Recognition: no theorem link
Collective AI can amplify tiny perturbations into divergent decisions
Pith reviewed 2026-05-15 14:20 UTC · model grok-4.3
The pith
Multi-LLM deliberation amplifies tiny perturbations into divergent decisions
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Iterative multi-LLM deliberation amplifies tiny perturbations into divergent conversational trajectories and different final decisions. In a fully deterministic self-hosted benchmark, exact reruns are identical, yet small meaning-preserving changes to the scenario text still separate over time and often alter the final recommendation. In deployed black-box API systems, nominally identical committee runs likewise remain unstable even at temperature 0. Across 12 policy scenarios, instability in collective AI arises from sensitivity to nearby initial conditions under repeated interaction itself. Committee architecture modulates this instability: role structure, model composition, and feedback内存
What carries the argument
Iterative multi-LLM deliberation, the repeated back-and-forth among models that builds each response on prior outputs and thereby magnifies small initial differences
Load-bearing premise
That the tested meaning-preserving changes to scenario text are small enough and equivalent enough that any resulting divergence must come from the interaction dynamics rather than unmeasured differences in model interpretation.
What would settle it
A controlled deterministic run in which the exact same set of meaning-preserving scenario variants produces identical committee trajectories and final recommendations across repeated trials.
Figures



read the original abstract
Large language models are increasingly deployed not as single assistants but as committees whose members deliberate and then vote or synthesize a decision. Such systems are often expected to be more robust than individual models. We show that iterative multi-LLM deliberation can instead amplify tiny perturbations into divergent conversational trajectories and different final decisions. In a fully deterministic self-hosted benchmark, exact reruns are identical, yet small meaning-preserving changes to the scenario text still separate over time and often alter the final recommendation. In deployed black-box API systems, nominally identical committee runs likewise remain unstable even at temperature 0, where many users expect near-determinism. Across 12 policy scenarios, these findings indicate that instability in collective AI is not only a consequence of residual platform-side stochasticity, but can arise from sensitivity to nearby initial conditions under repeated interaction itself. Additional deployed experiments show that committee architecture modulates this instability: role structure, model composition, and feedback memory can each alter the degree of divergence. Collective AI therefore faces a stability problem, not only an accuracy problem: deterministic execution alone does not guarantee predictable or auditable deliberative outcomes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that iterative multi-LLM deliberation in collective AI systems can amplify tiny meaning-preserving perturbations in input scenarios into divergent conversational trajectories and different final decisions. This occurs even in fully deterministic self-hosted benchmarks where exact reruns produce identical outputs, and persists in black-box API deployments at temperature 0. Across 12 policy scenarios, the work shows that committee architecture (role structure, model composition, feedback memory) modulates the degree of divergence, indicating that instability arises from interaction dynamics rather than solely from platform stochasticity.
Significance. If the central claim holds after addressing documentation gaps, the result identifies a fundamental stability problem in collective AI that is distinct from accuracy issues. Deterministic execution alone does not ensure predictable or auditable outcomes, with direct implications for high-stakes deployments such as policy synthesis or decision committees. The use of controlled deterministic benchmarks to isolate interaction effects is a methodological strength that allows falsifiable observation of amplification without relying on fitted parameters.
major comments (3)
- [Experimental Setup] The central claim requires that observed divergence stems from interaction dynamics amplifying perturbations rather than unmeasured interpretive differences. The manuscript describes 'small meaning-preserving changes' across 12 scenarios but provides no explicit construction method, semantic similarity metric, or human validation protocol to confirm equivalence. This is load-bearing for the deterministic self-hosted results, where any residual difference would deterministically produce divergent trajectories without invoking amplification.
- [Deployed Experiments] In the black-box API experiments, instability at temperature 0 is attributed to interaction sensitivity, yet the paper does not detail controls for API-side consistency (e.g., request ordering, caching, or version pinning) beyond temperature. This leaves open whether platform behavior interacts with the perturbations, weakening the separation between stochasticity and deterministic sensitivity.
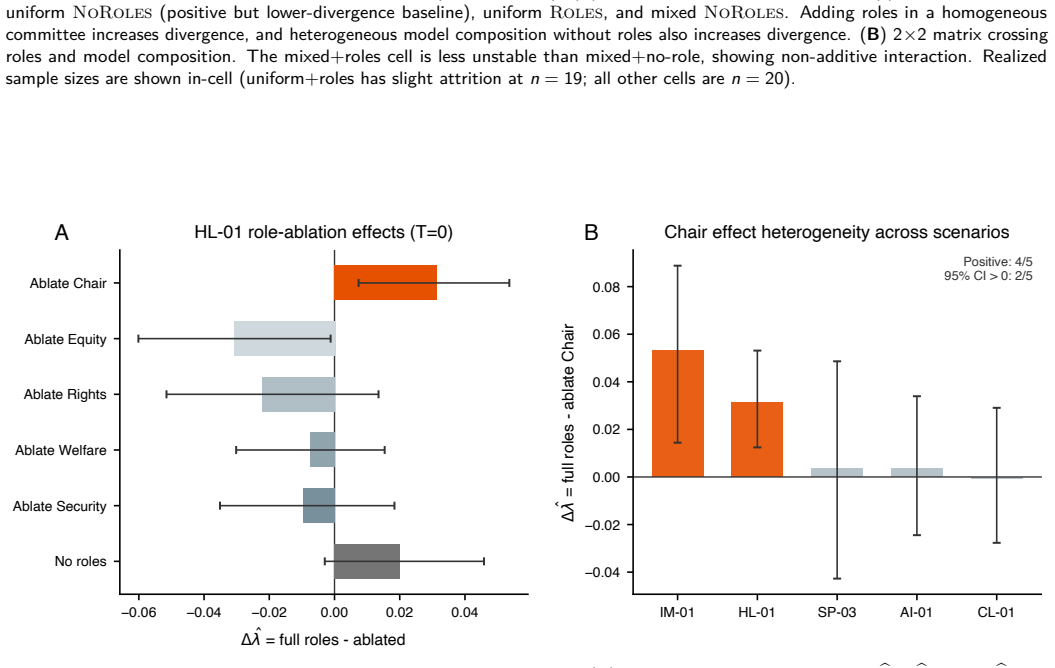
- [Architecture Modulation Results] The claim that committee architecture modulates instability is supported by additional experiments, but the manuscript should specify quantitative divergence metrics (e.g., trajectory similarity or decision agreement rates) and report statistical significance or variance across the 12 scenarios to substantiate the modulation effects.
minor comments (1)
- [Abstract] The abstract states that 'exact reruns are identical' but should report the number of reruns performed and the precise determinism guarantees of the self-hosted setup to allow readers to assess the strength of the baseline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for clarifying our experimental methods and results on instability in collective AI systems. We address each major comment below and have revised the manuscript accordingly to strengthen the documentation and quantitative support for our claims.
read point-by-point responses
-
Referee: [Experimental Setup] The central claim requires that observed divergence stems from interaction dynamics amplifying perturbations rather than unmeasured interpretive differences. The manuscript describes 'small meaning-preserving changes' across 12 scenarios but provides no explicit construction method, semantic similarity metric, or human validation protocol to confirm equivalence. This is load-bearing for the deterministic self-hosted results, where any residual difference would deterministically produce divergent trajectories without invoking amplification.
Authors: We agree that explicit details on perturbation construction are necessary to rule out initial interpretive differences. In the revised manuscript, we have added a new 'Perturbation Generation Protocol' subsection in the Methods. Perturbations were generated via targeted synonym substitutions and minor syntactic rephrasings using a controlled prompt on a separate model, followed by verification with sentence embeddings (all-MiniLM-L6-v2, cosine similarity threshold >0.93) and dual-author manual review confirming semantic equivalence in all cases. This protocol is now fully documented to support the deterministic benchmark claims. revision: yes
-
Referee: [Deployed Experiments] In the black-box API experiments, instability at temperature 0 is attributed to interaction sensitivity, yet the paper does not detail controls for API-side consistency (e.g., request ordering, caching, or version pinning) beyond temperature. This leaves open whether platform behavior interacts with the perturbations, weakening the separation between stochasticity and deterministic sensitivity.
Authors: We have expanded the deployed experiments section to include these controls. All API requests used pinned model versions (e.g., gpt-4-0613), identical payloads without cache directives, and were executed in randomized order across separate sessions on different days. Single-model baseline repetitions confirmed no platform-induced divergence, isolating the effect to committee interactions. These details are now specified in Section 3.2 of the revision. revision: yes
-
Referee: [Architecture Modulation Results] The claim that committee architecture modulates instability is supported by additional experiments, but the manuscript should specify quantitative divergence metrics (e.g., trajectory similarity or decision agreement rates) and report statistical significance or variance across the 12 scenarios to substantiate the modulation effects.
Authors: We have augmented the results with explicit quantitative metrics. Trajectory divergence is quantified using normalized Levenshtein distance on full deliberation logs, and decision agreement is reported as the percentage of matching final recommendations. For each architecture variant, we now provide means, standard deviations across the 12 scenarios, and p-values from paired statistical tests (Wilcoxon signed-rank). These are presented in an updated Table 2 and Section 4.3 to substantiate the modulation findings. revision: yes
Circularity Check
No circularity: empirical observations of deliberation instability are independent of inputs
full rationale
The paper reports direct experimental results from controlled multi-LLM committee runs across 12 scenarios, comparing exact reruns versus small meaning-preserving text changes. No equations, fitted parameters, self-citations, or derivations are invoked to generate the claimed outcomes; divergence is measured as an observed phenomenon rather than predicted from prior quantities. The central claim therefore rests on external benchmarks (deterministic self-hosted execution and API behavior) and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
URLhttps://arxiv.org/abs/2308.08155. Weize Chen, Yusheng Su, Jingwei Zuo, et al. AgentVerse: Fa- cilitating multi-agent collaboration and exploring emergent behaviors in agents,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors
URLhttps://arxiv.org/abs/ 2308.10848. Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: Communicative agents for mind exploration of large language model society,
work page internal anchor Pith review arXiv
-
[3]
CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society
URL https://arxiv.org/abs/2303.17760. Sirui Hong, Ming Zhuge, Junjie Chen, et al. MetaGPT: Meta programming for multi-agent collaborative framework,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
URLhttps://arxiv.org/abs/2308.00352. Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Mered- ith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behav- ior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST), pages 1–22,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
doi:10.1145/3586183.3606763. Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting. InInternational Conference on Learning Representations (ICLR),
-
[6]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, et al
URLhttps://arxiv.org/ abs/2310.11324. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, et al. Judging LLM-as-a-Judge with MT-Bench and chatbot arena. InAd- vances in Neural Information Processing Systems (NeurIPS), volume 36,
-
[7]
Amos Tversky and Daniel Kahneman
doi:10.1111/ 1467-9760.00148. Amos Tversky and Daniel Kahneman. The framing of decisions and the psychology of choice.Science, 211(4481):453–458,
-
[8]
doi:10.1126/science.7455683. Scott E. Page.The Difference: How the Power of Diver- sity Creates Better Groups, Firms, Schools, and Societies. Princeton University Press,
-
[9]
Jean-Pierre Eckmann and David Ruelle
doi:10.1073/pnas.0403723101. Jean-Pierre Eckmann and David Ruelle. Ergodic theory of chaos and strange attractors.Reviews of Modern Physics, 57(3):617–656,
-
[10]
Edward Ott.Chaos in Dynamical Systems
doi:10.1103/RevModPhys.57.617. Edward Ott.Chaos in Dynamical Systems. Cambridge Univer- sity Press, 2nd edition,
-
[11]
Joelle Pineau, Philippe Vincent-Lamarre, Koustuv Sinha, Vin- cent Larivière, Alina Beygelzimer, Florence d’Alché Buc, Emily Fox, and Hugo Larochelle. Improving reproducibility in machine learning research: A report from the neurips 2019 reproducibility program.Journal of Machine Learning Research, 22(164):1–20,
work page 2019
-
[12]
doi: 10.1109/MCSE.2007.55. 9
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.