Recognition: no theorem link
Logics-Parsing-Omni Technical Report
Pith reviewed 2026-05-15 13:33 UTC · model grok-4.3
The pith
The Omni Parsing framework uses three hierarchical levels and evidence anchoring to turn unstructured multimodal signals into traceable structured knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that integrating Holistic Detection, Fine-grained Recognition, and Multi-level Interpreting with an evidence anchoring mechanism enables the transformation of unstructured audio-visual and other signals into standardized, machine-readable knowledge through evidence-based logical induction.
What carries the argument
The evidence anchoring mechanism that enforces strict alignment between high-level semantic descriptions and low-level facts within the progressive three-level parsing structure.
If this is right
- Complex audio-visual signals can be converted into structured knowledge that supports reliable downstream tasks.
- Fine-grained perception and high-level cognition become mutually reinforcing rather than separate processes.
- Standardized benchmarks like OmniParsingBench allow quantitative measurement of parsing reliability.
- Knowledge outputs are locatable, enumerable, and traceable by design.
Where Pith is reading between the lines
- Such a framework could reduce errors in AI systems that interpret real-world events from video or audio.
- It might enable more seamless integration with logical reasoning engines by providing grounded inputs.
- Applications could extend to automated report generation or event monitoring where traceability matters.
Load-bearing premise
The evidence anchoring mechanism can maintain accurate alignment between high-level interpretations and low-level facts across varied data types without introducing errors or information loss.
What would settle it
An experiment showing a mismatch where a high-level logical conclusion attributes an action or attribute to the incorrect object or time stamp in a provided audio-visual input.
Figures
















read the original abstract
Addressing the challenges of fragmented task definitions and the heterogeneity of unstructured data in multimodal parsing, this paper proposes the Omni Parsing framework. This framework establishes a Unified Taxonomy covering documents, images, and audio-visual streams, introducing a progressive parsing paradigm that bridges perception and cognition. Specifically, the framework integrates three hierarchical levels: 1) Holistic Detection, which achieves precise spatial-temporal grounding of objects or events to establish a geometric baseline for perception; 2) Fine-grained Recognition, which performs symbolization (e.g., OCR/ASR) and attribute extraction on localized objects to complete structured entity parsing; and 3) Multi-level Interpreting, which constructs a reasoning chain from local semantics to global logic. A pivotal advantage of this framework is its evidence anchoring mechanism, which enforces a strict alignment between high-level semantic descriptions and low-level facts. This enables ``evidence-based'' logical induction, transforming unstructured signals into standardized knowledge that is locatable, enumerable, and traceable. Building on this foundation, we constructed a standardized dataset and released the Logics-Parsing-Omni model, which successfully converts complex audio-visual signals into machine-readable structured knowledge. Experiments demonstrate that fine-grained perception and high-level cognition are synergistic, effectively enhancing model reliability. Furthermore, to quantitatively evaluate these capabilities, we introduce OmniParsingBench. Code, models and the benchmark are released at https://github.com/alibaba/Logics-Parsing/tree/master/Logics-Parsing-Omni.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
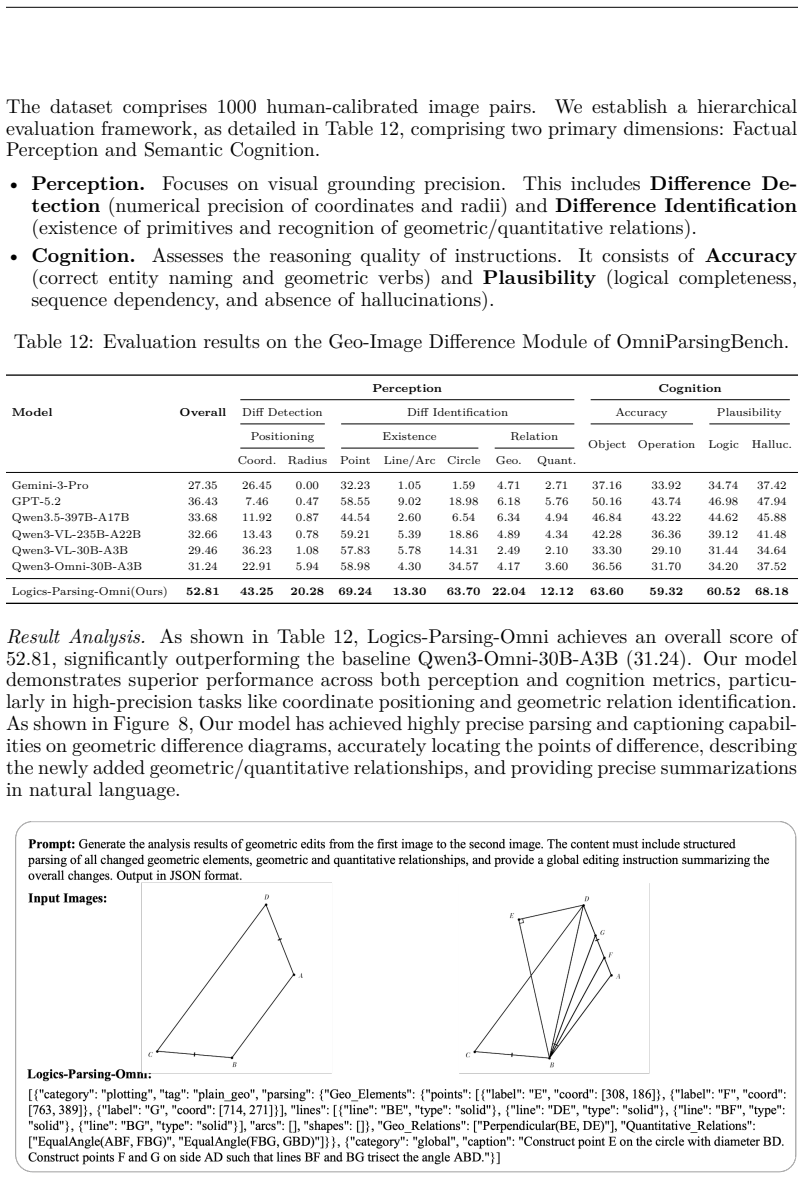
Summary. The paper proposes the Omni Parsing framework to address fragmented task definitions and heterogeneity in multimodal parsing across documents, images, and audio-visual streams. It introduces a Unified Taxonomy and a progressive parsing paradigm with three hierarchical levels: Holistic Detection for spatial-temporal grounding, Fine-grained Recognition for symbolization (e.g., OCR/ASR) and attribute extraction, and Multi-level Interpreting for building reasoning chains from local semantics to global logic. A central element is the evidence anchoring mechanism enforcing strict alignment between high-level semantics and low-level facts to enable evidence-based logical induction, producing locatable, enumerable, and traceable knowledge. The authors release the Logics-Parsing-Omni model, a standardized dataset, and OmniParsingBench, claiming experiments show synergy between perception and cognition.
Significance. If the framework and anchoring mechanism hold under rigorous validation, the work could offer a unified, traceable approach to structured knowledge extraction from unstructured multimodal signals, with the open release of code, models, and benchmark providing a valuable resource for reproducibility and extension in multimodal AI research.
major comments (3)
- [Framework Description (Abstract and § on progressive parsing)] The evidence anchoring mechanism is described as pivotal for enforcing strict, lossless alignment between high-level semantic descriptions (Multi-level Interpreting) and low-level facts (Holistic Detection and Fine-grained Recognition), yet the manuscript supplies no formal definition, algorithm, loss function, anchoring rule, or example of how geometric baselines connect to logical conclusions. This is load-bearing for the central claim of reliable cross-modal transformation without alignment errors.
- [Experiments and Evaluation] The statement that experiments demonstrate synergy between fine-grained perception and high-level cognition, enhancing model reliability, is unsupported by any quantitative metrics, ablation results, error rates, or data exclusion criteria. Without these, the empirical validation of the framework cannot be evaluated.
- [OmniParsingBench] OmniParsingBench is introduced for quantitative evaluation of the capabilities, but no details are provided on its construction, task definitions, metrics, or comparisons to existing benchmarks, leaving the assessment of the model's performance on heterogeneous inputs incomplete.
minor comments (1)
- [Abstract] The abstract refers to constructing 'a standardized dataset' without specifying its scale, modality balance, annotation process, or release details beyond the GitHub link.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our technical report. We address each major comment point by point below and will revise the manuscript to incorporate additional formal details, quantitative results, and benchmark specifications.
read point-by-point responses
-
Referee: [Framework Description (Abstract and § on progressive parsing)] The evidence anchoring mechanism is described as pivotal for enforcing strict, lossless alignment between high-level semantic descriptions (Multi-level Interpreting) and low-level facts (Holistic Detection and Fine-grained Recognition), yet the manuscript supplies no formal definition, algorithm, loss function, anchoring rule, or example of how geometric baselines connect to logical conclusions. This is load-bearing for the central claim of reliable cross-modal transformation without alignment errors.
Authors: We agree that the evidence anchoring mechanism is central and requires formalization. In the revised manuscript we will add a dedicated subsection containing: (1) a mathematical definition of the anchoring operation, (2) the algorithm (with pseudocode), (3) the loss function used to enforce alignment, (4) the explicit anchoring rules that map geometric baselines to logical predicates, and (5) a concrete worked example tracing a detection box through recognition to a logical conclusion. This material will be placed immediately after the description of the three hierarchical levels. revision: yes
-
Referee: [Experiments and Evaluation] The statement that experiments demonstrate synergy between fine-grained perception and high-level cognition, enhancing model reliability, is unsupported by any quantitative metrics, ablation results, error rates, or data exclusion criteria. Without these, the empirical validation of the framework cannot be evaluated.
Authors: The current manuscript asserts synergy but does not present the supporting quantitative evidence. We will expand the Experiments section to include: concrete metrics (accuracy, F1, exact-match), ablation tables contrasting perception-only, cognition-only, and full Omni Parsing pipelines, error-rate breakdowns by modality, and explicit data-exclusion criteria. These additions will directly substantiate the synergy claim. revision: yes
-
Referee: [OmniParsingBench] OmniParsingBench is introduced for quantitative evaluation of the capabilities, but no details are provided on its construction, task definitions, metrics, or comparisons to existing benchmarks, leaving the assessment of the model's performance on heterogeneous inputs incomplete.
Authors: We acknowledge that the manuscript currently provides only a high-level mention of OmniParsingBench. In the revision we will add a full section describing: the data-collection and annotation pipeline, the precise task definitions for each modality, the evaluation metrics (including how locatability, enumerability, and traceability are scored), and direct comparisons against existing benchmarks such as DocVQA, ChartQA, and AudioCaps. This will enable readers to assess performance on heterogeneous inputs. revision: yes
Circularity Check
No circularity: framework proposal is self-contained
full rationale
The paper introduces the Omni Parsing framework as an independent architectural proposal with three explicitly defined hierarchical levels (Holistic Detection, Fine-grained Recognition, Multi-level Interpreting) plus an evidence anchoring mechanism. No equations, fitted parameters, or predictions appear in the provided text; the central claims are not derived from prior results but are instead presented as a new taxonomy and paradigm. Released code, models, and OmniParsingBench provide external falsifiability, satisfying the criterion for a self-contained proposal against benchmarks. No self-citation chains, ansatzes, or renamings of known results are load-bearing.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multimodal unstructured data can be progressively parsed from geometric perception to logical cognition
- ad hoc to paper Evidence anchoring enforces reliable alignment between semantics and facts
invented entities (1)
-
Omni Parsing framework
no independent evidence
Forward citations
Cited by 1 Pith paper
-
How Far Is Document Parsing from Solved? PureDocBench: A Source-TraceableBenchmark across Clean, Degraded, and Real-World Settings
PureDocBench shows document parsing is far from solved, with top models at ~74/100, small specialists competing with large VLMs, and ranking reversals under real degradation.
Reference graph
Works this paper leans on
-
[2]
URL https://arxiv.org/abs/2106.15322. Inclusion AI, Bowen Ma, Cheng Zou, Canxiang Yan, Chunxiang Jin, Chunjie Shen, Chenyu Lian, Dandan Zheng, Fudong Wang, Furong Xu, et al. Ming-flash-omni: A sparse, unified architecture for multimodal perception and generation.arXiv preprint arXiv:2510.24821,
-
[3]
Keyu An, Qian Chen, Chong Deng, Zhihao Du, Changfeng Gao, Zhifu Gao, Yue Gu, Ting He, Hangrui Hu, Kai Hu, et al. Funaudiollm: Voice understanding and genera- tion foundation models for natural interaction between humans and llms.arXiv preprint arXiv:2407.04051,
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
URL https://arxiv.org/abs/2507.16343. Xiangyang Chen, Shuzhao Li, Xiuwen Zhu, Yongfan Chen, Fan Yang, Cheng Fang, Lin Qu, Xiaoxiao Xu, Hu Wei, and Minggang Wu. Logics-parsing technical report.arXiv preprint arXiv:2509.19760,
-
[6]
24 Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, In- derjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next gen- eration agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Cheng Cui, Ting Sun, Suyin Liang, Tingquan Gao, Zelun Zhang, Jiaxuan Liu, Xueqing Wang, Changda Zhou, Hongen Liu, Manhui Lin, Yue Zhang, Yubo Zhang, Handong Zheng, Jing Zhang, Jun Zhang, Yi Liu, Dianhai Yu, and Yanjun Ma. Paddleocr-vl: Boosting multilingual document parsing via a 0.9b ultra-compact vision-language model, 2025a. URLhttps://arxiv.org/abs/25...
-
[8]
Dolphin: Document image parsing via heterogeneous anchor prompting.arXiv preprint arXiv:2505.14059,
Hao Feng, Shu Wei, Xiang Fei, Wei Shi, Yingdong Han, Lei Liao, Jinghui Lu, Binghong Wu, Qi Liu, Chunhui Lin, et al. Dolphin: Document image parsing via heterogeneous anchor prompting.arXiv preprint arXiv:2505.14059,
-
[9]
Jack Hong, Shilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, and Weidi Xie
URLhttps://arxiv.org/abs/2105.07031. Jack Hong, Shilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, and Weidi Xie. Worldsense: Evaluating real-world omnimodal understanding for multimodal llms.arXiv preprint arXiv:2502.04326,
-
[10]
URLhttps://arxiv.org/abs/2508. 03983. Contributors: Heinrich Dinkel et al. (listed alphabetically in Appendix B). Anwen Hu, Haiyang Xu, Jiabo Ye, Ming Yan, Liang Zhang, Bo Zhang, Ji Zhang, Qin Jin, Fei Huang, and Jingren Zhou. mplug-docowl 1.5: Unified structure learning for ocr-free document understanding. InFindings of the Association for Computational ...
work page 2024
-
[11]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
URLhttps://arxiv.org/abs/2506.05218. 25 Zhiqiu Lin, Siyuan Cen, Daniel Jiang, Jay Karhade, Hewei Wang, Chancharik Mitra, Tiffany Ling, Yuhan Huang, Sifan Liu, Mingyu Chen, et al. Towards understanding camera motions in any video.arXiv preprint arXiv:2504.15376,
-
[13]
Pengfei Liu, Jun Tao, and Zhixiang Ren. A quantitative analysis of knowledge-learning preferences in large language models in molecular science, 2025a. URLhttps://arxiv. org/abs/2402.04119. Yuan Liu, Zhongyin Zhao, Le Tian, Haicheng Wang, Xubing Ye, Yangxiu You, Zilin Yu, Chuhan Wu, Zhou Xiao, Yang Yu, et al. Points-reader: Distillation-free adaptation of...
-
[14]
Souvik Mandal, Ashish Talewar, Paras Ahuja, and Prathamesh Juvatkar
Accessed: 2025-12-10. Souvik Mandal, Ashish Talewar, Paras Ahuja, and Prathamesh Juvatkar. Nanonets-ocr-s: A model for transforming documents into structured markdown with intelligent content recognition and semantic tagging,
work page 2025
- [15]
-
[16]
Librispeech: an asr corpus based on public domain audio books
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: an asr corpus based on public domain audio books. InAcoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on, pp. 5206–5210. IEEE,
work page 2015
-
[17]
Shuai Peng, Di Fu, Liangcai Gao, Xiuqin Zhong, Hongguang Fu, and Zhi Tang. Multimath: Bridging visual and mathematical reasoning for large language models.arXiv preprint arXiv:2409.00147,
-
[18]
Jake Poznanski, Aman Rangapur, Jon Borchardt, Jason Dunkelberger, Regan Huff, Daniel Lin, Christopher Wilhelm, Kyle Lo, and Luca Soldaini. olmocr: Unlocking trillions of tokens in pdfs with vision language models.arXiv preprint arXiv:2502.18443,
-
[19]
Robust Speech Recognition via Large-Scale Weak Supervision
URLhttps: //arxiv.org/abs/2212.04356. Stephan Roecker. mermaid-flowchart-transformer-moondream- caption [dataset].https://huggingface.co/datasets/sroecker/ mermaid-flowchart-transformer-moondream-caption,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Accessed: 2025-12-10. Hunyuan Vision Team, Pengyuan Lyu, Xingyu Wan, Gengluo Li, Shangpin Peng, Weinong Wang, Liang Wu, Huawen Shen, Yu Zhou, Canhui Tang, et al. Hunyuanocr technical report.arXiv preprint arXiv:2511.19575, 2025a. Meituan LongCat Team, Bairui Wang, Bin Xiao, Bo Zhang, Bolin Rong, Borun Chen, Chang Wan, Chao Zhang, Chen Huang, Chen Chen, et...
-
[21]
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny
URL https://arxiv.org/abs/2303.00332. Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 5294–5306, 2025b. Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen,...
-
[22]
DeepSeek-OCR: Contexts Optical Compression
Haoran Wei, Yaofeng Sun, and Yukun Li. Deepseek-ocr: Contexts optical compression. arXiv preprint arXiv:2510.18234,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Deepseek-ocr 2: Visual causal flow.arXiv preprint arXiv:2601.20552,
Haoran Wei, Yaofeng Sun, and Yukun Li. Deepseek-ocr 2: Visual causal flow.arXiv preprint arXiv:2601.20552,
-
[24]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, et al. Qwen2. 5-omni technical report.arXiv preprint arXiv:2503.20215, 2025a. Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, Yuanjun Lv, Yongqi Wang, Dake Guo, He Wang, Linhan Ma, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Wenqi Zhang, Hang Zhang, Xin Li, Jiashuo Sun, Yongliang Shen, Weiming Lu, Deli Zhao, Yueting Zhuang, and Lidong Bing. 2.5 years in class: A multimodal textbook for vision- language pretraining.arXiv preprint arXiv:2501.00958,
-
[26]
27 Xinyi Zheng, Douglas Burdick, Lucian Popa, and Nancy Xin Ru Wang
URLhttps://arxiv.org/abs/ 2408.05517. 27 Xinyi Zheng, Douglas Burdick, Lucian Popa, and Nancy Xin Ru Wang. Global table ex- tractor (GTE): A framework for joint table identification and cell structure recognition using visual context.CoRR, abs/2005.00589,
-
[28]
URLhttp://arxiv.org/ abs/1911.10683. Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479,
-
[29]
A Appendix A.1 Detailed Evaluation on the Natural Image Module of OmniParsingBench Perception Analysis.The perception metric computes the instance-level parsing score. An instance (entity, knowledge-aware entity, or text) is considered correctonly if: (1) its pre- dicted bounding box achieves the highest Intersection-over-Union (IoU) with a ground-truth b...
-
[30]
with the granular metrics presented below, we introduce the exact cross-domain aggregation rules as follows: Perception: •Location:Represents geometric spatial positioning, derived from the average of coordi- nate and radius metrics in the Geometry domain. Location = 1 2 (GeoCoord + GeoRadius) •Content - Element:Evaluates the exact existence and recall of...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.