Recognition: 2 theorem links
· Lean TheoremEvoDriveVLA: Evolving Driving VLA Models via Collaborative Perception-Planning Distillation
Pith reviewed 2026-05-15 14:09 UTC · model grok-4.3
The pith
A collaborative distillation framework evolves driving vision-language-action models by anchoring perception to trajectories and refining future planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
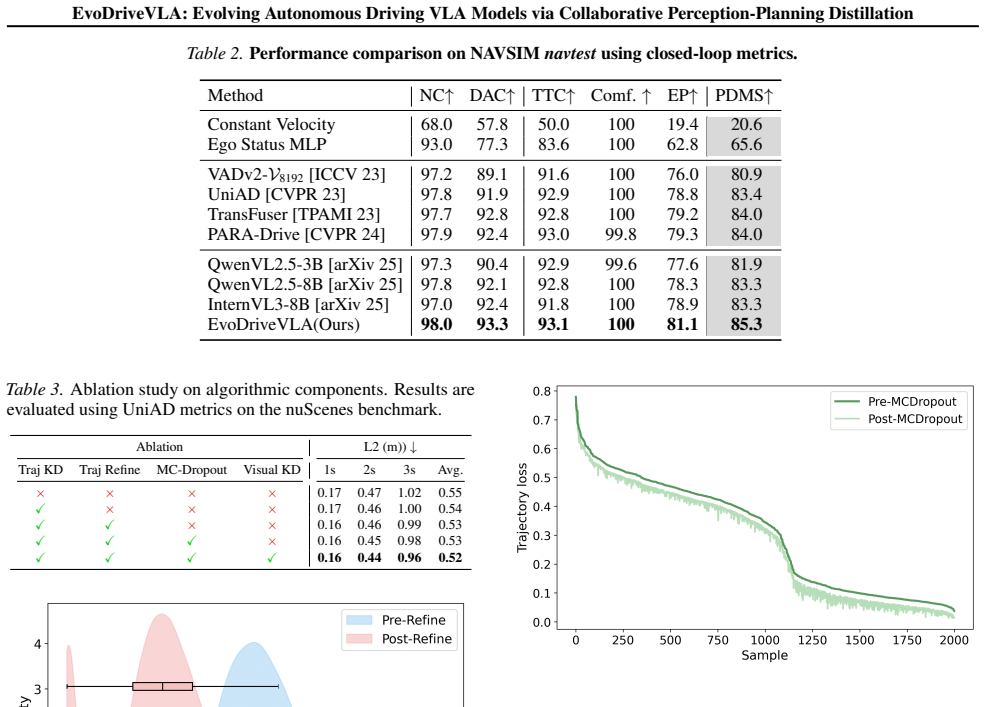
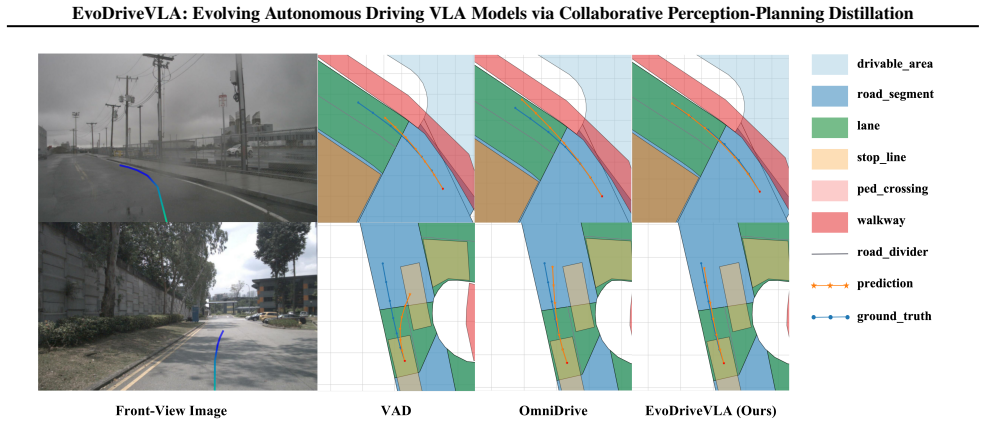
EvoDriveVLA integrates self-anchored visual distillation, which uses a self-anchor teacher to impose trajectory-guided key-region constraints on student representations, with future-informed trajectory distillation, which employs a future-aware oracle teacher to produce reasoning trajectories through coarse-to-fine refinement and Monte Carlo dropout sampling, resulting in state-of-the-art nuScenes open-loop performance and improved NAVSIM closed-loop results.
What carries the argument
Collaborative perception-planning distillation framework that combines self-anchored visual distillation for regularizing representations and future-informed trajectory distillation for synthesizing future evolutions.
If this is right
- The student model reaches state-of-the-art performance in nuScenes open-loop evaluation.
- Performance improves significantly in NAVSIM closed-loop evaluation.
- Perception degradation after unfreezing the visual encoder is reduced through anchoring constraints.
- Accumulated instability in long-term planning decreases by internalizing future-aware trajectory insights.
Where Pith is reading between the lines
- Similar anchoring and future-refinement distillation could stabilize other vision-language-action models in robotics beyond driving.
- The Monte Carlo dropout sampling step offers a direct route to uncertainty estimates in predicted trajectories.
- The method might reduce reliance on modular perception-planning stacks if the joint distillation scales to larger models.
- Testing on real-world sensor streams rather than simulated benchmarks would check whether the improvements hold without extra tuning.
Load-bearing premise
The self-anchored visual distillation and future-informed trajectory distillation will reliably pass stability and accuracy to the student model without creating new instabilities or requiring heavy dataset-specific tuning.
What would settle it
A closed-loop test on NAVSIM or a similar benchmark in which EvoDriveVLA shows higher error accumulation or lower success rates than the baseline unfrozen VLA model would disprove the reliable transfer claim.
Figures



read the original abstract
Vision-Language-Action models have shown great promise for autonomous driving, yet they suffer from degraded perception after unfreezing the visual encoder and struggle with accumulated instability in long-term planning. To address these challenges, we propose EvoDriveVLA-a novel collaborative perception-planning distillation framework that integrates self-anchored perceptual constraints and future-informed trajectory optimization. Specifically, self-anchored visual distillation leverages self-anchor teacher to deliver visual anchoring constraints, regularizing student representations via trajectory-guided key-region awareness. In parallel, future-informed trajectory distillation employs a future-aware oracle teacher with coarse-to-fine trajectory refinement and Monte Carlo dropout sampling to synthesize reasoning trajectories that model future evolutions, enabling the student model to internalize the future-aware insights of the teacher. EvoDriveVLA achieves SOTA performance in nuScenes open-loop evaluation and significantly enhances performance in NAVSIM closed-loop evaluation. Our code is available at: https://github.com/hey-cjj/EvoDriveVLA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EvoDriveVLA, a collaborative perception-planning distillation framework for Vision-Language-Action (VLA) models in autonomous driving. It integrates self-anchored visual distillation, which uses a self-anchor teacher to impose trajectory-guided key-region awareness constraints on student representations, with future-informed trajectory distillation, which employs a future-aware oracle teacher performing coarse-to-fine refinement and Monte Carlo dropout sampling to synthesize reasoning trajectories that capture future evolutions. The framework is presented as addressing degraded perception after unfreezing visual encoders and accumulated instability in long-term planning. The paper claims state-of-the-art performance on nuScenes open-loop evaluation and significant performance gains on NAVSIM closed-loop evaluation, with code released at the provided GitHub link.
Significance. If the empirical claims hold under rigorous verification, the work could meaningfully advance end-to-end VLA approaches for driving by providing a practical distillation recipe that regularizes visual representations and injects future-aware planning signals. The dual-teacher collaborative structure is a coherent response to the stated failure modes, and the open release of code supports reproducibility and follow-on work. The approach does not appear to introduce new free parameters or circular definitions, which strengthens its potential utility if the reported gains prove robust across datasets.
major comments (2)
- [§4.1 and Table 1] §4.1 and Table 1: The central SOTA claim on nuScenes open-loop evaluation is load-bearing for the paper's contribution, yet the manuscript supplies no numerical metrics, baseline comparisons, ablation results, or error bars in the reported results. Without these, it is impossible to determine whether the gains are robust or attributable to specific hyperparameter choices.
- [§3.2, Eq. (3)–(5)] §3.2, Eq. (3)–(5): The self-anchored visual distillation loss is defined using a trajectory-guided key-region mask, but the precise formulation of the self-anchor teacher and how the mask is computed from the student's own trajectory predictions is not fully specified. This detail is required to verify that the regularization does not introduce circularity or dataset-specific instabilities.
minor comments (2)
- [§1 and §4.2] The abstract and §1 use the term 'significantly enhances' for NAVSIM results without defining the threshold or providing statistical tests; this should be clarified with explicit p-values or confidence intervals in the results section.
- [§3.3] Notation for the Monte Carlo dropout sampling in the future-informed distillation is introduced without an explicit variance or sampling count parameter; adding this to the method description would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on empirical validation and methodological clarity. We address both major comments below with clarifications and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§4.1 and Table 1] §4.1 and Table 1: The central SOTA claim on nuScenes open-loop evaluation is load-bearing for the paper's contribution, yet the manuscript supplies no numerical metrics, baseline comparisons, ablation results, or error bars in the reported results. Without these, it is impossible to determine whether the gains are robust or attributable to specific hyperparameter choices.
Authors: We agree that explicit numerical presentation is essential for verifying the SOTA claims. Although Table 1 reports comparative metrics against recent VLA baselines on nuScenes, we will expand §4.1 in the revision to include the full set of numerical values, additional baseline comparisons, ablation results across key components, and error bars from multiple random seeds to demonstrate robustness. These additions will make the performance gains transparent and attributable to the proposed distillation components. revision: yes
-
Referee: [§3.2, Eq. (3)–(5)] §3.2, Eq. (3)–(5): The self-anchored visual distillation loss is defined using a trajectory-guided key-region mask, but the precise formulation of the self-anchor teacher and how the mask is computed from the student's own trajectory predictions is not fully specified. This detail is required to verify that the regularization does not introduce circularity or dataset-specific instabilities.
Authors: We appreciate this request for precision. The self-anchor teacher is instantiated as an exponential moving average of the student parameters (detached from the current gradient computation), and the trajectory-guided mask is obtained by projecting the student's predicted waypoints onto the visual feature grid via a differentiable spatial attention operation. We will insert a complete algorithmic description, explicit equations for mask generation, and a short proof of non-circularity (due to the stop-gradient on the teacher) into the revised §3.2, along with pseudocode for Eqs. (3)–(5). revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes EvoDriveVLA as an additive collaborative distillation framework that applies self-anchored visual constraints and future-informed trajectory optimization from external teacher models. No equations, uniqueness theorems, or self-citations appear in the provided text that would reduce the claimed SOTA results on nuScenes and NAVSIM to a fitted parameter or input defined by the method itself. The derivation chain consists of standard teacher-student regularization steps whose outputs are evaluated empirically rather than forced by construction from the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Knowledge distillation from specialized teachers improves student generalization on perception and planning tasks
invented entities (2)
-
self-anchor teacher
no independent evidence
-
future-aware oracle teacher
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
self-anchored visual distillation leverages self-anchor teacher to deliver visual anchoring constraints, regularizing student representations via trajectory-guided key-region awareness
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
future-informed trajectory distillation employs a future-aware oracle teacher with coarse-to-fine trajectory refinement and Monte Carlo dropout sampling
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Cao, J., Zhang, Q., Jia, P., Zhao, X., Lan, B., Zhang, X., Li, Z., Wei, X., Chen, S., Li, L., et al. Fastdrivevla: Effi- cient end-to-end driving via plug-and-play reconstruction- based token pruning.arXiv preprint arXiv:2507.23318, 2025a. Cao, J., Zhang, Y ., Huang, T., Lu, M., Zhang, Q., An, R., Ma, N., and Zhang, S. Move-kd: Knowledge distillation for ...
-
[3]
Chi, H., Gao, H.-a., Liu, Z., Liu, J., Liu, C., Li, J., Yang, K., Yu, Y ., Wang, Z., Li, W., et al. Impromptu vla: Open weights and open data for driving vision-language-action models.arXiv preprint arXiv:2505.23757,
-
[4]
Fu, H., Zhang, D., Zhao, Z., Cui, J., Liang, D., Zhang, C., Zhang, D., Xie, H., Wang, B., and Bai, X. Orion: A holis- tic end-to-end autonomous driving framework by vision- language instructed action generation.arXiv preprint arXiv:2503.19755,
-
[5]
Gao, H., Chen, S., Jiang, B., Liao, B., Shi, Y ., Guo, X., Pu, Y ., Yin, H., Li, X., Zhang, X., et al. Rad: Training an end-to-end driving policy via large-scale 3dgs-based reinforcement learning.arXiv preprint arXiv:2502.13144,
-
[6]
Guo, Z. and Zhang, Z. Vdrive: Leveraging reinforced vla and diffusion policy for end-to-end autonomous driving. arXiv preprint arXiv:2510.15446,
-
[7]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., and Dean, J. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
S3gaussian: Self-supervised street gaussians for autonomous driving
Huang, N., Wei, X., Zheng, W., An, P., Lu, M., Zhan, W., Tomizuka, M., Keutzer, K., and Zhang, S. S3gaussian: Self-supervised street gaussians for autonomous driving. arXiv preprint arXiv:2405.20323,
-
[9]
Kachaev, N., Kolosov, M., Zelezetsky, D., Kovalev, A. K., and Panov, A. I. Don’t blind your vla: Aligning visual representations for ood generalization.arXiv preprint arXiv:2510.25616,
- [10]
-
[11]
Li, K., Li, Z., Lan, S., Xie, Y ., Zhang, Z., Liu, J., Wu, Z., Yu, Z., and Alvarez, J. M. Hydra-mdp++: Advancing end-to-end driving via expert-guided hydra-distillation. arXiv preprint arXiv:2503.12820, 2025a. Li, X., Li, P., Zheng, Y ., Sun, W., Wang, Y ., and Chen, Y . Semi-supervised vision-centric 3d occupancy world model for autonomous driving.arXiv ...
-
[12]
Liu, W., Liu, P., and Ma, J. Dsdrive: Distilling large lan- guage model for lightweight end-to-end autonomous driv- ing with unified reasoning and planning.arXiv preprint arXiv:2505.05360,
-
[13]
GPT-Driver: Learning to Drive with GPT
Mao, J., Qian, Y ., Ye, J., Zhao, H., and Wang, Y . Gpt- driver: Learning to drive with gpt.arXiv preprint arXiv:2310.01415,
work page internal anchor Pith review arXiv
-
[14]
Shi, M., Liu, F., Wang, S., Liao, S., Radhakrishnan, S., Zhao, Y ., Huang, D.-A., Yin, H., Sapra, K., Yacoob, Y ., et al. Ea- gle: Exploring the design space for multimodal llms with mixture of encoders.arXiv preprint arXiv:2408.15998,
-
[15]
10 EvoDriveVLA: Evolving Autonomous Driving VLA Models via Collaborative Perception-Planning Distillation Tang, Z., Lv, Z., Zhang, S., Zhou, Y ., Duan, X., Wu, F., and Kuang, K. Aug-kd: Anchor-based mixup generation for out-of-domain knowledge distillation.arXiv preprint arXiv:2403.07030,
-
[16]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Tian, X., Gu, J., Li, B., Liu, Y ., Wang, Y ., Zhao, Z., Zhan, K., Jia, P., Lang, X., and Zhao, H. Drivevlm: The conver- gence of autonomous driving and large vision-language models.arXiv preprint arXiv:2402.12289,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Wei, X., Ye, Z., Gu, Y ., Zhu, Z., Guo, Y ., Shen, Y ., Zhao, S., Lu, M., Sun, H., Wang, B., et al. Parkgaussian: Surround- view 3d gaussian splatting for autonomous parking.arXiv preprint arXiv:2601.01386,
-
[18]
FutureSightDrive: Thinking Visually with Spatio-Temporal CoT for Autonomous Driving
Zeng, S., Chang, X., Xie, M., Liu, X., Bai, Y ., Pan, Z., Xu, M., Wei, X., and Guo, N. Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving. arXiv preprint arXiv:2505.17685,
work page internal anchor Pith review arXiv
-
[19]
Zhang, J., Xia, W., Zhou, Z., Gong, Y ., and Mei, J. Lap: Fast latent diffusion planner with fine-grained fea- ture distillation for autonomous driving.arXiv preprint arXiv:2512.00470, 2025a. Zhang, Q., Cheng, A., Lu, M., Zhang, R., Zhuo, Z., Cao, J., Guo, S., She, Q., and Zhang, S. Beyond text-visual atten- tion: Exploiting visual cues for effective toke...
- [20]
-
[21]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y ., Su, W., Shao, J., et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Zou, J., Chen, S., Liao, B., Zheng, Z., Song, Y ., Zhang, L., Zhang, Q., Liu, W., and Wang, X. Diffusiondrivev2: Rein- forcement learning-constrained truncated diffusion mod- eling in end-to-end autonomous driving.arXiv preprint arXiv:2512.07745,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.