Recognition: unknown
Clinical Cognition Alignment for Gastrointestinal Diagnosis with Multimodal LLMs
Pith reviewed 2026-05-15 06:31 UTC · model grok-4.3
The pith
The CogAlign framework aligns multimodal LLMs to hierarchical clinical cognition and enforces causal lesion features via counterfactual reinforcement learning for gastrointestinal endoscopy diagnosis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Standard supervised tuning converges to spurious background correlations, but the Clinical-Cognitive-Aligned (CogAlign) framework remedies this by first internalizing hierarchical diagnostic logic through supervised fine-tuning on a clinical cognition dataset and then applying counterfactual reinforcement learning with lesion-masked samples and cognition-centric rewards to ground outputs in causal lesion features.
What carries the argument
Counterfactual-driven reinforcement learning that generates lesion-masked normal samples and optimizes the model using clinical-cognition-centric rewards to enforce causal rectification.
If this is right
- The resulting models achieve state-of-the-art performance across multiple benchmarks.
- Diagnostic accuracy improves significantly in complex clinical scenarios.
- The model internalizes the full hierarchy of expert reasoning from anatomical localization to microvascular analysis.
- Diagnoses become grounded in causal lesion features rather than spurious background correlations.
Where Pith is reading between the lines
- The same hierarchical-plus-counterfactual recipe could transfer to other medical imaging domains that require causal feature grounding.
- The approach may lower the volume of fine-grained annotations needed once the clinical cognition structure is defined.
- Real-time video endoscopy evaluation would test whether the learned causal focus holds under temporal and motion variations.
Load-bearing premise
That lesion-masked counterfactual samples plus clinical-cognition-centric rewards will strictly constrain the model to causal lesion features without introducing new biases or failing to generalize beyond the training distribution.
What would settle it
A controlled test set in which background textures or lighting are systematically varied while lesion features remain fixed, checking whether diagnostic accuracy stays stable or drops.
Figures




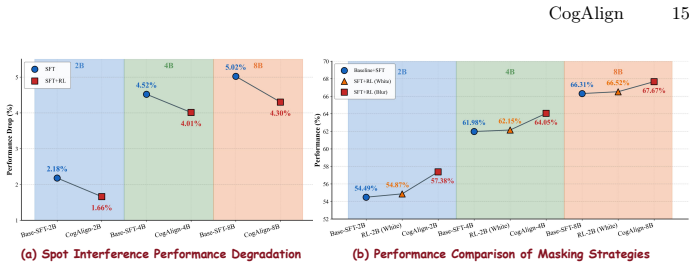
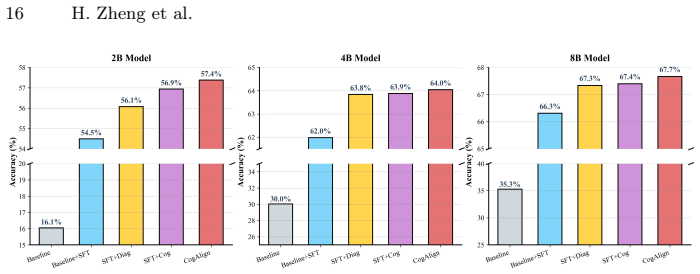
read the original abstract
Multimodal Large Language Models (MLLMs) have demonstrated remarkable potential in medical image analysis. However, their application in gastrointestinal endoscopy is currently hindered by two critical limitations: the misalignment between general model reasoning and standardized clinical cognitive pathways, and the lack of causal association between visual features and diagnostic outcomes. In this paper, we propose a novel Clinical-Cognitive-Aligned (CogAlign) framework to address these challenges. First, we endow the model with rigorous clinical analytical capabilities by constructing the hierarchical clinical cognition dataset and employing Supervised Fine-Tuning (SFT). Unlike conventional approaches, this strategy internalizes the hierarchical diagnostic logic of experts, ranging from anatomical localization and morphological evaluation to microvascular analysis, directly into the model. Second, to eliminate visual bias, we provide a theoretical analysis demonstrating that standard supervised tuning inevitably converges to spurious background correlations. Guided by this insight, we propose a counterfactual-driven reinforcement learning strategy to enforce causal rectification. By generating counterfactual normal samples via lesion masking and optimizing through clinical-cognition-centric rewards, we constrain the model to strictly ground its diagnosis in causal lesion features. Extensive experiments demonstrate that our approach achieves State-of-the-Art (SoTA) performance across multiple benchmarks, significantly enhancing diagnostic accuracy in complex clinical scenarios. All source code and datasets will be made publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Clinical-Cognitive-Aligned (CogAlign) framework for multimodal LLMs in gastrointestinal endoscopy. It constructs a hierarchical clinical cognition dataset for supervised fine-tuning to internalize expert diagnostic logic (anatomical localization to microvascular analysis), followed by a counterfactual reinforcement learning stage that generates lesion-masked normal samples and optimizes via clinical-cognition-centric rewards to enforce causal grounding and eliminate spurious background correlations. The authors claim this yields state-of-the-art performance across multiple benchmarks.
Significance. If the empirical claims hold and the method generalizes without introducing new shortcuts, the work could meaningfully advance reliable AI-assisted GI diagnosis by directly addressing misalignment with clinical pathways and visual biases, an important gap in current MLLM applications. The planned public release of code and datasets is a positive contribution to reproducibility.
major comments (2)
- [Counterfactual RL section] Counterfactual RL section (described in abstract and § on counterfactual RL): the theoretical analysis correctly identifies spurious convergence under standard SFT, yet the RL objective contains no explicit regularization term against mask-induced artifacts (boundary discontinuities, texture changes). This is load-bearing for the central claim that lesion masking plus rewards 'strictly' constrains the model to causal lesion features without new biases or distribution shift failures.
- [Experiments section] Experiments section: the abstract asserts SoTA results and 'significantly enhancing diagnostic accuracy' but the provided manuscript summary supplies no quantitative metrics, baselines, ablation studies, or error bars. Without these, the performance claims cannot be assessed as load-bearing evidence for the framework's superiority.
minor comments (2)
- Clarify the precise mathematical form of the clinical-cognition-centric reward function, including how hierarchical cognition levels are scored and combined.
- The abstract would benefit from one or two key quantitative results (e.g., accuracy deltas on primary benchmarks) to substantiate the SoTA claim without requiring the reader to reach the full experiments section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and will revise the manuscript accordingly to strengthen the presentation of the counterfactual RL component and the experimental evidence.
read point-by-point responses
-
Referee: [Counterfactual RL section] Counterfactual RL section (described in abstract and § on counterfactual RL): the theoretical analysis correctly identifies spurious convergence under standard SFT, yet the RL objective contains no explicit regularization term against mask-induced artifacts (boundary discontinuities, texture changes). This is load-bearing for the central claim that lesion masking plus rewards 'strictly' constrains the model to causal lesion features without new biases or distribution shift failures.
Authors: We agree that the absence of an explicit regularization term for mask-induced artifacts represents a gap in the current formulation. The theoretical analysis shows that standard SFT converges to spurious correlations, and the counterfactual masking plus cognition-centric rewards are intended to enforce causal grounding; however, without additional regularization, boundary and texture artifacts could introduce new biases. In the revised manuscript we will augment the RL objective with a regularization term that penalizes boundary discontinuities and texture inconsistencies (e.g., via perceptual loss on masked regions), thereby making the causal constraint more robust. revision: yes
-
Referee: [Experiments section] Experiments section: the abstract asserts SoTA results and 'significantly enhancing diagnostic accuracy' but the provided manuscript summary supplies no quantitative metrics, baselines, ablation studies, or error bars. Without these, the performance claims cannot be assessed as load-bearing evidence for the framework's superiority.
Authors: The full manuscript contains a dedicated Experiments section with quantitative metrics, baseline comparisons, ablation studies, and error bars across multiple benchmarks. To make these results immediately visible and to support the abstract claims, we will insert a concise results summary table (including key accuracy gains and statistical significance) into the abstract and introduction, while retaining the detailed tables and figures in the main Experiments section. revision: yes
Circularity Check
No significant circularity; derivation is self-contained training strategy
full rationale
The paper presents a two-stage approach: (1) SFT on a constructed hierarchical clinical cognition dataset to internalize diagnostic logic, and (2) counterfactual RL using lesion-masked samples plus clinical-cognition rewards to enforce causal grounding. No equations, fitted parameters, or derivations are shown that reduce the claimed SoTA performance or causal enforcement to inputs by construction. The theoretical analysis of spurious SFT convergence is described as provided within the work itself rather than imported via self-citation. The method is an independent training recipe with no load-bearing self-referential steps or renamed known results. This is the common honest non-finding for empirical training papers.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Standard supervised tuning on medical images converges to spurious background correlations
- domain assumption Hierarchical clinical cognition data can be constructed to internalize expert diagnostic logic
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2407.04106 (2024)
Alkhaldi,A.,Alnajim,R.,Alabdullatef,L.,Alyahya,R.,Chen,J.,Zhu,D.,Alsinan, A., Elhoseiny, M.: Minigpt-med: Large language model as a general interface for CogAlign 17 radiology diagnosis. arXiv preprint arXiv:2407.04106 (2024)
-
[2]
Medical image analysis91, 103000 (2024)
Azad, R., Kazerouni, A., Heidari, M., Aghdam, E.K., Molaei, A., Jia, Y., Jose, A., Roy, R., Merhof, D.: Advances in medical image analysis with vision transformers: a comprehensive review. Medical image analysis91, 103000 (2024)
work page 2024
-
[3]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Sci- entific data7(1), 283 (2020)
Borgli, H., Thambawita, V., Smedsrud, P.H., Hicks, S., Jha, D., Eskeland, S.L., Randel, K.R., Pogorelov, K., Lux, M., Nguyen, D.T.D., et al.: Hyperkvasir, a com- prehensive multi-class image and video dataset for gastrointestinal endoscopy. Sci- entific data7(1), 283 (2020)
work page 2020
-
[5]
arXiv preprint arXiv:2508.14706 (2025)
Chen, J., Cai, Z., Liu, Z., Yang, Y., Wang, R., Xiao, Q., Feng, X., Su, Z., Guo, J., Wan, X., et al.: Shizhengpt: Towards multimodal llms for traditional chinese medicine. arXiv preprint arXiv:2508.14706 (2025)
-
[6]
In: Proceedings of the 2024 conference on empirical methods in natural language processing
Chen, J., Gui, C., Ouyang, R., Gao, A., Chen, S., Chen, G.H., Wang, X., Cai, Z., Ji, K., Wan, X., et al.: Towards injecting medical visual knowledge into multimodal llms at scale. In: Proceedings of the 2024 conference on empirical methods in natural language processing. pp. 7346–7370 (2024)
work page 2024
-
[7]
arXiv preprint arXiv:2602.06965 (2026)
Deria, A., Kumar, K., Dukre, A.M., Segal, E., Khan, S., Razzak, I.: Medmo: Grounding and understanding multimodal large language model for medical im- ages. arXiv preprint arXiv:2602.06965 (2026)
-
[8]
Computerized medical imaging and graphics31(4-5), 198–211 (2007)
Doi, K.: Computer-aided diagnosis in medical imaging: historical review, current status and future potential. Computerized medical imaging and graphics31(4-5), 198–211 (2007)
work page 2007
-
[9]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[10]
In: International confer- ence on medical image computing and computer-assisted intervention
Fan, D.P., Ji, G.P., Zhou, T., Chen, G., Fu, H., Shen, J., Shao, L.: Pranet: Par- allel reverse attention network for polyp segmentation. In: International confer- ence on medical image computing and computer-assisted intervention. pp. 263–273. Springer (2020)
work page 2020
-
[11]
Google: Gemini 3 pro: the frontier of vision ai (2025),https://blog.google/ innovation-and-ai/technology/developers-tools/gemini-3-pro-vision/
work page 2025
-
[12]
Nature645(8081), 633–638 (2025)
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., et al.: Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature645(8081), 633–638 (2025)
work page 2025
-
[13]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
work page 2016
-
[14]
International Journal of Computer Assisted Radiology and Surgery 20(7), 1513–1520 (2025)
He, Q., Bano, S., Stoyanov, D., Zuo, S.: Divgi: delve into digestive endoscopy image classification. International Journal of Computer Assisted Radiology and Surgery 20(7), 1513–1520 (2025)
work page 2025
-
[15]
Computational Visual Media (2026)
Hu, B.C., Ji, G.P., Shao, D., Fan, D.P.: Pranet-v2: Dual-supervised reverse atten- tion for medical image segmentation. Computational Visual Media (2026)
work page 2026
-
[16]
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. Iclr1(2), 3 (2022)
work page 2022
-
[17]
Jha, D., Sharma, V., Dasu, N., Tomar, N.K., Hicks, S., Bhuyan, M.K., Das, P.K., Riegler, M.A., Halvorsen, P., Bagci, U., et al.: Gastrovision: A multi-class endoscopy image dataset for computer aided gastrointestinal disease detection. 18 H. Zheng et al. In: Workshop on machine learning for multimodal healthcare data. pp. 125–140. Springer (2023)
work page 2023
-
[18]
arXiv preprint arXiv:2510.08668 (2025)
Jiang, S., Wang, Y., Song, S., Hu, T., Zhou, C., Pu, B., Zhang, Y., Yang, Z., Feng, Y., Zhou, J.T., et al.: Hulu-med: A transparent generalist model towards holistic medical vision-language understanding. arXiv preprint arXiv:2510.08668 (2025)
-
[19]
World journal of gastroenterology 27(40), 6794 (2021)
Kröner, P.T., Engels, M.M., Glicksberg, B.S., Johnson, K.W., Mzaik, O., van Hooft, J.E., Wallace, M.B., El-Serag, H.B., Krittanawong, C.: Artificial intelligence in gastroenterology: A state-of-the-art review. World journal of gastroenterology 27(40), 6794 (2021)
work page 2021
-
[20]
IEEE Transactions on Medical Imaging (2026)
Lai, Y., Zhong, J., Li, M., Zhao, S., Li, Y., Psounis, K., Yang, X.: Med-r1: Rein- forcement learning for generalizable medical reasoning in vision-language models. IEEE Transactions on Medical Imaging (2026)
work page 2026
-
[21]
Advances in Neural Information Processing Systems36, 28541–28564 (2023)
Li, C., Wong, C., Zhang, S., Usuyama, N., Liu, H., Yang, J., Naumann, T., Poon, H., Gao, J.: Llava-med: Training a large language-and-vision assistant for biomedicine in one day. Advances in Neural Information Processing Systems36, 28541–28564 (2023)
work page 2023
-
[22]
arXiv preprint arXiv:2502.09838 (2025)
Lin, T., Zhang, W., Li, S., Yuan, Y., Yu, B., Li, H., He, W., Jiang, H., Li, M., Song, X., et al.: Healthgpt: A medical large vision-language model for unifying compre- hension and generation via heterogeneous knowledge adaptation. arXiv preprint arXiv:2502.09838 (2025)
-
[23]
arXiv preprint arXiv:2505.23601 (2025)
Liu, S., Zheng, B., Chen, W., Peng, Z., Yin, Z., Shao, J., Hu, J., Yuan, Y.: En- dobench: A comprehensive evaluation of multi-modal large language models for endoscopy analysis. arXiv preprint arXiv:2505.23601 (2025)
-
[24]
In: Machine learning for health (ML4H)
Moor, M., Huang, Q., Wu, S., Yasunaga, M., Dalmia, Y., Leskovec, J., Zakka, C., Reis, E.P., Rajpurkar, P.: Med-flamingo: a multimodal medical few-shot learner. In: Machine learning for health (ML4H). pp. 353–367. PMLR (2023)
work page 2023
-
[25]
Nature reviews Gastroenterology & hepatology 18(5), 314–334 (2021)
Motta, J.P., Wallace, J.L., Buret, A.G., Deraison, C., Vergnolle, N.: Gastrointesti- nal biofilms in health and disease. Nature reviews Gastroenterology & hepatology 18(5), 314–334 (2021)
work page 2021
-
[26]
arXiv preprint arXiv:2602.23363 (2026)
Mullappilly, S.S., Kurpath, M.I., Mohamed, O., Zidan, M., Khan, F., Khan, S., Anwer, R., Cholakkal, H.: Medix-r1: Open ended medical reinforcement learning. arXiv preprint arXiv:2602.23363 (2026)
-
[27]
arXiv preprint arXiv:2412.07769 (2024)
Mullappilly, S.S., Kurpath, M.I., Pieri, S., Alseiari, S.Y., Cholakkal, S., Aldahmani, K., Khan, F., Anwer, R., Khan, S., Baldwin, T., et al.: Bimedix2: Bio-medical expert lmm for diverse medical modalities. arXiv preprint arXiv:2412.07769 (2024)
-
[28]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Nath, V., Li, W., Yang, D., Myronenko, A., Zheng, M., Lu, Y., Liu, Z., Yin, H., Law, Y.M., Tang, Y., et al.: Vila-m3: Enhancing vision-language models with medical expert knowledge. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 14788–14798 (2025)
work page 2025
-
[29]
arXiv preprint arXiv:2510.15710 (2025)
Ning,J.,Li,W.,Tang,C.,Lin,J.,Ma,C.,Zhang,C.,Liu,J.,Chen,Y.,Gao,S.,Liu, L., et al.: Unimedvl: Unifying medical multimodal understanding and generation through observation-knowledge-analysis. arXiv preprint arXiv:2510.15710 (2025)
-
[30]
In: International Conference on Medi- cal Image Computing and Computer-Assisted Intervention
Pan, J., Liu, C., Wu, J., Liu, F., Zhu, J., Li, H.B., Chen, C., Ouyang, C., Rueck- ert, D.: Medvlm-r1: Incentivizing medical reasoning capability of vision-language models (vlms) via reinforcement learning. In: International Conference on Medi- cal Image Computing and Computer-Assisted Intervention. pp. 337–347. Springer (2025)
work page 2025
-
[31]
World Journal of Gastroenterology31(10), 102725 (2025) CogAlign 19
Ramoni, D., Scuricini, A., Carbone, F., Liberale, L., Montecucco, F.: Artificial in- telligence in gastroenterology: Ethical and diagnostic challenges in clinical practice. World Journal of Gastroenterology31(10), 102725 (2025) CogAlign 19
work page 2025
-
[32]
arXiv preprint arXiv:2410.21302 (2024)
Roth, M., Nowak, M.V., Krenzer, A., Puppe, F.: Domain-adaptive pre-training of self-supervised foundation models for medical image classification in gastrointesti- nal endoscopy. arXiv preprint arXiv:2410.21302 (2024)
-
[33]
Sellergren, A., Kazemzadeh, S., Jaroensri, T., Kiraly, A., Traverse, M., Kohlberger, T., Xu, S., Jamil, F., Hughes, C., Lau, C., et al.: Medgemma technical report. arXiv preprint arXiv:2507.05201 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Advances in Neural Information Processing Systems33, 9573–9585 (2020)
Shah, H., Tamuly, K., Raghunathan, A., Jain, P., Netrapalli, P.: The pitfalls of simplicity bias in neural networks. Advances in Neural Information Processing Systems33, 9573–9585 (2020)
work page 2020
-
[35]
BMC Medical Informatics and Decision Making25(1), 117 (2025)
Shool, S., Adimi, S., Saboori Amleshi, R., Bitaraf, E., Golpira, R., Tara, M.: A systematic review of large language model (llm) evaluations in clinical medicine. BMC Medical Informatics and Decision Making25(1), 117 (2025)
work page 2025
-
[36]
arXiv preprint arXiv:2511.00916 (2025)
Shu, Y., Liu, C., Chen, R., Li, D., Dai, B.: Fleming-vl: Towards universal medical visual reasoning with multimodal llms. arXiv preprint arXiv:2511.00916 (2025)
-
[37]
Scientific Data8(1), 142 (2021)
Smedsrud, P.H., Thambawita, V., Hicks, S.A., Gjestang, H., Nedrejord, O.O., Næss, E., Borgli, H., Jha, D., Berstad, T.J.D., Eskeland, S.L., et al.: Kvasir-capsule, a video capsule endoscopy dataset. Scientific Data8(1), 142 (2021)
work page 2021
-
[38]
Annals of internal medicine177(12), 1652–1663 (2024)
Soleymanjahi, S., Huebner, J., Elmansy, L., Rajashekar, N., Lüdtke, N., Paracha, R., Thompson, R., Grimshaw, A.A., Foroutan, F., Sultan, S., et al.: Artificial intelligence–assisted colonoscopy for polyp detection: a systematic review and meta-analysis. Annals of internal medicine177(12), 1652–1663 (2024)
work page 2024
-
[39]
arXiv preprint arXiv:2506.16962 (2025)
Sun, H., Jiang, Y., Lou, W., Zhang, Y., Li, W., Wang, L., Liu, M., Liu, L., Wang, X.: Chiron-o1: Igniting multimodal large language models towards gen- eralizable medical reasoning via mentor-intern collaborative search. arXiv preprint arXiv:2506.16962 (2025)
-
[40]
Nature medicine29(3), 738–747 (2023)
Thieme, A.H., Zheng, Y., Machiraju, G., Sadee, C., Mittermaier, M., Gertler, M., Salinas, J.L., Srinivasan, K., Gyawali, P., Carrillo-Perez, F., et al.: A deep-learning algorithm to classify skin lesions from mpox virus infection. Nature medicine29(3), 738–747 (2023)
work page 2023
-
[41]
Vallée, R., De Maissin, A., Coutrot, A., Mouchère, H., Bourreille, A., Normand, N.: Crohnipi: An endoscopic image database for the evaluation of automatic crohn’s disease lesionsrecognition algorithms.In: MedicalImaging 2020:Biomedical Appli- cations in Molecular, Structural, and Functional Imaging. vol. 11317, pp. 440–446. SPIE (2020)
work page 2020
-
[42]
Advances in neural information pro- cessing systems30(2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017)
work page 2017
-
[43]
Wang, W., Ma, Z., Wang, Z., Wu, C., Ji, J., Chen, W., Li, X., Yuan, Y.: A survey of llm-based agents in medicine: How far are we from baymax? Findings of the Association for Computational Linguistics: ACL 2025 pp. 10345–10359 (2025)
work page 2025
- [44]
-
[45]
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Xu, W., Chan, H.P., Li, L., Aljunied, M., Yuan, R., Wang, J., Xiao, C., Chen, G., Liu,C.,Li,Z.,etal.:Lingshu:Ageneralistfoundationmodelforunifiedmultimodal medical understanding and reasoning. arXiv preprint arXiv:2506.07044 (2025)
work page internal anchor Pith review arXiv 2025
-
[46]
Expert Systems with Applications138, 112821 (2019)
Yanase, J., Triantaphyllou, E.: A systematic survey of computer-aided diagnosis in medicine: Past and present developments. Expert Systems with Applications138, 112821 (2019)
work page 2019
-
[47]
Yokote, A., Umeno, J., Kawasaki, K., Fujioka, S., Fuyuno, Y., Matsuno, Y., Yoshida, Y., Imazu, N., Miyazono, S., Moriyama, T., et al.: Small bowel capsule 20 H. Zheng et al. endoscopy examination and open access database with artificial intelligence: the see-artificial intelligence project. DEN open4(1), e258 (2024)
work page 2024
-
[48]
Nature medicine30(11), 3129–3141 (2024)
Zhang, K., Zhou, R., Adhikarla, E., Yan, Z., Liu, Y., Yu, J., Liu, Z., Chen, X., Davison, B.D., Ren, H., et al.: A generalist vision–language foundation model for diverse biomedical tasks. Nature medicine30(11), 3129–3141 (2024)
work page 2024
- [49]
-
[50]
Zhou, Y., Song, L., Shen, J.: Improving medical large vision-language models with abnormal-aware feedback. In: Proceedings of the 63rd Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: Long Papers). pp. 12994–13011 (2025)
work page 2025
-
[51]
In: Findings of the Association for Computational Linguistics: ACL 2025
Zhou,Y.,Song,L.,Shen,J.:Mam:Modularmulti-agentframeworkformulti-modal medical diagnosis via role-specialized collaboration. In: Findings of the Association for Computational Linguistics: ACL 2025. pp. 25319–25333 (2025)
work page 2025
-
[52]
Zhou, Y., Zheng, H., Chen, D., Yang, H., Han, W., Shen, J.: From medical llms to versatile medical agents: A comprehensive survey. intelligence10, 11 (2025)
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.