Grounding Synthetic Data Generation With Vision and Language Models
Pith reviewed 2026-05-15 13:43 UTC · model grok-4.3
The pith
Mixing real remote sensing images with synthetic ones grounded by vision-language models improves segmentation and captioning performance over real data alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
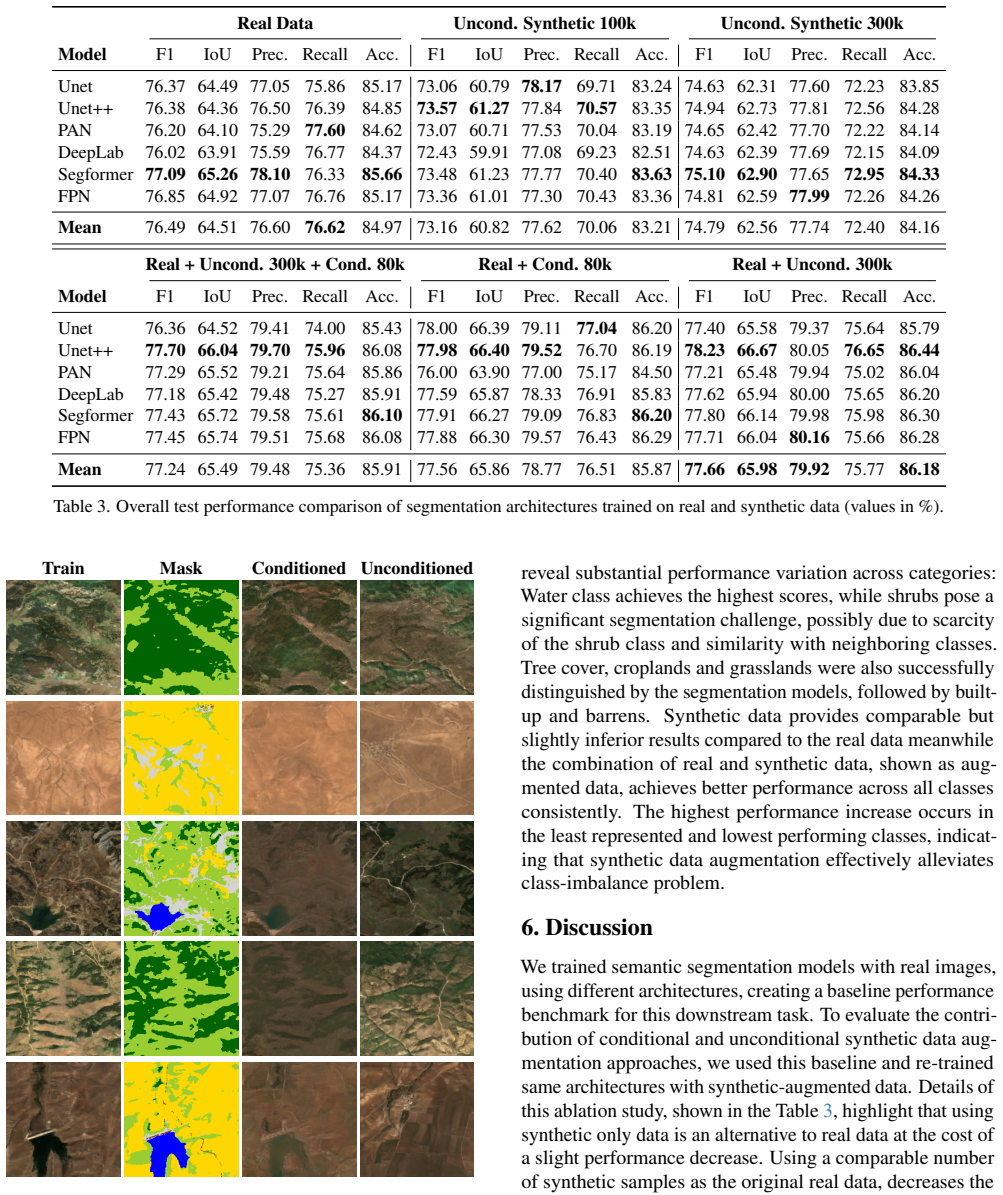
A vision-language grounded pipeline for generating synthetic remote sensing images yields an augmented dataset in which training on the combination of real and synthetic samples consistently exceeds the performance of training on real samples alone for semantic segmentation and image captioning.
What carries the argument
The vision-language grounding process that generates segmentation maps and captions for each synthetic image and verifies their cross-modal consistency with the visual content.
If this is right
- Models trained exclusively on the synthetic portion reach competitive performance levels on the target tasks.
- Augmented training sets (real plus synthetic) outperform real-data baselines in both semantic segmentation and image captioning.
- The framework supplies an automated evaluation method that checks semantic composition and cross-modal consistency.
- The resulting ARAS400k collection serves as a scalable public benchmark for remote sensing segmentation and captioning.
Where Pith is reading between the lines
- The same grounding approach could be applied to other data-scarce domains to reduce reliance on new real-world collection.
- Consistency scores between generated maps and captions might serve as a general filter for synthetic data quality in any vision task.
- The dataset size ratio of three synthetic images per real image may indicate a practical upper bound for useful augmentation before diminishing returns set in.
Load-bearing premise
Vision-language models produce segmentation maps and captions whose consistency with the image reliably signals which synthetic samples will improve downstream task performance, without any manual filtering.
What would settle it
Train segmentation and captioning models on the ARAS400k augmented split versus the real-only split and compare mIoU and caption metrics; if the augmented set does not exceed the real baseline, the central claim is false.
Figures




read the original abstract
Deep learning models benefit from increasing data diversity and volume, motivating synthetic data augmentation to improve existing datasets. However, existing evaluation metrics for synthetic data typically calculate latent feature similarity, which is difficult to interpret and does not always correlate with the contribution to downstream tasks. We propose a vision-language grounded framework for interpretable synthetic data augmentation and evaluation in remote sensing. Our approach combines generative models, semantic segmentation and image captioning with vision and language models. Based on this framework, we introduce ARAS400k: A large-scale Remote sensing dataset Augmented with Synthetic data for segmentation and captioning, containing 100k real images and 300k synthetic images, each paired with segmentation maps and descriptions. ARAS400k enables the automated evaluation of synthetic data by analyzing semantic composition, minimizing caption redundancy, and verifying cross-modal consistency between visual structures and language descriptions. Experimental results indicate that while models trained exclusively on synthetic data reach competitive performance levels, those trained with augmented data (a combination of real and synthetic images) consistently outperform real-data baselines. Consequently, this work establishes a scalable benchmark for remote sensing tasks, specifically in semantic segmentation and image captioning. The dataset is available at zenodo.org/records/18890661 and the code base at github.com/caglarmert/ARAS400k.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a vision-language grounded framework for interpretable synthetic data generation and evaluation in remote sensing. It combines generative models with VLM-based semantic segmentation and captioning to create the ARAS400k dataset (100k real + 300k synthetic images, each paired with segmentation maps and descriptions). Synthetic data quality is assessed via semantic composition analysis, caption redundancy minimization, and cross-modal consistency checks. Experiments claim that models trained solely on synthetic data achieve competitive performance, while augmented real+synthetic training consistently outperforms real-data baselines for semantic segmentation and image captioning.
Significance. If the reported gains prove robust and independent of selective curation, the work would provide a valuable public benchmark (ARAS400k) and interpretable evaluation metrics that better correlate with downstream task performance than latent feature similarity. The public release of the dataset on Zenodo and code on GitHub supports reproducibility and could help address data scarcity in remote sensing.
major comments (1)
- [Abstract and ARAS400k description] Abstract and ARAS400k dataset description: the manuscript does not state whether the 300k synthetic images comprise the full set of generated samples or only the subset retained after applying VLM-based cross-modal consistency, semantic composition, and caption redundancy filters. This distinction is load-bearing for the central claim that augmented training outperforms real baselines, because post-hoc selection could account for the gains rather than the grounding framework itself.
minor comments (2)
- The abstract and results summary omit error bars, statistical significance tests, exact train/validation/test splits, and the full evaluation protocol (e.g., which segmentation and captioning metrics are used and how baselines are trained).
- No details are provided on the specific generative models, VLM architectures, or hyperparameter choices used for data generation and consistency scoring.
Simulated Author's Rebuttal
We appreciate the referee's careful reading and constructive feedback on our manuscript. We respond to the major comment point by point below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and ARAS400k description] Abstract and ARAS400k dataset description: the manuscript does not state whether the 300k synthetic images comprise the full set of generated samples or only the subset retained after applying VLM-based cross-modal consistency, semantic composition, and caption redundancy filters. This distinction is load-bearing for the central claim that augmented training outperforms real baselines, because post-hoc selection could account for the gains rather than the grounding framework itself.
Authors: We agree that the manuscript should explicitly clarify whether the 300k synthetic images are the complete set of generated samples or the filtered subset. This information is important for assessing the framework's contribution. In the revised manuscript, we will update the abstract and the ARAS400k dataset description to specify that the 300k images are those retained after applying the VLM-based cross-modal consistency checks, semantic composition analysis, and caption redundancy minimization. These steps are core to the vision-language grounded framework we propose, providing interpretable quality control rather than opaque post-hoc curation. The experiments in the paper use this final augmented dataset, and we believe this clarification will address the concern that selection alone drives the performance gains. If the initial number of generated samples before filtering is available from our experiments, we will include retention statistics as well. revision: yes
Circularity Check
No significant circularity; empirical results on constructed dataset
full rationale
The paper constructs ARAS400k by applying off-the-shelf VLMs to generate and annotate 300k synthetic images, then reports direct empirical comparisons of segmentation and captioning models trained on real-only, synthetic-only, and augmented splits. No equations, fitted parameters, or self-citations are used to derive performance numbers; the central claims rest on standard train/test splits and off-the-shelf model evaluations whose outcomes are independent of the generation process itself. The listed evaluation criteria (semantic composition, caption redundancy, cross-modal consistency) serve only to describe the dataset, not to force the reported accuracy gains by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision and language models can accurately generate and evaluate semantic content in remote sensing images.
Reference graph
Works this paper leans on
-
[1]
Ahmad Al-Qerem, Ali Mohd Ali, Hani Attar, Shadi Nash- wan, Lianyong Qi, Mohammad Kazem Moghimi, and Ahmed Solyman. Synthetic generation of multidimensional data to improve classification model validity.ACM Journal of Data and Information Quality, 15(3):1–20, 2023. 2
work page 2023
-
[2]
Ajay Bandi, Pydi Venkata Satya Ramesh Adapa, and Yudu Eswar Vinay Pratap Kumar Kuchi. The power of generative ai: A review of requirements, models, input–output formats, evaluation metrics, and challenges.Future Internet, 15(8): 260, 2023. 1
work page 2023
-
[3]
Farhat Lamia Barsha and William Eberle. An in-depth re- view and analysis of mode collapse in generative adversarial networks.Machine Learning, 114(6):141, 2025. 2
work page 2025
-
[4]
Evaluation metrics for generative models: An empirical study.Mach
Eyal Betzalel, Coby Penso, and Ethan Fetaya. Evaluation metrics for generative models: An empirical study.Mach. Learn. Knowl. Extr., 6(3), 2024. 1
work page 2024
-
[5]
Encoder-decoder with atrous separable convolution for semantic image segmentation
Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In ECCV, 2018. 3
work page 2018
-
[6]
A comprehensive survey for generative data augmentation.Neurocomputing, 600:128167, 2024
Yunhao Chen, Zihui Yan, and Yunjie Zhu. A comprehensive survey for generative data augmentation.Neurocomputing, 600:128167, 2024. 1
work page 2024
-
[7]
Qimin Cheng, Haiyan Huang, Yuan Xu, Yuzhuo Zhou, Huany- ing Li, and Zhongyuan Wang. Nwpu-captions dataset and mlca-net for remote sensing image captioning.IEEE Trans- actions on Geoscience and Remote Sensing, 60:1–19, 2022. 3
work page 2022
-
[8]
Generative AI for synthetic data generation: Methods, challenges and the future
Xu Guo and Yiqiang Chen. Generative ai for syn- thetic data generation: Methods, challenges and the future. arXiv:2403.04190, 2024. 1
-
[9]
Synthclip: Are we ready for a fully synthetic clip training?, 2024
Hasan Abed Al Kader Hammoud, Hani Itani, Fabio Pizzati, Philip Torr, Adel Bibi, and Bernard Ghanem. Synthclip: Are we ready for a fully synthetic clip training?, 2024. 2
work page 2024
-
[10]
Ruozhen He, Ziyan Yang, Paola Cascante-Bonilla, Alexan- der C. Berg, and Vicente Ordonez. Learning from synthetic data for visual grounding, 2024. 2
work page 2024
-
[11]
CLIPScore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. CLIPScore: A reference-free evaluation metric for image captioning. InConference on Empirical Methods in Natural Language Processing, 2021. 2, 3
work page 2021
-
[12]
Denoising diffu- sion probabilistic models.Advances in neural information processing systems, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models.Advances in neural information processing systems, 2020. 2
work page 2020
-
[13]
Nick Huang, Aaron Gokaslan, V olodymyr Kuleshov, and James Tompkin. The GAN is dead; long live the GAN! a modern GAN baseline.Advances in Neural Information Processing Systems, 37:44177–44215, 2024. 2
work page 2024
-
[14]
Distilling diffusion models into conditional GANs
Minguk Kang, Richard Zhang, Connelly Barnes, Sylvain Paris, Suha Kwak, Jaesik Park, Eli Shechtman, Jun-Yan Zhu, and Taesung Park. Distilling diffusion models into conditional GANs. InECCV, 2024. 2
work page 2024
-
[15]
Alias-free generative adversarial networks
Tero Karras, Miika Aittala, Samuli Laine, Erik H ¨ark¨onen, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Alias-free generative adversarial networks. InInternational Conference on Neural Information Processing Systems, 2021. 2, 3, 4
work page 2021
-
[16]
Pyramid Attention Network for Semantic Segmentation
Hanchao Li, Pengfei Xiong, Jie An, and Lingxue Wang. Pyramid attention network for semantic segmentation. arXiv:1805.10180, 2018. 3
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
Feature pyramid networks for object detection
Tsung-Yi Lin, Piotr Doll ´ar, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2117–2125, 2017. 3
work page 2017
-
[18]
Xinfu Liu, Benze Wu, and Yirui Wu. A remote sensing image classification method based on detail attention sampling and teacher-student network.ACM Journal of Data and Informa- tion Quality, 17(3):1–19, 2025. 2
work page 2025
-
[19]
Xiaoqiang Lu, Binqiang Wang, Xiangtao Zheng, and Xuelong Li. Exploring models and data for remote sensing image caption generation.IEEE Transactions on Geoscience and Remote Sensing, 56(4):2183–2195, 2017. 3 7
work page 2017
-
[20]
Semantic image synthesis with spatially-adaptive nor- malization
Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu. Semantic image synthesis with spatially-adaptive nor- malization. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2332–2341,
-
[21]
Deep semantic understanding of high resolution remote sensing image
Bo Qu, Xuelong Li, Dacheng Tao, and Xiaoqiang Lu. Deep semantic understanding of high resolution remote sensing image. In2016 International Conference on Computer, Infor- mation and Telecommunication Systems (CITS), pages 1–5,
-
[22]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer,
-
[23]
A U-net based discriminator for generative adversarial networks
Edgar Schonfeld, Bernt Schiele, and Anna Khoreva. A U-net based discriminator for generative adversarial networks. In CVPR, 2020. 3, 4
work page 2020
-
[24]
Gemma Team. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [25]
-
[26]
Shaobo Wang, Yantai Yang, Qilong Wang, Kaixin Li, Linfeng Zhang, and Junchi Yan. Not all samples should be utilized equally: Towards understanding and improving dataset distil- lation.arXiv preprint arXiv:2408.12483, 2024. 2
-
[27]
Segformer: Simple and efficient design for semantic segmentation with transformers
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transformers. Advances in neural information processing systems, 34:12077– 12090, 2021. 3
work page 2021
-
[28]
Generative ai in depth: A survey of recent advances, model variants, and real-world applications
Shamim Yazdani, Akansha Singh, Nripsuta Saxena, Zichong Wang, Avash Palikhe, Deng Pan, Umapada Pal, Jie Yang, and Wenbin Zhang. Generative ai in depth: A survey of recent advances, model variants, and real-world applications. Journal of Big Data, 12(1):230, 2025. 2
work page 2025
-
[29]
Esa worldcover 10 m 2021 v200, 2022
Daniele Zanaga, Ruben Van De Kerchove, Dirk Daems, Wanda De Keersmaecker, Carsten Brockmann, Grit Kirches, Jan Wevers, Oliver Cartus, Maurizio Santoro, Steffen Fritz, et al. Esa worldcover 10 m 2021 v200, 2022. 2
work page 2021
-
[30]
Unet++: A nested u-net architecture for medical image segmentation
Zongwei Zhou, Md Mahfuzur Rahman Siddiquee, Nima Tajbakhsh, and Jianming Liang. Unet++: A nested u-net architecture for medical image segmentation. InInternational workshop on deep learning in medical image analysis, 2018. 3 8
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.