Recognition: no theorem link
How Far Is Document Parsing from Solved? PureDocBench: A Source-TraceableBenchmark across Clean, Degraded, and Real-World Settings
Pith reviewed 2026-05-11 02:23 UTC · model grok-4.3
The pith
A new source-traceable benchmark shows document parsing is far from solved, with top models reaching only about 74 out of 100.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PureDocBench demonstrates that document parsing remains far from solved. The benchmark supplies 1,475 pages rendered from HTML/CSS sources in three parallel tracks (clean, digital degradation, real degradation) with fully verifiable annotations. Among 40 evaluated systems the best overall score is approximately 74 out of 100, a 44.6-point spread separates the strongest from the weakest model, specialist parsers of 4 billion parameters or fewer match or exceed far larger general vision-language models, and no model exceeds 67 percent on formula recognition when averaged across tracks.
What carries the argument
PureDocBench, the programmatically generated benchmark that renders document images directly from HTML/CSS sources to produce source-traceable annotations for clean, digitally degraded, and real-degraded versions of the same pages.
If this is right
- Specialist parsers limited to 4 billion parameters or fewer can rival or surpass general vision-language models that are 5 to 100 times larger.
- Formula recognition remains a shared bottleneck where every tested model stays below 67 percent when the formula metric is averaged over all three degradation tracks.
- General vision-language models lose far fewer points under digital and real degradation than pipeline specialists, producing ranking reversals that render clean-only evaluation misleading for deployment.
- Annotation audits of prior benchmarks reveal more than 12 percent errors, raising questions about rankings derived from those older datasets.
Where Pith is reading between the lines
- Practical deployment decisions should require testing under degraded conditions rather than relying on clean-image scores alone.
- Targeted work on mathematical formula handling would likely improve results across both specialist and general-purpose model families.
- The source-traceable generation method could be scaled to additional document types such as handwritten notes or highly dynamic layouts to test remaining gaps.
Load-bearing premise
The HTML/CSS documents together with the chosen degradation models are representative of the content distribution and error patterns found in real scanned or photographed documents across the ten domains.
What would settle it
A model that scores above 90 overall on PureDocBench while maintaining the same relative ordering across the clean, digital-degradation, and real-degradation tracks would contradict the claim that document parsing is far from solved.
Figures




















read the original abstract
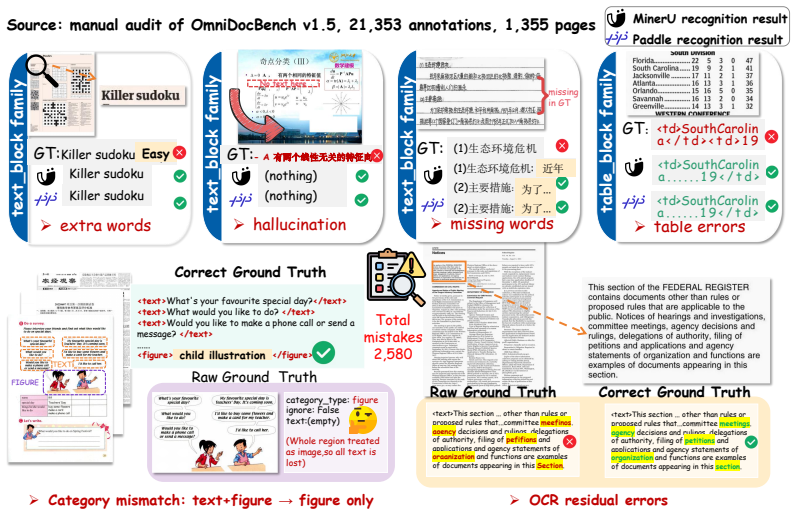
The past year has seen over 20 open-source document parsing models, yet thefield still benchmarks almost exclusively on OmniDocBench, a 1,355-pagemanually annotated dataset whose top scores have saturated above 90%. Athree-stage audit pipeline we run on OmniDocBench screens its 21,353evaluator-scored blocks and confirms 2,580 errors (12.08%); combined with overa year of public availability, both annotation quality and contamination riskcall its rankings into question. To address these issues, we presentPureDocBench, a programmatically generated, source-traceable benchmark thatrenders document images from HTML/CSS and produces verifiable annotations fromthe same source, covering 10 domains, 66 subcategories, and 1,475 pages, eachin three versions: clean, digitally degraded, and real-degraded (4,425 imagestotal). Evaluating 40 models spanning pipeline specialists, end-to-endspecialists, and general-purpose VLMs, we find: (i) document parsing is farfrom solved: the best model scores only ~74 out of 100, with a 44.6-point gapbetween the strongest and weakest models; (ii) specialist parsers with <=4Bparameters rival or surpass general VLMs that are 5-100x larger, yet formularecognition remains a shared bottleneck where no model exceeds 67% whenaveraging the formula metric across all three tracks; (iii) general VLMs loseonly 0.99/8.52 Overall points under digital/real degradation versus 4.90/14.21for pipeline specialists, producing ranking reversals that make clean-onlyevaluation misleading for deployment. All data, code, and artifacts arepublicly released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper audits OmniDocBench and identifies 2,580 errors (12.08%) across 21,353 blocks via a three-stage pipeline, then introduces PureDocBench: a source-traceable benchmark of 1,475 pages across 10 domains rendered from HTML/CSS templates, with annotations derived directly from source code. Each page has clean, digitally degraded, and real-degraded versions (4,425 images total). Evaluation of 40 models (pipeline specialists, end-to-end specialists, and VLMs) yields the claims that document parsing remains far from solved (top score ~74/100 with 44.6-point gaps), small specialists compete with much larger VLMs, formula recognition is a universal bottleneck (<67% averaged across tracks), and degradation causes ranking reversals that make clean-only evaluation misleading.
Significance. If the benchmark's synthetic construction and degradations prove representative, the work would establish a contamination-resistant, verifiable alternative to saturated manual benchmarks, highlight formula recognition and robustness as open problems, and demonstrate that parameter-efficient specialists can match or exceed general VLMs. The public release of data, code, and artifacts, combined with the 40-model evaluation spanning multiple tracks, provides a concrete, reproducible foundation for future progress in document parsing.
major comments (2)
- [PureDocBench construction and real-degraded track description] The real-degraded track starts from the same synthetic HTML/CSS renders and applies chosen degradation models rather than using independently collected real-world scanned or photographed documents. This design measures robustness to simulated conditions but does not establish coverage of empirical real-world distributions (irregular layouts, handwriting, domain-specific artifacts, authentic noise), which is load-bearing for the central claim that parsing is 'far from solved' in real-world settings and for the reported ranking reversals under degradation.
- [OmniDocBench audit section] The three-stage audit pipeline on OmniDocBench that screens 21,353 blocks and confirms 2,580 errors (12.08%) is used to motivate the new benchmark and question prior rankings, yet the manuscript provides insufficient detail on error definitions, the exact procedures of each stage, automation level, and any validation of the error count. This detail is required to assess whether the reported annotation quality and contamination issues are robust enough to justify discarding OmniDocBench-style evaluations.
minor comments (2)
- [Abstract and results section] The abstract states the best model scores '~74 out of 100' and a '44.6-point gap'; the main text should explicitly define the overall scoring metric, its aggregation across domains/tracks/metrics, and which specific models/tracks produce the gap to allow precise interpretation.
- [Degradation procedures] The manuscript should include a brief comparison table or discussion showing how the chosen digital and real degradation procedures relate to documented real-world scanning/photographing artifacts, even if only as a limitation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: The real-degraded track starts from the same synthetic HTML/CSS renders and applies chosen degradation models rather than using independently collected real-world scanned or photographed documents. This design measures robustness to simulated conditions but does not establish coverage of empirical real-world distributions (irregular layouts, handwriting, domain-specific artifacts, authentic noise), which is load-bearing for the central claim that parsing is 'far from solved' in real-world settings and for the reported ranking reversals under degradation.
Authors: We thank the referee for highlighting this important distinction. The real-degraded track applies authentic degradation models—derived from real scanning and imaging processes—to the clean synthetic pages. This controlled setup allows us to isolate the effects of degradation on the exact same document content, which directly reveals the ranking reversals and the limitations of clean-only evaluations. While we acknowledge that this does not capture every possible real-world variation (such as handwritten text or layouts outside HTML/CSS capabilities), it provides a verifiable and reproducible way to assess robustness to common real-world degradations. We will revise the manuscript to more precisely describe the real-degraded track as simulating real-world degradation conditions applied to source-traceable documents, rather than implying exhaustive coverage of all empirical distributions. This does not undermine the core finding that document parsing remains far from solved, as evidenced by the top score of approximately 74/100 even in the clean track. revision: partial
-
Referee: The three-stage audit pipeline on OmniDocBench that screens 21,353 blocks and confirms 2,580 errors (12.08%) is used to motivate the new benchmark and question prior rankings, yet the manuscript provides insufficient detail on error definitions, the exact procedures of each stage, automation level, and any validation of the error count. This detail is required to assess whether the reported annotation quality and contamination issues are robust enough to justify discarding OmniDocBench-style evaluations.
Authors: We agree that more detailed information on the audit pipeline is essential for transparency and to allow proper evaluation of our findings. In the revised version of the manuscript, we will substantially expand the section describing the OmniDocBench audit. This expansion will include: detailed definitions of the error types identified; a step-by-step breakdown of the three-stage pipeline, specifying which parts are automated and which involve human review; the criteria and procedures used for validation; and additional examples of the errors found. These additions will help readers assess the robustness of the 12.08% error rate and the motivation for introducing PureDocBench. revision: yes
Circularity Check
No circularity: benchmark generated independently from HTML/CSS sources with direct source-derived annotations
full rationale
The paper's central claims rest on constructing PureDocBench by rendering document images from HTML/CSS templates across 10 domains and deriving verifiable annotations directly from the source code for each of the 1,475 pages in clean/digital/real-degraded tracks. Model evaluations (best score ~74/100, gaps, degradation robustness) are then performed on this new dataset. This process is self-contained and externally generated rather than reducing to fitted parameters, prior benchmark scores, or self-citations. The separate audit of OmniDocBench errors is not load-bearing for the PureDocBench results or the 'far from solved' conclusion.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption HTML/CSS source code can be rendered into images that faithfully represent document layout and content for the chosen 10 domains
- domain assumption The digital and real degradation procedures produce images whose difficulty distribution matches real-world scanned documents
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2111.08609 , year=
Lei Cui, Yiheng Xu, Tengchao Lv, and Furu Wei. Document AI: Benchmarks, models and applications.arXiv preprint arXiv:2111.08609, 2021
-
[2]
PaddleOCR-VL-1.5: Towards a Multi-Task 0.9B VLM for Robust In-the-Wild Document Parsing
Cheng Cui, Ting Sun, Suyin Liang, Tingquan Gao, Zelun Zhang, Jiaxuan Liu, Xueqing Wang, Changda Zhou, Hongen Liu, Manhui Lin, Yue Zhang, Yubo Zhang, Yi Liu, Dianhai Yu, and Yanjun Ma. PaddleOCR-VL-1.5: Towards a multi-task 0.9B VLM for robust in-the-wild document parsing.arXiv preprint arXiv:2601.21957, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Glm-ocr technical report.arXiv preprint arXiv:2603.10910,
Shuaiqi Duan, Yadong Xue, Weihan Wang, Zhe Su, Huan Liu, Sheng Yang, Guobing Gan, Guo Wang, Zihan Wang, Shengdong Yan, et al. GLM-OCR technical report.arXiv preprint arXiv:2603.10910, 2026
-
[4]
Junbo Niu, Zheng Liu, Zhuangcheng Gu, Bin Wang, Linke Ouyang, Zhiyuan Zhao, Tao Chu, Tianyao He, Fan Wu, Qintong Zhang, et al. MinerU2.5: A decoupled vision-language model for efficient high-resolution document parsing.arXiv preprint arXiv:2509.22186, 2025
-
[5]
MinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale
Bin Wang, Tianyao He, Linke Ouyang, Fan Wu, Zhiyuan Zhao, Tao Chu, Yuan Qu, Zhenjiang Jin, Weijun Zeng, Ziyang Miao, et al. MinerU2.5-Pro: Pushing the limits of data-centric document parsing at scale.arXiv preprint arXiv:2604.04771, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Hao Feng, Wei Shi, Ke Zhang, Xiang Fei, Lei Liao, Dingkang Yang, Yongkun Du, Xuecheng Wu, Jingqun Tang, Yang Liu, Hong Chen, and Can Huang. Dolphin-v2: Universal document parsing via scalable anchor prompting.arXiv preprint arXiv:2602.05384, 2026
-
[7]
Firered-ocr technical report, 2026
Hao Wu, Haoran Lou, Xinyue Li, Zuodong Zhong, Zhaojun Sun, Phellon Chen, Xuanhe Zhou, Kai Zuo, Yibo Chen, Xu Tang, et al. FireRed-OCR technical report.arXiv preprint arXiv:2603.01840, 2026
-
[8]
Hunyuanocr Technical Report.arXiv preprint arXiv:2511.19575, 2025
Hunyuan Vision Team, Pengyuan Lyu, Xingyu Wan, Gengluo Li, Shangpin Peng, Weinong Wang, Liang Wu, Huawen Shen, Yu Zhou, Canhui Tang, Qi Yang, et al. HunyuanOCR technical report.arXiv preprint arXiv:2511.19575, 2025
-
[9]
DeepSeek-OCR: Contexts Optical Compression
Haoran Wei, Yaofeng Sun, and Yukun Li. DeepSeek-OCR: Contexts optical compression.arXiv preprint arXiv:2510.18234, 2025
work page internal anchor Pith review arXiv 2025
-
[10]
Deepseek-ocr 2: Visual causal flow.arXiv preprint arXiv:2601.20552,
Haoran Wei, Yaofeng Sun, and Yukun Li. DeepSeek-OCR 2: Visual causal flow.arXiv preprint arXiv:2601.20552, 2026
-
[11]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-VL technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Gemini 3.1 Pro: A smarter model for your most complex tasks
Gemini Team. Gemini 3.1 Pro: A smarter model for your most complex tasks. https://blog.google/innovation-and-ai/models-and-research/ gemini-models/gemini-3-1-pro/, February 2026. Google Blog post
work page 2026
-
[13]
OmniDocBench: Benchmarking diverse PDF document parsing with comprehensive annotations
Linke Ouyang, Yuan Qu, Hongbin Zhou, Jiawei Zhu, Rui Zhang, Zhiyuan Zhao, Bin Wang, et al. OmniDocBench: Benchmarking diverse PDF document parsing with comprehensive annotations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
work page 2025
-
[14]
arXiv preprint arXiv:2511.18434 , year=
Yongkun Du, Pinxuan Chen, Xuye Ying, and Zhineng Chen. DocPTBench: Benchmarking end-to-end photographed document parsing and translation.arXiv preprint arXiv:2511.18434, 2025
-
[15]
arXiv preprint arXiv:2603.04205 , year=
Changda Zhou, Ziyue Gao, Xueqing Wang, Tingquan Gao, Cheng Cui, Jing Tang, and Yi Liu. Real5-OmniDocBench: A full-scale physical reconstruction benchmark for robust document parsing in the wild.arXiv preprint arXiv:2603.04205, 2026
-
[16]
Zhang Li, Zhibo Lin, Qiang Liu, Ziyang Zhang, Shuo Zhang, Zidun Guo, Jiajun Song, Jiarui Zhang, Xiang Bai, and Yuliang Liu. MDPBench: A benchmark for multilingual document parsing in real-world scenarios.arXiv preprint arXiv:2603.28130, 2026. 10
-
[17]
Ling Fu, Zhebin Kuang, Jiajun Song, Mingxin Huang, Biao Yang, Yuzhe Li, Linghao Zhu, Qidi Luo, Xinyu Wang, Hao Lu, Zhang Li, Guozhi Tang, Bin Shan, Chunhui Lin, Qi Li, et al. OCRBench v2: An improved benchmark for evaluating large multimodal models on visual text localization and reasoning.arXiv preprint arXiv:2501.00321, 2025
-
[18]
olmOCR 2: Unit test rewards for document OCR
Jake Poznanski, Luca Soldaini, and Kyle Lo. olmOCR 2: Unit test rewards for document OCR. arXiv preprint arXiv:2510.19817, 2025
-
[19]
Mingxin Huang, Yongxin Shi, Dezhi Peng, Songxuan Lai, Zecheng Xie, and Lianwen Jin. OCR-Reasoning Benchmark: Unveiling the true capabilities of MLLMs in complex text-rich image reasoning.arXiv preprint arXiv:2505.17163, 2025
-
[20]
Intelligent document processing market size, share & industry analysis
Fortune Business Insights. Intelligent document processing market size, share & industry analysis. Technical Report FBI108590, Fortune Business In- sights, 2026. Available at https://www.fortunebusinessinsights.com/ intelligent-document-processing-market-108590. Accessed: 2026-05-07
work page 2026
-
[21]
Intelligent document processing market size report,
Grand View Research. Intelligent document processing market size report,
-
[22]
Technical Report GVR-4-68040-023-3, Grand View Research, 2025. Available at https://www.grandviewresearch.com/industry-analysis/ intelligent-document-processing-market-report. Accessed: 2026-05-07
work page 2025
-
[23]
Logics-Parsing-Omni Technical Report
Xin An, Jingyi Cai, Xiangyang Chen, Huayao Liu, Peiting Liu, Peng Wang, Bei Yang, Xiuwen Zhu, et al. Logics-parsing-omni technical report.arXiv preprint arXiv:2603.09677, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Bin Wang, Fan Wu, Linke Ouyang, Zhuangcheng Gu, Rui Zhang, Renqiu Xia, Bo Zhang, and Conghui He. Image over text: Transforming formula recognition evaluation with character detection matching.arXiv preprint arXiv:2409.03643, 2024
-
[25]
Image-based table recognition: Data, model, and evaluation
Xu Zhong, Elaheh ShafieiBavani, and Antonio Jimeno Yepes. Image-based table recognition: Data, model, and evaluation. InProceedings of the European Conference on Computer Vision, 2020
work page 2020
-
[26]
Multimodal OCR: Parse anything from documents, 2026
Handong Zheng, Yumeng Li, Kaile Zhang, Liang Xin, Guangwei Zhao, Hao Liu, Jiayu Chen, Jie Lou, Qi Fu, Rui Yang, et al. Multimodal OCR: Parse anything from documents.arXiv preprint arXiv:2603.13032, 2026
-
[27]
Zhang Li, Yuliang Liu, Qiang Liu, Zhiyin Ma, Ziyang Zhang, Shuo Zhang, Biao Yang, Zidun Guo, Jiarui Zhang, Xinyu Wang, and Xiang Bai. MonkeyOCR: Document parsing with a structure-recognition-relation triplet paradigm.arXiv preprint arXiv:2506.05218, 2025
-
[28]
Kun Yin, Yunfei Wu, Bing Liu, Zhongpeng Cai, Xiaotian Li, Huang Chen, Xin Li, Haoyu Cao, Yinsong Liu, Deqiang Jiang, Xing Sun, Yunsheng Wu, Qianyu Li, Antai Guo, Yanzhen Liao, Yanqiu Qu, Haodong Lin, Chengxu He, and Shuangyin Liu. Youtu-parsing: Perception, structuring and recognition via high-parallelism decoding.arXiv preprint arXiv:2601.20430, 2026
-
[29]
Yongkun Du, Zhineng Chen, and Yu-Gang Jiang. OpenOCR: An open-source toolkit for general-OCR research and applications.https://github.com/Topdu/OpenOCR, 2024
work page 2024
-
[30]
Jake Poznanski, Aman Rangapur, Jon Borchardt, Jason Dunkelberger, Regan Huff, Daniel Lin, Christopher Wilhelm, Kyle Lo, and Luca Soldaini. olmOCR: Unlocking trillions of tokens in PDFs with vision language models.arXiv preprint arXiv:2502.18443, 2025
-
[31]
Yufeng Zhong, Lei Chen, Zhixiong Zeng, Xuanle Zhao, Deyang Jiang, Liming Zheng, Jing Huang, Haibo Qiu, Peng Shi, Siqi Yang, and Lin Ma. Reading or reasoning? format decoupled reinforcement learning for document OCR.arXiv preprint arXiv:2601.08834, 2026
-
[32]
Logics-MLLM Team. Logics-Parsing-v2. https://huggingface.co/Logics-MLLM/ Logics-Parsing-v2, 2026. Hugging Face model card; accessed 2026-05-07
work page 2026
-
[33]
Yufeng Zhong, Lei Chen, Xuanle Zhao, Wenkang Han, Liming Zheng, Jing Huang, Deyang Jiang, Yilin Cao, Lin Ma, and Zhixiong Zeng. OCRVerse: Towards holistic OCR in end-to-end vision-language models.arXiv preprint arXiv:2601.21639, 2026. 11
-
[34]
arXiv preprint arXiv:2603.13398 , year=
Daxiang Dong, Mingming Zheng, Dong Xu, Chunhua Luo, Bairong Zhuang, Yuxuan Li, Ruoyun He, Haoran Wang, Wenyu Zhang, Wenbo Wang, et al. Qianfan-OCR: A unified end-to-end model for document intelligence.arXiv preprint arXiv:2603.13398, 2026
-
[35]
Souvik Mandal, Ashish Talewar, Siddhant Thakuria, Paras Ahuja, and Prathamesh Juvatkar. Nanonets-OCR2: A model for transforming documents into structured markdown with in- telligent content recognition and semantic tagging. https://huggingface.co/nanonets/ Nanonets-OCR2-3B, 2025. Hugging Face model card
work page 2025
-
[36]
ChatDOC Team. OCRFlux-3B. https://huggingface.co/ChatDOC/OCRFlux-3B, 2025. Hugging Face model card
work page 2025
-
[37]
Yumeng Li, Guang Yang, Hao Liu, Bowen Wang, and Colin Zhang. dots.ocr: Multilingual document layout parsing in a single vision-language model.arXiv preprint arXiv:2512.02498, 2025
-
[38]
Yongkun Du, Zhineng Chen, Yazhen Xie, Weikang Bai, Hao Feng, Wei Shi, Yuchen Su, Can Huang, and Yu-Gang Jiang. UniRec-0.1B: Unified text and formula recognition with 0.1B parameters.arXiv preprint arXiv:2512.21095, 2025
-
[39]
OpenDoc-0.1B: An ultra-lightweight document parsing system
Yongkun Du, Zhineng Chen, Yazhen Xie, Weikang Bai, Hao Feng, Wei Shi, Yuchen Su, Can Huang, and Yu-Gang Jiang. OpenDoc-0.1B: An ultra-lightweight document parsing system. https://github.com/Topdu/OpenOCR/blob/main/docs/opendoc.md, 2025
work page 2025
-
[40]
Qwen3.5: Towards native multimodal agents
Qwen Team. Qwen3.5: Towards native multimodal agents. https://qwen.ai/blog?id= qwen3.5, February 2026. Model card citation; accessed 2026-05-07
work page 2026
- [41]
-
[42]
arXiv preprint arXiv:2601.09668 , year=
Ailin Huang, Chengyuan Yao, Chunrui Han, Fanqi Wan, Hangyu Guo, Haoran Lv, Hongyu Zhou, Jia Wang, Jian Zhou, Jianjian Sun, et al. STEP3-VL-10B technical report.arXiv preprint arXiv:2601.09668, 2026
-
[43]
Tianyu Yu, Zefan Wang, Chongyi Wang, Fuwei Huang, Wenshuo Ma, Zhihui He, Tianchi Cai, Weize Chen, Yuxiang Huang, Yuanqian Zhao, et al. MiniCPM-V 4.5: Cooking efficient MLLMs via architecture, data, and training recipe.arXiv preprint arXiv:2509.18154, 2025. 12 A OmniDocBench Annotation Audit A.1 Motivation and Methodology OmniDocBench [13] contains 27,376 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.