Recognition: 2 theorem links
· Lean TheoremMESD: A Risk-Sensitive Metric for Explanation Fairness Across Intersectional Subgroups
Pith reviewed 2026-05-15 11:49 UTC · model grok-4.3
The pith
MESD quantifies disparities in explanation stability across intersectional subgroups to detect procedural unfairness missed by outcome metrics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MESD is a procedural fairness metric that quantifies disparities in explanation quality across intersectional subgroups formed by the Cartesian product of protected attributes; it does so through label-aware aggregation aligned with outcome-conditional fairness, empirical-Bayes shrinkage for small subgroups, and CVaR weighting to emphasize worst-case disparities, and it can be jointly optimized with utility and outcome fairness inside an NSGA-II framework.
What carries the argument
MESD (Multi-category Explanation Stability Disparity), a metric that measures differences in explanation stability across intersectional subgroups using label-aware aggregation, empirical-Bayes shrinkage, and CVaR weighting.
If this is right
- Models can be trained to reduce procedural disparities in explanations while preserving accuracy and outcome parity.
- Fairness gerrymandering becomes measurable at the level of combined attributes rather than single protected features.
- Optimization frameworks can now trade off three objectives: utility, outcome fairness, and explanation consistency.
- Regulatory audits gain a concrete way to check whether reasoning differs across demographic intersections.
Where Pith is reading between the lines
- MESD-style stability tracking could be applied to other explanation techniques such as feature attributions or counterfactuals.
- The same intersectional logic might extend to sequential decisions or reinforcement learning policies.
- High-stakes domains could adopt MESD thresholds as part of certification processes for automated systems.
Load-bearing premise
Disparities in explanation stability across intersectional subgroups directly indicate violations of procedural fairness principles.
What would settle it
An experiment in which models with large measured MESD values receive expert or legal confirmation that their decision processes remain procedurally consistent and fair, or models with low MESD values are shown to use systematically different reasoning for different subgroups.
Figures

read the original abstract
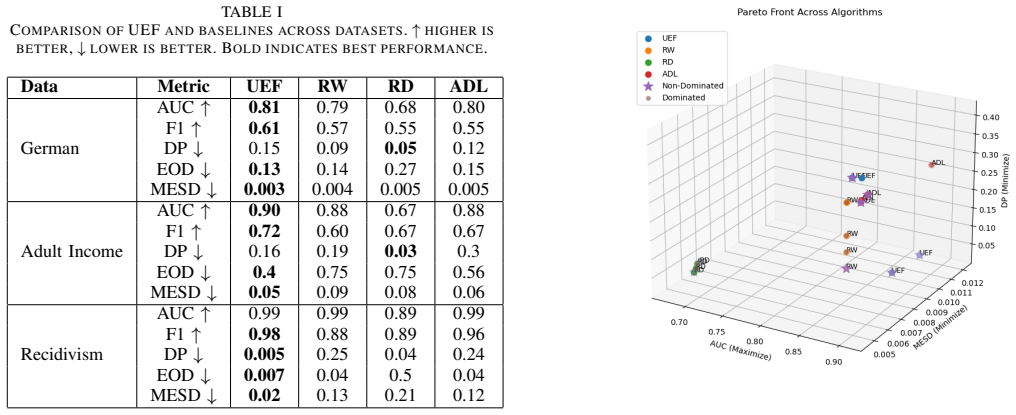
Fairness in machine learning is predominantly evaluated through outcome-oriented metrics, such as Demographic parity, which measure whether predictions are statistically consistent across protected groups. However, these metrics cannot detect whether a model uses systematically different reasoning for different demographic groups, which violates procedural fairness principles. This problem is compounded by intersectionality, where models may appear fair on individual attributes (e.g., race) while exhibiting significant disparities for intersectional subgroups (e.g., race $\times$ gender), a phenomenon known as fairness gerrymandering. In this work, we introduce Multi-category Explanation Stability Disparity (MESD), a procedural fairness metric that quantifies disparities in explanation quality across intersectional subgroups formed by the Cartesian product of multiple protected attributes. MESD integrates three components, which are label-aware aggregation aligned with outcome-conditional fairness, empirical-Bayes shrinkage to stabilize estimates for small intersectional groups, and Conditional Value-at-Risk (CVaR) weighting to emphasize worst-case subgroup disparities. We integrate MESD within a multi-objective optimization framework (UEF) that jointly optimizes utility, outcome fairness, and procedural fairness using NSGA-II. We evaluated MESD and UEF on three benchmark datasets along with four state-of-the-art methods in several experiments, and we demonstrate that MESD reveals procedural disparities invisible to outcome metrics alone. We position our contribution within procedural justice theory and discuss implications for regulatory compliance and intersectional equity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Multi-category Explanation Stability Disparity (MESD) metric to quantify procedural fairness by measuring disparities in post-hoc explanation stability across intersectional subgroups formed by Cartesian products of protected attributes. MESD integrates label-aware aggregation (aligned with outcome-conditional fairness), empirical-Bayes shrinkage for small groups, and CVaR weighting to emphasize worst-case disparities. It is embedded in the UEF multi-objective optimization framework solved via NSGA-II to jointly optimize model utility, outcome fairness, and procedural fairness. Experiments on three benchmark datasets with four SOTA methods are claimed to show that MESD detects procedural disparities invisible to standard outcome metrics such as demographic parity.
Significance. If the core proxy assumption is validated, MESD could extend fairness assessment to intersectional procedural aspects and fairness gerrymandering, with practical value in the UEF optimization for balancing objectives. The risk-sensitive CVaR component and shrinkage for sparse cells are technically interesting strengths. However, without evidence that stability tracks genuine reasoning differences, the significance for procedural justice applications remains provisional.
major comments (3)
- [Experiments] Experiments section: No ablation studies, sensitivity checks, or external validation (e.g., against ground-truth decision paths or human consistency judgments) are described to establish that MESD-detected stability disparities reflect actual differences in model reasoning across subgroups rather than explainer artifacts, data sparsity in intersectional cells, or aggregation choices. This assumption is load-bearing for the abstract claim that MESD reveals disparities invisible to outcome metrics.
- [MESD Definition] MESD definition (likely §3): The metric incorporates free parameters (CVaR alpha level and empirical-Bayes shrinkage strength) whose impact on detected disparities for small intersectional subgroups is not analyzed; without robustness results, the claim that MESD reliably quantifies procedural fairness is weakened.
- [Abstract and §2] Abstract and positioning section: The link between explanation stability and procedural fairness principles is asserted via label-aware aggregation and CVaR but lacks a formal argument or theorem showing why post-hoc stability is a valid proxy when outcome metrics are already satisfied; this gap prevents the central claim from being fully supported.
minor comments (2)
- Define all acronyms at first use (e.g., CVaR, NSGA-II, UEF) and ensure consistent notation for intersectional subgroups throughout.
- [MESD Definition] Add explicit equations for the three MESD components and the overall formula to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We agree that strengthening the validation of MESD as a proxy for procedural fairness, analyzing hyperparameter sensitivity, and clarifying the theoretical link to procedural justice will improve the manuscript. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Experiments] Experiments section: No ablation studies, sensitivity checks, or external validation (e.g., against ground-truth decision paths or human consistency judgments) are described to establish that MESD-detected stability disparities reflect actual differences in model reasoning across subgroups rather than explainer artifacts, data sparsity in intersectional cells, or aggregation choices. This assumption is load-bearing for the abstract claim that MESD reveals disparities invisible to outcome metrics.
Authors: We agree that the current experiments would benefit from additional validation to rule out artifacts. Our existing results across three datasets and four explainers demonstrate that MESD identifies disparities in cases where outcome metrics like demographic parity are satisfied, supporting the claim of visibility beyond outcome fairness. In revision, we will add ablation studies on explainer choice, subgroup size thresholds, and aggregation variants, along with sensitivity checks for data sparsity effects. We will also expand the discussion of limitations regarding potential explainer artifacts. revision: yes
-
Referee: [MESD Definition] MESD definition (likely §3): The metric incorporates free parameters (CVaR alpha level and empirical-Bayes shrinkage strength) whose impact on detected disparities for small intersectional subgroups is not analyzed; without robustness results, the claim that MESD reliably quantifies procedural fairness is weakened.
Authors: We acknowledge that robustness to the CVaR alpha and shrinkage parameters is important for small subgroups. The manuscript presents the metric with default values chosen for stability, but does not include full sensitivity analysis. We will add a new subsection or appendix with plots and tables showing MESD variation across a range of alpha levels (e.g., 0.5 to 0.95) and shrinkage strengths, focusing on intersectional cells with low sample sizes, to demonstrate that detected disparities remain consistent. revision: yes
-
Referee: [Abstract and §2] Abstract and positioning section: The link between explanation stability and procedural fairness principles is asserted via label-aware aggregation and CVaR but lacks a formal argument or theorem showing why post-hoc stability is a valid proxy when outcome metrics are already satisfied; this gap prevents the central claim from being fully supported.
Authors: The positioning in §2 draws on procedural justice literature to argue that consistent reasoning across groups (captured by stable explanations) constitutes a distinct fairness dimension. While no formal theorem is provided, the label-aware aggregation aligns with outcome-conditional fairness notions, and CVaR emphasizes worst-case disparities relevant to intersectional equity. We will revise §2 to include a more structured argument with additional references, clarifying the proxy relationship without claiming a new theorem. This addresses the gap while remaining faithful to the manuscript's scope. revision: partial
Circularity Check
MESD is a directly defined metric; no derivation reduces to its own inputs by construction.
full rationale
The paper defines MESD explicitly as the integration of three specified components (label-aware aggregation, empirical-Bayes shrinkage, CVaR weighting) without any equation that treats a fitted parameter or self-cited result as a 'prediction' of itself. No self-citation chain is load-bearing for a uniqueness theorem, no ansatz is smuggled, and no renaming of known results occurs. Evaluation on external benchmark datasets supplies independent content, rendering the central claim self-contained rather than circular.
Axiom & Free-Parameter Ledger
free parameters (2)
- CVaR alpha level
- empirical-Bayes shrinkage strength
axioms (1)
- domain assumption Disparities in explanation quality across subgroups violate procedural fairness principles
invented entities (1)
-
MESD metric
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MESD integrates label-aware aggregation, empirical-Bayes shrinkage, and CVaR weighting to quantify disparities in explanation stability S(g) across Cartesian-product subgroups G = A1 × … × Am (Eqs. 1-6).
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
UEF jointly optimizes utility, outcome fairness (DP/EOD), and procedural fairness (MESD) via NSGA-II and Chebyshev scalarization.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Fairness of Explanations in Artificial Intelligence (AI): A Unifying Framework, Axioms, and Future Direction toward Responsible AI
A conditional invariance framework defines explanation fairness as explanations being statistically independent of protected attributes given task-relevant features, unifying existing metrics and enabling procedural b...
Reference graph
Works this paper leans on
-
[1]
Involvement of machine learning tools in healthcare decision making,
S. M. D. A. C. Jayatilake and G. U. Ganegoda, “Involvement of machine learning tools in healthcare decision making,”Journal of healthcare engineering, vol. 2021, no. 1, p. 6679512, 2021
work page 2021
-
[2]
S. Barocas and A. D. Selbst, “Big data’s disparate impact,”Calif. L. Rev., vol. 104, p. 671, 2016
work page 2016
-
[3]
Bias in machine learning: A literature review,
K. Mavrogiorgos, A. Kiourtis, A. Mavrogiorgou, A. Menychtas, and D. Kyriazis, “Bias in machine learning: A literature review,”Applied Sciences, vol. 14, no. 19, p. 8860, 2024
work page 2024
-
[4]
Equality of opportunity in supervised learning,
M. Hardt, E. Price, and N. Srebro, “Equality of opportunity in supervised learning,”Advances in Neural Information Processing Systems, vol. 29, 2016
work page 2016
-
[5]
Marrying fairness and explainability in supervised learning,
P. A. Grabowicz, N. Perello, and A. Mishra, “Marrying fairness and explainability in supervised learning,” inProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, 2022, pp. 1905–1916
work page 2022
-
[6]
Fairness and explainability: Bridging the gap towards fair model explanations,
Y . Zhao, Y . Wang, and T. Derr, “Fairness and explainability: Bridging the gap towards fair model explanations,” inProceedings of the AAAI conference on artificial intelligence, vol. 37, no. 9, 2023, pp. 11 363– 11 371
work page 2023
-
[7]
A unified approach to interpreting model predictions,
S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[8]
M. T. Ribeiro, S. Singh, and C. Guestrin, “” why should i trust you?” explaining the predictions of any classifier,” inProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016, pp. 1135–1144
work page 2016
-
[9]
Fairness via explanation quality: Evaluating disparities in the quality of post hoc explanations,
J. Dai, S. Upadhyay, U. Aivodji, S. H. Bach, and H. Lakkaraju, “Fairness via explanation quality: Evaluating disparities in the quality of post hoc explanations,” inProceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society, 2022, pp. 203–214
work page 2022
-
[10]
The road to explainability is paved with bias: Measuring the fairness of explanations,
A. Balagopalan, H. Zhang, K. Hamidieh, T. Hartvigsen, F. Rudzicz, and M. Ghassemi, “The road to explainability is paved with bias: Measuring the fairness of explanations,” inProceedings of the 2022 ACM conference on fairness, accountability, and transparency, 2022, pp. 1194–1206
work page 2022
-
[11]
The fairness-accuracy pareto front,
S. Wei and M. Niethammer, “The fairness-accuracy pareto front,” Statistical Analysis and Data Mining: The ASA Data Science Journal, vol. 15, no. 3, pp. 287–302, 2022
work page 2022
-
[12]
Preventing fairness gerrymandering: Auditing and learning for subgroup fairness,
M. Kearns, S. Neel, A. Roth, and Z. S. Wu, “Preventing fairness gerrymandering: Auditing and learning for subgroup fairness,” inIn- ternational conference on machine learning. PMLR, 2018, pp. 2564– 2572
work page 2018
-
[13]
A review on fairness in machine learning,
D. Pessach and E. Shmueli, “A review on fairness in machine learning,” ACM Computing Surveys (CSUR), vol. 55, no. 3, pp. 1–44, 2022
work page 2022
-
[14]
Demographic parity: Mitigating biases in real-world data,
O. Loukas and H.-R. Chung, “Demographic parity: Mitigating biases in real-world data,”arXiv preprint arXiv:2309.17347, 2023
-
[15]
Data preprocessing techniques for classi- fication without discrimination,
F. Kamiran and T. Calders, “Data preprocessing techniques for classi- fication without discrimination,”Knowledge and Information Systems, vol. 33, no. 1, pp. 1–33, 2012
work page 2012
-
[16]
Mitigating unwanted biases with adversarial learning,
B. H. Zhang, B. Lemoine, and M. Mitchell, “Mitigating unwanted biases with adversarial learning,” inProceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, 2018, pp. 335–340
work page 2018
-
[17]
The intersectionality problem for algorithmic fairness,
J. Himmelreich, A. Hsu, K. Lum, and E. Veomett, “The intersectionality problem for algorithmic fairness,”arXiv preprint arXiv:2411.02569, 2024
-
[18]
Fairness with overlapping groups; a probabilistic perspective,
F. Yang, M. Cisse, and S. Koyejo, “Fairness with overlapping groups; a probabilistic perspective,”Advances in neural information processing systems, vol. 33, pp. 4067–4078, 2020
work page 2020
-
[19]
Investigating and mitigating the performance–fairness tradeoff via protected-category sampling,
G. Popoola and J. Sheppard, “Investigating and mitigating the performance–fairness tradeoff via protected-category sampling,”Elec- tronics, vol. 13, no. 15, p. 3024, 2024
work page 2024
-
[20]
A critical survey on fairness benefits of explainable ai,
L. Deck, J. Schoeffer, M. De-Arteaga, and N. K ¨uhl, “A critical survey on fairness benefits of explainable ai,” inProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, 2024, pp. 1579–1595
work page 2024
-
[21]
A. Shulner-Tal, T. Kuflik, and D. Kliger, “Fairness, explainability and in- between: Understanding the impact of different explanation methods on non-expert users’ perceptions of fairness toward an algorithmic system,” Ethics and Information Technology, vol. 24, no. 1, p. 2, 2022
work page 2022
-
[22]
What will it take to generate fairness-preserving explanations?
J. Dai, S. Upadhyay, S. H. Bach, and H. Lakkaraju, “What will it take to generate fairness-preserving explanations?”arXiv preprint arXiv:2106.13346, 2021
-
[23]
Fooling lime and shap: Adversarial attacks on post hoc explanation methods,
D. Slack, S. Hilgard, E. Jia, S. Singh, and H. Lakkaraju, “Fooling lime and shap: Adversarial attacks on post hoc explanation methods,” in Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, 2020, pp. 180–186
work page 2020
-
[24]
Generating diagnostic and actionable explanations for fair graph neural networks,
Z. Wang, Q. Zeng, W. Lin, M. Jiang, and K. C. Tan, “Generating diagnostic and actionable explanations for fair graph neural networks,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 19, 2024, pp. 21 690–21 698
work page 2024
-
[25]
Explainability for fair machine learning,
T. Begley, T. Schwedes, C. Frye, and I. Feige, “Explainability for fair machine learning,”arXiv preprint arXiv:2010.07389, 2020
-
[26]
Evaluating and aggregating feature-based model explanations,
U. Bhatt, A. Weller, and J. M. Moura, “Evaluating and aggregating feature-based model explanations,” inProceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, 2020, pp. 3016– 3022
work page 2020
-
[27]
A reductions approach to fair classification,
A. Agarwal, A. Beygelzimer, M. Dud ´ık, J. Langford, and H. Wallach, “A reductions approach to fair classification,” inInternational conference on machine learning. PMLR, 2018, pp. 60–69
work page 2018
-
[28]
Fairness- aware class imbalanced learning on multiple subgroups,
D. A. Tarzanagh, B. Hou, B. Tong, Q. Long, and L. Shen, “Fairness- aware class imbalanced learning on multiple subgroups,” inUncertainty in Artificial Intelligence. PMLR, 2023, pp. 2123–2133
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.