Recognition: 2 theorem links
· Lean TheoremTowards Generalizable Robotic Manipulation in Dynamic Environments
Pith reviewed 2026-05-15 09:46 UTC · model grok-4.3
The pith
PUMA integrates scene-centric historical optical flow with specialized world queries to implicitly forecast object states, delivering a 6.3% success-rate gain on dynamic manipulation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By integrating scene-centric historical optical flow and specialized world queries to implicitly forecast object-centric future states, PUMA couples history-aware perception with short-horizon prediction and achieves state-of-the-art performance, yielding a 6.3% absolute improvement in success rate over baselines on dynamic manipulation tasks.
What carries the argument
PUMA architecture that integrates scene-centric historical optical flow and specialized world queries to enable implicit short-horizon prediction of object-centric future states.
If this is right
- Training on dynamic trajectories produces spatiotemporal representations that transfer to and improve performance on static manipulation tasks.
- Existing VLA models can be ranked systematically by their ability to maintain success across the benchmark's multi-dimensional dynamic evaluation suite.
- Hierarchical task complexities in the dataset expose which components of spatiotemporal reasoning remain weakest in current models.
- Short-horizon implicit forecasting reduces reliance on separate motion-prediction modules during policy execution.
Where Pith is reading between the lines
- The same flow-plus-query pattern could be stacked across multiple time steps to support longer-horizon planning without changing the core architecture.
- Because the method avoids explicit object tracking, it may generalize more readily to cluttered scenes where individual object identities are hard to maintain.
- Combining the learned implicit forecasts with lightweight physics priors at inference time could further raise robustness when prediction errors accumulate.
Load-bearing premise
Scene-centric historical optical flow combined with specialized world queries supplies enough information for reliable short-horizon forecasts of object motion without explicit physics models.
What would settle it
Ablating the optical-flow input from PUMA and measuring whether success rates on the DOMINO dynamic tasks fall back to baseline levels.
Figures

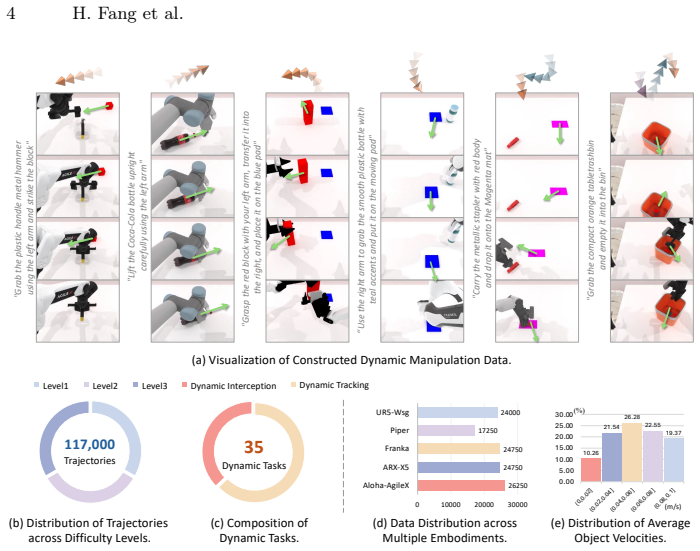
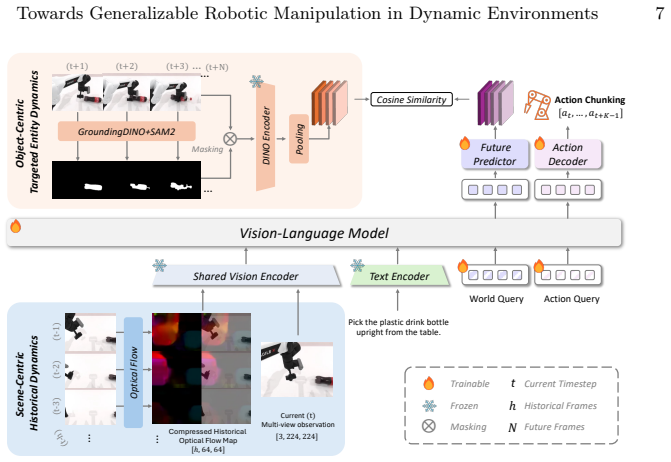



read the original abstract
Vision-Language-Action (VLA) models excel in static manipulation but struggle in dynamic environments with moving targets. This performance gap primarily stems from a scarcity of dynamic manipulation datasets and the reliance of mainstream VLAs on single-frame observations, restricting their spatiotemporal reasoning capabilities. To address this, we introduce DOMINO, a large-scale dataset and benchmark for generalizable dynamic manipulation, featuring 35 tasks with hierarchical complexities, over 110K expert trajectories, and a multi-dimensional evaluation suite. Through comprehensive experiments, we systematically evaluate existing VLAs on dynamic tasks, explore effective training strategies for dynamic awareness, and validate the generalizability of dynamic data. Furthermore, we propose PUMA, a dynamics-aware VLA architecture. By integrating scene-centric historical optical flow and specialized world queries to implicitly forecast object-centric future states, PUMA couples history-aware perception with short-horizon prediction. Results demonstrate that PUMA achieves state-of-the-art performance, yielding a 6.3% absolute improvement in success rate over baselines. Moreover, we show that training on dynamic data fosters robust spatiotemporal representations that transfer to static tasks. All code and data are available at https://github.com/H-EmbodVis/DOMINO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the DOMINO dataset and benchmark for dynamic robotic manipulation (35 tasks, >110K trajectories) and proposes the PUMA VLA architecture, which integrates scene-centric historical optical flow with specialized world queries to implicitly forecast object-centric future states. It reports that PUMA achieves state-of-the-art results with a 6.3% absolute success-rate gain over baselines on dynamic tasks and that dynamic-data training yields transferable spatiotemporal representations for static tasks; code and data are released publicly.
Significance. If the empirical claims are substantiated, the work would be significant for closing the dynamic-environment gap in VLA models by supplying both a new benchmark and an architecture that couples history-aware perception with short-horizon prediction without explicit physics. Public code and data release is a clear strength that supports reproducibility and follow-on research.
major comments (2)
- [Experiments] Experiments section: the central 6.3% absolute improvement is presented without reported baseline implementation details, statistical significance tests, or explicit task-success definitions, preventing verification that the gain is attributable to the proposed components rather than implementation differences.
- [PUMA Architecture] PUMA architecture and results: the claim that scene-centric historical optical flow plus specialized world queries produce reliable short-horizon object-state forecasts rests solely on end-to-end task success; no isolated quantitative evaluation (e.g., future-position or velocity prediction error on held-out trajectories) is provided to confirm the forecasting mechanism operates as described rather than as richer history features.
minor comments (1)
- [Abstract] The abstract refers to a 'multi-dimensional evaluation suite' without enumerating the dimensions or metrics used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the clarity and verifiability of our empirical claims. We address each major point below and will incorporate the requested details and evaluations into the revised manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central 6.3% absolute improvement is presented without reported baseline implementation details, statistical significance tests, or explicit task-success definitions, preventing verification that the gain is attributable to the proposed components rather than implementation differences.
Authors: We agree that the current experiments section omits key implementation details for the baselines, statistical significance testing, and precise task-success definitions. In the revision we will expand the Experiments section to include: (1) full baseline implementation details (model checkpoints, training hyperparameters, data augmentation, and optimization settings); (2) statistical significance results (e.g., mean success rates with standard deviations across 5 random seeds and paired t-test p-values); and (3) explicit per-task success criteria (e.g., object displacement thresholds, grasp stability conditions, and temporal windows for dynamic targets). These additions will allow readers to confirm that the reported 6.3% gain stems from the proposed components. revision: yes
-
Referee: [PUMA Architecture] PUMA architecture and results: the claim that scene-centric historical optical flow plus specialized world queries produce reliable short-horizon object-state forecasts rests solely on end-to-end task success; no isolated quantitative evaluation (e.g., future-position or velocity prediction error on held-out trajectories) is provided to confirm the forecasting mechanism operates as described rather than as richer history features.
Authors: We acknowledge that the forecasting behavior is currently evidenced only indirectly through end-to-end task success. While the architecture is explicitly designed to couple historical optical flow with world queries for implicit short-horizon prediction, we agree that isolated metrics would provide stronger support. In the revised manuscript we will add a dedicated ablation subsection reporting future-position and velocity prediction errors (L2 distance and angular error) on held-out trajectories for both PUMA and ablated variants (no optical flow, no world queries). This will directly quantify the forecasting contribution beyond richer history features. revision: yes
Circularity Check
No circularity; empirical results on new dataset and architecture are self-contained
full rationale
The paper introduces the DOMINO dataset and PUMA architecture, with performance claims resting on direct experimental comparisons of success rates across tasks. No equations, derivations, or self-citations are shown that reduce the reported 6.3% improvement or the implicit forecasting claim to a fitted parameter, self-definition, or prior author result by construction. The integration of scene-centric optical flow and world queries is presented as a design choice whose value is assessed end-to-end via task metrics rather than assumed tautologically. This is the standard case of an empirical contribution with independent validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reliance on single-frame observations restricts spatiotemporal reasoning capabilities in mainstream VLAs
invented entities (1)
-
specialized world queries
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [2]
-
[3]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Bjorck, J., Castañeda, F., Cherniadev, N., Da, X., Ding, R., Fan, L., Fang, Y., Fox, D., Hu, F., Huang, S., et al.: Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734 (2025) 1, 11, 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
In: 9th Annual Conference on Robot Learn- ing (2025) 1, 9, 11, 13, 26, 28, 29, 30, 31
Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M.R., Finn, C., Fusai, N., Galliker, M.Y., et al.:\π0.5: a vision-language-action model with open-world generalization. In: 9th Annual Conference on Robot Learn- ing (2025) 1, 9, 11, 13, 26, 28, 29, 30, 31
work page 2025
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al.:\π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164 (2024) 1, 3, 9, 11, 13, 26
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Robotics: Science and Systems XIX (2023) 2, 13
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Dabis, J., Finn, C., Gopalakr- ishnan, K., Hausman, K., Herzog, A., Hsu, J., et al.: Rt-1: Robotics transformer for real-world control at scale. Robotics: Science and Systems XIX (2023) 2, 13
work page 2023
-
[7]
Bu, Q., Cai, J., Chen, L., Cui, X., Ding, Y., Feng, S., Gao, S., He, X., Hu, X., Huang, X., et al.: Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems. arXiv preprint arXiv:2503.06669 (2025) 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Bu, Q., Yang, Y., Cai, J., Gao, S., Ren, G., Yao, M., Luo, P., Li, H.: Uni- vla: Learning to act anywhere with task-centric latent actions. arXiv preprint arXiv:2505.06111 (2025) 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
WorldVLA: Towards Autoregressive Action World Model
Cen, J., Yu, C., Yuan, H., Jiang, Y., Huang, S., Guo, J., Li, X., Song, Y., Luo, H., Wang, F., et al.: Worldvla: Towards autoregressive action world model. arXiv preprint arXiv:2506.21539 (2025) 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Chen, T., Chen, Z., Chen, B., Cai, Z., Liu, Y., Li, Z., Liang, Q., Lin, X., Ge, Y., Gu, Z., et al.: Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation. arXiv preprint arXiv:2506.18088 (2025) 2, 5, 9, 14, 21
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
GitHub repository (1 2025).https: //doi
starVLA Contributors: Starvla: A lego-like codebase for vision-language-action model developing. GitHub repository (1 2025).https: //doi. org/10 .5281/ zenodo.18264214,https://github.com/starVLA/starVLA9, 11, 12, 27
work page 2025
-
[12]
InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot Policy
Contributors, I.M.: Internvla-m1: A spatially guided vision-language-action frame- work for generalist robot policy. arXiv preprint arXiv:2510.13778 (2025) 9, 11, 13, 25, 26
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
arXiv preprint arXiv:2505.03912 (2025) 1 16 H
Cui, C., Ding, P., Song, W., Bai, S., Tong, X., Ge, Z., Suo, R., Zhou, W., Liu, Y., Jia, B., Zhao, H., Huang, S., Wang, D.: Openhelix: A short survey, empirical analysis, and open-source dual-system vla model for robotic manipulation. arXiv preprint arXiv:2505.03912 (2025) 1 16 H. Fang et al
-
[14]
In: International Conference on Machine Learning
Driess, D., Xia, F., Sajjadi, M.S., Lynch, C., Chowdhery, A., Ichter, B., Wahid, A., Tompson, J., Vuong, Q., Yu, T., et al.: Palm-e: An embodied multimodal language model. In: International Conference on Machine Learning. pp. 8469–8488. PMLR (2023) 13
work page 2023
-
[15]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Ehsani, K., Han, W., Herrasti, A., VanderBilt, E., Weihs, L., Kolve, E., Kembhavi, A., Mottaghi, R.: Manipulathor: A framework for visual object manipulation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 4497–4506 (2021) 14
work page 2021
-
[16]
arXiv preprint arXiv:2505.02152 (2025) 13
Fan, C., Jia, X., Sun, Y., Wang, Y., Wei, J., Gong, Z., Zhao, X., Tomizuka, M., Yang, X., Yan, J., et al.: Interleave-vla: Enhancing robot manipulation with inter- leaved image-text instructions. arXiv preprint arXiv:2505.02152 (2025) 13
-
[17]
In: Scandinavian conference on Image analysis
Farnebäck, G.: Two-frame motion estimation based on polynomial expansion. In: Scandinavian conference on Image analysis. pp. 363–370. Springer (2003) 23
work page 2003
-
[18]
IEEE Robotics and Automation Letters (2020) 14
James, S., Ma, Z., Rovick Arrojo, D., Davison, A.J.: Rlbench: The robot learn- ing benchmark & learning environment. IEEE Robotics and Automation Letters (2020) 14
work page 2020
-
[19]
arXiv preprint arXiv:2510.04246 (2025) 13
Jang,H.,Yu,S.,Kwon,H.,Jeon,H.,Seo,Y.,Shin,J.:Contextvla:Vision-language- action model with amortized multi-frame context. arXiv preprint arXiv:2510.04246 (2025) 13
-
[20]
In: International Conference on Machine Learning
Jiang, Y., Gupta, A., Zhang, Z., Wang, G., Dou, Y., Chen, Y., Fei-Fei, L., Anand- kumar, A., Zhu, Y., Fan, L.: Vima: Robot manipulation with multimodal prompts. In: International Conference on Machine Learning. pp. 14975–15022. PMLR (2023) 13
work page 2023
-
[21]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
Jiang, Z., Xie, Y., Lin, K., Xu, Z., Wan, W., Mandlekar, A., Fan, L.J., Zhu, Y.: Dexmimicgen: Automated data generation for bimanual dexterous manipulation via imitation learning. In: 2025 IEEE International Conference on Robotics and Automation (ICRA). pp. 16923–16930. IEEE (2025) 14
work page 2025
-
[22]
Artificial intelligence101(1-2), 99–134 (1998) 3
Kaelbling, L.P., Littman, M.L., Cassandra, A.R.: Planning and acting in partially observable stochastic domains. Artificial intelligence101(1-2), 99–134 (1998) 3
work page 1998
-
[23]
In: Robotics: Science and Systems (2024) 14
Khazatsky, A., Pertsch, K., Nair, S., Balakrishna, A., Dasari, S., Karamcheti, S., Nasiriany, S., Srirama, M.K., Chen, L.Y., Ellis, K., et al.: Droid: A large-scale in-the-wild robot manipulation dataset. In: Robotics: Science and Systems (2024) 14
work page 2024
-
[24]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Kim, M.J., Finn, C., Liang, P.: Fine-tuning vision-language-action models: Opti- mizing speed and success. arXiv preprint arXiv:2502.19645 (2025) 1, 9, 10, 11, 13, 24, 25, 28, 29, 30, 31
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
In: 8th Annual Conference on Robot Learning 1, 3, 9, 11, 13, 24, 25
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E.P., Sanketi, P.R., Vuong, Q., et al.: Openvla: An open-source vision-language-action model. In: 8th Annual Conference on Robot Learning 1, 3, 9, 11, 13, 24, 25
-
[26]
HAMLET: Switch your Vision-Language-Action Model into a History-Aware Policy
Koo, M., Choi, D., Kim, T., Lee, K., Kim, C., Seo, Y., Shin, J.: Hamlet: Switch your vision-language-action model into a history-aware policy. arXiv preprint arXiv:2510.00695 (2025) 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Evaluating Real-World Robot Manipulation Policies in Simulation
Li, X., Hsu, K., Gu, J., Pertsch, K., Mees, O., Walke, H.R., Fu, C., Lunawat, I., Sieh, I., Kirmani, S., Levine, S., Wu, J., Finn, C., Su, H., Vuong, Q., Xiao, T.: Evaluating real-world robot manipulation policies in simulation. arXiv preprint arXiv:2405.05941 (2024) 14
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Lin, M., Ding, P., Wang, S., Zhuang, Z., Liu, Y., Tong, X., Song, W., Lyu, S., Huang, S., Wang, D.: Hif-vla: Hindsight, insight and foresight through motion representation for vision-language-action models. arXiv preprint arXiv:2512.09928 (2025) 13 Towards Generalizable Robotic Manipulation in Dynamic Environments 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Advances in Neural Information Processing Systems36, 44776–44791 (2023) 14
Liu, B., Zhu, Y., Gao, C., Feng, Y., Liu, Q., Zhu, Y., Stone, P.: Libero: Benchmark- ing knowledge transfer for lifelong robot learning. Advances in Neural Information Processing Systems36, 44776–44791 (2023) 14
work page 2023
-
[30]
arXiv preprint arXiv:2508.19257 (2025) 13
Liu, C., Zhang, J., Li, C., Zhou, Z., Wu, S., Huang, S., Duan, H.: Ttf-vla: Tempo- ral token fusion via pixel-attention integration for vision-language-action models. arXiv preprint arXiv:2508.19257 (2025) 13
-
[31]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Li, C., Yang, J., Su, H., Zhu, J., et al.: Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499 (2023) 8, 23
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Liu, S., Wu, L., Li, B., Tan, H., Chen, H., Wang, Z., Xu, K., Su, H., Zhu, J.: Rdt-1b: a diffusion foundation model for bimanual manipulation. arXiv preprint arXiv:2410.07864 (2024) 3, 9, 11, 13, 24, 25
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
International Conference on Learning Representations (2019) 22
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. International Conference on Learning Representations (2019) 22
work page 2019
-
[34]
Makoviychuk, V., Wawrzyniak, L., Guo, Y., Lu, M., Storey, K., Macklin, M., Hoeller, D., Rudin, N., Allshire, A., Handa, A., et al.: Isaac gym: High perfor- mance gpu based physics simulation for robot learning. In: Thirty-fifth Confer- ence on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) 14
-
[35]
IEEE Robotics and Automation Letters7(3), 7327–7334 (2022) 14
Mees, O., Hermann, L., Rosete-Beas, E., Burgard, W.: Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks. IEEE Robotics and Automation Letters7(3), 7327–7334 (2022) 14
work page 2022
-
[36]
Mu, T., Ling, Z., Xiang, F., Yang, D.C., Li, X., Tao, S., Huang, Z., Jia, Z., Su, H.: Maniskill: Generalizable manipulation skill benchmark with large-scale demon- strations. In: Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) 14
-
[37]
In: Robotics: Science and Systems (2024) 14
Nasiriany, S., Maddukuri, A., Zhang, L., Parikh, A., Lo, A., Joshi, A., Mandlekar, A., Zhu, Y.: Robocasa: Large-scale simulation of everyday tasks for generalist robots. In: Robotics: Science and Systems (2024) 14
work page 2024
-
[38]
O’Neill, A., Rehman, A., Maddukuri, A., Gupta, A., Padalkar, A., Lee, A., Pooley, A., Gupta, A., Mandlekar, A., Jain, A., et al.: Open x-embodiment: Robotic learn- ing datasets and rt-x models: Open x-embodiment collaboration 0. pp. 6892–6903. IEEE (2024) 2, 14
work page 2024
-
[39]
Optical Memory and Neural Networks 34(Suppl 1), S72–S82 (2025) 13
Patratskiy, M.A., Kovalev, A.K., Panov, A.I.: Spatial traces: Enhancing vla mod- els with spatial-temporal understanding. Optical Memory and Neural Networks 34(Suppl 1), S72–S82 (2025) 13
work page 2025
-
[40]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Pertsch, K., Stachowicz, K., Ichter, B., Driess, D., Nair, S., Vuong, Q., Mees, O., Finn, C., Levine, S.: Fast: Efficient action tokenization for vision-language-action models. arXiv preprint arXiv:2501.09747 (2025) 9, 11, 25, 26
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
arXiv preprint arXiv:2310.13724 (2023) 14
Puig, X., Undersander, E., Szot, A., Cote, M.D., Yang, T.Y., Partsey, R., Desai, R., Clegg, A.W., Hlavac, M., Min, S.Y., et al.: Habitat 3.0: A co-habitat for humans, avatars and robots. arXiv preprint arXiv:2310.13724 (2023) 14
-
[42]
arXiv preprint arXiv:2402.08191 (2024) 14
Pumacay, W., Singh, I., Duan, J., Krishna, R., Thomason, J., Fox, D.: The colos- seum: A benchmark for evaluating generalization for robotic manipulation. arXiv preprint arXiv:2402.08191 (2024) 14
-
[43]
arXiv preprint arXiv:2602.03983 (2026) 14
Qiu, W., Huang, T., Feng, A., Ying, R.: Efficient long-horizon vision- language-action models via static-dynamic disentanglement. arXiv preprint arXiv:2602.03983 (2026) 14
-
[44]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., Mintun, E., Pan, J., Alwala, K.V., Carion, N., 18 H. Fang et al. Wu, C.Y., Girshick, R., Dollár, P., Feichtenhofer, C.: Sam 2: Segment anything in images and videos (2024),https://arxiv.org/abs/2408.007148, 23
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Transactions on Machine Learning Research 13
Reed, S., Zolna, K., Parisotto, E., Colmenarejo, S.G., Novikov, A., Barth-maron, G., Giménez, M., Sulsky, Y., Kay, J., Springenberg, J.T., et al.: A generalist agent. Transactions on Machine Learning Research 13
-
[46]
Ren, T., Liu, S., Zeng, A., Lin, J., Li, K., Cao, H., Chen, J., Huang, X., Chen, Y., Yan, F., Zeng, Z., Zhang, H., Li, F., Yang, J., Li, H., Jiang, Q., Zhang, L.: Grounded sam: Assembling open-world models for diverse visual tasks (2024) 8, 23
work page 2024
-
[47]
Shi, H., Xie, B., Liu, Y., Sun, L., Liu, F., Wang, T., Zhou, E., Fan, H., Zhang, X., Huang, G.: Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation. arXiv preprint arXiv:2508.19236 (2025) 1, 13
-
[48]
In: Conference on robot learning
Shridhar, M., Manuelli, L., Fox, D.: Cliport: What and where pathways for robotic manipulation. In: Conference on robot learning. pp. 894–906. PMLR (2022) 13
work page 2022
-
[49]
arXiv preprint arXiv:2508.10333 (2025) 14
Song, W., Zhou, Z., Zhao, H., Chen, J., Ding, P., Yan, H., Huang, Y., Tang, F., Wang, D., Li, H.: Reconvla: Reconstructive vision-language-action model as effective robot perceiver. arXiv preprint arXiv:2508.10333 (2025) 14
-
[50]
Octo: An Open-Source Generalist Robot Policy
Team, O.M., Ghosh, D., Walke, H., Pertsch, K., Black, K., Mees, O., Dasari, S., Hejna, J., Kreiman, T., Xu, C., et al.: Octo: An open-source generalist robot policy. arXiv preprint arXiv:2405.12213 (2024) 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
In: Conference on Robot Learning
Walke, H.R., Black, K., Zhao, T.Z., Vuong, Q., Zheng, C., Hansen-Estruch, P., He, A.W., Myers, V., Kim, M.J., Du, M., et al.: Bridgedata v2: A dataset for robot learning at scale. In: Conference on Robot Learning. pp. 1723–1736. PMLR (2023) 2, 14
work page 2023
-
[52]
arXiv preprint arXiv:2509.09372 (2025) 1, 9, 11, 25, 26
Wang, Y., Ding, P., Li, L., Cui, C., Ge, Z., Tong, X., Song, W., Zhao, H., Zhao, W., Hou, P., Huang, S., Tang, Y., Wang, W., Zhang, R., Liu, J., Wang, D.: Vla- adapter: An effective paradigm for tiny-scale vision-language-action model. arXiv preprint arXiv:2509.09372 (2025) 1, 9, 11, 25, 26
-
[53]
In: Findings of the Association for Computational Linguistics: EMNLP 2024
Wang, Y., Yue, Z., Zeng, H., Wang, D., McAuley, J.: Train once, deploy anywhere: Matryoshka representation learning for multimodal recommendation. In: Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 13461–13472 (2024) 14
work page 2024
-
[54]
arXiv preprint arXiv:2412.13877 (2024) 14
Wu, K., Hou, C., Liu, J., Che, Z., Ju, X., Yang, Z., Li, M., Zhao, Y., Xu, Z., Yang, G., et al.: Robomind: Benchmark on multi-embodiment intelligence normative data for robot manipulation. arXiv preprint arXiv:2412.13877 (2024) 14
-
[55]
In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020) 2, 5
Xiang, F., Qin, Y., Mo, K., Xia, Y., Zhu, H., Liu, F., Liu, M., Jiang, H., Yuan, Y., Wang, H., Yi, L., Chang, A.X., Guibas, L.J., Su, H.: SAPIEN: A simulated part-based interactive environment. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020) 2, 5
work page 2020
-
[56]
arXiv preprint arXiv:2510.17950 (2025) 14
Yakefu, A., Xie, B., Xu, C., Zhang, E., Zhou, E., Jia, F., Yang, H., Fan, H., Zhang, H., Peng, H., et al.: Robochallenge: Large-scale real-robot evaluation of embodied policies. arXiv preprint arXiv:2510.17950 (2025) 14
-
[57]
arXiv preprint arXiv:2512.22615 (2025) 3
Ye, J., Gong, S., Gao, J., Fan, J., Wu, S., Bi, W., Bai, H., Shang, L., Kong, L.: Dream-vl & dream-vla: Open vision-language and vision-language-action models with diffusion language model backbone. arXiv preprint arXiv:2512.22615 (2025) 3
-
[58]
In: Conference on robot learning
Yu, T., Quillen, D., He, Z., Julian, R., Hausman, K., Finn, C., Levine, S.: Meta- world:Abenchmarkandevaluationformulti-taskandmetareinforcementlearning. In: Conference on robot learning. pp. 1094–1100. PMLR (2020) 14 Towards Generalizable Robotic Manipulation in Dynamic Environments 19
work page 2020
-
[59]
Navid: Video-based vlm plans the next step for vision-and-language navigation,
Zhang, J., Wang, K., Xu, R., Zhou, G., Hong, Y., Fang, X., Wu, Q., Zhang, Z., Wang, H.: Navid: Video-based vlm plans the next step for vision-and-language navigation. arXiv preprint arXiv:2402.15852 (2024) 13
-
[60]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang, S., Xu, Z., Liu, P., Yu, X., Li, Y., Gao, Q., Fei, Z., Yin, Z., Wu, Z., Jiang, Y.G., et al.: Vlabench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 11142–11152 (2025) 14
work page 2025
-
[61]
arXiv preprint arXiv:2507.04447 (2025) 3, 7, 14
Zhang, W., Liu, H., Qi, Z., Wang, Y., Yu, X., Zhang, J., Dong, R., He, J., Lu, F., Wang, H., et al.: Dreamvla: a vision-language-action model dreamed with compre- hensive world knowledge. arXiv preprint arXiv:2507.04447 (2025) 3, 7, 14
-
[62]
IEEE Robotics and Automation Letters (2025) 14
Zhang, Y., Wang, R., Chen, X.: Dynamic behavior cloning with temporal feature prediction: Enhancing robotic arm manipulation in moving object tasks. IEEE Robotics and Automation Letters (2025) 14
work page 2025
-
[63]
Robotics: Science and Systems XIX (2023) 3, 6, 9, 28, 29, 30, 31
Zhao, T., Kumar, V., Levine, S., Finn, C.: Learning fine-grained bimanual manip- ulation with low-cost hardware. Robotics: Science and Systems XIX (2023) 3, 6, 9, 28, 29, 30, 31
work page 2023
-
[64]
TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies
Zheng, R., Liang, Y., Huang, S., Gao, J., Daumé III, H., Kolobov, A., Huang, F., Yang, J.: Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. arXiv preprint arXiv:2412.10345 (2024) 13
work page internal anchor Pith review arXiv 2024
-
[65]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
Zhu, Y., Wong, J., Mandlekar, A., Martín-Martín, R., Joshi, A., Lin, K., Mad- dukuri, A., Nasiriany, S., Zhu, Y.: robosuite: A modular simulation framework and benchmark for robot learning. arXiv preprint arXiv:2009.12293 (2020) 14
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[66]
TowardsGeneralizableRobotic Manipulation in Dynamic Environments
Zitkovich, B., Yu, T., Xu, S., Xu, P., Xiao, T., Xia, F., Wu, J., Wohlhart, P., Welker, S., Wahid, A., et al.: Rt-2: Vision-language-action models transfer web knowledge to robotic control. In: Conference on Robot Learning. pp. 2165–2183. PMLR (2023) 13 20 H. Fang et al. Towards Generalizable Robotic Manipulation in Dynamic Environments Supplementary Mate...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.