Recognition: 1 theorem link
· Lean TheoremFoleyDirector: Fine-Grained Temporal Steering for Video-to-Audio Generation via Structured Scripts
Pith reviewed 2026-05-15 07:31 UTC · model grok-4.3
The pith
FoleyDirector adds structured temporal scripts to DiT-based video-to-audio models for exact timing control over multiple events.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
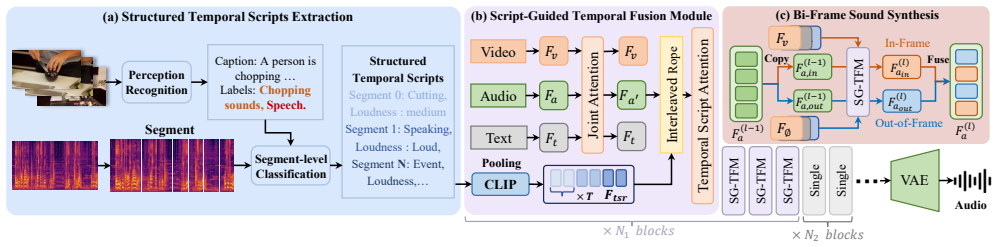
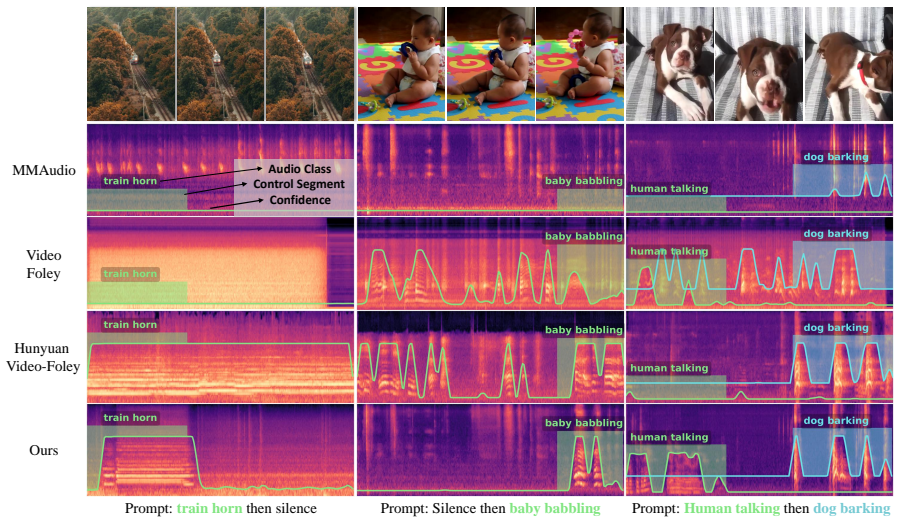
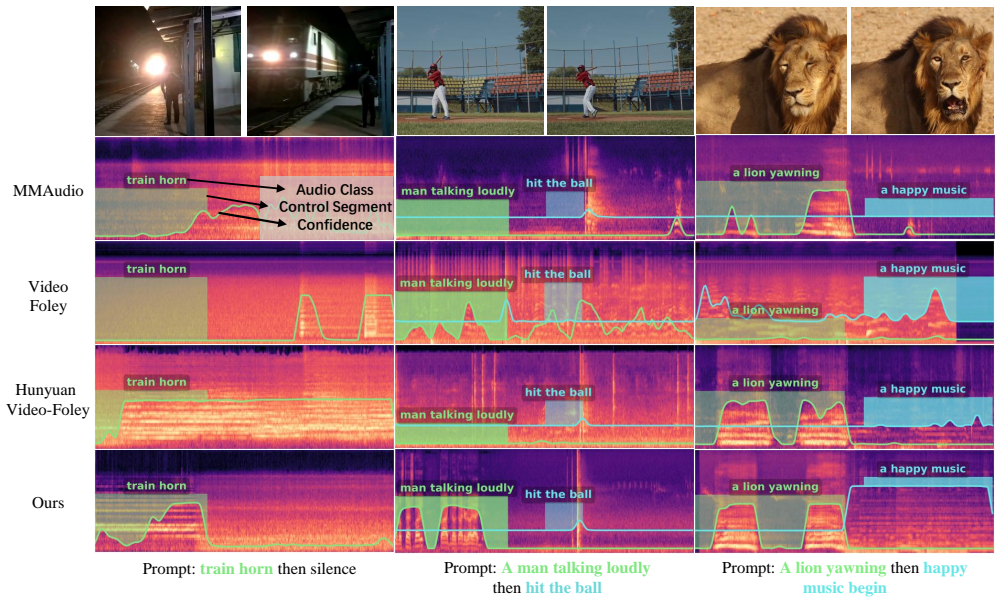
FoleyDirector enables precise temporal guidance in DiT-based V2A generation by introducing Structured Temporal Scripts that supply captions for short temporal segments, integrated through the Script-Guided Temporal Fusion Module using Temporal Script Attention, and supported by Bi-Frame Sound Synthesis for multi-event cases, while preserving base-model audio quality and permitting seamless mode switching.
What carries the argument
Script-Guided Temporal Fusion Module, which applies Temporal Script Attention to merge features from Structured Temporal Scripts into the generation pipeline without degrading fidelity.
If this is right
- Creators gain direct control over when each sound begins and ends in complex scenes.
- Off-screen and occluded sounds become reliably placeable without relying on visible cues.
- The same model can produce both free and temporally directed audio tracks interchangeably.
- New evaluation sets allow direct measurement of timing accuracy in addition to audio realism.
Where Pith is reading between the lines
- The script format could transfer to other time-aligned generation tasks such as video editing or animation sound design.
- Extending the scripts to include intensity or spatial cues might further increase controllability beyond timing alone.
- If the fusion approach generalizes, similar steering could apply to text-to-audio or image-to-audio pipelines.
Load-bearing premise
The fusion module can incorporate the structured scripts without creating audible artifacts or lowering quality when videos contain many overlapping events or weak visual cues.
What would settle it
Generate audio from a multi-event video with scripted timings; if the output either mismatches the requested timing sequence or shows clear quality loss relative to the uncontrolled baseline model, the central claim fails.
Figures








read the original abstract
Recent Video-to-Audio (V2A) methods have achieved remarkable progress, enabling the synthesis of realistic, high-quality audio. However, they struggle with fine-grained temporal control in multi-event scenarios or when visual cues are insufficient, such as small regions, off-screen sounds, or occluded or partially visible objects. In this paper, we propose FoleyDirector, a framework that, for the first time, enables precise temporal guidance in DiT-based V2A generation while preserving the base model's audio quality and allowing seamless switching between V2A generation and temporally controlled synthesis. FoleyDirector introduces Structured Temporal Scripts (STS), a set of captions corresponding to short temporal segments, to provide richer temporal information. These features are integrated via the Script-Guided Temporal Fusion Module, which employs Temporal Script Attention to fuse STS features coherently. To handle complex multi-event scenarios, we further propose Bi-Frame Sound Synthesis, enabling parallel in-frame and out-of-frame audio generation and improving controllability. To support training and evaluation, we construct the DirectorSound dataset and introduce VGGSoundDirector and DirectorBench. Experiments demonstrate that FoleyDirector substantially enhances temporal controllability while maintaining high audio fidelity, empowering users to act as Foley directors and advancing V2A toward more expressive and controllable generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FoleyDirector, a DiT-based video-to-audio (V2A) framework that introduces Structured Temporal Scripts (STS) as per-segment captions to enable fine-grained temporal control. These are fused via the Script-Guided Temporal Fusion Module using Temporal Script Attention, while Bi-Frame Sound Synthesis generates parallel in-frame and out-of-frame audio for multi-event cases. New resources DirectorSound, VGGSoundDirector, and DirectorBench are presented for training and evaluation. The central claim is that the method delivers precise temporal guidance while preserving base-model audio quality and permitting seamless switching between standard V2A and controlled synthesis.
Significance. If the quantitative claims hold, the work would meaningfully advance controllable V2A by addressing a recognized gap in multi-event and low-visibility scenarios. The modular STS representation and switchable architecture could enable practical user-directed Foley workflows, and the introduced benchmarks would provide a standardized testbed for future temporal-control research.
major comments (3)
- [§3.2] §3.2 (Script-Guided Temporal Fusion Module): the Temporal Script Attention mechanism is described only at a high level; without the explicit attention formulation or integration equations, it is impossible to verify that STS features are fused without introducing artifacts or altering the base DiT distribution in low-visibility or occluded-object cases, which is load-bearing for the 'no quality degradation' claim.
- [§4.2] §4.2 and Table 3 (Bi-Frame Sound Synthesis ablation): the parallel in-frame/out-of-frame generation is presented as key to multi-event controllability, yet no ablation isolating its contribution versus the fusion module alone is reported; this leaves the attribution of improved temporal metrics on DirectorBench ambiguous.
- [§4.3] §4.3 (quantitative results): the abstract asserts 'substantially enhances temporal controllability while maintaining high audio fidelity,' but the visible results lack direct side-by-side comparison of perceptual quality metrics (e.g., FAD, CLAP) against the unmodified DiT baseline on the same multi-event subsets, undermining the preservation claim.
minor comments (2)
- [Abstract] The term 'Foley directors' is introduced in the abstract without a brief operational definition; a short clarification in §1 would improve accessibility.
- [Figure 2] Figure captions for the architecture diagram should explicitly label the data flow between STS, the fusion module, and the Bi-Frame synthesizer to match the textual description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and will revise the paper to incorporate the suggested clarifications and additional analyses.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Script-Guided Temporal Fusion Module): the Temporal Script Attention mechanism is described only at a high level; without the explicit attention formulation or integration equations, it is impossible to verify that STS features are fused without introducing artifacts or altering the base DiT distribution in low-visibility or occluded-object cases, which is load-bearing for the 'no quality degradation' claim.
Authors: We agree that the description of the Temporal Script Attention in §3.2 is high-level. In the revised manuscript we will add the explicit mathematical formulation, including the query-key-value projections, attention computation, and the precise integration equations showing how STS features are fused into the DiT blocks. These additions will demonstrate that the fusion is designed to preserve the base DiT distribution and does not introduce artifacts, directly supporting the no-degradation claim even in low-visibility and occluded cases. revision: yes
-
Referee: [§4.2] §4.2 and Table 3 (Bi-Frame Sound Synthesis ablation): the parallel in-frame/out-of-frame generation is presented as key to multi-event controllability, yet no ablation isolating its contribution versus the fusion module alone is reported; this leaves the attribution of improved temporal metrics on DirectorBench ambiguous.
Authors: The referee is correct that Table 3 does not isolate the Bi-Frame Sound Synthesis contribution from the fusion module. We will add a dedicated ablation in the revised version that fixes the Script-Guided Temporal Fusion Module and compares variants with and without Bi-Frame Sound Synthesis. This will clarify the specific contribution of the parallel in-frame/out-of-frame generation to the temporal metrics on DirectorBench. revision: yes
-
Referee: [§4.3] §4.3 (quantitative results): the abstract asserts 'substantially enhances temporal controllability while maintaining high audio fidelity,' but the visible results lack direct side-by-side comparison of perceptual quality metrics (e.g., FAD, CLAP) against the unmodified DiT baseline on the same multi-event subsets, undermining the preservation claim.
Authors: We acknowledge that the current quantitative results do not include direct side-by-side perceptual quality comparisons (FAD, CLAP) of the full model versus the unmodified DiT baseline specifically on multi-event subsets. In the revision we will add these comparisons on the relevant DirectorBench multi-event subsets to provide direct evidence that audio fidelity is preserved. revision: yes
Circularity Check
No significant circularity; architectural additions are independent of inputs
full rationale
The paper introduces FoleyDirector as a modular extension to existing DiT-based V2A models via new components (Structured Temporal Scripts, Script-Guided Temporal Fusion Module with Temporal Script Attention, and Bi-Frame Sound Synthesis) plus supporting datasets (DirectorSound, VGGSoundDirector, DirectorBench). No equations, fitted parameters, or self-citations are presented that reduce any claimed result to its own inputs by construction. The temporal control claims rest on the explicit design of these modules rather than any re-derivation or renaming of prior quantities, leaving the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArrowOfTime.leanTemporalSequence, zAtStep, arrow_from_z unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FoleyDirector introduces Structured Temporal Scripts (STS), a set of captions corresponding to short temporal segments... Script-Guided Temporal Fusion Module... Temporal Script Attention... Bi-Frame Sound Synthesis
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
RefineAnything: Multimodal Region-Specific Refinement for Perfect Local Details
RefineAnything is a multimodal diffusion model using Focus-and-Refine crop-and-resize with blended paste-back to achieve high-fidelity local image refinement and near-perfect background preservation.
Reference graph
Works this paper leans on
-
[1]
Black forest labs; frontier ai lab, 2024
BlackForest. Black forest labs; frontier ai lab, 2024. 1, 2
work page 2024
-
[2]
Vggsound: A large-scale audio-visual dataset
Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zis- serman. Vggsound: A large-scale audio-visual dataset. In International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2020. 5
work page 2020
-
[3]
Video-guided foley sound generation with multimodal con- trols
Ziyang Chen, Prem Seetharaman, Bryan Russell, Oriol Ni- eto, David Bourgin, Andrew Owens, and Justin Salamon. Video-guided foley sound generation with multimodal con- trols. 2025. 3
work page 2025
-
[4]
MMAu- dio: Taming multimodal joint training for high-quality video-to-audio synthesis
Ho Kei Cheng, Masato Ishii, Akio Hayakawa, Takashi Shibuya, Alexander Schwing, and Yuki Mitsufuji. MMAu- dio: Taming multimodal joint training for high-quality video-to-audio synthesis. InCVPR, 2025. 1, 2, 3
work page 2025
-
[5]
Simple and controllable music generation
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre D ´efossez. Simple and controllable music generation. InThirty- seventh Conference on Neural Information Processing Sys- tems, 2023. 2
work page 2023
-
[6]
Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, et al. Cosyvoice: A scalable multilingual zero-shot text- to-speech synthesizer based on supervised semantic tokens. arXiv preprint arXiv:2407.05407, 2024. 2
-
[7]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xi- ang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, et al. Cosyvoice 2: Scalable streaming speech synthesis with large language models.arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Zhihao Du, Changfeng Gao, Yuxuan Wang, Fan Yu, Tianyu Zhao, Hao Wang, Xiang Lv, Hui Wang, Xian Shi, Keyu An, et al. Cosyvoice 3: Towards in-the-wild speech gen- eration via scaling-up and post-training.arXiv preprint arXiv:2505.17589, 2025. 2
-
[9]
Deepanway Ghosal, Navonil Majumder, Ambuj Mehrish, and Soujanya Poria. Text-to-audio generation using instruc- tion tuned llm and latent diffusion model.arXiv preprint arXiv:2304.13731, 2023. 2
-
[10]
Imagebind: One embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. InCVPR, 2023. 6
work page 2023
-
[11]
Shawn Hershey, Sourish Chaudhuri, Daniel P. W. Ellis, Jort F. Gemmeke, Aren Jansen, R. Channing Moore, Manoj Plakal, Devin Platt, Rif A. Saurous, Bryan Seybold, Malcolm Slaney, Ron J. Weiss, and Kevin Wilson. Cnn architectures for large-scale audio classification, 2017. 6
work page 2017
-
[12]
Video-to-audio generation with fine-grained temporal semantics.arXiv preprint arXiv:2409.14709, 2024
Yuchen Hu, Yu Gu, Chenxing Li, Rilin Chen, and Dong Yu. Video-to-audio generation with fine-grained temporal semantics.arXiv preprint arXiv:2409.14709, 2024. 2
-
[13]
Feizhen Huang, Yu Wu, Yutian Lin, and Bo Du. Spotlighting partially visible cinematic language for video-to-audio gen- eration via self-distillation, 2025. 2
work page 2025
-
[14]
Rongjie Huang, Jiawei Huang, Dongchao Yang, Yi Ren, Luping Liu, Mingze Li, Zhenhui Ye, Jinglin Liu, Xiang Yin, and Zhou Zhao. Make-an-audio: Text-to-audio genera- tion with prompt-enhanced diffusion models.arXiv preprint arXiv:2301.12661, 2023. 2
-
[15]
Chia-Yu Hung, Navonil Majumder, Zhifeng Kong, Ambuj Mehrish, Amir Zadeh, Chuan Li, Rafael Valle, Bryan Catan- zaro, and Soujanya Poria. Tangoflux: Super fast and faithful text to audio generation with flow matching and clap-ranked preference optimization, 2024. 2
work page 2024
- [16]
-
[17]
Audiocaps: Generating captions for audios in the wild
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. Audiocaps: Generating captions for audios in the wild. InNAACL-HLT, 2019. 5
work page 2019
- [18]
-
[19]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Efficient training of audio transformers with patchout
Khaled Koutini, Jan Schl ¨uter, Hamid Eghbal-zadeh, and Ger- hard Widmer. Efficient training of audio transformers with patchout. InInterspeech 2022, 23rd Annual Conference of the International Speech Communication Association, In- cheon, Korea, 18-22 September 2022, pages 2753–2757. ISCA, 2022. 6
work page 2022
-
[21]
Audiogen: Textually guided audio gen- eration.arXiv preprint arXiv:2209.15352, 2022
Felix Kreuk, Gabriel Synnaeve, Adam Polyak, Uriel Singer, Alexandre D ´efossez, Jade Copet, Devi Parikh, Yaniv Taig- man, and Yossi Adi. Audiogen: Textually guided audio gen- eration.arXiv preprint arXiv:2209.15352, 2022. 2
-
[22]
Junwon Lee, Jaekwon Im, Dabin Kim, and Juhan Nam. Video-foley: Two-stage video-to-sound generation via tem- poral event condition for foley sound.IEEE Transactions on Audio, Speech and Language Processing, 2025. 6, 2
work page 2025
-
[23]
Dreamfoley: Scalable vlms for high-fidelity video-to- audio generation, 2025
Fu Li, Weichao Zhao, You Li, Zhichao Zhou, and Dongliang He. Dreamfoley: Scalable vlms for high-fidelity video-to- audio generation, 2025. 1
work page 2025
-
[24]
You Li, Fan Ma, and Yi Yang. Anysynth: Harnessing the power of image synthetic data generation for generalized vision-language tasks.arXiv preprint arXiv:2411.16749, 2024
-
[25]
Imagine and seek: Improv- ing composed image retrieval with an imagined proxy
You Li, Fan Ma, and Yi Yang. Imagine and seek: Improv- ing composed image retrieval with an imagined proxy. In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 3984–3993, 2025. 1
work page 2025
-
[26]
Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D Plumbley. Audi- oLDM: Text-to-audio generation with latent diffusion mod- els.Proceedings of the International Conference on Machine Learning, pages 21450–21474, 2023. 2
work page 2023
-
[27]
Haohe Liu, Yi Yuan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Yuping Wang, Wenwu Wang, Yuxuan Wang, and Mark D. Plumbley. Audioldm 2: Learning holistic au- dio generation with self-supervised pretraining.IEEE/ACM 9 Transactions on Audio, Speech, and Language Processing, 32:2871–2883, 2024. 2
work page 2024
-
[28]
Flashaudio: Rectified flows for fast and high-fidelity text-to-audio generation, 2025
Huadai Liu, Jialei Wang, Rongjie Huang, Yang Liu, Heng Lu, Zhou Zhao, and Wei Xue. Flashaudio: Rectified flows for fast and high-fidelity text-to-audio generation, 2025. 2
work page 2025
-
[29]
Huadai Liu, Jialei Wang, Kaicheng Luo, Wen Wang, Qian Chen, Zhou Zhao, and Wei Xue. Thinksound: Chain-of- thought reasoning in multimodal large language models for audio generation and editing. 2025. 3
work page 2025
-
[30]
Diff-foley: Synchronized video-to-audio synthesis with la- tent diffusion models, 2023
Simian Luo, Chuanhao Yan, Chenxu Hu, and Hang Zhao. Diff-foley: Synchronized video-to-audio synthesis with la- tent diffusion models, 2023. 1, 2
work page 2023
-
[31]
Fan Ma, Xiaojie Jin, Heng Wang, Yuchen Xian, Jiashi Feng, and Yi Yang. Vista-llama: Reducing hallucination in video language models via equal distance to visual tokens, 2025. 1
work page 2025
-
[32]
Alec Radford, Jong Wook Kim, Chris Hallacy, A. Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from nat- ural language supervision. InICML, 2021. 4
work page 2021
-
[33]
High-resolution image syn- thesis with latent diffusion models, 2022
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models, 2022. 1
work page 2022
-
[34]
Sizhe Shan, Qiulin Li, Yutao Cui, Miles Yang, Yuehai Wang, Qun Yang, Jin Zhou, and Zhao Zhong. Hunyuanvideo- foley: Multimodal diffusion with representation alignment for high-fidelity foley audio generation, 2025. 2, 3, 4
work page 2025
-
[35]
Seedream 4.0: Toward Next-generation Multimodal Image Generation
Seedream Team, Yunpeng Chen, Yu Gao, Lixue Gong, Meng Guo, Qiushan Guo, Zhiyao Guo, Xiaoxia Hou, Weilin Huang, Yixuan Huang, et al. Seedream 4.0: Toward next- generation multimodal image generation.arXiv preprint arXiv:2509.20427, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Temporally aligned audio for video with autoregression
Ilpo Viertola, Vladimir Iashin, and Esa Rahtu. Temporally aligned audio for video with autoregression. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025. 3
work page 2025
-
[37]
Audiobox: Unified audio generation with natural language prompts, 2023
Apoorv Vyas, Bowen Shi, Matthew Le, Andros Tjandra, Yi-Chiao Wu, Baishan Guo, Jiemin Zhang, Xinyue Zhang, Robert Adkins, William Ngan, Jeff Wang, Ivan Cruz, Bapi Akula, Akinniyi Akinyemi, Brian Ellis, Rashel Moritz, Yael Yungster, Alice Rakotoarison, Liang Tan, Chris Summers, Carleigh Wood, Joshua Lane, Mary Williamson, and Wei- Ning Hsu. Audiobox: Unifie...
work page 2023
-
[38]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianx- iao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jin- gren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fan...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Kling-foley: Multimodal diffusion trans- former for high-quality video-to-audio generation
Jun Wang, Xijuan Zeng, Chunyu Qiang, Ruilong Chen, Shiyao Wang, Le Wang, Wangjing Zhou, Pengfei Cai, Jiahui Zhao, Nan Li, et al. Kling-foley: Multimodal diffusion trans- former for high-quality video-to-audio generation. 2025. 2, 3
work page 2025
-
[40]
Yongqi Wang, Wenxiang Guo, Rongjie Huang, Jiawei Huang, Zehan Wang, Fuming You, Ruiqi Li, and Zhou Zhao. Frieren: Efficient video-to-audio generation network with rectified flow matching.Advances in Neural Information Processing Systems, 37:128118–128138, 2024. 3
work page 2024
-
[41]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, et al. Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.18871, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-omni: A family of omni-modal large language models.arXiv preprint arXiv:2503.20215, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Video-to-audio generation with hidden alignment, 2024
Manjie Xu, Chenxing Li, Yong Ren, Rilin Chen, Yu Gu, Wei Liang, and Dong Yu. Video-to-audio generation with hidden alignment, 2024. 3
work page 2024
-
[44]
Ruihang Xu, Dewei Zhou, Fan Ma, and Yi Yang. Con- textgen: Contextual layout anchoring for identity-consistent multi-instance generation.arXiv preprint arXiv:2510.11000,
-
[45]
Towards weakly supervised text-to-audio grounding.arXiv preprint arXiv:2401.02584, 2024
Xuenan Xu, Ziyang Ma, Mengyue Wu, and Kai Yu. Towards weakly supervised text-to-audio grounding.arXiv preprint arXiv:2401.02584, 2024. 6
-
[46]
Dongchao Yang, Jianwei Yu, Helin Wang, Wen Wang, Chao Weng, Yuexian Zou, and Dong Yu. Diffsound: Discrete diffusion model for text-to-sound generation.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:1720–1733, 2023. 2
work page 2023
-
[47]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Foley- crafter: Bring silent videos to life with lifelike and synchro- nized sounds, 2024
Yiming Zhang, Yicheng Gu, Yanhong Zeng, Zhening Xing, Yuancheng Wang, Zhizheng Wu, and Kai Chen. Foley- crafter: Bring silent videos to life with lifelike and synchro- nized sounds, 2024. 2
work page 2024
-
[49]
Dewei Zhou, You Li, Fan Ma, Zongxin Yang, and Yi Yang. Migc++: Advanced multi-instance generation controller for image synthesis.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 1, 3
work page 2024
-
[50]
Migc: Multi-instance generation controller for text-to-image synthesis
Dewei Zhou, You Li, Fan Ma, Xiaoting Zhang, and Yi Yang. Migc: Multi-instance generation controller for text-to-image synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6818– 6828, 2024. 3
work page 2024
-
[51]
Dewei Zhou, Ji Xie, Zongxin Yang, and Yi Yang. 3dis: Depth-driven decoupled instance synthesis for text-to-image generation.arXiv preprint arXiv:2410.12669, 2024. 10
-
[52]
Dewei Zhou, Mingwei Li, Zongxin Yang, Yu Lu, Yunqiu Xu, Zhizhong Wang, Zeyi Huang, and Yi Yang. Bidedpo: Condi- tional image generation with simultaneous text and condition alignment.arXiv preprint arXiv:2511.19268, 2025
-
[53]
Dreamrenderer: Taming multi-instance attribute control in large-scale text-to-image models
Dewei Zhou, Mingwei Li, Zongxin Yang, and Yi Yang. Dreamrenderer: Taming multi-instance attribute control in large-scale text-to-image models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16712–16722, 2025
work page 2025
-
[54]
Dewei Zhou, Ji Xie, Zongxin Yang, and Yi Yang. 3dis-flux: simple and efficient multi-instance generation with dit ren- dering.arXiv preprint arXiv:2501.05131, 2025. 1
-
[55]
Masked audio generation using a single non- autoregressive transformer, 2024
Alon Ziv, Itai Gat, Gael Le Lan, Tal Remez, Felix Kreuk, Alexandre D ´efossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. Masked audio generation using a single non- autoregressive transformer, 2024. 2 11 FoleyDirector: Fine-Grained Temporal Steering for Video-to-Audio Generation via Structured Scripts Supplementary Material Figure 4.Ablation on trainin...
work page 2024
-
[56]
Analyze the audio in the context of the video to form a rich overall perception, considering multiple aspects such as content, timbre, volume, pitch, texture, and environment
-
[57]
Generate a concise and informative caption summarizing your perception: caption:
-
[58]
Based on the caption and the audio, identify and locate distinct sound events, including their timing
-
[59]
(b) Segment-level Classification You are an audio-visual analysis expert
List all detected sound categories in the format: category: sound1, sound2, ..., separated by commas. (b) Segment-level Classification You are an audio-visual analysis expert. Analyze the provided audio clip along with its corresponding video clip, and determine whether any of the specified categories are present
-
[60]
For each category in the provided list, indicate whether the category is present in the clip ("Yes") or absent ("No"), based primarily on the audio, but ensure your conclusion is consistent with the visual content
-
[61]
If a category is present, you may optionally provide additional details such as: a) Loudness: "soft", "medium", or "loud“ b) Timbre: a brief description of the sound quality c) Desc: a brief caption of sound Output the result in the following JSON format only Figure 5.System Prompt.The system prompt we used in annotation pipeline Distribution matching Qua...
-
[62]
We train our model on 8×A800 GPUs (40 GB each) us- ing the MMAudio-medium architecture, with a total train- ing time of approximately 72 hours. During training, we randomly drop TSR features with a probability of 0.1 We set an initial learning rate of2.0×10 −5. We use the AdamW optimizer and a cosine learning rate decay schedule. We apply a weight decay o...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.