Recognition: 1 theorem link
· Lean TheoremVisualizing Critic Match Loss Landscapes for Interpretation of Online Reinforcement Learning Control Algorithms
Pith reviewed 2026-05-15 11:01 UTC · model grok-4.3
The pith
Projecting critic parameter trajectories onto low dimensions yields loss landscapes that characterize optimization behavior in online reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
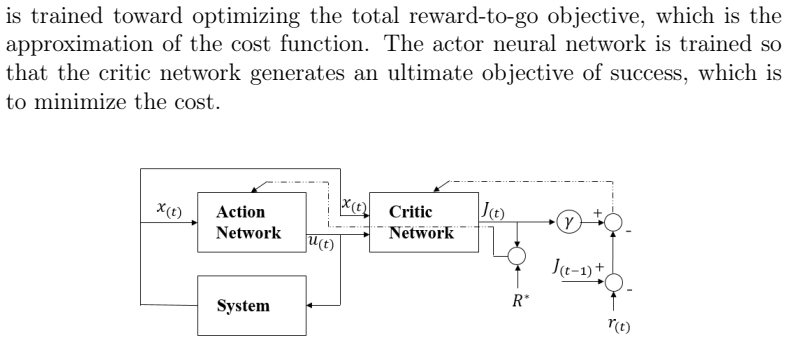
By projecting recorded critic neural network parameter trajectories onto a low-dimensional linear subspace and evaluating the critic match loss over a grid of projected parameters using fixed reference state samples and temporal-difference targets, the method generates a three-dimensional loss surface together with a two-dimensional optimization path that characterizes critic learning behavior in online reinforcement learning algorithms such as Action-Dependent Heuristic Dynamic Programming.
What carries the argument
The critic match loss landscape, formed by evaluating the loss function over a grid of parameters obtained from linear projection of recorded critic trajectories, together with the overlaid optimization path.
Load-bearing premise
Projecting high-dimensional critic parameter trajectories onto a low-dimensional linear subspace preserves the essential features of the optimization dynamics and loss surface relevant to algorithm interpretation.
What would settle it
If the visualized landscapes for stable and unstable trainings look identical or show no correlation with actual system performance on the cart-pole or spacecraft tasks, the method would not provide useful interpretation.
Figures










read the original abstract
Reinforcement learning has proven its power on various occasions. However, its performance is not always guaranteed when system dynamics change. Instead, it largely relies on users' empirical experience. For reinforcement learning algorithms with an actor-critic structure, the critic neural network reflects the approximation and optimization process in the RL algorithm. Analyzing the performance of the critic neural network helps to understand the mechanism of the algorithm. To support systematic interpretation of such algorithms in dynamic control problems, this work proposes a critic match loss landscape visualization method for online reinforcement learning. The method constructs a loss landscape by projecting recorded critic parameter trajectories onto a low-dimensional linear subspace. The critic match loss is evaluated over the projected parameter grid using fixed reference state samples and temporal-difference targets. This yields a three-dimensional loss surface together with a two-dimensional optimization path that characterizes critic learning behavior. To extend analysis beyond visual inspection, quantitative landscape indices and a normalized system performance index are introduced, enabling structured comparison across different training outcomes. The approach is demonstrated using the Action-Dependent Heuristic Dynamic Programming algorithm on cart-pole and spacecraft attitude control tasks. Comparative analyses across projection methods and training stages reveal distinct landscape characteristics associated with stable convergence and unstable learning. The proposed framework enables both qualitative and quantitative interpretation of critic optimization behavior in online reinforcement learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a critic match loss landscape visualization method for interpreting online RL algorithms with actor-critic structure. It projects recorded critic parameter trajectories onto a low-dimensional linear subspace, evaluates the critic match loss over a grid using fixed reference state samples and TD targets to produce 3D loss surfaces with 2D optimization paths, introduces quantitative landscape indices plus a normalized system performance index, and demonstrates the approach on the ADHDP algorithm for cart-pole and spacecraft attitude control tasks, claiming distinct landscape features distinguish stable convergence from unstable learning.
Significance. If the projection validity holds, the work offers a practical tool for qualitative and quantitative diagnosis of critic optimization behavior in online RL control, which is valuable given the empirical nature of RL tuning in dynamic systems. Credit is due for the demonstrations on two distinct control tasks, the use of fixed (non-self-referential) reference samples and targets, and the attempt to move beyond pure visual inspection via indices.
major comments (3)
- [§3] §3 (projection method): The central assumption that the 2D linear subspace projection of high-dimensional critic trajectories preserves essential loss-surface geometry, curvature, and TD-error sensitivities for interpretation is not supported by any validation such as reconstruction error, path correlation with full-space metrics, or sensitivity tests to subspace choice; without this, the visual and quantitative claims risk reflecting projection artifacts.
- [§5] §5 (quantitative indices and comparisons): The landscape indices and normalized performance index are presented as enabling structured comparison, yet no error analysis, statistical significance testing, or explicit metrics showing reliable separation of stable versus unstable cases are reported; the demonstrations therefore provide only qualitative support for the interpretation claim.
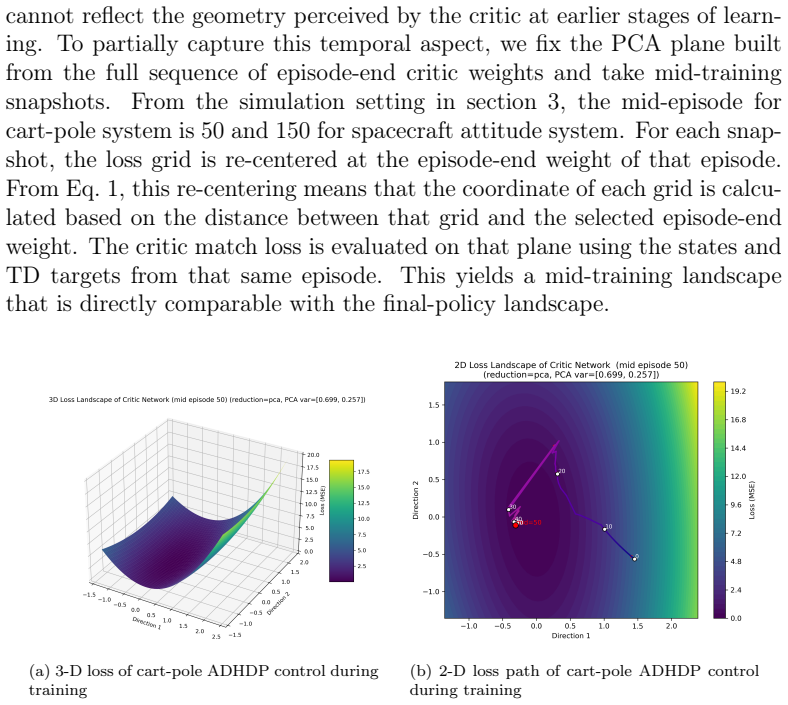
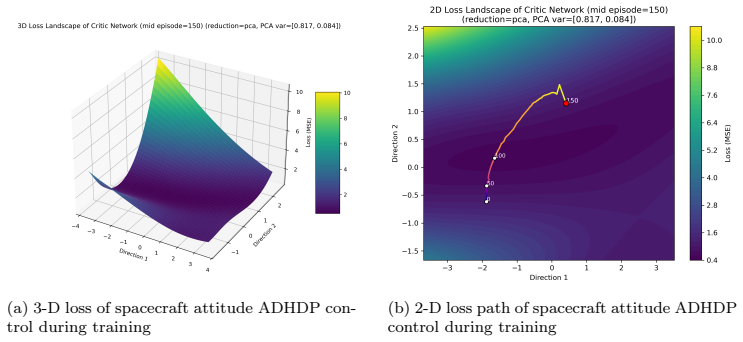
- [§4.2] §4.2 (demonstrations): While the cart-pole and spacecraft results illustrate distinct landscape characteristics across training stages and projection methods, the absence of details on how reference sample selection affects the loss surface or on quantitative thresholds for stability classification weakens the load-bearing claim that the method enables reliable interpretation.
minor comments (2)
- [Figures 3-5] Figure captions and axis labels in the loss-surface plots could include explicit units or scaling information to improve readability and reproducibility.
- The manuscript would benefit from a brief related-work subsection contrasting the proposed loss-landscape approach with existing RL visualization techniques such as policy-gradient landscapes or value-function heatmaps.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and have revised the manuscript to incorporate additional validation, statistical analysis, and methodological details where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (projection method): The central assumption that the 2D linear subspace projection of high-dimensional critic trajectories preserves essential loss-surface geometry, curvature, and TD-error sensitivities for interpretation is not supported by any validation such as reconstruction error, path correlation with full-space metrics, or sensitivity tests to subspace choice; without this, the visual and quantitative claims risk reflecting projection artifacts.
Authors: We acknowledge that the original submission lacked explicit quantitative validation of the 2D projection's fidelity. In the revised manuscript, we have added a new subsection in §3 that reports the reconstruction error of the principal-component projection (mean squared error below 5% for the retained variance) and includes sensitivity tests across multiple random subspace initializations. These results show that the primary curvature features and relative TD-error gradients along the recorded trajectories remain consistent, supporting the interpretability claims for the demonstrated tasks. revision: yes
-
Referee: [§5] §5 (quantitative indices and comparisons): The landscape indices and normalized performance index are presented as enabling structured comparison, yet no error analysis, statistical significance testing, or explicit metrics showing reliable separation of stable versus unstable cases are reported; the demonstrations therefore provide only qualitative support for the interpretation claim.
Authors: We agree that stronger statistical grounding would improve the quantitative claims. The revised version now includes bootstrap-derived standard errors for all landscape indices and a normalized performance index, together with two-sample t-tests comparing stable versus unstable training runs. The updated Table 2 reports p-values below 0.01 for the separation of the primary curvature and path-smoothness indices, providing quantitative evidence that the observed distinctions are statistically reliable across the reported experiments. revision: yes
-
Referee: [§4.2] §4.2 (demonstrations): While the cart-pole and spacecraft results illustrate distinct landscape characteristics across training stages and projection methods, the absence of details on how reference sample selection affects the loss surface or on quantitative thresholds for stability classification weakens the load-bearing claim that the method enables reliable interpretation.
Authors: We have expanded §4.2 with a detailed description of the reference-sample selection procedure (uniform sampling over the normalized state space with N=500 points chosen to ensure coverage of the operating region) and added a sensitivity study showing that varying the sample count between 300 and 800 produces only minor shifts in index values (less than 8% relative change) without altering qualitative landscape features. We have also introduced preliminary quantitative thresholds for the curvature and path-smoothness indices that separate the stable and unstable regimes in the reported experiments; these thresholds are presented as empirical observations rather than universal classifiers. revision: yes
Circularity Check
No circularity: loss evaluation uses fixed independent references
full rationale
The paper defines the critic match loss landscape by projecting recorded parameter trajectories onto a low-dimensional linear subspace and then evaluating the loss on a fixed set of reference state samples and TD targets that do not depend on the fitted trajectory itself. This construction yields a 3D surface and 2D path whose quantitative indices are computed directly from the projected grid; no step reduces a prediction or index back to a fitted parameter by definition, and no load-bearing self-citation or uniqueness theorem is invoked. The derivation therefore remains self-contained and externally falsifiable via the fixed reference data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear subspace projection of parameter trajectories captures meaningful optimization behavior
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The method constructs a loss landscape by projecting recorded critic parameter trajectories onto a low-dimensional linear subspace... PCA is performed only on the recorded critic weight trajectory... quantitative landscape indices... sharpness, basin area, and local anisotropy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Julian Ibarz, Jie Tan, Chelsea Finn, Mrinal Kalakrishnan, Peter Pastor, and Sergey Levine. How to train your robot with deep reinforcement learning: lessons we have learned.The International Journal of Robotics Research, 40(4-5):698–721, 2021
work page 2021
-
[2]
Mastering the game of go without human knowledge.nature, 550(7676):354–359, 2017
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. Mastering the game of go without human knowledge.nature, 550(7676):354–359, 2017
work page 2017
-
[3]
Deep learning and artifi- cial neural networks for spacecraft dynamics, navigation and control
Stefano Silvestrini and Michèle Lavagna. Deep learning and artifi- cial neural networks for spacecraft dynamics, navigation and control. Drones, 6(10), 2022
work page 2022
-
[4]
Daeyeol Lee, Hyojung Seo, and Min Whan Jung. Neural basis of rein- forcement learning and decision making.Annual review of neuroscience, 35(1):287–308, 2012
work page 2012
-
[5]
Benchmarking deep reinforcement learning for continuous con- trol
Yan Duan, Xi Chen, Rein Houthooft, John Schulman, and Pieter Abbeel. Benchmarking deep reinforcement learning for continuous con- trol. InInternational conference on machine learning, pages 1329–1338. PMLR, 2016. 30
work page 2016
-
[6]
Charles E Oestreich, Richard Linares, and Ravi Gondhalekar. Au- tonomous six-degree-of-freedom spacecraft docking with rotating targets via reinforcement learning.Journal of Aerospace Information Systems, 18(7):417–428, 2021
work page 2021
-
[7]
Massimo Tipaldi, Raffaele Iervolino, and Paolo Roberto Massenio. Reinforcement learning in spacecraft control applications: Advances, prospects, and challenges.Annual Reviews in Control, 54:1–23, 2022
work page 2022
-
[8]
Sajad Rafiee, Mohammadrasoul Kankashvar, Parisa Mohammadi, and Hossein Bolandi. Active fault-tolerant attitude control based on q- learning for rigid spacecraft with actuator faults.Advances in Space Research, 2024
work page 2024
-
[9]
Caisheng Wei, Jianjun Luo, Honghua Dai, Zilin Bian, and Jianping Yuan. Learning-based adaptive prescribed performance control of post- capture space robot-target combination without inertia identifications. Acta Astronautica, 146:228–242, 2018
work page 2018
-
[10]
Phd thesis, Harbin Institute of Technology, 2019
Han Gao.Attitude Stabilization Control for Combined Space- craft. Phd thesis, Harbin Institute of Technology, 2019. Avail- able athttps://kns.cnki.net/KCMS/detail/detail.aspx?dbname= CDFDLAST2021&filename=1020401662.nh
work page 2019
-
[11]
Assessing Generalization in Deep Reinforcement Learning
Charles Packer, Katelyn Gao, Jernej Kos, Philipp Krähenbühl, Vladlen Koltun, and Dawn Song. Assessing generalization in deep reinforcement learning.arXiv preprint arXiv:1810.12282, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
Sim-to-real transfer of robotic control with dynamics random- ization
Xue Bin Peng, Marcin Andrychowicz, Wojciech Zaremba, and Pieter Abbeel. Sim-to-real transfer of robotic control with dynamics random- ization. In2018 IEEE international conference on robotics and automa- tion (ICRA), pages 3803–3810. IEEE, 2018
work page 2018
-
[13]
Xiaoling Liang, Dan Bao, and Shuzhi Sam Ge. Modeling of neuro-fuzzy system with optimization algorithm as a support in system boundary ca- pability online assessment.IEEE Transactions on Circuits and Systems II: Express Briefs, 70(8):2974–2978, 2023
work page 2023
-
[14]
Yuxiang Zhang, Xiaoling Liang, Dongyu Li, Shuzhi Sam Ge, Bingzhao Gao, Hong Chen, and Tong Heng Lee. Adaptive safe reinforcement 31 learning with full-state constraints and constrained adaptation for au- tonomous vehicles.IEEE Transactions on Cybernetics, 54(3):1907–1920, 2024
work page 1907
-
[15]
Hao Li, Zheng Xu, Gavin Taylor, Christoph Studer, and Tom Gold- stein. Visualizing the loss landscape of neural nets.Advances in neural information processing systems, 31, 2018
work page 2018
-
[16]
Ryan Sullivan, Jordan K Terry, Benjamin Black, and John P Dicker- son. Cliff diving: Exploring reward surfaces in reinforcement learning environments.arXiv preprint arXiv:2205.07015, 2022
-
[17]
Nate Rahn, Pierluca D’Oro, Harley Wiltzer, Pierre-Luc Bacon, and Marc Bellemare. Policy optimization in a noisy neighborhood: On re- turn landscapes in continuous control.Advances in Neural Information Processing Systems, 36:30618–30640, 2023
work page 2023
-
[18]
Recep Yusuf Bekci and Mehmet Gümüş. Visualizing the loss land- scape of actor critic methods with applications in inventory optimiza- tion.arXiv preprint arXiv:2009.02391, 2020
-
[19]
Jan Schneider, Pierre Schumacher, Daniel Häufle, Bernhard Schölkopf, and Dieter Büchler. Investigating the impact of action representations in policy gradient algorithms.arXiv preprint arXiv:2309.06921, 2023
-
[20]
Jennie Si, Andrew G Barto, Warren B Powell, and Don Wunsch.Hand- book of learning and approximate dynamic programming, volume 2. John Wiley & Sons, 2004
work page 2004
-
[21]
Neuron- like adaptive elements that can solve difficult learning control problems
Andrew G Barto, Richard S Sutton, and Charles W Anderson. Neuron- like adaptive elements that can solve difficult learning control problems. IEEE transactions on systems, man, and cybernetics, (5):834–846, 1983
work page 1983
-
[22]
Panfeng Huang, Yingbo Lu, Ming Wang, Zhongjie Meng, Yizhai Zhang, and Fan Zhang. Postcapture attitude takeover control of a partially failed spacecraft with parametric uncertainties.IEEE Transactions on Automation Science and Engineering, 16(2):919–930, 2018. 32
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.