Recognition: no theorem link
Procedural Refinement by LLM-driven Algorithmic Debugging for ARC-AGI-2
Pith reviewed 2026-05-15 09:02 UTC · model grok-4.3
The pith
ABPR couples LLMs with a Prolog meta-interpreter to debug hypothesized transformation rules through SLD proof trees on ARC-AGI-2 tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ABPR treats each LLM-generated program as a declarative hypothesis of the latent rule, reifies its execution into compact SLD proof trees via a Prolog meta-interpreter, and applies Shapiro-style algorithmic debugging to isolate the faulty subgoal; repeated parallel search over these traces then produces refined programs that solve the majority of ARC-AGI-2 evaluation tasks.
What carries the argument
Abduction-Based Procedural Refinement (ABPR), which converts LLM programs into SLD proof trees so that algorithmic debugging can perform semantic re-checking of the hypothesized transformation rule.
If this is right
- Parallel trace-guided search lowers stochastic variance as breadth and depth increase.
- The same framework lifts accuracy on relational abstraction benchmarks beyond grid tasks.
- Refinement shifts from outcome-level feedback to semantic verification of the hypothesized rule.
- Higher Pass@2 scores are achieved without changing the underlying LLM.
Where Pith is reading between the lines
- The proof-tree representation may allow LLMs to explain their reasoning steps in other program-synthesis settings.
- Extending the meta-interpreter to additional symbolic languages could broaden the method to non-Prolog domains.
- If search breadth continues to reduce variance, the approach could become a stable alternative to repeated sampling for hard reasoning problems.
Load-bearing premise
The Prolog meta-interpreter must faithfully translate the LLM's candidate programs into SLD proof trees whose subgoals actually correspond to the latent abstractions required by the grid or relational tasks.
What would settle it
A controlled run on ARC-AGI-2 tasks in which the generated proof trees consistently fail to flag the incorrect subgoal yet the final Pass@2 score shows no improvement over plain LLM prompting would falsify the claim that trace-guided refinement is responsible for the observed gains.
Figures







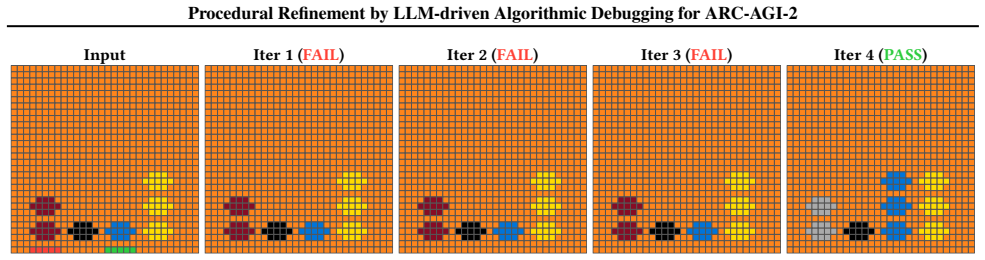
read the original abstract
In high-complexity abstract reasoning, a system must infer a latent rule from a few examples or structured observations and apply it to unseen instances. LLMs can express such rules as programs, but ordinary conversation-based refinement is largely outcome-level: it observes that an answer or output is wrong without formally re-checking which abstraction, relation, or transformation justified that outcome. We propose \emph{Abduction-Based Procedural Refinement} (ABPR), a neuro-symbolic refinement approach that couples an LLM with a Prolog meta-interpreter. ABPR treats each candidate program as an executable declarative hypothesis of the latent rule and reifies its SLD goal--subgoal resolution into compact proof-tree-style derivations, following Shapiro's algorithmic program debugging (APD). In this view, refinement is not merely code-level debugging, but semantic re-checking of the model's hypothesised rule. We evaluate ABPR primarily on ARC-AGI-2, a challenging few-shot abstract rule induction benchmark over grid transformations. ABPR with Gemini-3-Flash achieves 56.67\% Pass@2, while GPT-5.5 xHigh with ABPR reaches 98.33\% Pass@2 on the public evaluation set. Supplementary experiments on fill-in-the-blank I-RAVEN-X and A-I-RAVEN adaptations provide evidence that the same trace-guided framework extends beyond ARC-specific grid tasks to RAVEN-style relational and analogical abstraction. Repeated-run and sensitivity analyses show that parallel trace-guided search reduces stochastic variance as search breadth and refinement depth increase.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Abduction-Based Procedural Refinement (ABPR), a neuro-symbolic method that pairs an LLM with a Prolog meta-interpreter to treat candidate programs as declarative hypotheses of latent transformation rules and refine them via algorithmic debugging on SLD proof trees. It reports 56.67% Pass@2 for Gemini-3-Flash and 98.33% Pass@2 for GPT-5.5 xHigh on the ARC-AGI-2 public set, plus supplementary results on adapted I-RAVEN-X and A-I-RAVEN tasks, claiming that trace-guided search reduces variance with increased breadth and depth.
Significance. If the results hold and the meta-interpreter faithfully maps LLM rules to ARC-relevant abstractions, the work would demonstrate a concrete advance in structured refinement for few-shot abstract reasoning, moving beyond outcome-level LLM feedback to semantic re-checking of hypothesized relations and transformations.
major comments (2)
- [Abstract] Abstract: the headline Pass@2 figures (56.67% and 98.33%) are given without any baseline comparisons (direct LLM prompting, other neuro-symbolic systems, or ablations), error bars, run counts, or explicit definition of how Pass@2 is computed, so the central empirical claim cannot be assessed from the text.
- [Method] Method (Prolog meta-interpreter description): the assertion that SLD goal-subgoal trees reify LLM-proposed rules into subgoals that exactly track ARC latent abstractions (object relations, spatial transformations, color mappings) is not supported by concrete examples or fidelity arguments; if the encoding collapses to low-level grid predicates, the debugging loop cannot deliver the claimed semantic refinement.
minor comments (1)
- [Abstract] Abstract: 'Pass@2' and 'repeated-run and sensitivity analyses' are referenced without operational definitions or pointers to the relevant experimental section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address each major comment point by point below, indicating the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline Pass@2 figures (56.67% and 98.33%) are given without any baseline comparisons (direct LLM prompting, other neuro-symbolic systems, or ablations), error bars, run counts, or explicit definition of how Pass@2 is computed, so the central empirical claim cannot be assessed from the text.
Authors: We agree with this observation. While the full manuscript includes repeated-run analyses and sensitivity studies demonstrating variance reduction with increased breadth and depth, the abstract does not provide baseline comparisons or details on Pass@2 computation. We will revise the abstract to include: (1) a brief comparison to direct LLM prompting baselines, (2) the definition of Pass@2 as the success rate when allowing two independent attempts per task, (3) mention of 5 repeated runs with standard error bars, and (4) reference to ablations on the trace-guided search. This will make the central claims assessable from the abstract. revision: yes
-
Referee: [Method] Method (Prolog meta-interpreter description): the assertion that SLD goal-subgoal trees reify LLM-proposed rules into subgoals that exactly track ARC latent abstractions (object relations, spatial transformations, color mappings) is not supported by concrete examples or fidelity arguments; if the encoding collapses to low-level grid predicates, the debugging loop cannot deliver the claimed semantic refinement.
Authors: We acknowledge the need for concrete examples to support the claim. The current description focuses on the general framework following Shapiro's APD, but lacks specific illustrations. We will add a detailed example in the Method section showing an LLM-generated Prolog rule for an ARC task involving object relations and spatial transformations, along with the corresponding SLD goal-subgoal tree. This example will demonstrate how the predicates capture high-level abstractions (e.g., 'same_color', 'rotated_by_90') rather than low-level grid operations, with arguments for fidelity based on the ARC task ontology. We believe this will clarify that the debugging loop performs semantic refinement. revision: yes
Circularity Check
No circularity: empirical benchmark results from running ABPR on ARC-AGI-2
full rationale
The paper describes a neuro-symbolic method (ABPR) that pairs an LLM with a Prolog meta-interpreter to reify candidate programs into SLD proof trees for refinement, following Shapiro's external APD framework. Performance figures (56.67% and 98.33% Pass@2) are obtained by executing the implemented system on the public ARC-AGI-2 evaluation set. No equations, predictions, or uniqueness claims reduce by construction to fitted parameters, self-defined quantities, or self-citation chains. The central results are falsifiable empirical measurements independent of any internal redefinition of the inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Curious Case of Neural Text Degeneration
URL https://openreview.net/forum? id=Sx038sxNY3. Hitzler, P. and Sarker, M. K. Neuro-symbolic artificial intelligence: The state of the art.AI Communications, 2022. Holtzman, A., Buys, J., Du, L., Forbes, M., and Choi, Y . The curious case of neural text degeneration.arXiv preprint arXiv:1904.09751, 2019. Huang, J., Chen, X., Mishra, S., Zheng, H. S., Yu,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
URL https://openai.com/research. Accessed 2025. Poetiq Team. Traversing the frontier of superintelligence: Poetiq shatters ARC-AGI-2 state of the art. Poetiq AI Technical Blog, January 2025. URL https:// poetiq.ai/posts/arcagi_announcement/. Ridnik, T., Kredo, D., and Friedman, I. Code genera- tion with alphacodium: From prompt engineering to flow enginee...
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[3]
**Training Examples ** - Input-output pairs to help you understand the transformation pattern
-
[4]
Your REAL GOAL is to produce a ‘solve/2‘ predicate that correctly transforms the Challenge input(s)
**Challenge(s)** - New input(s) for which you must produce correct output(s) The Training Examples are for learning the pattern. Your REAL GOAL is to produce a ‘solve/2‘ predicate that correctly transforms the Challenge input(s). The training examples help you understand what transformation to apply, but success is measured by whether your code works on t...
-
[5]
**Example Inspection: ** Carefully examine the input and output grids for each training example. Note their dimensions, color palettes, and any prominent visual features (shapes, symmetries, patterns)
-
[6]
**Challenge Awareness: ** Look at the Challenge input(s). Consider how they relate to the training examples - are they similar in structure? Do they have edge cases not seen in training?
-
[7]
**Formulate a Hypothesis: ** * Based on your analysis, formulate a transformation rule that works consistently across all examples AND generalizes to the challenge. 29 Procedural Refinement by LLM-driven Algorithmic Debugging for ARC-AGI-2 * Express the rule as a sequence of image manipulation operations. * Prioritize simpler, more general rules that avoi...
-
[8]
* You *must* provide code representing your best attempt
**Output Format: ** * Begin with a concise paragraph explaining the proposed solution. * You *must* provide code representing your best attempt. Do not give up or refuse to produce code. * ** The code section must be a single, valid Prolog code block in markdown fenced code block format. ** * ** Start with ‘:- use module(bk).‘** * The main predicate must ...
-
[9]
Study the Training Examples to understand the transformation pattern
-
[10]
Write a Prolog ‘solve/2‘ predicate that correctly implements this transformation
-
[11]
Your code will be tested on the Training Examples for debugging, and the FINAL goal is to correctly transform the Challenge input(s) Remember to use ‘:- use module(bk).‘ and leverage the bk.pl library predicates when appropriate. Fix Prompt **CODE REFINEMENT REQUIRED - Attempt{current iteration}/{max iterations}** Your code has gone through{iteration coun...
-
[12]
The detailed execution trace of the most recent attempt
-
[13]
Identify the root cause of failures - is it a logic error, edge case handling, or incorrect pattern matching? Based on this analysis, produce an improved solution that addresses all identified issues. **REFERENCE SOLUTIONS ({history type}):** {attempts history} 33 Procedural Refinement by LLM-driven Algorithmic Debugging for ARC-AGI-2 **DECLARATIVE DEBUGG...
-
[14]
**INPUT/EXPECTED/ACTUAL grids ** - visual comparison of what was expected vs produced
-
[15]
**DIFFERENCE SUMMARY ** - specific cells that differ
-
[16]
**PROOF TREE ** - the successful execution path showing how your code transformed the data Before you produce your solution, study the proof tree carefully by appling **algothmic program debugging ** rules to identify the buggy predicates:
-
[17]
Start from the root node and check if its output is correct given its input
-
[18]
If a node’s output is CORRECT→skip its entire subtree (no bug there)
-
[19]
If a node’s output is INCORRECT→examine its children nodes
-
[20]
A node is the **bug location ** when: its own output is incorrect, BUT all its children outputs are correct. ‘‘‘ {trace detail} ‘‘‘ **CHALLENGE INPUT(S) - Your code must correctly transform these: ** {challenge diagrams} Remember: The training examples are for learning the pattern, but the REAL goal is to produce correct outputs for the Challenge input(s)...
-
[21]
Address all issues identified in the trace
-
[22]
Handle edge cases properly
-
[23]
**CRITICAL: Ensure the solution GENERALIZES to the Challenge input(s) ** - don’t overfit to training examples
-
[24]
Use bk.pl library predicates correctly (remember: 1-indexed coordinates, bbox is a compound term)
-
[25]
Avoid hardcoding specific values that only work for training examples 34
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.