Recognition: 1 theorem link
· Lean TheoremWikiCLIP: An Efficient Contrastive Baseline for Open-domain Visual Entity Recognition
Pith reviewed 2026-05-15 13:08 UTC · model grok-4.3
The pith
WikiCLIP shows a contrastive model with LLM entity embeddings and patch-level adaptation can outperform generative methods on open-domain visual entity recognition while running nearly 100 times faster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
WikiCLIP revisits the contrastive paradigm for open-domain visual entity recognition by using large language model embeddings as entity representations, enhancing them via a Vision-Guided Knowledge Adaptor that aligns textual semantics with visual patch cues, and employing a Hard Negative Synthesis Mechanism to create visually similar yet semantically distinct negatives for training.
What carries the argument
Vision-Guided Knowledge Adaptor (VGKA), which aligns LLM-derived entity embeddings with image features at the patch level to support fine-grained visual-semantic matching.
Load-bearing premise
That LLM entity embeddings combined with patch-level visual alignment and hard-negative training can capture the distinctions needed for open-domain entities without generative modeling.
What would settle it
Running WikiCLIP on the OVEN unseen split and finding no 16 percent accuracy gain over prior contrastive baselines, or finding inference latency comparable to AutoVER, would falsify the performance and efficiency claims.
Figures








read the original abstract
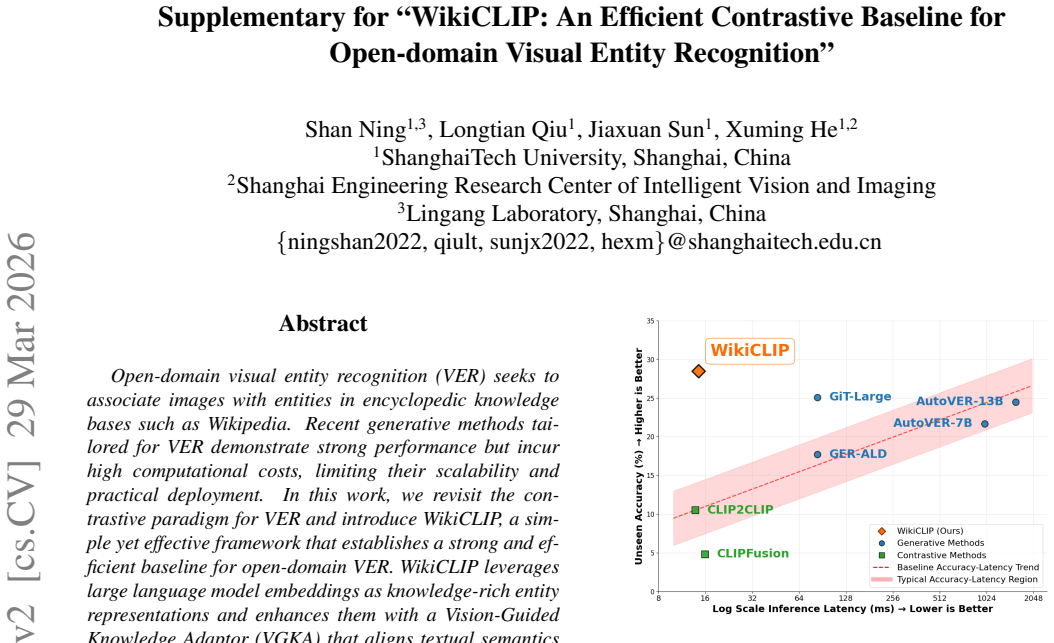
Open-domain visual entity recognition (VER) seeks to associate images with entities in encyclopedic knowledge bases such as Wikipedia. Recent generative methods tailored for VER demonstrate strong performance but incur high computational costs, limiting their scalability and practical deployment. In this work, we revisit the contrastive paradigm for VER and introduce WikiCLIP, a simple yet effective framework that establishes a strong and efficient baseline for open-domain VER. WikiCLIP leverages large language model embeddings as knowledge-rich entity representations and enhances them with a Vision-Guided Knowledge Adaptor (VGKA) that aligns textual semantics with visual cues at the patch level. To further encourage fine-grained discrimination, a Hard Negative Synthesis Mechanism generates visually similar but semantically distinct negatives during training. Experimental results on popular open-domain VER benchmarks, such as OVEN, demonstrate that WikiCLIP significantly outperforms strong baselines. Specifically, WikiCLIP achieves a 16\% improvement on the challenging OVEN unseen set, while reducing inference latency by nearly 100 times compared with the leading generative model, AutoVER. The project page is available at https://artanic30.github.io/project_pages/WikiCLIP/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes WikiCLIP, a contrastive framework for open-domain visual entity recognition that uses LLM-derived entity embeddings, a Vision-Guided Knowledge Adaptor (VGKA) for patch-level visual-textual alignment, and a Hard Negative Synthesis Mechanism to generate challenging negatives. It reports that this approach yields a 16% improvement on the OVEN unseen set while reducing inference latency by nearly 100x relative to the generative baseline AutoVER.
Significance. If the quantitative claims are substantiated, the work supplies a reproducible and computationally lightweight contrastive baseline that challenges the necessity of generative modeling for open-domain VER. The combination of external LLM knowledge with targeted adaptor and negative mining could influence scalable deployment in encyclopedic image-entity linking tasks.
major comments (3)
- [Abstract] Abstract: the central performance claims (16% gain on OVEN unseen, ~100x latency reduction) are stated without error bars, ablation tables, or statistical tests; the contribution of VGKA versus the base contrastive loss therefore cannot be isolated from the given text.
- [Methods (VGKA)] Methods section on VGKA: the adaptor is described as performing patch-level alignment, yet no equations, architecture diagram, or training objective detail the precise fusion of visual patch features with LLM entity embeddings, leaving open whether the reported margin depends on this component or on the hard-negative synthesis alone.
- [Experimental Results] Experimental results: the manuscript references OVEN and other benchmarks but provides neither the exact evaluation protocol (e.g., top-k, entity filtering) nor comparisons against recent contrastive VER baselines beyond AutoVER, weakening the claim that WikiCLIP establishes a new strong baseline.
minor comments (1)
- [Abstract] The project page URL is given but the paper should include a concise reproducibility checklist (hyperparameters, data splits, hardware) in the main text or appendix.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and have revised the paper to incorporate additional details, equations, diagrams, protocols, and comparisons where needed. These changes strengthen the clarity and substantiation of our claims without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (16% gain on OVEN unseen, ~100x latency reduction) are stated without error bars, ablation tables, or statistical tests; the contribution of VGKA versus the base contrastive loss therefore cannot be isolated from the given text.
Authors: We agree that the abstract presents headline numbers without supporting statistical context. In the revised manuscript we have added error bars and significance markers to all primary results in Table 1, expanded the ablation study in Section 4.3 to isolate VGKA from the base contrastive objective and hard-negative synthesis, and updated the abstract to reference these supporting analyses. The length constraint of the abstract precludes embedding full tables, but the main text now supplies the requested isolation. revision: yes
-
Referee: [Methods (VGKA)] Methods section on VGKA: the adaptor is described as performing patch-level alignment, yet no equations, architecture diagram, or training objective detail the precise fusion of visual patch features with LLM entity embeddings, leaving open whether the reported margin depends on this component or on the hard-negative synthesis alone.
Authors: We thank the referee for highlighting this omission. The revised Methods section now contains the complete mathematical formulation of the VGKA fusion (including patch-wise cross-attention equations between visual features and LLM embeddings), a new architecture diagram, and the full training objective. Additional ablation results demonstrate that VGKA contributes measurable gains independently of the hard-negative mechanism. revision: yes
-
Referee: [Experimental Results] Experimental results: the manuscript references OVEN and other benchmarks but provides neither the exact evaluation protocol (e.g., top-k, entity filtering) nor comparisons against recent contrastive VER baselines beyond AutoVER, weakening the claim that WikiCLIP establishes a new strong baseline.
Authors: We have expanded Section 4 to specify the exact evaluation protocol (top-1 accuracy, entity filtering rules, and OVEN split details) and added a new table comparing WikiCLIP against recent contrastive VER baselines (including CLIP variants and other knowledge-augmented contrastive methods). These additions confirm that the reported improvements hold relative to the broader contrastive literature. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces WikiCLIP as a contrastive framework that combines LLM-derived entity embeddings with a Vision-Guided Knowledge Adaptor and hard-negative synthesis, then reports empirical gains on external benchmarks such as OVEN. No equations, fitted parameters, or self-citations are presented that reduce any claimed prediction or uniqueness result to the same inputs by construction. All load-bearing steps rely on standard contrastive objectives and independent test-set evaluation rather than self-referential definitions or imported uniqueness theorems, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (2)
- VGKA adaptor parameters
- Hard negative synthesis parameters
axioms (2)
- domain assumption Large language model embeddings provide knowledge-rich representations for Wikipedia entities
- domain assumption Patch-level visual cues can be aligned with textual semantics via a lightweight adaptor
invented entities (2)
-
Vision-Guided Knowledge Adaptor (VGKA)
no independent evidence
-
Hard Negative Synthesis Mechanism
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
WikiCLIP employs a dual-encoder architecture... optimized using a contrastive learning objective... InfoNCE loss
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in Neural Information Processing Systems, 35:23716–23736,
-
[2]
Good news, everyone! context driven entity-aware captioning for news images
Ali Furkan Biten, Lluis Gomez, Marcal Rusinol, and Di- mosthenis Karatzas. Good news, everyone! context driven entity-aware captioning for news images. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019. 1
work page 2019
-
[3]
Web-scale visual entity recognition: An llm-driven data approach.ArXiv, abs/2410.23676, 2024
Mathilde Caron, Alireza Fathi, Cordelia Schmid, and Ahmet Iscen. Web-scale visual entity recognition: An llm-driven data approach.ArXiv, abs/2410.23676, 2024. 1, 2, 5, 6, 7
-
[4]
Mathilde Caron, Ahmet Iscen, Alireza Fathi, and Cordelia Schmid. A generative approach for wikipedia-scale visual entity recognition.2024 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 17313– 17322, 2024. 1, 2, 5, 6
work page 2024
-
[5]
Xi Chen, Xiao Wang, Soravit Changpinyo, A. J. Piergio- vanni, Piotr Padlewski, Daniel M. Salz, Sebastian Good- man, Adam Grycner, Basil Mustafa, Lucas Beyer, Alexander Kolesnikov, Joan Puigcerver, Nan Ding, Keran Rong, Hassan Akbari, Gaurav Mishra, Linting Xue, Ashish V . Thapliyal, James Bradbury, Weicheng Kuo, Mojtaba Seyedhosseini, Chao Jia, Burcu Kara...
-
[6]
Yang Chen, Hexiang Hu, Yi Luan, Haitian Sun, Soravit Changpinyo, Alan Ritter, and Ming-Wei Chang. Can pre-trained vision and language models answer visual information-seeking questions?ArXiv, abs/2302.11713,
-
[7]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazar´e, Maria Lomeli, Lucas Hosseini, and Herv´e J´egou. The faiss library
-
[8]
Abhimanyu Dubey, Abhinav Jauhri, and et al. The llama 3 herd of models.ArXiv, abs/2407.21783, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Mm-avs: A full- scale dataset for multi-modal summarization
Xiyan Fu, Jun Wang, and Zhenglu Yang. Mm-avs: A full- scale dataset for multi-modal summarization. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Lan- guage Technologies, 2021. 1
work page 2021
-
[10]
Peng Gao, Renrui Zhang, Chris Liu, Longtian Qiu, Siyuan Huang, Weifeng Lin, Shitian Zhao, Shijie Geng, Ziyi Lin, Peng Jin, Kaipeng Zhang, Wenqi Shao, Chao Xu, Conghui He, Junjun He, Hao Shao, Pan Lu, Hongsheng Li, and Yu Qiao. Sphinx-x: Scaling data and parameters for a family of multi-modal large language models.ArXiv, abs/2402.05935,
-
[11]
Ziyu Guo, Renrui Zhang, Longtian Qiu, Xianzheng Ma, Xu- peng Miao, Xuming He, and Bin Cui. Calip: Zero-shot enhancement of clip with parameter-free attention.arXiv preprint arXiv:2209.14169, 2022. 3
-
[12]
Grant Van Horn, Oisin Mac Aodha, Yang Song, Yin Cui, Chen Sun, Alexander Shepard, Hartwig Adam, Pietro Per- ona, and Serge J. Belongie. The inaturalist species classi- fication and detection dataset.2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8769– 8778, 2017. 1
work page 2018
-
[13]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685, 2021. 7
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
Hexiang Hu, Yi Luan, Yang Chen, Urvashi Khandelwal, Mandar Joshi, Kenton Lee, Kristina Toutanova, and Ming- Wei Chang. Open-domain visual entity recognition: Towards recognizing millions of wikipedia entities.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 12031–12041, 2023. 2, 3, 5, 6, 7, 8
work page 2023
-
[15]
Scaling up visual and vision-language representa- tion learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representa- tion learning with noisy text supervision. InInternational conference on machine learning, pages 4904–4916. PMLR,
-
[16]
Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V . Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision.ArXiv, abs/2102.05918,
-
[17]
Novel dataset for fine-grained image categorization : Stanford dogs
Aditya Khosla, Nityananda Jayadevaprakash, Bangpeng Yao, and Li Fei-Fei. Novel dataset for fine-grained image categorization : Stanford dogs. 2012. 1
work page 2012
-
[18]
Region- aware pretraining for open-vocabulary object detection with vision transformers
Dahun Kim, Anelia Angelova, and Weicheng Kuo. Region- aware pretraining for open-vocabulary object detection with vision transformers. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 11144–11154, 2023. 3
work page 2023
-
[19]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models.arXiv preprint arXiv:2301.12597, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Ziyi Lin, Dongyang Liu, Renrui Zhang, Peng Gao, Long- tian Qiu, Han Xiao, Han Qiu, Wenqi Shao, Keqin Chen, Ji- aming Han, et al. Sphinx: A mixer of weights, visual em- beddings and image scales for multi-modal large language models. InEuropean Conference on Computer Vision, pages 36–55. Springer, 2024. 3
work page 2024
-
[21]
Visual news: Benchmark and challenges in news im- age captioning
Fuxiao Liu, Yinghan Wang, Tianlu Wang, and Vicente Or- donez. Visual news: Benchmark and challenges in news im- age captioning. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021. 1
work page 2021
-
[22]
Improved Baselines with Visual Instruction Tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning.ArXiv, abs/2310.03744, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.arXiv preprint arXiv:2304.08485, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Llava-next: Im- proved reasoning, ocr, and world knowledge, 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Im- proved reasoning, ocr, and world knowledge, 2024. 3
work page 2024
-
[25]
Thomas Mensink, Jasper R. R. Uijlings, Llu ´ıs Castrej´on, Arushi Goel, Felipe Cadar, Howard Zhou, Fei Sha, An- dre F. de Ara´ujo, and Vittorio Ferrari. Encyclopedic vqa: Vi- sual questions about detailed properties of fine-grained cate- gories.2023 IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 3090–3101, 2023. 1, 2, 5
work page 2023
-
[26]
Sha Ning, Longtian Qiu, Yongfei Liu, and Xuming He. Hoiclip: Efficient knowledge transfer for hoi detection with vision-language models.2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 23507–23517, 2023. 3
work page 2023
-
[27]
Shan Ning, Longtian Qiu, and Xuming He. Wiki-r1: Incentivizing multimodal reasoning for knowledge-based vqa via data and sampling curriculum.arXiv preprint arXiv:2603.05256, 2026. 1
-
[28]
Vision - openai api.https://platform
OpenAI. Vision - openai api.https://platform. openai.com/docs/guides/vision, 2023. 1, 6
work page 2023
-
[29]
Gpt-5: Advancing general-purpose language intel- ligence, 2025
OpenAI. Gpt-5: Advancing general-purpose language intel- ligence, 2025. Accessed on November 12, 2025. 6
work page 2025
-
[30]
Longtian Qiu, Shan Ning, and Xuming He. Mining fine- grained image-text alignment for zero-shot captioning via text-only training.ArXiv, abs/2401.02347, 2024. 3
-
[31]
NoisyGRPO: Incentivizing Multimodal CoT Reasoning via Noise Injection and Bayesian Estimation
Longtian Qiu, Shan Ning, Jiaxuan Sun, and Xuming He. Noisygrpo: Incentivizing multimodal cot reasoning via noise injection and bayesian estimation.arXiv preprint arXiv:2510.21122, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Longtian Qiu, Shan Ning, Chuyu Zhang, Jiaxuan Sun, and Xuming He. Da-dpo: Cost-efficient difficulty-aware prefer- ence optimization for reducing mllm hallucinations.arXiv preprint arXiv:2601.00623, 2026. 3
-
[33]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021. 2, 3, 6, 7
work page 2021
-
[34]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023. 3
work page 2023
-
[35]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of math- ematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Quan Sun, Yuxin Fang, Ledell Yu Wu, Xinlong Wang, and Yue Cao. Eva-clip: Improved training techniques for clip at scale.ArXiv, abs/2303.15389, 2023. 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Representation Learning with Contrastive Predictive Coding
A ¨aron van den Oord, Yazhe Li, and Oriol Vinyals. Repre- sentation learning with contrastive predictive coding.ArXiv, abs/1807.03748, 2018. 4
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in neural information processing systems, pages 5998–6008, 2017. 6
work page 2017
- [39]
-
[40]
GIT: A generative image-to-text transformer for vision and language
Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, and Lijuan Wang. Git: A generative image-to-text transformer for vision and language.ArXiv, abs/2205.14100, 2022. 6
-
[41]
Grounding language models for visual entity recognition
Zilin Xiao, Ming Gong, Paola Cascante-Bonilla, Xingyao Zhang, Jie Wu, and Vicente Ordonez. Grounding language models for visual entity recognition. InEuropean Confer- ence on Computer Vision, pages 393–411. Springer, 2024. 1, 2, 5, 6, 7
work page 2024
-
[42]
Hu Xu, Gargi Ghosh, Po-Yao Huang, Dmytro Okhonko, Armen Aghajanyan, Florian Metze, Luke Zettlemoyer, and Christoph Feichtenhofer. Videoclip: Contrastive pre-training for zero-shot video-text understanding.arXiv preprint arXiv:2109.14084, 2021. 3
-
[43]
Echosight: Advancing visual-language models with wiki knowledge.ArXiv, abs/2407.12735, 2024
Yibin Yan and Weidi Xie. Echosight: Advancing visual-language models with wiki knowledge.ArXiv, abs/2407.12735, 2024. 5, 6
-
[44]
Filip: Fine-grained interactive language-image pre-training.ArXiv, abs/2111.07783, 2021
Lewei Yao, Runhu Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. Filip: Fine-grained interactive language-image pre-training.ArXiv, abs/2111.07783, 2021. 3
-
[45]
Florence: A new foundation model for computer vision.arXiv preprint arXiv:2111.11432, 2021
Lu Yuan, Dongdong Chen, Yi-Ling Chen, Noel Codella, Xiyang Dai, Jianfeng Gao, Houdong Hu, Xuedong Huang, Boxin Li, Chunyuan Li, et al. Florence: A new foundation model for computer vision.arXiv preprint arXiv:2111.11432, 2021. 3
-
[46]
Yan Zeng, Xinsong Zhang, and Hang Li. Multi-grained vi- sion language pre-training: Aligning texts with visual con- cepts.arXiv preprint arXiv:2111.08276, 2021. 3
-
[47]
Hongkuan Zhou, Lavdim Halilaj, Sebastian Monka, Stefan Schmid, Yuqicheng Zhu, Jingcheng Wu, Nadeem Nazer, and Steffen Staab. Seeing and knowing in the wild: Open- domain visual entity recognition with large-scale knowl- edge graphs via contrastive learning.arXiv preprint arXiv:2510.13675, 2025. 2 A. Overview of Appendixes In this supplementary material, w...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.