Recognition: 2 theorem links
· Lean TheoremAdaMem: Adaptive User-Centric Memory for Long-Horizon Dialogue Agents
Pith reviewed 2026-05-15 09:43 UTC · model grok-4.3
The pith
AdaMem improves long-horizon dialogue performance by organizing memory into four adaptive types and using question-conditioned retrieval with selective graph expansion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AdaMem organizes dialogue history into working, episodic, persona, and graph memories within a single framework. At inference it first resolves the target participant, constructs a question-conditioned retrieval route that starts with semantic retrieval and adds relation-aware graph expansion only when needed, then produces the final answer through a role-specialized pipeline for evidence synthesis and response generation. The method achieves state-of-the-art performance on the LoCoMo and PERSONAMEM benchmarks for long-horizon reasoning and user modeling.
What carries the argument
The question-conditioned retrieval route that combines semantic similarity search with selective relation-aware graph expansion, backed by four distinct memory stores and a role-specialized synthesis pipeline.
If this is right
- Related experiences remain linked through graph structure, preserving temporal and causal coherence that isolated fragments lose.
- Retrieval adapts to each question by expanding the graph only when semantic matches alone are insufficient.
- Different memory types supply evidence at the right granularity for recent context versus long-term traits.
- Role-specialized synthesis steps reduce the chance that mixed evidence produces off-target responses.
- State-of-the-art results appear on both long-horizon reasoning and user-modeling benchmarks.
Where Pith is reading between the lines
- The same conditional retrieval pattern could be applied to agent planning tasks that require consistent memory across multiple steps.
- Selective graph expansion might reduce noise in domains where user relationships form dense but sparse subgraphs.
- Modular role-specialized pipelines could be reused in multi-agent systems to keep synthesis logic separate from retrieval.
- The four-type memory split suggests a general template for balancing recency, episodicity, stability, and connectivity in other long-context applications.
Load-bearing premise
The assumption that adding selective graph expansion and role-specialized synthesis will surface user-centric evidence that pure similarity misses without introducing new coherence or relevance errors.
What would settle it
A controlled test set of long-horizon questions where the full AdaMem pipeline produces lower accuracy or more inconsistent user modeling than a version that uses only semantic retrieval without graph expansion.
Figures




read the original abstract
Large language model (LLM) agents increasingly rely on external memory to support long-horizon interaction, personalized assistance, and multi-step reasoning. However, existing memory systems still face three core challenges: they often rely too heavily on semantic similarity, which can miss evidence crucial for user-centric understanding; they frequently store related experiences as isolated fragments, weakening temporal and causal coherence; and they typically use static memory granularities that do not adapt well to the requirements of different questions. We propose AdaMem, an adaptive user-centric memory framework for long-horizon dialogue agents. AdaMem organizes dialogue history into working, episodic, persona, and graph memories, enabling the system to preserve recent context, structured long-term experiences, stable user traits, and relation-aware connections within a unified framework. At inference time, AdaMem first resolves the target participant, then builds a question-conditioned retrieval route that combines semantic retrieval with relation-aware graph expansion only when needed, and finally produces the answer through a role-specialized pipeline for evidence synthesis and response generation. We evaluate AdaMem on the LoCoMo and PERSONAMEM benchmarks for long-horizon reasoning and user modeling. Experimental results show that AdaMem achieves state-of-the-art performance on both benchmarks. The code will be released upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AdaMem, an adaptive user-centric memory framework for LLM-based long-horizon dialogue agents. It organizes dialogue history into four memory types (working, episodic, persona, and graph) to address limitations of pure semantic similarity retrieval, fragmented storage that breaks temporal/causal links, and static memory granularities. At inference, the system resolves the target participant, constructs a question-conditioned retrieval route that combines semantic retrieval with selective relation-aware graph expansion, and generates responses via a role-specialized synthesis pipeline. The central claim is that this yields state-of-the-art performance on the LoCoMo and PERSONAMEM benchmarks.
Significance. If the results hold under rigorous validation, AdaMem would represent a meaningful step toward more reliable long-term user modeling in dialogue agents by selectively augmenting similarity-based retrieval with structured relational expansion while preserving coherence. This could influence downstream work on personalized agents and memory-augmented reasoning.
major comments (3)
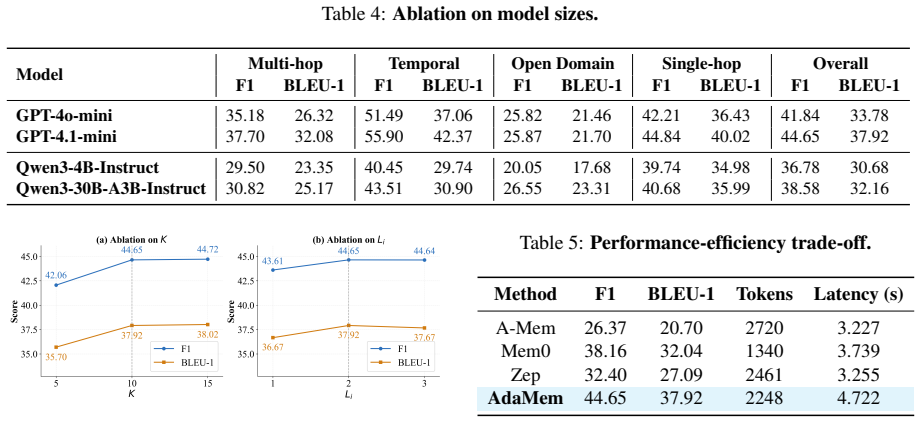
- [Experimental Results] Experimental Results section: The SOTA claim on LoCoMo and PERSONAMEM is presented without ablations that isolate the selective graph expansion component from pure semantic retrieval or from the role-specialized synthesis step. This is load-bearing for the central claim that the combined route captures user-centric evidence missed by similarity alone without introducing coherence or relevance errors.
- [Method / Inference-time Route] Inference-time retrieval route description: No explicit decision rule, threshold, or condition is given for when relation-aware graph expansion is triggered versus skipped. This omission directly affects the weakest assumption that the adaptive mechanism reliably improves over baseline similarity retrieval on long-horizon dialogues.
- [Abstract / Experiments] Abstract and Experiments: The manuscript reports SOTA results but supplies no quantitative metrics, error analysis, or comparison tables in the provided summary; without these, the robustness of the performance advantage cannot be assessed.
minor comments (2)
- [Memory Organization] A summary table comparing the four memory types (working, episodic, persona, graph) on dimensions such as update frequency, retrieval method, and intended use case would improve clarity.
- [Experiments] Ensure that all benchmark-specific metrics and baseline implementations are described with sufficient detail for reproducibility, including any prompt templates used in the role-specialized synthesis.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, providing clarifications from the full paper and committing to revisions that strengthen the experimental validation and method transparency without misrepresenting our contributions.
read point-by-point responses
-
Referee: [Experimental Results] Experimental Results section: The SOTA claim on LoCoMo and PERSONAMEM is presented without ablations that isolate the selective graph expansion component from pure semantic retrieval or from the role-specialized synthesis step. This is load-bearing for the central claim that the combined route captures user-centric evidence missed by similarity alone without introducing coherence or relevance errors.
Authors: We agree that explicit ablations isolating the selective graph expansion and role-specialized synthesis are necessary to substantiate the central claim. The current experiments compare AdaMem against strong baselines that use pure semantic retrieval, but we will add new ablation variants in the revised manuscript: one disabling graph expansion (relying only on semantic retrieval) and one disabling the role-specialized synthesis pipeline. These will quantify incremental gains and confirm no coherence degradation occurs. revision: yes
-
Referee: [Method / Inference-time Route] Inference-time retrieval route description: No explicit decision rule, threshold, or condition is given for when relation-aware graph expansion is triggered versus skipped. This omission directly affects the weakest assumption that the adaptive mechanism reliably improves over baseline similarity retrieval on long-horizon dialogues.
Authors: The decision rule is implemented via the participant resolver combined with a lightweight query classifier that triggers graph expansion for queries involving relational, causal, or cross-event reasoning (e.g., detected via keywords and intent patterns). We will revise the Inference-time Route subsection to include an explicit algorithmic description and pseudocode detailing the exact conditions under which expansion is applied versus skipped. revision: yes
-
Referee: [Abstract / Experiments] Abstract and Experiments: The manuscript reports SOTA results but supplies no quantitative metrics, error analysis, or comparison tables in the provided summary; without these, the robustness of the performance advantage cannot be assessed.
Authors: The full manuscript (Section 4) includes quantitative metrics, comparison tables against baselines on both LoCoMo and PERSONAMEM, and initial error breakdowns. To improve accessibility, we will update the abstract with key numerical results and expand the Experiments section with a dedicated error analysis subsection in the revision. revision: partial
Circularity Check
No circularity: empirical framework with benchmark results
full rationale
The paper introduces AdaMem as a new memory organization (working/episodic/persona/graph) and inference pipeline (participant resolution + conditional semantic+graph retrieval + role synthesis). No equations, fitted parameters, or derivations appear that reduce performance claims to self-defined quantities or author prior work. SOTA results are stated as direct outcomes of evaluation on the external LoCoMo and PERSONAMEM benchmarks, with no self-citation chains or ansatz smuggling invoked to justify the core mechanism. This is a standard empirical systems paper whose central claims rest on reported benchmark numbers rather than any closed derivation loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents benefit from explicit separation of recent context, long-term events, stable traits, and relational structure
invented entities (1)
-
question-conditioned retrieval route
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AdaMem organizes dialogue history into working, episodic, persona, and graph memories... combines semantic retrieval with relation-aware graph expansion only when needed
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose AdaMem, an adaptive user-centric memory framework... achieving state-of-the-art performance on both benchmarks
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Goal-Oriented Reasoning for RAG-based Memory in Conversational Agentic LLM Systems
Goal-Mem improves RAG memory retrieval in agentic LLMs by explicit goal decomposition and backward chaining via Natural Language Logic, outperforming nine baselines on multi-hop and implicit inference tasks.
Reference graph
Works this paper leans on
-
[1]
Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851– 13870. Kai Mei, Xi Zhu, Wujiang Xu, Mingyu Jin, Wenyue Hua, Zelong Li, Shuyuan Xu, Ruosong Ye, Yingqiang Ge, and Yongfeng Zhang. 2025. Aios: Llm agent operating syste...
work page 2025
-
[2]
MemGPT: Towards LLMs as Operating Systems
Memgpt: Towards llms as operating systems. arXiv preprint arXiv:2310.08560. Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. 2025. Zep: a tempo- ral knowledge graph architecture for agent memory. arXiv preprint arXiv:2501.13956. Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-n...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Yanwei Yue, Guibin Zhang, Boyang Liu, Guancheng Wan, Kun Wang, Dawei Cheng, and Yiyan Qi. 2025. Masrouter: Learning to route llms for multi-agent systems. InProceedings of the 63rd Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers). Shaokun Zhang, Ming Yin, Jiey...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Identify one primary topic/event in the message.,→
-
[5]
Infer the author's attitude toward the event
-
[6]
Infer the reason behind the attitude
-
[7]
Extract facts or events revealed by the message.,→
-
[8]
Extract user attributes revealed by the message.,→
-
[9]
Produce a one-sentence summary and a brief rationale.,→ Return JSON: { "text": "original message", "tags": { "topic": ["..."], "attitude": ["Positive|Negative|Mixed"], "reason": ["..."], "facts": ["..."], "attributes": ["..."] }, "summary": "...", "rationale": "..." } Message: "{message}" E.2 Episodic Memory Router Prompts Role.After message understanding...
-
[10]
Only merge topics that talk about the same underlying event/theme.,→
-
[11]
Preserve the original meaning and context of each topic.,→
-
[12]
Extract as many common details as possible when naming the merged topic.,→
-
[13]
Do not reveal the user's attitude in the merged topic name.,→
-
[14]
Keep distinct concepts separate. Input: { "topic1": "summary sentence 1", "topic2": "summary sentence 2", ... } Return JSON: { "Grouped Topics": { "NewTopicName1": ["original_topic1", "original_topic2"],,→ "NewTopicName2": ["original_topic3"] }, "Grouping Rationale": "Explanation of the grouping",→ } E.4 Route Refinement Prompt Role.This prompt is used by...
-
[15]
Keep useful, on-topic information from CURRENT RESULT.,→
-
[16]
Add new, relevant, well-supported facts from EVIDENCE.,→
-
[17]
Remove off-topic content
-
[18]
Prefer concrete details such as entities, dates, numbers, and events.,→
-
[19]
Resolve contradictions by preferring more specific or more recent evidence.,→
-
[20]
Use timestamps when answering temporal questions.,→ Return JSON: { "content": "merged factual summary", "sources": ["source-1", "source-2", ...] } [Info Check Prompt] You are the InfoCheckAgent. Judge whether the collected information is,→ sufficient to answer the QUESTION. QUESTION: {question} RESULT: {result} Return JSON: { "enough": true | false } [Fol...
-
[21]
Identify what is still missing
-
[22]
Generate 1-3 targeted retrieval queries
-
[23]
Mention concrete entities or events whenever possible.,→ Return JSON: { "new_requests": ["query-1", "query-2", ...] } E.6 Working Agent Answer Prompt Role.This prompt is used by the Working Agent to convert the research summary into the final answer. It explicitly encourages concise, entity- centric responses and injects additional persona attributes or f...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.