voice assistant increases older adults' empathy perceptions while low agreeableness reduces likeability, but personality leaves perceived intelligence unchanged.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
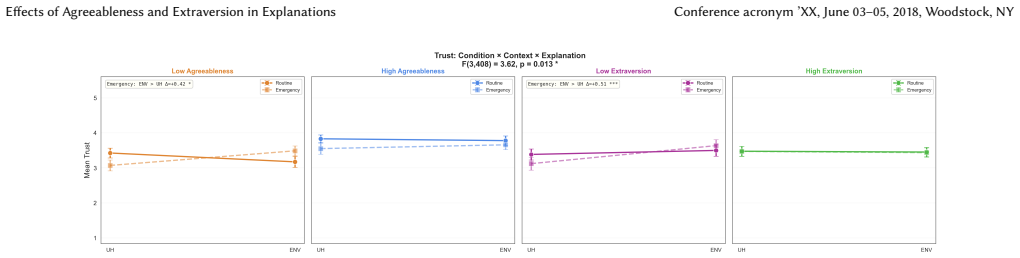
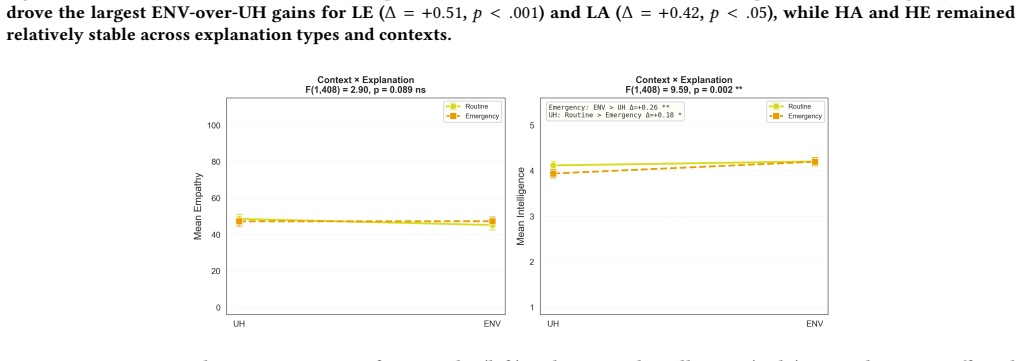
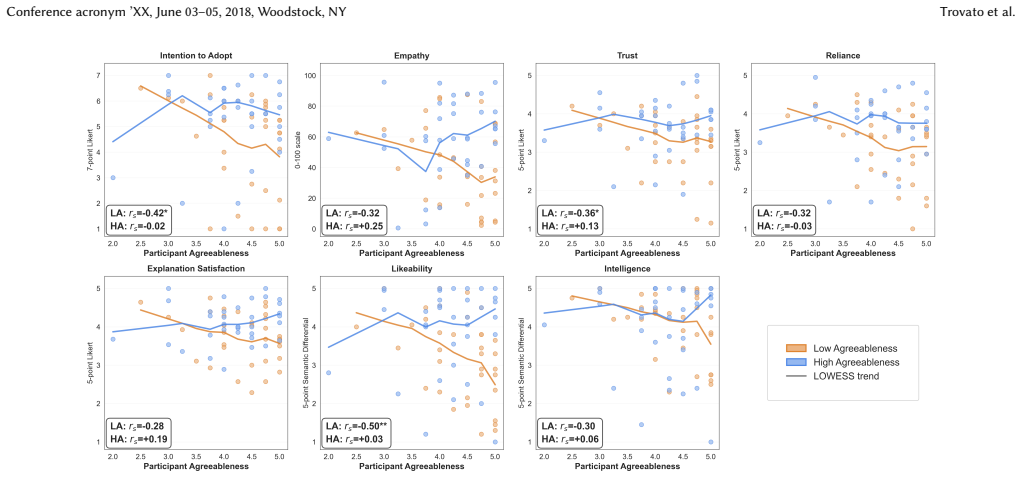
The central claim is that agreeableness and extraversion in the LLM-VA Robin produce differential effects: high agreeableness elevates empathy perceptions, low agreeableness penalizes likeability, and perceived intelligence remains unaffected, indicating personality influences social impressions without altering competence views. Real-time environmental explanations outperform conversational history explanations across empathy, likeability, trust, reliance, and satisfaction, with advantages concentrated in emergency contexts. Highly agreeable users prove especially critical of low-agreeableness agents, revealing a user-agent personality congruence effect.
What carries the argument
The controlled manipulation of agreeableness and extraversion levels in the LLM-VA agent Robin, together with the contrast between real-time environmental explanations and conversational history explanations.
Load-bearing premise
The experimental manipulations successfully created distinct perceptions of agreeableness and extraversion in the LLM-VA, and self-reported perception measures validly capture real differences in user experience for this population.
What would settle it
A follow-up study that records actual behavioral reliance or adoption rates instead of self-reports and finds no reliable differences between high- and low-agreeableness agents or between real-time and history-based explanations.
Figures










read the original abstract
Large Language Model-based Voice Assistants (LLM-VAs) are increasingly deployed in assistive settings for older adults, yet little is known about how an agent's personality shapes user perceptions of its explanations. This paper presents a mixed factorial experiment (N=140) examining how agreeableness and extraversion in an LLM-VA ("Robin") influence older adults' perceptions across seven measures: empathy, likeability, trust, reliance, satisfaction, intention to adopt, and perceived intelligence. Results reveal that high agreeableness drove stronger empathy perceptions, while low agreeableness consistently penalized likeability. Importantly, perceived intelligence remained unaffected by personality, suggesting that personality shapes sociability without altering competence perceptions. Real-time environmental explanations outperformed conversational history explanations on five measures, with advantages concentrated in emergency contexts. Notably, highly agreeable participants were especially critical of low-agreeableness agents, revealing a user-agent personality congruence effect. These findings offer design implications for personality-aware, context-sensitive LLM-VAs in assistive settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a mixed-factorial experiment (N=140 older adults) testing how agreeableness and extraversion in an LLM-based voice assistant influence perceptions of explanations across seven measures: empathy, likeability, trust, reliance, satisfaction, intention to adopt, and perceived intelligence. Key results include stronger empathy with high agreeableness, reduced likeability with low agreeableness, no personality effect on perceived intelligence, superiority of real-time environmental explanations over history-based ones (especially in emergencies), and a user-agent personality congruence effect.
Significance. If the manipulations are verified and statistical reporting is completed, the findings would provide useful empirical guidance for designing personality-aware LLM-VAs in assistive contexts for older adults, particularly by showing that personality traits primarily shape sociability perceptions without altering competence judgments and by highlighting benefits of context-sensitive explanations.
major comments (2)
- [Methods and Results] The central claims attributing differences in empathy, likeability, and the congruence effect to agreeableness and extraversion require evidence that the personality manipulations succeeded. The manuscript does not report manipulation checks or their results in the methods or results sections, leaving open the possibility that observed effects arise from other cues such as phrasing rather than the intended traits.
- [Results] The abstract and results omit essential statistical details including the specific tests used, effect sizes, p-values, and data exclusion rules for the seven perception measures. This information is needed to evaluate the reliability of claims such as real-time explanations outperforming on five measures and the personality congruence effect.
minor comments (1)
- [Abstract] The abstract would benefit from briefly specifying the four personality combinations and the two explanation types to improve self-containment.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address the major concerns regarding manipulation checks and statistical reporting below, and will incorporate the necessary revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods and Results] The central claims attributing differences in empathy, likeability, and the congruence effect to agreeableness and extraversion require evidence that the personality manipulations succeeded. The manuscript does not report manipulation checks or their results in the methods or results sections, leaving open the possibility that observed effects arise from other cues such as phrasing rather than the intended traits.
Authors: We agree that verifying the success of the personality manipulations is crucial for attributing the observed effects to agreeableness and extraversion. Although the original submission omitted these checks, we will revise the Methods section to describe the manipulation check using items from the Big Five Inventory adapted for the agent, and report the results (including means, standard deviations, and t-tests or ANOVA results) in the Results section to confirm the manipulations were effective. revision: yes
-
Referee: [Results] The abstract and results omit essential statistical details including the specific tests used, effect sizes, p-values, and data exclusion rules for the seven perception measures. This information is needed to evaluate the reliability of claims such as real-time explanations outperforming on five measures and the personality congruence effect.
Authors: We acknowledge the need for more detailed statistical reporting. In the revised manuscript, we will expand the Results section to specify the statistical tests employed (e.g., mixed-factorial ANOVA), include effect sizes, report exact p-values, and detail any data exclusion rules (such as excluding participants with incomplete surveys). We will also update the abstract to include key statistical information where feasible. This will enhance the transparency and evaluability of our findings on explanation types and personality congruence. revision: yes
Circularity Check
No circularity: purely empirical user study with independent experimental results
full rationale
The paper reports a mixed-factorial experiment (N=140) measuring older adults' perceptions of LLM-VA personality traits and explanation types across seven scales. All central claims (agreeableness effects on empathy/likeability, null effect on perceived intelligence, real-time explanations outperforming history, congruence effect) are presented as direct statistical outcomes of the manipulations and self-reported data. No equations, parameter fittings, derivations, or self-citation chains appear in the provided text; results do not reduce to inputs by construction and remain falsifiable against external replication.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Personality traits can be reliably induced and perceived via LLM prompt engineering in voice assistants
- standard math Standard statistical assumptions hold for the mixed factorial design and perception rating scales
Reference graph
Works this paper leans on
-
[1]
Rangina Ahmad, Dominik Siemon, Ulrich Gnewuch, and Susanne Robra- Bissantz. 2022. Designing Personality-Adaptive Conversational Agents for Mental Health Care.Information Systems Frontiers24, 3 (June 2022), 923–943. doi:10.1007/s10796-022-10254-9
-
[2]
Rangina Ahmad, Dominik Siemon, and Susanne Robra-Bissantz. 2020. Extra- Bot vs IntroBot: The Influence of Linguistic Cues on Communication Satisfac- tion.AMCIS 2020 Proceedings(Aug. 2020). https://aisel.aisnet.org/amcis2020/ cognitive_in_is/cognitive_in_is/10
work page 2020
-
[3]
Mohammed N Alharbi, Shihong Huang, and David Garlan. 2021. A probabilis- tic model for effective explainability based on personality traits. InEuropean Conference on Software Architecture. Springer, 205–225
work page 2021
-
[4]
Fatemeh Alizadeh, Peter Tolmie, Minha Lee, Philipp Wintersberger, Dominik Pins, and Gunnar Stevens. 2024. Voice Assistants’ Accountability through Ex- planatory Dialogues. InProceedings of the 6th ACM Conference on Conversational User Interfaces (CUI ’24). Association for Computing Machinery, New York, NY, USA, 1–12. doi:10.1145/3640794.3665557
-
[5]
Mohammad Amin Kuhail, Mohamed Bahja, Ons Al-Shamaileh, Justin Thomas, Amina Alkazemi, and Joao Negreiros. 2024. Assessing the Impact of Chatbot- Human Personality Congruence on User Behavior: A Chatbot-Based Advising System Case.IEEE Access12 (2024), 71761–71782. doi:10.1109/ACCESS.2024. 3402977
-
[6]
Alejandro Barredo Arrieta, Natalia Díaz-Rodríguez, Javier Del Ser, Adrien Ben- netot, Siham Tabik, Alberto Barbado, Salvador García, Sergio Gil-López, Daniel Molina, Richard Benjamins, et al. 2020. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Information fusion58 (2020), 82–115
work page 2020
-
[7]
Christoph Bartneck. 2023. Godspeed questionnaire series: Translations and usage. InInternational handbook of behavioral health assessment. Springer, 1–35
work page 2023
-
[8]
Christoph Bartneck, Dana Kulić, Elizabeth Croft, and Susana Zoghbi. 2009. Measurement instruments for the anthropomorphism, animacy, likeability, per- ceived intelligence, and perceived safety of robots.International journal of social robotics1, 1 (2009), 71–81
work page 2009
-
[9]
Rashmi Dutta Baruah and Mario Muñoz Organero. 2024. A brief Review on the Role of Context in Explainable AI. In2024 IEEE International Conference on Evolving and Adaptive Intelligent Systems (EAIS). IEEE, 1–6
work page 2024
-
[10]
Marilyn Bello, Rafael Bello, María-Matilde García, Ann Nowé, Iván Sevillano- García, and Francisco Herrera. 2025. A three-Level Framework for LLM- Enhanced eXplainable AI: From technical explanations to natural language. Information Systems Frontiers(2025), 1–22
work page 2025
-
[11]
Steve Benford, Gabriella Giannachi, Boriana Koleva, and Tom Rodden. 2009. From interaction to trajectories: designing coherent journeys through user expe- riences. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’09). Association for Computing Machinery, New York, NY, USA, 709–718. doi:10.1145/1518701.1518812
-
[12]
Bickmore, Lisa Caruso, Kerri Clough-Gorr, and Tim Heeren
Timothy W. Bickmore, Lisa Caruso, Kerri Clough-Gorr, and Tim Heeren. 2005. ‘It’s just like you talk to a friend’ relational agents for older adults.Interacting with Computers17, 6 (Dec. 2005), 711–735. doi:10.1016/j.intcom.2005.09.002
-
[13]
Anthony Bokolo Jnr. 2025. Examining the use of intelligent conversational voice-assistants for improved mobility behavior of older adults in smart cities. International Journal of Human–Computer Interaction41, 7 (2025), 3867–3888
work page 2025
-
[14]
Newbold, Anja Thieme, Leigh Clark, Gavin Doherty, and Benjamin Cowan
Robert Bowman, Orla Cooney, Joseph W. Newbold, Anja Thieme, Leigh Clark, Gavin Doherty, and Benjamin Cowan. 2024. Exploring how politeness impacts the user experience of chatbots for mental health support.Int. J. Hum.-Comput. Stud.184, C (April 2024). doi:10.1016/j.ijhcs.2023.103181
- [15]
-
[16]
Adrian Bussone, Simone Stumpf, and Dympna O’Sullivan. 2015. The role of explanations on trust and reliance in clinical decision support systems. In2015 international conference on healthcare informatics. IEEE, 160–169
work page 2015
-
[17]
Bengisu Cagiltay, Hui-Ru Ho, Kaiwen Sun, Zhaoyuan Su, Yuxing Wu, Olivia K Richards, Qiao Jin, Junnan Yu, Jerry Alan Fails, Jason Yip, et al. 2024. Methods for Family-Centered Design: Bridging the Gap Between Research and Practice. InExtended Abstracts of the CHI Conference on Human Factors in Computing Systems. 1–6
work page 2024
- [18]
-
[19]
Lauren Cerino, Adam Felts, Alexa Balmuth, Taylor Brennan, Chaiwoo Lee, and Joseph Coughlin. 2025. Older Adults’ Perspectives on Artificial Intelligence as a Source of Advice.Innovation in Aging9, Supplement_2 (2025), igaf122–1371
work page 2025
-
[20]
Szeyi Chan, Jiachen Li, Siman Ao, Yufei Wang, Ibrahim Bilau, Brian D Jones, Eunhwa Yang, Elizabeth D Mynatt, and Xiang Zhi Tan. 2025. Insights from Designing Context-Aware Meal Preparation Assistance for Older Adults with Mild Cognitive Impairment (MCI) and Their Care Partners. InProceedings of the 2025 ACM Designing Interactive Systems Conference. 3263–3279
work page 2025
-
[21]
Mango Mango, How to Let The Lettuce Dry Without A Spinner?
Szeyi Chan, Jiachen Li, Bingsheng Yao, Amama Mahmood, Chien-Ming Huang, Holly Jimison, Elizabeth D Mynatt, and Dakuo Wang. 2025. " Mango Mango, How to Let The Lettuce Dry Without A Spinner?": Exploring User Perceptions of Using An LLM-Based Conversational Assistant Toward Cooking Partner. Proceedings of the ACM on Human-Computer Interaction9, 7 (2025), 1–35
work page 2025
-
[22]
Mai Lee Chang, Alicia Lee, Nara Han, Anna Huang, Hugo Simão, Samantha Reig, Abdullah Ubed Mohammad Ali, Rebekah Martinez, Neeta M Khanuja, John Zimmerman, et al. 2024. Dynamic Agent Affiliation: Who Should the AI Agent Work for in the Older Adult’s Care Network?. InProceedings of the 2024 ACM Designing Interactive Systems Conference. 1774–1788
work page 2024
-
[23]
Mai Lee Chang, Samantha Reig, Alicia Lee, Anna Huang, Hugo Simão, Nara Han, Neeta M Khanuja, Abdullah Ubed Mohammad Ali, Rebekah Martinez, John Zimmerman, et al. 2025. Unremarkable to remarkable AI agent: Explor- ing boundaries of agent intervention for adults with and without cognitive impairment.Proceedings of the ACM on Human-Computer Interaction9, 2 (...
work page 2025
-
[24]
Jessie Chin and Smit Desai. 2021. Being a nice partner: The effects of age and interaction types on the perceived social abilities of conversational agents. In TMS Proceedings 2021. PubPub
work page 2021
-
[25]
Jessie Chin, Smit Desai, Sheny Lin, and Shannon Mejia. 2024. Like my aunt dorothy: effects of conversational styles on perceptions, acceptance and metaphorical descriptions of voice assistants during later adulthood.Proceedings of the ACM on Human-Computer Interaction8, CSCW1 (2024), 1–21
work page 2024
-
[26]
Sunny Consolvo, Katherine Everitt, Ian Smith, and James A Landay. 2006. Design requirements for technologies that encourage physical activity. InProceedings of the SIGCHI conference on Human Factors in computing systems. 457–466
work page 2006
-
[27]
Samuel Rhys Cox, Joel Wester, and Niels van Berkel. 2026. Polite But Bor- ing? Trade-offs Between Engagement and Psychological Reactance to Chatbot Feedback Styles. doi:10.48550/arXiv.2601.20683 arXiv:2601.20683 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.20683 2026
-
[28]
Andrea Cuadra, Jessica Bethune, Rony Krell, Alexa Lempel, Katrin Hänsel, Armin Shahrokni, Deborah Estrin, and Nicola Dell. 2023. Designing voice-first ambient interfaces to support aging in place. InProceedings of the 2023 ACM Designing Interactive Systems Conference. 2189–2205
work page 2023
-
[29]
Scott Davidoff, John Zimmerman, and Anind K Dey. 2010. How routine learners can support family coordination. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems. 2461–2470
work page 2010
-
[30]
Yang Deng, Wenqiang Lei, Minlie Huang, and Tat-Seng Chua. 2023. Rethinking conversational agents in the era of llms: Proactivity, non-collaborativity, and beyond. InProceedings of the Annual international ACM SIGIR conference on research and development in information retrieval in the Asia Pacific region. 298– 301
work page 2023
-
[31]
Smit Desai and Jessie Chin. 2023. OK Google, let’s learn: using voice user interfaces for informal self-regulated learning of health topics among younger and older adults. InProceedings of the 2023 CHI conference on human factors in computing systems. 1–21
work page 2023
-
[32]
Smit Desai, Mateusz Dubiel, and Luis A. Leiva. 2024. Examining Humanness as a Metaphor to Design Voice User Interfaces. InProceedings of the 6th ACM Con- ference on Conversational User Interfaces (CUI ’24). Association for Computing Machinery, New York, NY, USA, 1–15. doi:10.1145/3640794.3665535
-
[33]
Smit Desai and Michael Twidale. 2023. Metaphors in voice user interfaces: a slippery fish.ACM Transactions on Computer-Human Interaction30, 6 (2023), 1–37
work page 2023
-
[34]
Ameet Deshpande, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, and Karthik Narasimhan. 2023. Toxicity in chatgpt: Analyzing persona-assigned language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 1236–1270. doi:1...
-
[35]
Blanca Deusdad. 2025. Service-learning activity: a memory box for the social participation of older adults living with dementia and their informal caregivers. Social Work Education(2025), 1–19
work page 2025
-
[36]
Colin G. DeYoung, Lena C. Quilty, and Jordan B. Peterson. 2007. Between facets and domains: 10 aspects of the Big Five.Journal of Personality and Social Psychology93, 5 (2007), 880–896. doi:10.1037/0022-3514.93.5.880 Place: US
-
[37]
M. Brent Donnellan, Frederick L. Oswald, Brendan M. Baird, and Richard E. Lucas. 2006. The Mini-IPIP Scales: Tiny-yet-effective measures of the Big Five Factors of Personality.Psychological Assessment18, 2 (2006), 192–203. Effects of Agreeableness and Extraversion in Explanations Conference acronym ’XX, June 03–05, 2018, Woodstock, NY doi:10.1037/1040-359...
-
[38]
Scott Saponas, Yang Li, and James A
Steven Dow, T. Scott Saponas, Yang Li, and James A. Landay. 2006. External representations in ubiquitous computing design and the implications for design tools. InProceedings of the 6th conference on Designing Interactive systems (DIS ’06). Association for Computing Machinery, New York, NY, USA, 241–250. doi:10. 1145/1142405.1142443
-
[39]
Mark Edmonds, Feng Gao, Hangxin Liu, Xu Xie, Siyuan Qi, Brandon Rothrock, Yixin Zhu, Ying Nian Wu, Hongjing Lu, and Song-Chun Zhu. 2019. A tale of two explanations: Enhancing human trust by explaining robot behavior.Science Robotics4, 37 (2019), eaay4663
work page 2019
-
[40]
Upol Ehsan, Q Vera Liao, Michael Muller, Mark O Riedl, and Justin D Weisz
-
[41]
In Proceedings of the 2021 CHI conference on human factors in computing systems
Expanding explainability: Towards social transparency in ai systems. In Proceedings of the 2021 CHI conference on human factors in computing systems. 1–19
work page 2021
-
[42]
Upol Ehsan and Mark O Riedl. 2020. Human-centered explainable ai: Towards a reflective sociotechnical approach. InInternational conference on human- computer interaction. Springer, 449–466
work page 2020
-
[43]
Upol Ehsan, Pradyumna Tambwekar, Larry Chan, Brent Harrison, and Mark O Riedl. 2019. Automated rationale generation: a technique for explainable AI and its effects on human perceptions. InProceedings of the 24th international conference on intelligent user interfaces. 263–274
work page 2019
-
[44]
Upol Ehsan, Philipp Wintersberger, Q Vera Liao, Martina Mara, Marc Streit, Sandra Wachter, Andreas Riener, and Mark O Riedl. 2021. Operationalizing human-centered perspectives in explainable AI. InExtended abstracts of the 2021 CHI conference on human factors in computing systems. 1–6
work page 2021
-
[45]
Andreas Ejupi, Yves J Gschwind, Trinidad Valenzuela, Stephen R Lord, and Kim Delbaere. 2016. A kinect and inertial sensor-based system for the self-assessment of fall risk: A home-based study in older people.Human–Computer Interaction 31, 3-4 (2016), 261–293
work page 2016
-
[46]
Mira El Kamali, Leonardo Angelini, Denis Lalanne, Omar Abou Khaled, and Elena Mugellini. 2020. Multimodal conversational agent for older adults’ behav- ioral change. InCompanion Publication of the 2020 International Conference on Multimodal Interaction. 270–274
work page 2020
-
[47]
Lisa A. Elkin, Matthew Kay, James J. Higgins, and Jacob O. Wobbrock. 2021. An Aligned Rank Transform Procedure for Multifactor Contrast Tests. InThe 34th Annual ACM Symposium on User Interface Software and Technology (UIST ’21). Association for Computing Machinery, New York, NY, USA, 754–768. doi:10. 1145/3472749.3474784
-
[48]
Juliana J Ferreira and Mateus S Monteiro. 2020. What are people doing about XAI user experience? A survey on AI explainability research and practice. In International conference on human-computer interaction. Springer, 56–73
work page 2020
-
[49]
Susan T. Fiske, Amy J. C. Cuddy, and Peter Glick. 2007. Universal dimensions of social cognition: warmth and competence.Trends in Cognitive Sciences11, 2 (Feb. 2007), 77–83. doi:10.1016/j.tics.2006.11.005
-
[50]
Jodi Forlizzi. 2007. How robotic products become social products: an ethno- graphic study of cleaning in the home. InProceedings of the ACM/IEEE interna- tional conference on Human-robot interaction. 129–136
work page 2007
-
[51]
Vera Gallistl. 2024. AI explainability in long-term care: A sociological inquiry. Innovation in Aging8, Suppl 1 (2024), 342
work page 2024
-
[52]
Andrew Gambino, Jesse Fox, and Rabindra A. Ratan. 2020. Building a stronger CASA: Extending the computers are social actors paradigm.Human-Machine Communication1 (Jan. 2020), 71–85. doi:10.3316/INFORMIT.097034846749023
-
[53]
Cristina Getson and Goldie Nejat. 2021. Socially assistive robots helping older adults through the pandemic and life after COVID-19.Robotics10, 3 (2021), 106
work page 2021
-
[54]
Zohar Gilad, Ofra Amir, and Liat Levontin. 2021. The Effects of Warmth and Competence Perceptions on Users’ Choice of an AI System. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI ’21). Association for Computing Machinery, New York, NY, USA, 1–13. doi:10.1145/ 3411764.3446863
-
[55]
Alastair J Gill and Jon Oberlander. 2019. Taking care of the linguistic features of extraversion. InProceedings of the twenty-fourth annual conference of the cognitive science society. Routledge, 363–368
work page 2019
-
[56]
2023.Understanding the Disuse of Conversational Agents Among Older Adults
Emily Christine Gleaton. 2023.Understanding the Disuse of Conversational Agents Among Older Adults. Master’s thesis. Georgia Institute of Technology
work page 2023
-
[57]
Kentaro Go and John M Carroll. 2003. Scenario-based task analysis.The handbook of task analysis for human-computer interaction117 (2003)
work page 2003
-
[58]
David A Gold. 2012. An examination of instrumental activities of daily living assessment in older adults and mild cognitive impairment.Journal of clinical and experimental neuropsychology34, 1 (2012), 11–34
work page 2012
-
[59]
Lewis R. Goldberg. 1992. The development of markers for the Big-Five factor structure.Psychological Assessment4, 1 (1992), 26–42. doi:10.1037/1040-3590.4. 1.26 Place: US Publisher: American Psychological Association
-
[60]
Carla Graf. 2008. The Lawton instrumental activities of daily living scale.AJN The American Journal of Nursing108, 4 (2008), 52–62
work page 2008
-
[61]
Amar Halilovic and Senka Krivic. 2023. The influence of a robot’s personality on real-time explanations of its navigation. InInternational Conference on Social Robotics. Springer, 133–147
work page 2023
-
[62]
I’ve never seen a glass ceiling better represented
Helena A. Haxvig, Vincenzo D’Andrea, and Maurizio Teli. 2025. “I’ve never seen a glass ceiling better represented”: Bias and gendering in LLM-generated synthetic personas from a participatory design perspective.International Journal of Human-Computer Studies205 (Nov. 2025), 103651. doi:10.1016/j.ijhcs.2025. 103651
-
[63]
Holger Heppner, Birte Schiffhauer, and Udo Seelmeyer. 2024. Conveying chatbot personality through conversational cues in social media messages.Computers in Human Behavior: Artificial Humans2, 1 (Jan. 2024), 100044. doi:10.1016/j. chbah.2024.100044
work page doi:10.1016/j 2024
-
[64]
Robert R Hoffman, Shane T Mueller, Gary Klein, and Jordan Litman. 2023. Measures for explainable AI: Explanation goodness, user satisfaction, mental models, curiosity, trust, and human-AI performance.Frontiers in Computer Science5 (2023), 1096257
work page 2023
-
[65]
Xinhui Hu, Smit Desai, Morgan Lundy, and Jessie Chin. 2025. Beyond Func- tionality: Co-Designing Voice User Interfaces for Older Adults’ Well-being. InProceedings of the 7th ACM Conference on Conversational User Interfaces (CUI ’25). Association for Computing Machinery, New York, NY, USA, 1–15. doi:10.1145/3719160.3736613
-
[66]
Yaxin Hu, Yuxiao Qu, Adam Maus, and Bilge Mutlu. 2022. Polite or Direct? Conversation Design of a Smart Display for Older Adults Based on Politeness Theory. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems (CHI ’22). Association for Computing Machinery, New York, NY, USA, 1–15. doi:10.1145/3491102.3517525
-
[67]
Yuanhui Huang, Quan Zhou, and Anne Marie Piper. 2025. Designing Conver- sational AI for Aging: A Systematic Review of Older Adults’ Perceptions and Needs. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, 1–20. doi:10.1145/3706598.3713578
-
[68]
Hira Jamshed, Novia Nurain, and Robin N. Brewer. 2025. Designing Accessible Audio Nudges for Voice Interfaces. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, 1–16. doi:10.1145/3706598.3713563
-
[69]
Jiun-Yin Jian, Ann M Bisantz, and Colin G Drury. 2000. Foundations for an empirically determined scale of trust in automated systems.International journal of cognitive ergonomics4, 1 (2000), 53–71
work page 2000
-
[70]
Hang Jiang, Xiajie Zhang, Xubo Cao, Cynthia Breazeal, Deb Roy, and Jad Kabbara
-
[71]
PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits. InFindings of the Association for Computational Linguistics: NAACL 2024, Kevin Duh, Helena Gomez, and Steven Bethard (Eds.). Association for Computational Linguistics, Mexico City, Mexico, 3605–3627. doi:10.18653/v1/2024.findings-naacl.229
-
[72]
Oliver P. John, E. M. Donahue, and R. L. Kentle. 1991. Big Five Inventory. doi:10.1037/t07550-000 Institution: American Psychological Association
-
[73]
O. P. John and Sanjay Srivastava. 1999. The Big-Five Trait Taxonomy: History, Measurement, and Theoretical Perspectives. InHandbook of Personality: Theory and Research, O. P. John and L.A. Pervin (Eds.). Vol. 2. Guilford Press
work page 1999
- [74]
-
[75]
Sidney Katz. 1983. Assessing self-maintenance: activities of daily living, mobility, and instrumental activities of daily living.Journal of the American Geriatrics Society31, 12 (1983), 721–727
work page 1983
-
[76]
S. Kemper and T. Harden. 1999. Experimentally disentangling what’s beneficial about elderspeak from what’s not.Psychology and Aging14, 4 (Dec. 1999), 656–670. doi:10.1037//0882-7974.14.4.656
-
[77]
Pranav Khadpe, Ranjay Krishna, Li Fei-Fei, Jeffrey T. Hancock, and Michael S. Bernstein. 2020. Conceptual Metaphors Impact Perceptions of Human-AI Collab- oration.Proc. ACM Hum.-Comput. Interact.4, CSCW2 (Oct. 2020), 163:1–163:26. doi:10.1145/3415234
-
[78]
Han-Jong Kim, Chang Min Kim, and Tek-Jin Nam. 2018. SketchStudio: Ex- perience Prototyping with 2.5-Dimensional Animated Design Scenarios. In Proceedings of the 2018 Designing Interactive Systems Conference (DIS ’18). Asso- ciation for Computing Machinery, New York, NY, USA, 831–843. doi:10.1145/ 3196709.3196736
-
[79]
Jieun Kim and Susan R. Fussell. 2025. Should Voice Agents Be Polite in an Emergency? Investigating Effects of Speech Style and Voice Tone in Emergency Simulation. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, 1–17. doi:10.1145/3706598.3714203
-
[80]
Sunnie SY Kim, Jennifer Wortman Vaughan, Q Vera Liao, Tania Lombrozo, and Olga Russakovsky. 2025. Fostering appropriate reliance on large language models: The role of explanations, sources, and inconsistencies. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–19
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.