Recognition: 2 theorem links
· Lean TheoremBidirectional Cross-Attention Fusion of High-Res RGB and Low-Res HSI for Multimodal Automated Waste Sorting
Pith reviewed 2026-05-15 11:25 UTC · model grok-4.3
The pith
Bidirectional cross-attention fuses high-resolution RGB with low-resolution hyperspectral imaging for pixel-accurate waste segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BCAF aligns high-resolution RGB with low-resolution HSI at their native grids via localized, bidirectional cross-attention, avoiding pre-upsampling or early spectral collapse, and uses independent Swin Transformer backbones for each modality to reach 76.4 percent mIoU at 31 images per second on SpectralWaste and 62.3 percent mIoU for material segmentation on the K3I-Cycling dataset.
What carries the argument
Localized bidirectional cross-attention that fuses features from independent RGB and HSI Swin Transformer backbones directly at native grid positions without resolution changes or spectral collapse.
If this is right
- Achieves 76.4 percent mIoU at 31 images per second and 75.4 percent at 55 images per second on SpectralWaste
- Reaches 62.3 percent mIoU for material segmentation and 66.2 percent for plastic-type segmentation on K3I-Cycling
- Preserves spectral structure through 3D tokenization and spectral self-attention in the HSI backbone
- Supports analysis of trade-offs between RGB input resolution and number of HSI spectral slices
- Applies to any co-registered RGB input paired with lower-resolution high-channel auxiliary sensors
Where Pith is reading between the lines
- The method could reduce contamination rates in automated recycling streams by distinguishing visually similar plastics through spectral cues.
- Public release of the K3I-Cycling dataset subset allows direct comparison and further model development on industrial waste data.
- Optimizing the number of spectral slices versus RGB resolution may yield hardware-specific variants for different conveyor speeds.
- The same fusion pattern could transfer to other high-channel sensors such as multispectral cameras in manufacturing inspection.
Load-bearing premise
The input RGB and HSI image pairs are precisely co-registered so that attention can match corresponding locations without introducing alignment artifacts.
What would settle it
Performance on deliberately misaligned RGB-HSI test pairs that drops below the single-modality RGB baseline would show the cross-attention alignment has failed.
Figures









read the original abstract
Growing waste streams and the transition to a circular economy require efficient automated waste sorting. In industrial settings, materials move on fast conveyor belts, where reliable identification and ejection demand pixel-accurate segmentation. RGB imaging delivers high-resolution spatial detail, which is essential for accurate segmentation, but it confuses materials that look similar in the visible spectrum. Hyperspectral imaging (HSI) provides spectral signatures that separate such materials, yet its lower spatial resolution limits detail. Effective waste sorting therefore needs methods that fuse both modalities to exploit their complementary strengths. We present Bidirectional Cross-Attention Fusion (BCAF), which aligns high-resolution RGB with low-resolution HSI at their native grids via localized, bidirectional cross-attention, avoiding pre-upsampling or early spectral collapse. BCAF uses two independent backbones: a standard Swin Transformer for RGB and an HSI-adapted Swin backbone that preserves spectral structure through 3D tokenization with spectral self-attention. We also analyze trade-offs between RGB input resolution and the number of HSI spectral slices. Although our evaluation targets RGB-HSI fusion, BCAF is modality-agnostic and applies to co-registered RGB with lower-resolution, high-channel auxiliary sensors. On the benchmark SpectralWaste dataset, BCAF achieves state-of-the-art performance of 76.4% mIoU at 31 images/s and 75.4% mIoU at 55 images/s. We further evaluate a novel industrial dataset: K3I-Cycling (first RGB subset already released on Fordatis). On this dataset, BCAF reaches 62.3% mIoU for material segmentation (paper, metal, plastic, etc.) and 66.2% mIoU for plastic-type segmentation (PET, PP, HDPE, LDPE, PS, etc.). Code and model checkpoints are publicly available at https://github.com/jonasvilhofunk/BCAF_2026 .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Bidirectional Cross-Attention Fusion (BCAF), a multimodal architecture that fuses high-resolution RGB imagery with low-resolution hyperspectral imaging (HSI) for pixel-accurate material segmentation in automated waste sorting on conveyor belts. It employs independent Swin Transformer backbones (standard for RGB, 3D-tokenized with spectral self-attention for HSI) and localized bidirectional cross-attention to align modalities at native grids without pre-upsampling or early spectral collapse. The method reports state-of-the-art results on the SpectralWaste benchmark (76.4% mIoU at 31 images/s and 75.4% mIoU at 55 images/s) together with results on a new industrial dataset K3I-Cycling (62.3% mIoU material segmentation, 66.2% mIoU plastic-type segmentation), analyzes RGB-resolution vs. HSI-slice trade-offs, and releases public code and checkpoints.
Significance. If the reported mIoU and throughput numbers hold under the provided code and checkpoints, the work supplies a practical, modality-agnostic fusion technique that exploits complementary spatial and spectral cues for an industrially relevant task. The public release of code, model weights, and the first subset of K3I-Cycling strengthens reproducibility and enables direct follow-up; the explicit speed-accuracy operating points and the absence of forced algebraic circularity in the performance claims further increase the result's utility for downstream recycling systems.
major comments (2)
- [§4.3] §4.3 and Table 2: the claim that bidirectional cross-attention operates strictly at native grids without alignment artifacts rests on the quality of input co-registration; the manuscript should quantify the sensitivity of the reported mIoU to small spatial shifts (e.g., 1-2 pixel offsets) between RGB and HSI pairs, as this directly affects whether the 76.4% figure generalizes beyond the evaluated registration quality.
- [§5.2] §5.2, ablation on spectral-slice count: the trade-off analysis between RGB input resolution and number of HSI slices is presented only for the final mIoU; an additional row showing the corresponding inference throughput (images/s) for each configuration would make the speed-accuracy Pareto front explicit and strengthen the industrial relevance of the 31 vs. 55 images/s operating points.
minor comments (3)
- [§3.1] Abstract and §3.1: the HSI-adapted Swin backbone is described as using '3D tokenization with spectral self-attention,' but the precise patch size along the spectral dimension and the placement of the spectral attention relative to spatial attention are not stated; a short equation or diagram would remove ambiguity.
- [Figure 3] Figure 3 caption: the legend for the two operating points (31 and 55 images/s) should explicitly note whether these throughputs include the full pipeline (backbones + fusion + decoder) or only the fusion stage.
- [§6] §6: the statement that BCAF is 'modality-agnostic' is plausible but would benefit from a one-sentence clarification that the HSI backbone can be replaced by any high-channel auxiliary sensor whose spatial resolution is lower than RGB.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation to accept and for the constructive comments that will improve the manuscript's clarity and practical relevance. We address each major comment below and will incorporate the requested additions in the revised version.
read point-by-point responses
-
Referee: [§4.3] §4.3 and Table 2: the claim that bidirectional cross-attention operates strictly at native grids without alignment artifacts rests on the quality of input co-registration; the manuscript should quantify the sensitivity of the reported mIoU to small spatial shifts (e.g., 1-2 pixel offsets) between RGB and HSI pairs, as this directly affects whether the 76.4% figure generalizes beyond the evaluated registration quality.
Authors: We agree that quantifying robustness to small registration errors is important for industrial deployment, where perfect co-registration is not always feasible. In the revised manuscript we will add a dedicated paragraph and new experiment in §4.3 that measures mIoU degradation on the SpectralWaste test set under controlled 1-pixel and 2-pixel spatial offsets between the RGB and HSI inputs. The results will be discussed in relation to the native-grid claim and referenced from Table 2. revision: yes
-
Referee: [§5.2] §5.2, ablation on spectral-slice count: the trade-off analysis between RGB input resolution and number of HSI slices is presented only for the final mIoU; an additional row showing the corresponding inference throughput (images/s) for each configuration would make the speed-accuracy Pareto front explicit and strengthen the industrial relevance of the 31 vs. 55 images/s operating points.
Authors: We appreciate the suggestion to make the speed-accuracy trade-off explicit. All throughput measurements for the ablation configurations were already recorded during our experiments. In the revised manuscript we will extend the ablation table in §5.2 with an additional row (or column) reporting inference throughput in images/s for every RGB-resolution / HSI-slice combination, thereby clarifying the Pareto front that includes the 31 and 55 images/s operating points. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical neural architecture (BCAF) built from standard Swin Transformer blocks with bidirectional cross-attention for RGB-HSI fusion. All reported results (mIoU values, throughput) are measured on external public datasets (SpectralWaste, K3I-Cycling) rather than being algebraically forced by any internal fit or self-referential definition. No equations, uniqueness theorems, or predictions reduce to the inputs by construction; the central claims rest on benchmark numbers and publicly released code. This is the normal case of a self-contained empirical contribution with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bidirectional cross-attention can align and fuse co-registered high-res RGB and low-res HSI at native resolutions without significant information loss
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Bidirectional Cross-Attention Fusion (BCAF) ... localized, bidirectional cross-attention ... 3D tokenization with spectral self-attention ... Swin Transformer
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
no mention of cost functions, golden ratio, or periodicity
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
C. Chang, Hyperspectral Imaging: Techniques for Spectral Detection and Classification, Springer Science & Business Media, 2003
work page 2003
-
[3]
D. A. Burns, E. W. Ciurczak (Eds.), Handbook of Near-Infrared Analysis, 3rd Edition, CRC Press, 2007
work page 2007
- [4]
-
[5]
H. Zhou, L. Qi, H. Huang, X. Yang, Z. Wan, X. Wen, Canet: Co-attention network for rgb-d semantic segmentation, Pattern Recognition 124 (2022) 108468
work page 2022
-
[6]
Y . Li, X. Zhang, Hybrid long-range feature fusion network for multi-modal waste semantic segmen- tation, Information Fusion (2025) 103608
work page 2025
-
[7]
M. Bihler, L. Roming, Y . Jiang, A. J. Afifi, J. Aderhold, D. ˇCibirait˙e-Lukenskien˙e, S. Lorenz, R. Gloaguen, R. Gruna, M. Heizmann, Multi- sensor data fusion using deep learning for bulky waste image classification, in: Automated Visual Inspection and Machine Vision V , V ol. 12623, SPIE, 2023, pp. 69–82
work page 2023
-
[8]
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, B. Guo, Swin transformer: Hierarchical vision transformer using shifted windows, CoRR abs/2103.14030 (2021)
work page internal anchor Pith review arXiv 2021
-
[9]
O. Ronneberger, P. Fischer, T. Brox, U-net: Con- volutional networks for biomedical image seg- mentation, in: Medical Image Computing and Computer-Assisted Intervention (MICCAI), V ol. 9351, 2015
work page 2015
- [10]
- [11]
-
[12]
ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
A. Paszke, A. Chaurasia, S. Kim, E. Culurciello, Enet: A deep neural network architecture for real-time semantic segmentation, arXiv preprint arXiv:1606.02147 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[13]
H. Zhao, X. Qi, X. Shen, J. Shi, J. Jia, Ic- net for real-time semantic segmentation on high- resolution images, in: Proceedings of the Eu- ropean conference on computer vision (ECCV), 2018, pp. 405–420
work page 2018
-
[14]
E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Álvarez, P. Luo, Segformer: Simple and efficient design for semantic segmentation with transform- ers, CoRR (2021)
work page 2021
-
[15]
A. Senanayake, M. Arashpour, Automated electro- construction waste sorting: Computer vision for part-level segmentation, Waste Management 203 (2025) 114883
work page 2025
- [16]
-
[17]
D. Hong, Z. Han, J. Yao, L. Gao, B. Zhang, A. Plaza, J. Chanussot, Spectralformer: Rethink- ing hyperspectral image classification with trans- formers, CoRR (2021)
work page 2021
-
[18]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weis- senborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkor- eit, N. Houlsby, An image is worth 16x16 words: Transformers for image recognition at scale, Inter- national Conference on Learning Representations (2021)
work page 2021
-
[19]
X. Yang, W. Cao, Y . Lu, Y . Zhou, Hyperspectral image transformer classification networks, IEEE Transactions on Geoscience and Remote Sensing 60 (2022). 19
work page 2022
-
[20]
X. He, Y . Chen, Z. Lin, Spatial-spectral trans- former for hyperspectral image classification, Re- mote Sensing 13 (3) (2021)
work page 2021
-
[21]
L. Sun, G. Zhao, Y . Zheng, Z. Wu, Spec- tral–spatial feature tokenization transformer for hyperspectral image classification, IEEE Trans- actions on Geoscience and Remote Sensing 60 (2022)
work page 2022
-
[22]
J. Long, E. Shelhamer, T. Darrell, Fully convo- lutional networks for semantic segmentation, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3431– 3440
work page 2015
-
[23]
L.-C. Chen, G. Papandreou, I. Kokkinos, K. Mur- phy, A. L. Yuille, Deeplab: Semantic image seg- mentation with deep convolutional nets, atrous convolution, and fully connected crfs, IEEE trans- actions on pattern analysis and machine intelli- gence 40 (4) (2017) 834–848
work page 2017
-
[24]
T. Ji, H. Fang, R. Zhang, J. Yang, Z. Wang, X. Wang, Plastic waste identification based on multimodal feature selection and cross-modal swin transformer, Waste Management 192 (2025)
work page 2025
- [25]
-
[26]
J. Hu, L. Shen, G. Sun, Squeeze-and-excitation networks, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7132–7141
work page 2018
-
[27]
W. Shi, J. Caballero, F. Huszár, J. Totz, A. P. Aitken, R. Bishop, D. Rueckert, Z. Wang, Real- time single image and video super-resolution us- ing an efficient sub-pixel convolutional neural net- work, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 1874–1883
work page 2016
-
[28]
R. Wightman, Pytorch image mod- els,https://github.com/rwightman/ pytorch-image-models(2019).doi: 10.5281/zenodo.4414861
-
[29]
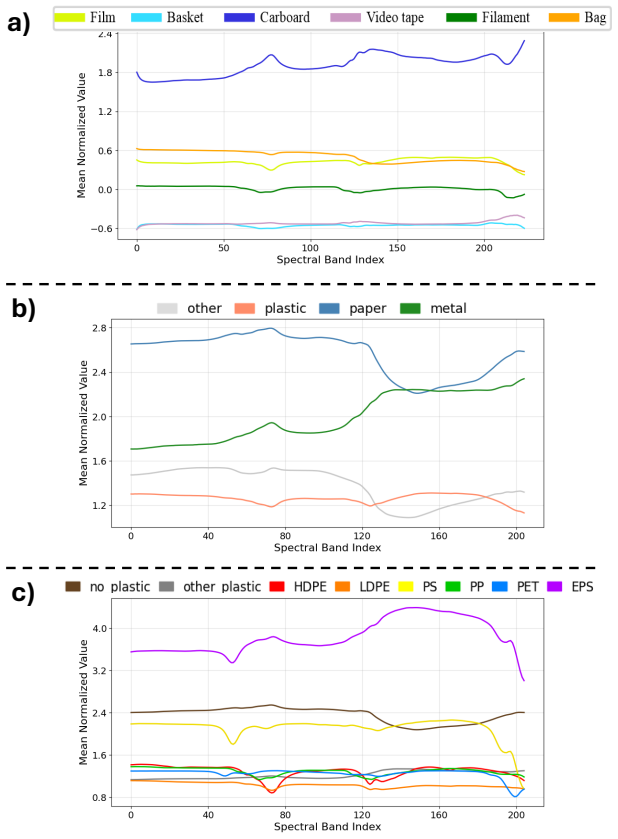
R. W. Schafer, What is a savitzky–golay filter?, IEEE Signal Processing Magazine 28 (4) (2011) 111–117. Appendix Dataset Class Spectra We show the mean normalized spectra for each class in all datasets. First, the HSI data is normalized. Then, for each class, all corresponding pixels are aggregated and the mean spectrum over channels is computed and plott...
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.