Recognition: 2 theorem links
· Lean TheoremROBOGATE: Adaptive Failure Discovery for Safe Robot Policy Deployment via Two-Stage Boundary-Focused Sampling
Pith reviewed 2026-05-15 00:28 UTC · model grok-4.3
The pith
ROBOGATE uses two-stage sampling to identify closed-form failure boundaries for robot policies in simulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
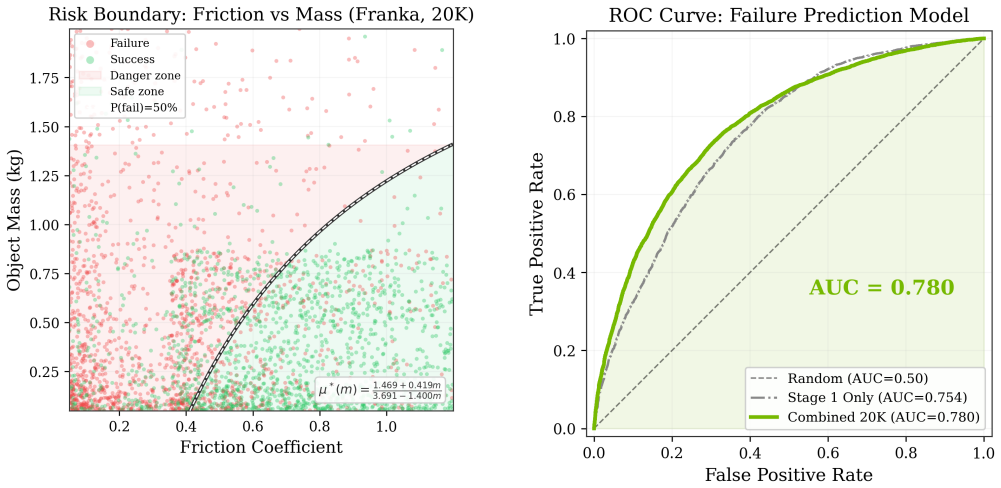
ROBOGATE combines Latin Hypercube Sampling across an 8-dimensional parameter space with boundary-focused sampling in the success rate transition zone to evaluate robot policies in NVIDIA Isaac Sim. A logistic regression model trained on over 50,000 experiments achieves an AUC of 0.780 and yields a closed-form equation for the failure boundary. Benchmarking shows that a VLA policy fine-tuned on LIBERO achieves 97.65% success there but 0% on the 68 industrial scenarios tested here, demonstrating a large cross-simulator performance gap.
What carries the argument
The two-stage boundary-focused sampling strategy paired with logistic regression to model risk and derive a closed-form failure boundary equation.
If this is right
- Robot policies can be pre-validated against identified failure boundaries before deployment.
- The closed-form equation allows quick prediction of failure risk for new parameter combinations.
- Large gaps between simulators indicate that single-simulator benchmarks are insufficient for safe deployment.
- Validation layers similar to those in quantum computing can be applied to physical AI systems.
Where Pith is reading between the lines
- Applying this sampling to real-world robot tests could validate the simulation's accuracy for industrial use.
- This approach might generalize to other high-dimensional control problems like autonomous vehicles or drone navigation.
- Future work could integrate the risk model directly into policy training to avoid high-risk regions.
- The method suggests rethinking benchmark suites to include industrial scenario diversity.
Load-bearing premise
The Newtonian physics in NVIDIA Isaac Sim accurately represent the dynamics and failure modes that would occur with real robots in industrial settings.
What would settle it
Running the same policies on physical robot hardware and observing whether the predicted failure boundary from the model matches the actual success rates.
Figures


read the original abstract
Deploying learned robot manipulation policies in industrial settings requires rigorous pre-deployment validation, yet exhaustive testing across high-dimensional parameter spaces is intractable. We present ROBOGATE, a deployment risk management framework that combines physics-based simulation with a two-stage adaptive sampling strategy to efficiently discover failure boundaries in the operational parameter space. Stage 1 employs Latin Hypercube Sampling (LHS) across an 8-dimensional parameter space; Stage 2 applies boundary-focused sampling concentrated in the 30-70% success rate transition zone. Using NVIDIA Isaac Sim with Newton physics, we evaluate a scripted pick-and-place controller across four robot embodiments -- Franka Panda (7-DOF), UR3e (6-DOF), UR5e (6-DOF), and UR10e (6-DOF) -- totaling over 50,000 experiments. Our logistic regression risk model achieves AUC 0.780 and identifies a closed-form failure boundary equation. We further benchmark eight VLA (Vision-Language-Action) policies, including a fine-tuned NVIDIA GR00T N1.6 (3B) trained on LIBERO-Spatial for 20K steps. The same checkpoint achieves 97.65% success rate on LIBERO (MuJoCo) but 0% on RoboGate's 68 industrial scenarios in NVIDIA Isaac Sim -- a 97.65 percentage point cross-simulator gap on a single model that underscores the deployment validation challenge. Inspired by the validation-layer paradigm NVIDIA codified for quantum computing with Ising, ROBOGATE provides this validation layer for Physical AI. Open-source.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ROBOGATE, a two-stage adaptive sampling framework for discovering failure boundaries of robot manipulation policies in high-dimensional parameter spaces. Stage 1 applies Latin Hypercube Sampling across an 8D space; Stage 2 concentrates samples in the 30-70% success-rate transition zone. Using NVIDIA Isaac Sim with Newton physics, the authors run over 50,000 trials on four simulated embodiments (Franka Panda, UR3e, UR5e, UR10e) with a scripted pick-and-place controller, fit a logistic regression risk model (AUC 0.780), and extract a closed-form failure boundary equation. They further benchmark eight VLA policies, including a GR00T N1.6 checkpoint that achieves 97.65% success on LIBERO (MuJoCo) but 0% on 68 Isaac Sim scenarios, and position the method as a validation layer for Physical AI. The code is open-sourced.
Significance. If the reported AUC, boundary equation, and cross-simulator gap hold under scrutiny, the work supplies a concrete, scalable procedure for locating policy failure regions without exhaustive enumeration, directly addressing a practical bottleneck in industrial robot deployment. The scale of the experiment (>50k trials) and the explicit demonstration of a 97.65-point performance drop between two widely used simulators provide empirical evidence that pre-deployment validation must be simulator-aware. The open-source release further increases potential utility for the robotics safety community.
major comments (2)
- [Abstract] Abstract: the closed-form failure boundary equation is asserted as an output of the logistic regression but neither the explicit equation nor any derivation steps (e.g., how the 30-70% transition zone maps to the final analytic form) are supplied; this is load-bearing for the central claim that the method yields a usable pre-deployment validator.
- [Experimental results] Experimental results (implicitly §4–5): all 50,000+ trials, logistic model fitting, and boundary identification are performed exclusively inside NVIDIA Isaac Sim with Newton physics on four simulated arms; no physical-robot experiments are reported. Because the title and abstract frame the contribution as enabling “safe robot policy deployment,” the absence of hardware validation leaves the transferability of the identified boundary untested, especially for contact-rich pick-and-place tasks where friction and compliance gaps are well-documented.
minor comments (2)
- [Abstract] Abstract: AUC 0.780, success rates, and the 97.65% gap are reported without error bars, confidence intervals, or explicit statements of the number of trials per scenario and any data-exclusion criteria.
- [Results] The manuscript would benefit from an explicit equation block or table that lists the fitted logistic coefficients and the resulting closed-form boundary expression once the derivation is added.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and experimental framing. We address each major comment below and outline the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the closed-form failure boundary equation is asserted as an output of the logistic regression but neither the explicit equation nor any derivation steps (e.g., how the 30-70% transition zone maps to the final analytic form) are supplied; this is load-bearing for the central claim that the method yields a usable pre-deployment validator.
Authors: We agree that the explicit equation and derivation are necessary to substantiate the central claim. In the revised manuscript we will add the closed-form failure boundary equation (derived from the logistic regression coefficients) to both the abstract and the methods section, together with a concise derivation showing how the 30-70% success-rate transition zone is used to fit the model and extract the analytic boundary. revision: yes
-
Referee: [Experimental results] Experimental results (implicitly §4–5): all 50,000+ trials, logistic model fitting, and boundary identification are performed exclusively inside NVIDIA Isaac Sim with Newton physics on four simulated arms; no physical-robot experiments are reported. Because the title and abstract frame the contribution as enabling “safe robot policy deployment,” the absence of hardware validation leaves the transferability of the identified boundary untested, especially for contact-rich pick-and-place tasks where friction and compliance gaps are well-documented.
Authors: We acknowledge that all reported experiments are simulation-based. ROBOGATE is presented as a scalable simulation-layer validation tool that identifies failure boundaries prior to hardware deployment. In the revision we will expand the discussion section to explicitly address sim-to-real transfer limitations for contact-rich tasks (including friction and compliance gaps) and add a forward-looking subsection on planned physical-robot validation. No new hardware experiments will be added in this revision, as they require a separate experimental campaign. revision: partial
Circularity Check
No significant circularity; derivation is self-contained statistical fitting
full rationale
The paper generates over 50,000 simulation trials via two-stage sampling (LHS followed by boundary-focused sampling in the 30-70% transition zone), fits a logistic regression risk model to these outcomes, reports AUC 0.780 on the data, and extracts a closed-form failure boundary by solving the fitted logistic equation for p=0.5. This is a standard empirical modeling pipeline with no equations reducing the reported boundary or AUC directly to fitted constants by construction, no self-citations invoked as load-bearing uniqueness theorems, and no ansatzes smuggled in. The boundary equation is a direct algebraic consequence of the fitted coefficients rather than a renaming or redefinition of the raw inputs. The derivation chain remains independent of the target claims and does not collapse to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption NVIDIA Isaac Sim with Newton physics accurately models the dynamics needed to expose policy failures in industrial pick-and-place tasks
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
logistic regression risk model achieves AUC 0.780 and identifies a closed-form failure boundary equation µ∗(m) = (1.469 + 0.419m)/(3.691−1.400m)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-stage adaptive sampling strategy... Stage 1 employs Latin Hypercube Sampling (LHS) across an 8-dimensional parameter space; Stage 2 applies boundary-focused sampling
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Octo: An open-source generalist robot policy
Octo Model Team. Octo: An open-source generalist robot policy. InRSS, 2024
2024
-
[2]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Bal- akrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. San- keti, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, 12 D. Sadigh, S. Levine, P. Liang, and C. Finn. Open- VLA: An open-source vision-language-action model. arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, et al.RT-2: Vision-language-action models transfer web knowledge to robotic control. InCoRL, 2023
2023
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter,et al.π 0: A vision-language-action flow model for general robot control.arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burch- fiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InRSS, 2023
2023
-
[6]
James, Z
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison. RL- Bench: The robot learning benchmark and learning en- vironment.IEEE RA-L, 5(2):3019–3026, 2020
2020
-
[7]
T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine. Meta-World: A benchmark and evaluation for multi-task and meta reinforcement learn- ing. InCoRL, 2020
2020
-
[8]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning. InNeurIPS, 2024
2024
-
[9]
Tobin, R
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. InIROS, 2017
2017
-
[10]
arXiv preprint arXiv:1910.07113 , year=
OpenAI, I. Akkaya, M. Andrychowicz, M. Chociej, M. Litwin, B. McGrew, A. Petron, A. Paino, M. Plap- pert, G. Powell, R. Ribas,et al.Solving Rubik’s Cube with a robot hand.arXiv:1910.07113, 2019
-
[11]
Muratore, M
F. Muratore, M. Gienger, and J. Peters. Robot learning from randomized simulations: A review.Frontiers in Robotics and AI, 9:799893, 2022
2022
-
[12]
Koren, S
M. Koren, S. Alsaif, R. Lee, and M. J. Kochenderfer. Adaptive stress testing for autonomous vehicles. InIV, 2018
2018
-
[13]
Dreossi, D
T. Dreossi, D. J. Fremont, S. Ghosh, E. Kim, H. Ravan- bakhsh, M. Vázquez-Chanlatte, and S. A. Seshia. Veri- fAI: A toolkit for the formal design and analysis of arti- ficial intelligence-based systems. InCAV, 2019
2019
-
[14]
Chaloner and I
K. Chaloner and I. Verdinelli. Bayesian experimental design: A review.Statistical Science, 10(3):273–304, 1995
1995
-
[15]
ISO 10218-1:2011 Robots and robotic devices— Safety requirements for industrial robots—Part 1: Robots
ISO. ISO 10218-1:2011 Robots and robotic devices— Safety requirements for industrial robots—Part 1: Robots. International Organization for Standardization, 2011
2011
-
[16]
ISO/TS 15066:2016 Robots and robotic devices— Collaborative robots
ISO. ISO/TS 15066:2016 Robots and robotic devices— Collaborative robots. International Organization for Standardization, 2016
2016
-
[17]
Concrete Problems in AI Safety
D. Amodei, C. Olah, J. Steinhardt, P. Christiano, J. Schulman, and D. Mané. Concrete problems in AI safety.arXiv:1606.06565, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[18]
W. Xu, Y . Chen, D. Held, and Z. Xu. SafeBench: A benchmarking platform for safety evaluation of au- tonomous vehicles. InNeurIPS Datasets and Bench- marks, 2022
2022
-
[19]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu. RoboCasa: Large- scale simulation of everyday tasks for generalist robots. arXiv:2406.02523, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
NVIDIA Launches Ising, the World’s First Open AI Models to Accelerate the Path to Useful Quantum Computers
NVIDIA Corporation. NVIDIA Launches Ising, the World’s First Open AI Models to Accelerate the Path to Useful Quantum Computers. Press release, April 14, 2026. https://nvidianews.nvidia.com/news/ nvidia-launches-ising-the-worlds-first-open-ai-models-to-accelerate-the-path-to-useful-quantum-computers
2026
-
[21]
GR00T N1.6: A generalist robot foundation model.https://huggingface.co/ nvidia/GR00T-N1.6-3B, 2025
NVIDIA Corporation. GR00T N1.6: A generalist robot foundation model.https://huggingface.co/ nvidia/GR00T-N1.6-3B, 2025
2025
-
[22]
SmolVLA: A small vision-language- action model.https://huggingface.co/ HuggingFaceTB/SmolVLA-Base, 2025
HuggingFace. SmolVLA: A small vision-language- action model.https://huggingface.co/ HuggingFaceTB/SmolVLA-Base, 2025
2025
- [23]
-
[24]
Y . Fei, X. Wang, L. Shi, et al. LIBERO-Plus: Evaluating VLA robustness across seven dimensions.https:// arxiv.org/abs/2510.13626, October 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
J. Choi, K. Lee, J. Park, J. Kim, R. Krishna, D. Fox, T. Yu. vla-eval: A unified evaluation harness for vision-language-action models.https://arxiv. org/abs/2603.13966, March 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [26]
-
[27]
Robomind: Benchmark on multi-embodiment intelligence normative data for robot manipulation,
RoboMIND Authors. RoboMIND: A multi- embodiment dataset with cross-robot failure demonstra- tions.https://arxiv.org/abs/2412.13877, December 2024
- [28]
-
[29]
Robotarena ∞: Scalable robot benchmarking via real-to-sim translation, 2025
A. Jangir, X. Zhang, et al. RobotArena∞: Real- to-sim translation for scalable benchmarking of robot policies. ICLR 2026.https://arxiv.org/abs/ 2510.23571
-
[30]
Zhu, et al
Y . Zhu, et al. RoboCasa365: Scaling simula- tion environments for household robotics. ICLR 2026.https://robocasa.ai/assets/ robocasa365_iclr26.pdf. A Failure Dictionary Schema Each experiment in the failure dictionary contains 26 fields (Franka) or 10 fields (UR5e). Table 12 documents the full Franka schema. Table 12: Franka failure dictionary schema (26...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.