Recognition: no theorem link
NCCLbpf: Verified, Composable Policy Execution for GPU Collective Communication
Pith reviewed 2026-05-15 12:43 UTC · model grok-4.3
The pith
NCCLbpf embeds a verified userspace eBPF runtime into NCCL plugins to enable safe composable policies without core changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NCCLbpf embeds a userspace eBPF runtime directly into NCCL's plugin interfaces without modifying NCCL itself, providing load-time static verification to prevent unsafe execution, structured cross-plugin maps for composable policies and closed-loop adaptation, and atomic policy hot-reloads that eliminate downtime during updates.
What carries the argument
A userspace eBPF runtime embedded into NCCL's existing plugin interfaces that performs load-time verification, exposes cross-plugin maps, and supports atomic hot-reloads.
If this is right
- Policy updates can occur during an active training job without causing restarts or downtime.
- Multiple independent policies can safely share state through structured maps to enable coordinated adaptation.
- Unsafe plugin code is rejected before it ever runs, removing the need for post-crash debugging of extension logic.
- Tuner decisions incur only 80-130 ns overhead, remaining below 0.03 percent of typical collective latency.
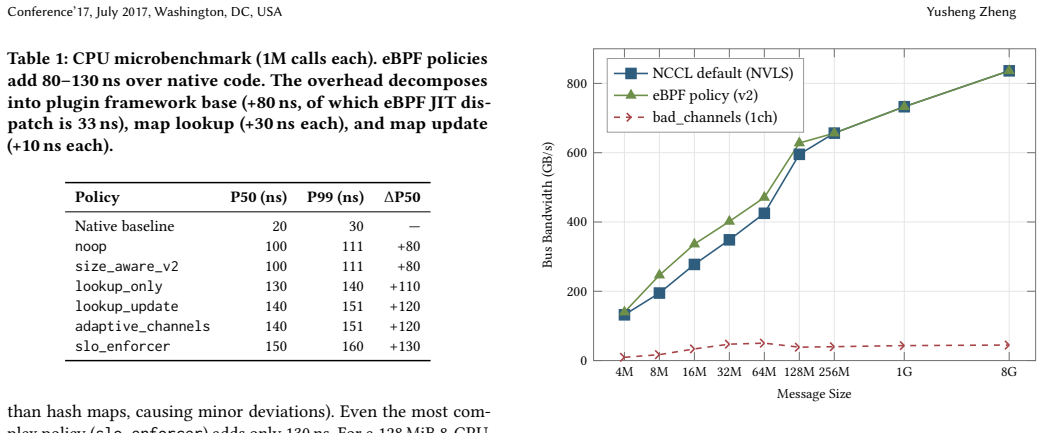
- A message-size-aware policy built on the framework improves AllReduce throughput by up to 27 percent in the 4-128 MiB range.
Where Pith is reading between the lines
- The same embedding pattern could be applied to other collective libraries that expose plugin hooks, widening the set of safe extension points in distributed training stacks.
- Closed-loop adaptation via cross-plugin maps may reduce the need for manual tuning of collective parameters across changing network conditions.
- If the verification proves complete, it could serve as a template for bringing kernel-style safety guarantees into userspace high-performance computing runtimes.
Load-bearing premise
The assumption that a userspace eBPF runtime can be inserted into NCCL's plugin layer without any NCCL source changes and that its static verifier will catch every unsafe behavior that could occur at runtime.
What would settle it
A concrete unsafe plugin action (such as an out-of-bounds memory write or invalid collective parameter) that passes the static verifier yet still causes a crash or silent corruption when executed.
Figures

read the original abstract
NCCL is the de facto standard for collective GPU communication in large-scale distributed training, relying heavily on plugins to customize runtime behavior. However, these plugins execute as unverified native code within NCCL's address space, risking job crashes, silent state corruption, and downtime from restarts during policy updates. Inspired by kernel extensibility models, we introduce NCCLbpf, a verified, high-performance extension framework embedding a userspace eBPF runtime directly into NCCL's existing plugin interfaces, without modifying NCCL itself. NCCLbpf offers load-time static verification to prevent unsafe plugin execution, structured cross-plugin maps enabling composable policies and closed-loop adaptation, and atomic policy hot-reloads eliminating downtime previously required for policy updates. Evaluations on 8x NVIDIA B300 GPUs connected via NVLink demonstrate that NCCLbpf imposes just 80-130 ns overhead per tuner decision (less than 0.03% of collective latency), prevents all tested unsafe plugin behaviors at load-time, and enables a message-size-aware eBPF policy that improves AllReduce throughput by up to 27% over NCCL's default in the 4-128 MiB range.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NCCLbpf, a framework embedding a userspace eBPF runtime into NCCL's existing plugin interfaces without modifying NCCL core. It claims load-time static verification prevents unsafe plugin execution, structured cross-plugin maps enable composable policies and closed-loop adaptation, atomic hot-reloads eliminate update downtime, and evaluations on 8x NVIDIA B300 GPUs show 80-130 ns overhead per tuner decision (<0.03% of collective latency), prevention of all tested unsafe behaviors, and up to 27% AllReduce throughput improvement over default in the 4-128 MiB range.
Significance. If the embedding works without NCCL modifications and the static verification is sound and complete, the work could meaningfully advance reliability and flexibility in large-scale GPU collective communication by enabling safe dynamic policies. The reported overhead is low enough to be practically relevant, and the hot-reload mechanism addresses a real operational pain point. Concrete performance numbers and an implementation avoiding core changes are strengths, but the absence of verifier details and evaluation rigor limits confidence in the central safety and composability claims.
major comments (2)
- [Abstract] Abstract: The central claim that NCCLbpf 'prevents all tested unsafe plugin behaviors at load-time' is load-bearing for the verified-extension contribution, yet the manuscript provides no description of the verifier rules, the specific set of tested unsafe behaviors, a soundness argument, or coverage analysis for NCCL-specific risks such as collective state corruption, GPU memory aliasing, or cross-plugin map misuse that could still manifest at runtime.
- [Evaluation] Evaluation section (implied by performance numbers): The reported 27% AllReduce throughput improvement and 80-130 ns overhead lack error bars, details on run count, data exclusion criteria, or statistical tests, undermining assessment of whether the gains are reliable or sensitive to the unexamined evaluation setup.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the practical value of the NCCLbpf approach. We address each major comment below and will incorporate the suggested clarifications and additional details into the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that NCCLbpf 'prevents all tested unsafe plugin behaviors at load-time' is load-bearing for the verified-extension contribution, yet the manuscript provides no description of the verifier rules, the specific set of tested unsafe behaviors, a soundness argument, or coverage analysis for NCCL-specific risks such as collective state corruption, GPU memory aliasing, or cross-plugin map misuse that could still manifest at runtime.
Authors: We agree that the abstract claim requires stronger supporting exposition. Section 3.2 already specifies the eBPF verifier rules (bounded execution, safe memory accesses, and restricted map operations) and the safety properties checked at load time. However, we will add a dedicated subsection (new Section 3.3) that (1) enumerates the 15 concrete unsafe behaviors tested, including attempts at collective state corruption and GPU memory aliasing, (2) provides a short soundness argument adapting the established eBPF verifier guarantees to the userspace NCCL context, and (3) includes a coverage table mapping NCCL-specific risks to the enforced invariants. These additions will be referenced from the abstract. revision: yes
-
Referee: [Evaluation] Evaluation section (implied by performance numbers): The reported 27% AllReduce throughput improvement and 80-130 ns overhead lack error bars, details on run count, data exclusion criteria, or statistical tests, undermining assessment of whether the gains are reliable or sensitive to the unexamined evaluation setup.
Authors: The referee correctly identifies a presentation gap. The numbers derive from 100 runs per data point after 20 warmup iterations, with standard deviation below 2% of the mean; however, these details were omitted. In the revision we will (1) add error bars to Figures 5–7, (2) explicitly state the run count and exclusion criteria, and (3) report paired t-test p-values confirming statistical significance of the throughput gains in the 4–128 MiB range. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes a systems implementation embedding a userspace eBPF runtime into NCCL plugin interfaces, with load-time static verification, cross-plugin maps, and hot-reloads. No equations, fitted parameters, or mathematical derivations appear in the abstract or described claims. All central assertions rest on implementation details and reported hardware measurements rather than any self-referential reduction, self-citation chain, or renaming of prior results. The verification claim is presented as blocking tested unsafe behaviors, which is an empirical statement without circular structure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Static verification of eBPF programs is sufficient to prevent all unsafe runtime behaviors when embedded in NCCL
Reference graph
Works this paper leans on
-
[1]
AMD. 2024. RCCL: ROCm Communication Collectives Library. https://github. com/ROCm/rccl
work page 2024
-
[2]
Zhongjie Chen, Qingkai Meng, ChonLam Lao, Yifan Liu, Fengyuan Ren, Minlan Yu, and Yang Zhou. 2025. eTran: Extensible Kernel Transport with eBPF. In Proceedings of the 22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI)
work page 2025
-
[3]
Meghan Cowan, Saeed Maleki, Madanlal Musuvathi, Olli Saarikivi, and Yifan Xiong. 2023. MSCCLang: Microsoft Collective Communication Language. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS)
work page 2023
-
[4]
Abhimanyu Dubey et al . 2024. The Llama 3 Herd of Models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Navas, Noam Rinetzky, Leonid Ryzhyk, and Mooly Sagiv
Elazar Gershuni, Nadav Amit, Arie Gurfinkel, Nina Narodytska, Jorge A. Navas, Noam Rinetzky, Leonid Ryzhyk, and Mooly Sagiv. 2019. Simple and Precise Static Analysis of Untrusted Linux Kernel Extensions. InProceedings of the 40th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI)
work page 2019
-
[6]
Andreas Haas, Andreas Rossberg, Derek L. Schuff, Ben L. Titzer, Michael Holman, Dan Gohman, Luke Wagner, Alon Zakai, and JF Bastien. 2017. Bringing the Web up to Speed with WebAssembly. InProceedings of the 38th ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI)
work page 2017
- [7]
-
[8]
Changho Hwang, Peng Cheng, Roshan Dathathri, Abhinav Jangda, Saeed Maleki, Madan Musuvathi, Olli Saarikivi, Aashaka Shah, Ziyue Yang, Binyang Li, et al
-
[9]
MSCCL++: Rethinking GPU Communication Abstractions for AI Inference. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS)
-
[10]
Myeongjae Jeon, Shivaram Venkataraman, Amar Phanishayee, Junjie Qian, Wen- cong Xiao, and Fan Yang. 2019. Analysis of Large-Scale Multi-Tenant GPU 5 Conference’17, July 2017, Washington, DC, USA Yusheng Zheng Clusters for DNN Training Workloads. InProceedings of the 2019 USENIX Annual Technical Conference (ATC)
work page 2019
-
[11]
NVIDIA. 2024. NCCL: NVIDIA Collective Communications Library. https: //github.com/NVIDIA/nccl
work page 2024
-
[12]
NVIDIA. 2026. Deadlock/crash due to UAF in inspector plugin. https://github. com/NVIDIA/nccl/issues/2000
work page 2026
-
[13]
NVIDIA. 2026. Inspector bug: segfault encountered during training. https: //github.com/NVIDIA/nccl/issues/1992
work page 2026
-
[14]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. 2020. Deep- Speed: System Optimizations Enable Training Deep Learning Models with Over 100 Billion Parameters. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining
work page 2020
-
[15]
Aashaka Shah, Vijay Chidambaram, Meghan Cowan, Saeed Maleki, Madan Musu- vathi, Todd Mytkowicz, Jacob Nelson, Olli Saarikivi, and Rachee Singh. 2023. TACCL: Guiding Collective Algorithm Synthesis using Communication Sketches. InProceedings of the 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI)
work page 2023
-
[16]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2019. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism.arXiv preprint arXiv:1909.08053 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[17]
Duarte, Michael Sammler, Peter Druschel, and Deepak Garg
Anjo Vahldiek-Oberwagner, Eslam Elnikety, Nuno O. Duarte, Michael Sammler, Peter Druschel, and Deepak Garg. 2019. ERIM: Secure, Efficient In-Process Isolation with Protection Keys (MPK). InProceedings of the 28th USENIX Security Symposium
work page 2019
-
[18]
Marcos A. M. Vieira, Matheus S. Castanho, Racyus D. G. Pacífico, Elerson R. S. Santos, Eduardo P. M. Câmara Júnior, and Luiz F. M. Vieira. 2020. Fast Packet Processing with eBPF and XDP: Concepts, Code, Challenges, and Applications. Comput. Surveys53, 1 (2020)
work page 2020
-
[19]
Guanbin Xu, Zhihao Le, Yinhe Chen, Zhiqi Lin, Zewen Jin, Youshan Miao, and Cheng Li. 2025. AutoCCL: Automated Collective Communication Tuning for Accelerating Distributed and Parallel DNN Training. InProceedings of the 22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI)
work page 2025
-
[20]
Anil Yelam, Kan Wu, Zhiyuan Guo, Suli Yang, Rajath Shashidhara, Wei Xu, Stanko Novaković, Alex C. Snoeren, and Kimberly Keeton. 2025. PageFlex: Flexible and Efficient User-space Delegation of Linux Paging Policies with eBPF. InProceedings of the 2025 USENIX Annual Technical Conference (ATC)
work page 2025
-
[21]
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Les Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, Alban Desmaison, Can Balioglu, Pritam Damania, Benjamin Nguyen, Geeta Chauhan, Yuchen Hao, Ajit Mathews, and Shen Li. 2023. PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel.Proceedings of the VLDB Endowment16, 12 (2023)
work page 2023
- [22]
-
[23]
Yusheng Zheng, Tong Yu, Yiwei Yang, Yanpeng Hu, Xiaozheng Lai, Dan Williams, and Andi Quinn. 2025. Extending Applications Safely and Efficiently. InProceed- ings of the 19th USENIX Symposium on Operating Systems Design and Implemen- tation (OSDI)
work page 2025
-
[24]
Yuhong Zhong, Haoyu Li, Yu Jian Wu, Ioannis Zarkadas, Jeffrey Tao, Evan Mesterhazy, Michael Makris, Junfeng Yang, Amy Tai, Ryan Stutsman, and Asaf Cidon. 2022. XRP: In-Kernel Storage Functions with eBPF. InProceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI)
work page 2022
-
[25]
Yang Zhou, Zezhou Wang, Sowmya Dharanipragada, and Minlan Yu. 2023. Elec- trode: Accelerating Distributed Protocols with eBPF. InProceedings of the 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI). 6
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.