Recognition: no theorem link
One-to-More: High-Fidelity Training-Free Anomaly Generation with Attention Control
Pith reviewed 2026-05-15 09:42 UTC · model grok-4.3
The pith
O2MAG generates realistic text-guided anomalies from one reference image by grafting self-attention across parallel diffusion processes without any training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
O2MAG manipulates three parallel diffusion processes via self-attention grafting from one reference anomalous image, incorporates the anomaly mask to avoid query confusion, applies Anomaly-Guided Optimization to close the gap between text prompts and true anomaly semantics, and uses Dual-Attention Enhancement to reinforce self- and cross-attention on masked areas, thereby producing synthetic anomalies that adhere to real anomalous distributions.
What carries the argument
Self-attention grafting from a single reference anomaly across three parallel diffusion processes, combined with mask handling, Anomaly-Guided Optimization, and Dual-Attention Enhancement.
If this is right
- The generated anomalies follow real distributions more closely than those from prior few-shot methods.
- Downstream anomaly detection models trained on the synthetic data achieve higher performance on real test images.
- Text prompts can guide the type of anomaly produced without requiring retraining.
- No training step is needed, so new reference anomalies can be used immediately for synthesis.
- Dual-attention reinforcement inside masks reduces faint or incomplete anomaly generation.
Where Pith is reading between the lines
- The same grafting approach could be tested for synthesizing rare events in video or 3D data where only one example exists.
- If attention transfer remains stable across domains, the technique might apply to other few-shot image editing tasks beyond industrial defects.
- The results suggest diffusion-model attention layers carry reusable structural information that can be repurposed across images without fine-tuning.
- Evaluating the method on medical or satellite imagery would show whether one reference suffices when anomaly appearance varies widely.
Load-bearing premise
That grafting self-attention from one reference anomaly and applying the listed optimizations produces outputs whose distribution matches real anomalies without any model training.
What would settle it
If anomaly detectors trained on O2MAG-generated data show no accuracy gain over detectors trained on data from existing trained synthesis methods when evaluated on standard real-world industrial test sets.
Figures


























read the original abstract
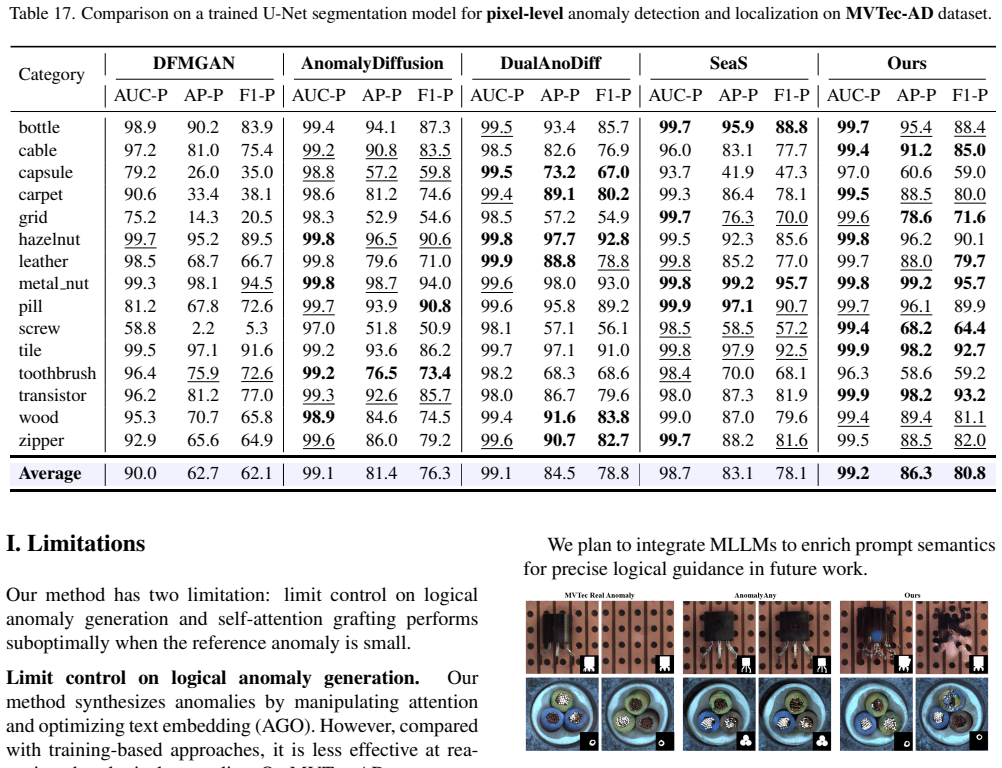
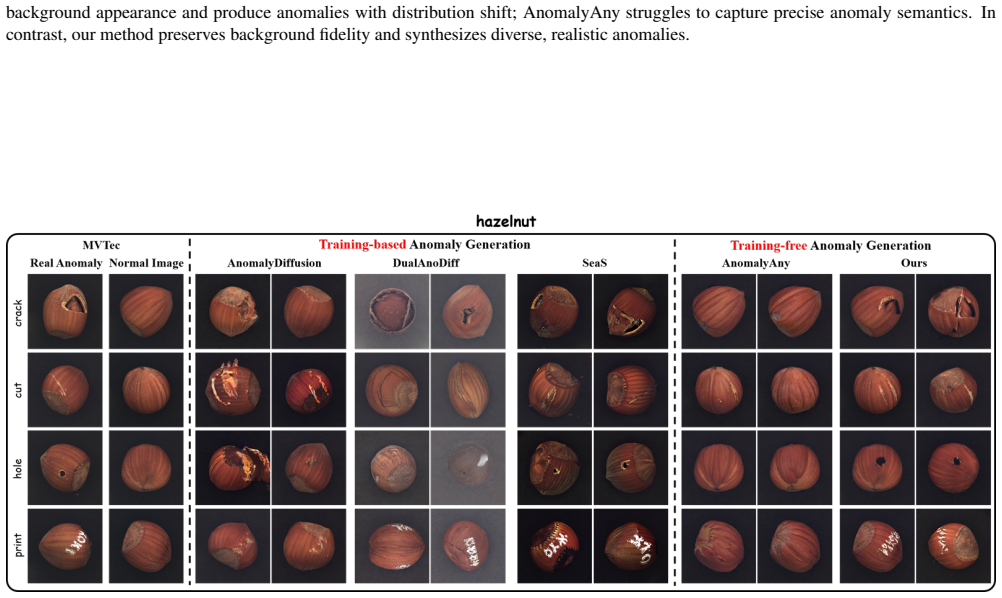
Industrial anomaly detection (AD) is characterized by an abundance of normal images but a scarcity of anomalous ones. Although numerous few-shot anomaly synthesis methods have been proposed to augment anomalous data for downstream AD tasks, most existing approaches require time-consuming training and struggle to learn distributions that are faithful to real anomalies, thereby restricting the efficacy of AD models trained on such data. To address these limitations, we propose a training-free few-shot anomaly generation method, namely O2MAG, which leverages the self-attention in One reference anomalous image to synthesize More realistic anomalies, supporting effective downstream anomaly detection. Specifically, O2MAG manipulates three parallel diffusion processes via self-attention grafting and incorporates the anomaly mask to mitigate foreground-background query confusion, synthesizing text-guided anomalies that closely adhere to real anomalous distributions. To bridge the semantic gap between the encoded anomaly text prompts and the true anomaly semantics, Anomaly-Guided Optimization is further introduced to align the synthesis process with the target anomalous distribution, steering the generation toward realistic and text-consistent anomalies. Moreover, to mitigate faint anomaly synthesis inside anomaly masks, Dual-Attention Enhancement is adopted during generation to reinforce both self- and cross-attention on masked regions. Extensive experiments validate the effectiveness of O2MAG, demonstrating its superior performance over prior state-of-the-art methods on downstream AD tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes O2MAG, a training-free few-shot anomaly generation method that grafts self-attention maps from a single reference anomalous image into three parallel diffusion processes, incorporates anomaly masks to reduce foreground-background confusion, introduces Anomaly-Guided Optimization to align text prompts with anomaly semantics, and applies Dual-Attention Enhancement to reinforce attention on masked regions, with the goal of synthesizing text-guided anomalies that closely match real anomalous distributions and improve downstream industrial anomaly detection performance.
Significance. If the distributional fidelity and downstream superiority claims hold with rigorous evidence, the work would represent a meaningful contribution to anomaly synthesis by removing the training requirement common to prior few-shot methods while leveraging diffusion attention control for realism, potentially enabling more effective data augmentation in data-scarce industrial settings.
major comments (3)
- [Method] Method section (core grafting procedure): Grafting self-attention from only a single reference anomaly fixes the spatial and semantic attention patterns to that specific example; no component (mask handling, optimization, or dual enhancement) is shown to expand support to intra-class variability such as differing defect shapes, sizes, or textures, directly undermining the claim that outputs 'closely adhere to real anomalous distributions'.
- [Abstract and Experiments] Abstract and Experiments: The abstract asserts 'extensive experiments' and 'superior performance over prior state-of-the-art methods on downstream AD tasks', yet provides no quantitative metrics (AUROC/AUPR deltas, FID/MMD scores, or ablation tables); this absence leaves the central fidelity and superiority claims without load-bearing evidence.
- [Abstract and Method] Abstract and Method (Anomaly-Guided Optimization): The method is positioned as training-free, but the optimization step count, learning rate, and grafting strength are listed as free parameters; their presence requires per-instance tuning and partially contradicts the training-free framing while introducing potential sensitivity not addressed in the claims.
minor comments (2)
- [Method] Clarify the exact formulation of the anomaly mask integration into the attention computation with an equation reference to avoid ambiguity in foreground-background query handling.
- [Experiments] Ensure all result figures include side-by-side comparisons with baselines and quantitative captions rather than relying solely on qualitative visuals.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below with clarifications and indicate the corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [Method] Method section (core grafting procedure): Grafting self-attention from only a single reference anomaly fixes the spatial and semantic attention patterns to that specific example; no component (mask handling, optimization, or dual enhancement) is shown to expand support to intra-class variability such as differing defect shapes, sizes, or textures, directly undermining the claim that outputs 'closely adhere to real anomalous distributions'.
Authors: The single-reference grafting provides the base attention pattern, yet the stochastic denoising in diffusion, combined with text conditioning, anomaly masks, Anomaly-Guided Optimization, and Dual-Attention Enhancement, permits controlled variations in defect appearance within the masked region. We agree that explicit evidence of intra-class variability was insufficient and have added new qualitative examples and a quantitative variability analysis (using shape and texture metrics) in the revised experiments section. revision: yes
-
Referee: [Abstract and Experiments] Abstract and Experiments: The abstract asserts 'extensive experiments' and 'superior performance over prior state-of-the-art methods on downstream AD tasks', yet provides no quantitative metrics (AUROC/AUPR deltas, FID/MMD scores, or ablation tables); this absence leaves the central fidelity and superiority claims without load-bearing evidence.
Authors: The full manuscript already contains the requested quantitative results (AUROC/AUPR gains, FID scores, and ablation tables) in Section 4. To make these claims immediately visible, we have revised the abstract to include key numerical deltas and added explicit cross-references to the tables and figures. revision: yes
-
Referee: [Abstract and Method] Abstract and Method (Anomaly-Guided Optimization): The method is positioned as training-free, but the optimization step count, learning rate, and grafting strength are listed as free parameters; their presence requires per-instance tuning and partially contradicts the training-free framing while introducing potential sensitivity not addressed in the claims.
Authors: Training-free denotes the lack of any model training or fine-tuning; the listed values are fixed hyperparameters used uniformly across all instances and datasets. We have revised the abstract and method section to state the exact fixed values (e.g., 50 steps, lr = 0.01) and added a short robustness analysis showing performance stability under small perturbations of these values. revision: partial
Circularity Check
No significant circularity; derivation consists of explicit algorithmic operations on diffusion attention
full rationale
The paper describes O2MAG as a training-free procedure that grafts self-attention maps from a single reference anomaly into three parallel diffusion processes, augments them with an anomaly mask to reduce query confusion, applies Anomaly-Guided Optimization for text alignment, and uses Dual-Attention Enhancement on masked regions. These steps are presented as direct manipulations of attention and diffusion trajectories without any parameter fitting whose output is then relabeled as a prediction, without self-definitional equations, and without load-bearing self-citations that substitute for independent justification. The central claim—that the resulting samples adhere to real anomalous distributions—is an empirical assertion tested on downstream AD tasks rather than a quantity that reduces to the inputs by algebraic identity or construction. No equations or algorithmic reductions in the provided description equate the generated distribution to the reference by tautology.
Axiom & Free-Parameter Ledger
free parameters (2)
- attention grafting strength
- optimization step count and learning rate
axioms (2)
- domain assumption Self-attention maps in diffusion models encode semantic anomaly features that can be grafted across images while preserving background fidelity.
- domain assumption Text prompts for anomalies can be aligned to visual distributions via gradient-based optimization inside the diffusion sampling loop.
invented entities (2)
-
Anomaly-Guided Optimization
no independent evidence
-
Dual-Attention Enhancement
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Anomalycontrol: few-shot anomaly generation by controlnet inpainting.IEEE Access, 2024
Musawar Ali, Nicola Fioraio, Samuele Salti, and Luigi Di Setfano. Anomalycontrol: few-shot anomaly generation by controlnet inpainting.IEEE Access, 2024. 2
work page 2024
-
[2]
Mvtec ad–a comprehensive real-world dataset for unsupervised anomaly detection
Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. Mvtec ad–a comprehensive real-world dataset for unsupervised anomaly detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9592–9600, 2019. 2, 6
work page 2019
-
[3]
Mikołaj Bi´nkowski, Danica J Sutherland, Michael Arbel, and Arthur Gretton. Demystifying mmd gans.arXiv preprint arXiv:1801.01401, 2018. 6
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Masactrl: Tuning-free mu- tual self-attention control for consistent image synthesis and editing
Mingdeng Cao, Xintao Wang, Zhongang Qi, Ying Shan, Xi- aohu Qie, and Yinqiang Zheng. Masactrl: Tuning-free mu- tual self-attention control for consistent image synthesis and editing. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 22560–22570, 2023. 3, 5
work page 2023
-
[5]
Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, and Daniel Cohen-Or. Attend-and-excite: Attention-based se- mantic guidance for text-to-image diffusion models.ACM transactions on Graphics (TOG), 42(4):1–10, 2023. 3
work page 2023
-
[6]
JaeHyuck Choi, MinJun Kim, and JeHyeong Hong. Magic: Mask-guided diffusion inpainting with multi-level pertur- bations and context-aware alignment for few-shot anomaly generation.arXiv preprint arXiv:2507.02314, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Generating and reweighting dense contrastive pat- terns for unsupervised anomaly detection
Songmin Dai, Yifan Wu, Xiaoqiang Li, and Xiangyang Xue. Generating and reweighting dense contrastive pat- terns for unsupervised anomaly detection. InProceedings of the AAAI Conference on Artificial Intelligence, pages 1454– 1462, 2024
work page 2024
-
[8]
Seas: Few-shot industrial anomaly image gen- eration with separation and sharing fine-tuning, 2025
Zhewei Dai, Shilei Zeng, Haotian Liu, Xurui Li, Feng Xue, and Yu Zhou. Seas: Few-shot industrial anomaly image gen- eration with separation and sharing fine-tuning, 2025. 2, 3, 6, 7, 8, 5
work page 2025
-
[9]
Few- shot defect image generation via defect-aware feature manip- ulation
Yuxuan Duan, Yan Hong, Li Niu, and Liqing Zhang. Few- shot defect image generation via defect-aware feature manip- ulation. InProceedings of the AAAI conference on artificial intelligence, pages 571–578, 2023. 2, 6, 7, 8, 3
work page 2023
-
[10]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patash- nik, Amit H Bermano, Gal Chechik, and Daniel Cohen- Or. An image is worth one word: Personalizing text-to- image generation using textual inversion.arXiv preprint arXiv:2208.01618, 2022. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Generative adversarial networks.Commu- nications of the ACM, 63(11):139–144, 2020
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks.Commu- nications of the ACM, 63(11):139–144, 2020. 2
work page 2020
-
[12]
Few-shot anomaly-driven generation for anomaly classification and segmentation, 2025
Guan Gui, Bin-Bin Gao, Jun Liu, Chengjie Wang, and Yun- sheng Wu. Few-shot anomaly-driven generation for anomaly classification and segmentation, 2025. 2
work page 2025
-
[13]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 4, 7, 8
work page 2016
-
[14]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt im- age editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium.Advances in neural information processing systems, 30, 2017. 6
work page 2017
-
[16]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Anomalyxfu- sion: Multi-modal anomaly synthesis with diffusion.arXiv preprint arXiv:2404.19444, 2024
Jie Hu, Yawen Huang, Yilin Lu, Guoyang Xie, Guan- nan Jiang, Yefeng Zheng, and Zhichao Lu. Anomalyxfu- sion: Multi-modal anomaly synthesis with diffusion.arXiv preprint arXiv:2404.19444, 2024. 2
-
[18]
Anomalyd- iffusion: Few-shot anomaly image generation with diffusion model
Teng Hu, Jiangning Zhang, Ran Yi, Yuzhen Du, Xu Chen, Liang Liu, Yabiao Wang, and Chengjie Wang. Anomalyd- iffusion: Few-shot anomaly image generation with diffusion model. InProceedings of the AAAI conference on artificial intelligence, pages 8526–8534, 2024. 2, 6, 7, 8, 3, 5
work page 2024
-
[19]
Haoqi Huang, Ping Wang, Jianhua Pei, Jiacheng Wang, Sha- hen Alexanian, and Dusit Niyato. Deep learning advance- ments in anomaly detection: A comprehensive survey.IEEE Internet of Things Journal, 2025. 1
work page 2025
-
[20]
Dual-interrelated diffusion model for few-shot anomaly image generation
Ying Jin, Jinlong Peng, Qingdong He, Teng Hu, Jiafu Wu, Hao Chen, Haoxuan Wang, Wenbing Zhu, Mingmin Chi, Jun Liu, et al. Dual-interrelated diffusion model for few-shot anomaly image generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 30420– 30429, 2025. 2, 6, 7, 8, 3, 5
work page 2025
-
[21]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2017. 6
work page 2017
-
[22]
Cutpaste: Self-supervised learning for anomaly de- tection and localization
Chun-Liang Li, Kihyuk Sohn, Jinsung Yoon, and Tomas Pfister. Cutpaste: Self-supervised learning for anomaly de- tection and localization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9664–9674, 2021. 2
work page 2021
-
[23]
Promptad: Learn- ing prompts with only normal samples for few-shot anomaly detection
Xiaofan Li, Zhizhong Zhang, Xin Tan, Chengwei Chen, Yanyun Qu, Yuan Xie, and Lizhuang Ma. Promptad: Learn- ing prompts with only normal samples for few-shot anomaly detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16838– 16848, 2024. 2
work page 2024
-
[24]
A comprehensive augmenta- tion framework for anomaly detection
Jiang Lin and Yaping Yan. A comprehensive augmenta- tion framework for anomaly detection. InProceedings of the AAAI Conference on Artificial Intelligence, pages 8742– 8749, 2024. 1
work page 2024
-
[25]
Compositional visual generation with composable diffusion models
Nan Liu, Shuang Li, Yilun Du, Antonio Torralba, and Joshua B Tenenbaum. Compositional visual generation with composable diffusion models. InEuropean conference on computer vision, pages 423–439. Springer, 2022. 5
work page 2022
-
[26]
Lars Mescheder, Andreas Geiger, and Sebastian Nowozin. Which training methods for gans do actually converge? In International conference on machine learning, pages 3481–
-
[27]
Shuanlong Niu, Bin Li, Xinggang Wang, and Hui Lin. De- fect image sample generation with gan for improving defect recognition.IEEE Transactions on Automation Science and Engineering, 17(3):1611–1622, 2020. 2
work page 2020
-
[28]
Few-shot image generation via cross-domain correspondence
Utkarsh Ojha, Yijun Li, Jingwan Lu, Alexei A Efros, Yong Jae Lee, Eli Shechtman, and Richard Zhang. Few-shot image generation via cross-domain correspondence. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10743–10752, 2021. 6
work page 2021
-
[29]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 3, 5
work page 2021
-
[30]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2, 3, 4, 6, 1
work page 2022
-
[31]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. InInternational Conference on Medical image com- puting and computer-assisted intervention, pages 234–241. Springer, 2015. 4, 7
work page 2015
-
[32]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500– 22510, 2023. 2, 3
work page 2023
-
[33]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Worts- man, et al. Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural in- formation processing systems, 35:25278–25294, 2022. 2
work page 2022
-
[34]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 4
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[35]
Defectfill: Realistic defect generation with inpainting diffusion model for visual inspection
Jaewoo Song, Daemin Park, Kanghyun Baek, Sangyub Lee, Jooyoung Choi, Eunji Kim, and Sungroh Yoon. Defectfill: Realistic defect generation with inpainting diffusion model for visual inspection. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18718–18727,
-
[36]
Unseen visual anomaly generation
Han Sun, Yunkang Cao, Hao Dong, and Olga Fink. Unseen visual anomaly generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 25508– 25517, 2025. 2, 3, 6, 7
work page 2025
-
[37]
Plug-and-play diffusion features for text-driven image-to-image translation
Narek Tumanyan, Michal Geyer, Shai Bagon, and Tali Dekel. Plug-and-play diffusion features for text-driven image-to-image translation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1921–1930, 2023. 3
work page 1921
-
[38]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 4, 6
work page 2017
-
[39]
Multi-party collaborative attention control for image customization
Han Yang, Chuanguang Yang, Qiuli Wang, Zhulin An, Weilun Feng, Libo Huang, and Yongjun Xu. Multi-party collaborative attention control for image customization. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 7942–7951, 2025. 3
work page 2025
-
[40]
Explicit boundary guided semi-push- pull contrastive learning for supervised anomaly detection
Xincheng Yao, Ruoqi Li, Jing Zhang, Jun Sun, and Chongyang Zhang. Explicit boundary guided semi-push- pull contrastive learning for supervised anomaly detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24490–24499, 2023. 2
work page 2023
-
[41]
Qianzi Yu, Kai Zhu, Yang Cao, Feijie Xia, and Yu Kang. Tf2: Few-shot text-free training-free defect image genera- tion for industrial anomaly inspection.IEEE Transactions on Circuits and Systems for Video Technology, 34(11):11825– 11837, 2024. 3, 6, 7, 8
work page 2024
-
[42]
Draem- a discriminatively trained reconstruction embedding for sur- face anomaly detection
Vitjan Zavrtanik, Matej Kristan, and Danijel Skoˇcaj. Draem- a discriminatively trained reconstruction embedding for sur- face anomaly detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 8330– 8339, 2021. 2, 8
work page 2021
-
[43]
Defect-gan: High-fidelity defect synthesis for automated defect inspection
Gongjie Zhang, Kaiwen Cui, Tzu-Yi Hung, and Shijian Lu. Defect-gan: High-fidelity defect synthesis for automated defect inspection. InProceedings of the IEEE/CVF Win- ter Conference on Applications of Computer Vision, pages 2524–2534, 2021. 2
work page 2021
-
[44]
A photo of a [cls] with a [anomalytype]
Ximiao Zhang, Min Xu, and Xiuzhuang Zhou. Realnet: A feature selection network with realistic synthetic anomaly for anomaly detection. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 16699–16708, 2024. 2 One-to-More: High-Fidelity Training-Free Anomaly Generation with Attention Control Supplementary Material Ov...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.