Recognition: 1 theorem link
· Lean TheoremSTAC: Plug-and-Play Spatio-Temporal Aware Cache Compression for Streaming 3D Reconstruction
Pith reviewed 2026-05-15 10:01 UTC · model grok-4.3
The pith
STAC reduces memory use nearly 10x and speeds inference 4x in streaming 3D reconstruction by compressing the growing KV cache while preserving quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
STAC is a plug-and-play Spatio-Temporally Aware Cache Compression framework that keeps long-term informative tokens via decayed cumulative attention scores, folds spatially redundant tokens into voxel-aligned representations, and jointly optimizes consecutive frames in chunks; together these steps cut memory consumption by nearly 10x and raise inference speed by 4x without degrading reconstruction quality or temporal consistency.
What carries the argument
The central mechanism is the three-part STAC cache compressor: Working Temporal Token Caching that ranks tokens by decayed cumulative attention, Long-term Spatial Token Caching that collapses redundant tokens into voxel grids, and Chunk-based Multi-frame Optimization that processes frame groups together.
If this is right
- Long input streams can be processed under fixed memory budgets without early eviction.
- Temporal coherence across frames remains high because informative tokens are retained by attention history.
- GPU throughput rises because both cache size and attention computation shrink.
- The same compression layers can be inserted into any existing causal 3D transformer without retraining.
- Real-time deployment on resource-limited devices becomes feasible for extended sessions.
Where Pith is reading between the lines
- The sparsity observation could be tested in other causal transformer pipelines such as video generation or long-horizon robotics perception.
- Adaptive compression thresholds might further reduce memory when scene complexity is low.
- The voxel-aligned storage format may lend itself to direct integration with downstream meshing or rendering pipelines.
- Similar decay-and-compress logic could be applied to non-3D streaming tasks that already use KV caches.
- The chunk optimization strategy might generalize to any multi-frame causal model to improve both speed and coherence.
Load-bearing premise
The assumption that attention patterns inside causal transformers for 3D reconstruction contain intrinsic spatio-temporal sparsity that can be removed without harming geometry accuracy or frame-to-frame consistency.
What would settle it
Running STAC on a long video stream and measuring a clear rise in reconstruction error or loss of temporal coherence relative to the uncompressed KV cache would show the sparsity claim does not hold.
Figures







read the original abstract
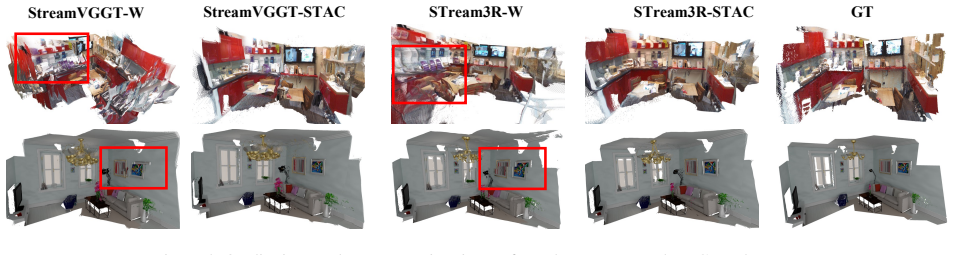
Online 3D reconstruction from streaming inputs requires both long-term temporal consistency and efficient memory usage. Although causal variants of VGGT address this challenge through a key-value (KV) cache mechanism, the cache grows linearly with the stream length, creating a major memory bottleneck. Under limited memory budgets, early cache eviction significantly degrades reconstruction quality and temporal consistency. In this work, we observe that attention in causal transformers for 3D reconstruction exhibits intrinsic spatio-temporal sparsity. Based on this insight, we propose STAC, a Spatio-Temporally Aware Cache Compression framework for streaming 3D reconstruction with large causal transformers. STAC consists of three key components: (1) a Working Temporal Token Caching mechanism that preserves long-term informative tokens using decayed cumulative attention scores; (2) a Long-term Spatial Token Caching scheme that compresses spatially redundant tokens into voxel-aligned representations for memory-efficient storage; and (3) a Chunk-based Multi-frame Optimization strategy that jointly processes consecutive frames to improve temporal coherence and GPU efficiency. Extensive experiments show that STAC achieves state-of-the-art reconstruction quality while reducing memory consumption by nearly 10x and accelerating inference by 4x, substantially improving the scalability of real-time 3D reconstruction in streaming settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes STAC, a plug-and-play Spatio-Temporally Aware Cache Compression framework for streaming 3D reconstruction with large causal transformers. It observes intrinsic spatio-temporal sparsity in attention and introduces three components: Working Temporal Token Caching that retains long-term tokens via decayed cumulative attention scores, Long-term Spatial Token Caching that compresses spatially redundant tokens into voxel-aligned representations, and Chunk-based Multi-frame Optimization to jointly process frames for coherence and efficiency. The central claim is that STAC achieves state-of-the-art reconstruction quality while reducing memory consumption by nearly 10x and accelerating inference by 4x.
Significance. If the empirical results hold, the work would meaningfully advance scalable real-time 3D reconstruction by addressing the linear KV-cache growth bottleneck in streaming settings, enabling longer sequences under fixed memory budgets without compromising geometry accuracy or temporal consistency.
major comments (2)
- [§3.1] §3.1 (Working Temporal Token Caching): The mechanism relies on decayed cumulative attention scores to evict tokens, but the manuscript provides no formal bound or analysis demonstrating that this preserves all salient tokens under rapid viewpoint changes or fine surface details; this assumption is load-bearing for the claim of negligible quality loss.
- [§4] §4 (Experiments): The reported 10x memory reduction and 4x speedup with SOTA quality lack detailed ablations on the sparsity exploitation, comparisons to standard KV eviction baselines across varying stream lengths, and quantitative temporal consistency metrics, making it impossible to verify that compression does not degrade reconstruction under complex motion.
minor comments (2)
- [Abstract] The abstract asserts 'extensive experiments' without naming the specific datasets, metrics (e.g., Chamfer distance, temporal coherence scores), or baseline methods, which reduces clarity.
- [§3.2] Notation for voxel-aligned representations in the Long-term Spatial Token Caching description could be made more precise to avoid ambiguity with standard voxel grid definitions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the theoretical justification and experimental rigor. We address each major comment below and will incorporate revisions to improve the manuscript.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Working Temporal Token Caching): The mechanism relies on decayed cumulative attention scores to evict tokens, but the manuscript provides no formal bound or analysis demonstrating that this preserves all salient tokens under rapid viewpoint changes or fine surface details; this assumption is load-bearing for the claim of negligible quality loss.
Authors: We agree that a formal bound would strengthen the claims. The current design is motivated by observed attention sparsity patterns in 3D reconstruction transformers, and our experiments across sequences with rapid viewpoint changes and fine details show negligible quality degradation. In revision, we will add a dedicated analysis subsection in §3.1 providing further justification for the decay mechanism, including sensitivity studies on eviction thresholds and their effect on surface details. revision: yes
-
Referee: [§4] §4 (Experiments): The reported 10x memory reduction and 4x speedup with SOTA quality lack detailed ablations on the sparsity exploitation, comparisons to standard KV eviction baselines across varying stream lengths, and quantitative temporal consistency metrics, making it impossible to verify that compression does not degrade reconstruction under complex motion.
Authors: We acknowledge these gaps in the experimental section. The manuscript currently reports overall performance gains and qualitative results, but we will expand §4 with: (i) component-wise ablations isolating spatio-temporal sparsity exploitation, (ii) comparisons against standard KV eviction baselines (such as attention-score-based eviction) across short-to-long stream lengths, and (iii) new quantitative temporal consistency metrics including frame-to-frame geometry alignment error and surface normal variance to verify robustness under complex motion. revision: yes
Circularity Check
No significant circularity; derivation rests on empirical observation and new mechanisms
full rationale
The paper grounds its central claim in an empirical observation that attention in causal transformers for 3D reconstruction exhibits intrinsic spatio-temporal sparsity, then introduces three new mechanisms (Working Temporal Token Caching via decayed cumulative scores, Long-term Spatial Token Caching via voxel-aligned compression, and Chunk-based Multi-frame Optimization) whose design is not derived from or equivalent to any fitted parameter or prior self-citation. No equations or uniqueness theorems are invoked that reduce the proposed compression ratios or quality preservation to the input data by construction; the 10x memory and 4x speedup claims are presented as outcomes of experimental validation rather than tautological re-derivations. The framework is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention in causal transformers for 3D reconstruction exhibits intrinsic spatio-temporal sparsity.
invented entities (3)
-
Working Temporal Token Caching
no independent evidence
-
Long-term Spatial Token Caching
no independent evidence
-
Chunk-based Multi-frame Optimization
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we observe that attention in causal transformers for 3D reconstruction exhibits intrinsic spatio-temporal sparsity... Working Temporal Token Caching mechanism that preserves long-term informative tokens using decayed cumulative attention scores; Long-term Spatial Token Caching scheme that compresses spatially redundant tokens into voxel-aligned representations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
S. Agarwal, N. Snavely, S. M. Seitz, and R. Szeliski. Bundle adjustment in the large. InECCV, pages 29–42, 2010. 2
work page 2010
-
[2]
Neural rgb-d surface reconstruction
Dejan Azinovi ´c, Ricardo Martin-Brualla, Dan B Goldman, Matthias Nießner, and Justus Thies. Neural rgb-d surface reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6290– 6301, 2022. 6, 8
work page 2022
-
[3]
Token Merging: Your ViT But Faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. To- ken merging: Your vit but faster.arXiv preprint arXiv:2210.09461, 2022. 6
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakan- tan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Lan- guage models are few-shot learners.Advances in neural in- formation processing systems, 33:1877–1901, 2020. 3
work page 1901
-
[5]
A naturalistic open source movie for op- tical flow evaluation
Daniel J Butler, Jonas Wulff, Garrett B Stanley, and Michael J Black. A naturalistic open source movie for op- tical flow evaluation. InEuropean Conference on Computer Vision, pages 611–625, 2012. 7, 4, 5
work page 2012
-
[6]
Learning to match features with seeded graph matching network
Hongkai Chen, Zixin Luo, Jiahui Zhang, Lei Zhou, Xuyang Bai, Zeyu Hu, Chiew-Lan Tai, and Long Quan. Learning to match features with seeded graph matching network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6301–6310, 2021. 2
work page 2021
-
[7]
Michael Connor and Piyush Kumar. Fast construction of k-nearest neighbor graphs for point clouds.IEEE Transac- tions on Visualization and Computer Graphics, 16(4):599– 608, 2010. 6
work page 2010
-
[8]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5828–5839, 2017. 7
work page 2017
-
[9]
Kai Deng, Zexin Ti, Jiawei Xu, Jian Yang, and Jin Xie. Vggt-long: Chunk it, loop it, align it–pushing vggt’s lim- its on kilometer-scale long rgb sequences.arXiv preprint arXiv:2507.16443, 2025. 2
-
[10]
Shangzhe Di, Zhelun Yu, Guanghao Zhang, Haoyuan Li, Tao Zhong, Hao Cheng, Bolin Li, Wanggui He, Fangxun Shu, and Hao Jiang. Streaming video question-answering with in-context video kv-cache retrieval.arXiv preprint arXiv:2503.00540, 2025. 3
-
[11]
D2- net: A trainable cnn for joint description and detection of local features
Mihai Dusmanu, Ignacio Rocco, Tomas Pajdla, Marc Polle- feys, Josef Sivic, Akihiko Torii, and Torsten Sattler. D2- net: A trainable cnn for joint description and detection of local features. InProceedings of the ieee/cvf Conference on Computer Vision and Pattern Recognition, pages 8092– 8101, 2019. 2
work page 2019
-
[12]
Yasutaka Furukawa, Carlos Hern ´andez, et al. Multi-view stereo: A tutorial.Foundations and trends® in Computer Graphics and Vision, 9(1-2):1–148, 2015. 1, 2
work page 2015
-
[13]
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.The in- ternational journal of robotics research, 32(11):1231–1237,
-
[14]
Vr-gs: A physical dynamics-aware interactive gaussian splatting system in virtual reality
Ying Jiang, Chang Yu, Tianyi Xie, Xuan Li, Yutao Feng, Huamin Wang, Minchen Li, Henry Lau, Feng Gao, Yin Yang, et al. Vr-gs: A physical dynamics-aware interactive gaussian splatting system in virtual reality. InACM SIG- GRAPH 2024 Conference Papers, pages 1–1, 2024. 1
work page 2024
-
[15]
Xin Jin and Jiawei Han.K-Means Clustering, pages 563–
-
[16]
Yushi Lan, Yihang Luo, Fangzhou Hong, Shangchen Zhou, Honghua Chen, Zhaoyang Lyu, Shuai Yang, Bo Dai, Chen Change Loy, and Xingang Pan. Stream3r: Scalable sequential 3d reconstruction with causal transformer.arXiv preprint arXiv:2508.10893, 2025. 1, 2, 3, 4, 5, 6, 7, 8
-
[17]
Ground- ing image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and J´erˆome Revaud. Ground- ing image matching in 3d with mast3r. InEuropean confer- ence on computer vision, pages 71–91. Springer, 2024. 2, 6, 7, 8, 5
work page 2024
-
[18]
David G Lowe. Distinctive image features from scale- invariant keypoints.International Journal of Computer Vi- sion, 60(2):91–110, 2004. 2
work page 2004
-
[19]
International Business Machines Company, 1966
Guy M Morton.A computer oriented geodetic data base and a new technique in file sequencing. International Business Machines Company, 1966. 6
work page 1966
-
[20]
LiveVLM: Efficient Online Video Understanding via Streaming-Oriented KV Cache and Retrieval
Zhenyu Ning, Guangda Liu, Qihao Jin, Wenchao Ding, Minyi Guo, and Jieru Zhao. Livevlm: Efficient online video understanding via streaming-oriented kv cache and retrieval. arXiv preprint arXiv:2505.15269, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Refusion: 3d reconstruction in dynamic environments for rgb-d cameras exploiting resid- uals
Emanuele Palazzolo, Jens Behley, Philipp Lottes, Philippe Giguere, and Cyrill Stachniss. Refusion: 3d reconstruction in dynamic environments for rgb-d cameras exploiting resid- uals. In2019 IEEE/RSJ International Conference on Intel- ligent Robots and Systems (IROS), pages 7855–7862. IEEE,
-
[23]
Vi- sion transformers for dense prediction
Ren ´e Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vi- sion transformers for dense prediction. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 12179–12188, 2021. 3
work page 2021
-
[24]
Mohamed Reda, Ahmed Onsy, Amira Y Haikal, and Ali Ghanbari. Path planning algorithms in the autonomous driv- ing system: A comprehensive review.Robotics and Au- tonomous Systems, 174:104630, 2024. 1
work page 2024
-
[25]
Asmaa Sakr and Tariq Abdullah. Virtual, augmented reality and learning analytics impact on learners, and educators: A systematic review.Education and Information Technologies, 29(15):19913–19962, 2024. 1 9
work page 2024
-
[26]
Superglue: Learning feature matching with graph neural networks
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature matching with graph neural networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4938–4947, 2020. 2
work page 2020
-
[27]
Structure- from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure- from-motion revisited. InProceedings of the IEEE Con- ference on Computer Vision and Pattern Recognition, pages 4104–4113, 2016. 1, 2
work page 2016
-
[28]
Pixelwise view selection for unstructured multi-view stereo
Johannes L Sch ¨onberger, Enliang Zheng, Jan-Michael Frahm, and Marc Pollefeys. Pixelwise view selection for unstructured multi-view stereo. InEuropean Conference on Computer Vision, pages 501–518, 2016. 2
work page 2016
-
[29]
You Shen, Zhipeng Zhang, Yansong Qu, and Liujuan Cao. Fastvggt: Training-free acceleration of visual geometry transformer.arXiv preprint arXiv:2509.02560, 2025. 2
-
[30]
Scene co- ordinate regression forests for camera relocalization in rgb-d images
Jamie Shotton, Ben Glocker, Christopher Zach, Shahram Izadi, Antonio Criminisi, and Andrew Fitzgibbon. Scene co- ordinate regression forests for camera relocalization in rgb-d images. InProceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition, pages 2930–2937,
-
[31]
A benchmark for the eval- uation of rgb-d slam systems
J ¨urgen Sturm, Nikolas Engelhard, Felix Endres, Wolfram Burgard, and Daniel Cremers. A benchmark for the eval- uation of rgb-d slam systems. In2012 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems, pages 573–580. IEEE, 2012. 7, 6
work page 2012
-
[32]
Optimizing the viewing graph for structure-from-motion
Chris Sweeney, Torsten Sattler, Tobias Hollerer, Matthew Turk, and Marc Pollefeys. Optimizing the viewing graph for structure-from-motion. InProceedings of the IEEE interna- tional conference on computer vision, pages 801–809, 2015. 2
work page 2015
-
[33]
Yuxuan Tian, Zihan Wang, Yebo Peng, Aomufei Yuan, Zhiming Wang, Bairen Yi, Xin Liu, Yong Cui, and Tong Yang. Keepkv: Eliminating output perturbation in kv cache compression for efficient llms inference.arXiv preprint arXiv:2504.09936, 2025. 6
-
[34]
Bundle adjustment—a modern synthe- sis
Bill Triggs, Philip F McLauchlan, Richard I Hartley, and An- drew W Fitzgibbon. Bundle adjustment—a modern synthe- sis. InInternational Workshop on Vision Algorithms, pages 298–372, 1999. 2
work page 1999
-
[35]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 3
work page 2017
-
[36]
Gc-mvsnet: Multi-view, multi- scale, geometrically-consistent multi-view stereo
Vibhas K Vats, Sripad Joshi, David J Crandall, Md Alimoor Reza, and Soon-heung Jung. Gc-mvsnet: Multi-view, multi- scale, geometrically-consistent multi-view stereo. InPro- ceedings of the IEEE/CVF Winter Conference on Applica- tions of Computer Vision, pages 3242–3252, 2024. 2
work page 2024
-
[37]
Zhongwei Wan, Xinjian Wu, Yu Zhang, Yi Xin, Chao- fan Tao, Zhihong Zhu, Xin Wang, Siqi Luo, Jing Xiong, Longyue Wang, et al. D2o: Dynamic discriminative oper- ations for efficient long-context inference of large language models.arXiv preprint arXiv:2406.13035, 2024. 3, 5
-
[38]
3d reconstruction with spatial memory.arXiv preprint arXiv:2408.16061, 2024
Hengyi Wang and Lourdes Agapito. 3d reconstruction with spatial memory.arXiv preprint arXiv:2408.16061, 2024. 2, 6, 7, 8, 5
-
[39]
Jiaqi Wang, Enze Shi, Huawen Hu, Chong Ma, Yiheng Liu, Xuhui Wang, Yincheng Yao, Xuan Liu, Bao Ge, and Shu Zhang. Large language models for robotics: Opportunities, challenges, and perspectives.Journal of Automation and In- telligence, 2024. 1
work page 2024
-
[40]
Vggt: Vi- sual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Vi- sual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025. 1, 2, 3, 7, 8, 5
work page 2025
-
[41]
Continuous 3d per- ception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d per- ception model with persistent state. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10510–10522, 2025. 2, 6, 7, 8, 4, 5
work page 2025
-
[42]
Dust3r: Geometric 3d vi- sion made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vi- sion made easy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20697– 20709, 2024. 2, 6, 7, 8, 5
work page 2024
-
[43]
Zheng Wang, Boxiao Jin, Zhongzhi Yu, and Minjia Zhang. Model tells you where to merge: Adaptive kv cache merging for llms on long-context tasks.arXiv preprint arXiv:2407.08454, 2024. 3
-
[44]
Robust global translations with 1dsfm
Kyle Wilson and Noah Snavely. Robust global translations with 1dsfm. InEuropean Conference on Computer Vision, pages 61–75, 2014. 2
work page 2014
-
[45]
Towards linear-time incremental struc- ture from motion
Changchang Wu. Towards linear-time incremental struc- ture from motion. In2013 International Conference on 3D Vision-3DV 2013, pages 127–134. IEEE, 2013. 2
work page 2013
-
[46]
Yuqi Wu, Wenzhao Zheng, Jie Zhou, and Jiwen Lu. Point3r: Streaming 3d reconstruction with explicit spatial pointer memory.arXiv preprint arXiv:2507.02863, 2025. 2, 6, 7, 8, 4, 5
-
[47]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453, 2023. 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass
Jianing Yang, Alexander Sax, Kevin J Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21924–21935,
-
[49]
Yanlai Yang, Zhuokai Zhao, Satya Narayan Shukla, Aashu Singh, Shlok Kumar Mishra, Lizhu Zhang, and Mengye Ren. Streammem: Query-agnostic kv cache memory for stream- ing video understanding.arXiv preprint arXiv:2508.15717,
-
[50]
Junyi Zhang, Charles Herrmann, Junhwa Hur, Varun Jam- pani, Trevor Darrell, Forrester Cole, Deqing Sun, and Ming- Hsuan Yang. Monst3r: A simple approach for estimat- ing geometry in the presence of motion.arXiv preprint arXiv:2410.03825, 2024. 6, 7, 8, 5
-
[51]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher R´e, Clark Barrett, et al. H2o: Heavy-hitter ora- cle for efficient generative inference of large language mod- 10 els.Advances in Neural Information Processing Systems, 36: 34661–34710, 2023. 3, 6
work page 2023
-
[52]
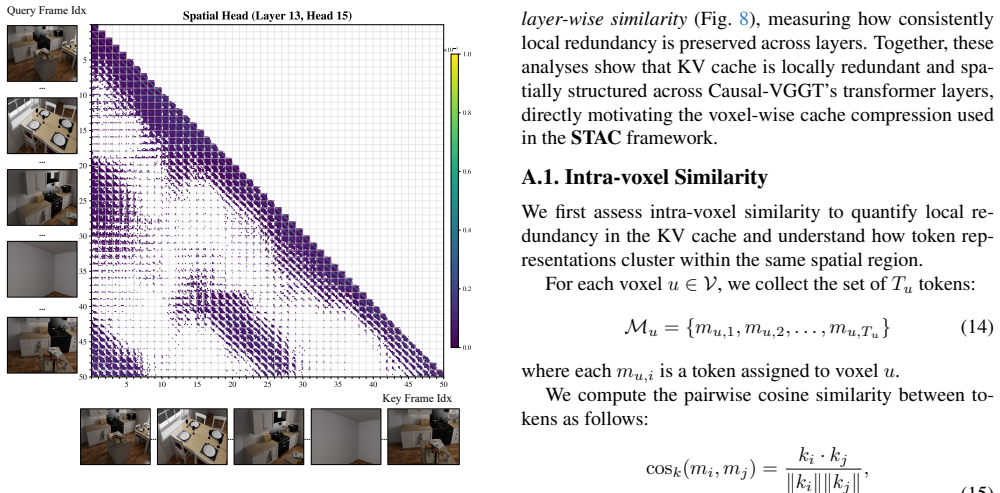
Dong Zhuo, Wenzhao Zheng, Jiahe Guo, Yuqi Wu, Jie Zhou, and Jiwen Lu. Streaming 4d visual geometry transformer. arXiv preprint arXiv:2507.11539, 2025. 1, 2, 3, 4, 5, 6, 7, 8 11 Key Frame Idx Query Frame Idx … … … … … … … … Figure 5. Visualization of a spatial attention head, where the top 1024 relevant key tokens are retained for each query. The axes are ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.