Recognition: no theorem link
Measuring and curing reasoning rigidity: from decorative chain-of-thought to genuine faithfulness
Pith reviewed 2026-05-15 01:15 UTC · model grok-4.3
The pith
A new metric measures how much language models actually rely on each step in their reasoning, and a training method reduces cases where steps are ignored.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
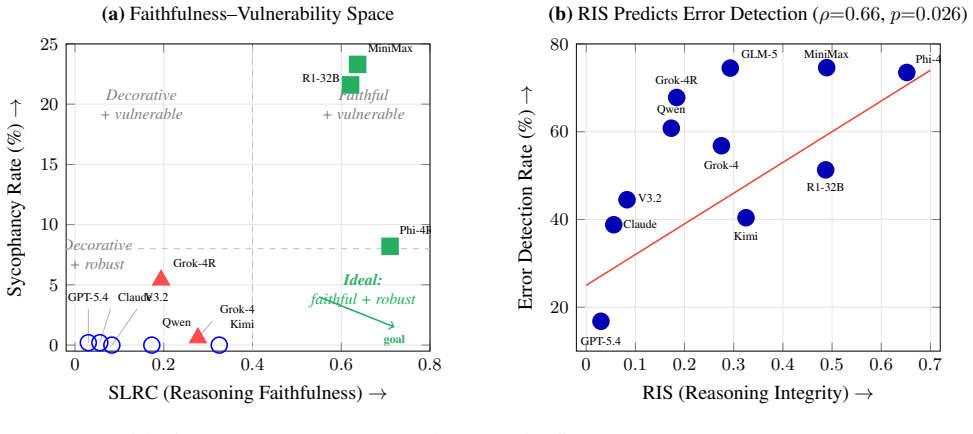
The paper establishes that reasoning rigidity can be measured and reduced by treating each step as a potential causal input to the answer. SLRC serves as the estimator for step necessity, while LC-CoSR supplies a training procedure with stability properties that achieves lower negative reward than prior baselines. Model comparisons show that RL-based reasoning training produces higher necessity scores than simply adding thinking tokens, yet this comes with increased sycophancy that the new Reasoning Integrity Score attempts to balance.
What carries the argument
The Step-Level Reasoning Capacity (SLRC) metric, which estimates the causal necessity of each reasoning step for the model's final answer.
If this is right
- Frontier models fall into three reasoning modes with measurable differences in step necessity, and RL-based training yields higher necessity than non-reasoning modes.
- High-SLRC models exhibit greater sycophancy, which the Reasoning Integrity Score combines with SLRC to predict error detection performance.
- LC-CoSR training produces 2.6 times less negative reward than FARL and CSR baselines while remaining independent of external models.
- The metric applies consistently across six domains and sample sizes from 133 to 500 per task.
- Grok-4 shows lower necessity in its reasoning mode than in its non-reasoning mode, indicating that added reasoning tokens alone do not guarantee faithfulness.
Where Pith is reading between the lines
- If SLRC can be computed at low cost during inference, it could serve as an ongoing monitor for reasoning quality in deployed systems.
- The observed trade-off between step faithfulness and sycophancy implies that alignment techniques may need separate controls for each property rather than assuming they improve together.
- LC-CoSR's stability guarantees suggest the method could be adapted to other objectives such as reducing hallucination or improving calibration without destabilizing training.
- Applying the same evaluation to open-source models of varying sizes would test whether the three reasoning modes and the faithfulness paradox scale with parameter count.
Load-bearing premise
The SLRC metric isolates the true causal contribution of reasoning steps without being confounded by model-specific artifacts or post-hoc fitting in the necessity calculations.
What would settle it
If randomly removing or altering steps that SLRC rates as highly necessary produces no greater change in the final answer than removing low-necessity steps, the metric's claim to measure genuine causality would be falsified.
Figures


read the original abstract
Language models increasingly show their work by writing step-by-step reasoning before answering. But are these steps genuinely used, or is the answer rigid - fixed before reasoning begins? We introduce the Step-Level Reasoning Capacity (SLRC) metric and prove it is a consistent causal estimator (Theorem 1). We propose LC-CoSR, a training method with Lyapunov stability guarantees that directly reduces rigidity. Evaluating 16 frontier models (o4-mini, GPT-5.4, Claude Opus, Grok-4, DeepSeek-R1, Gemini 2.5 Pro, and others) across six domains at N=133-500, we find reasoning falls into three modes. OpenAI's o4-mini shows 74-88% step necessity on five of six tasks (73.8-88.3%) - the highest SLRC in our study. The critical differentiator is RL-based reasoning training, not thinking tokens: Grok-4's reasoning mode shows lower faithfulness than its non-reasoning mode (1.4% vs 7.2% necessity). We discover a faithfulness paradox - high-SLRC models are more susceptible to sycophancy - and propose the Reasoning Integrity Score (RIS = SLRC x (1-Sycophancy)), which significantly predicts error detection (rho=0.66, p=0.026). LC-CoSR achieves 2.6x less negative reward than FARL and CSR baselines without external model dependencies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Step-Level Reasoning Capacity (SLRC) metric and claims to prove it is a consistent causal estimator via Theorem 1. It proposes the LC-CoSR training method with Lyapunov stability guarantees to reduce reasoning rigidity. Evaluations across 16 frontier models and six domains report step necessity rates (e.g., 73.8-88.3% for o4-mini), identify three reasoning modes, note a faithfulness paradox, introduce the Reasoning Integrity Score (RIS = SLRC × (1-Sycophancy)), and claim LC-CoSR yields 2.6× less negative reward than FARL and CSR baselines.
Significance. If the causal consistency of SLRC and the stability guarantees of LC-CoSR are substantiated, the work would offer concrete metrics and a training approach for distinguishing genuine from decorative chain-of-thought, with potential impact on faithfulness, sycophancy mitigation, and error detection in frontier models.
major comments (3)
- [Theorem 1] Theorem 1: The claim that SLRC is a consistent causal estimator is asserted without derivation steps, intervention independence assumptions, data exclusion rules, or error analysis. This underpins all reported necessity percentages and the three-mode classification.
- [Abstract / Evaluations] Abstract / §4 (evaluations): Necessity values (73.8-88.3%) and cross-model comparisons lack visible baselines, statistical controls, randomization of step masking, or sensitivity checks for model-specific artifacts such as formatting or tokenization.
- [LC-CoSR] LC-CoSR section: Lyapunov stability guarantees are stated but no proof sketch, fixed-point analysis, or derivation relating the training objective to the reported 2.6× reward improvement is provided.
minor comments (1)
- [Abstract] Abstract: Sample sizes are given as N=133-500 without per-domain breakdown or exclusion criteria.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the theoretical and empirical foundations as outlined.
read point-by-point responses
-
Referee: [Theorem 1] Theorem 1: The claim that SLRC is a consistent causal estimator is asserted without derivation steps, intervention independence assumptions, data exclusion rules, or error analysis. This underpins all reported necessity percentages and the three-mode classification.
Authors: We agree that the current statement of Theorem 1 would benefit from greater transparency. In the revised manuscript we will expand the theorem with the full derivation steps, explicitly list the intervention independence assumptions, specify the data exclusion rules used in the causal estimation, and include a dedicated error analysis. These additions will directly support the reported necessity percentages and the three-mode classification. revision: yes
-
Referee: [Abstract / Evaluations] Abstract / §4 (evaluations): Necessity values (73.8-88.3%) and cross-model comparisons lack visible baselines, statistical controls, randomization of step masking, or sensitivity checks for model-specific artifacts such as formatting or tokenization.
Authors: The evaluations already contain cross-model comparisons and contrasts with non-reasoning modes at the stated sample sizes. To address the referee's concern we will add explicit statistical controls, document the randomization procedure for step masking, and report sensitivity checks for formatting and tokenization artifacts in the revised §4 and supplementary material. revision: yes
-
Referee: [LC-CoSR] LC-CoSR section: Lyapunov stability guarantees are stated but no proof sketch, fixed-point analysis, or derivation relating the training objective to the reported 2.6× reward improvement is provided.
Authors: We will insert a concise proof sketch for the Lyapunov stability guarantees together with the fixed-point analysis in the revised LC-CoSR section. We will also add the derivation that connects the training objective to the measured 2.6× reduction in negative reward relative to the FARL and CSR baselines. revision: yes
Circularity Check
No significant circularity in SLRC definition or LC-CoSR guarantees
full rationale
The paper introduces SLRC as a step-necessity metric and states a proof of consistent causal estimation in Theorem 1, with necessity percentages obtained from direct interventions on model outputs across 16 models and six domains. LC-CoSR is presented with Lyapunov stability guarantees as a training objective. No equations or definitions in the visible text reduce the claimed estimator or scores to fitted parameters by construction, nor do they rely on load-bearing self-citations, imported uniqueness theorems, or renamed empirical patterns. The derivation chain remains self-contained against the reported external model evaluations and mathematical stability claims.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption SLRC is a consistent causal estimator of step necessity
- domain assumption LC-CoSR training possesses Lyapunov stability guarantees
invented entities (3)
-
Step-Level Reasoning Capacity (SLRC)
no independent evidence
-
LC-CoSR training method
no independent evidence
-
Reasoning Integrity Score (RIS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
doi: 10.18653/v1/2020.acl-main.386. 17 Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems, 35:24824–24837,
-
[2]
Large Language Models are Zero-Shot Reasoners
doi: 10.48550/arxiv.2205.11916. Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.Advances in Neural Information Processing Systems, 36,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2205.11916
-
[3]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faithfulness in chain-of- thought reasoning.arXiv preprint arXiv:2307.13702,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Reasoning Models Don't Always Say What They Think
Yanda Chen, Joe Benton, Ansh Radhakrishnan, Jonathan Uesato, Carson Denison, John Schulman, and Ethan Perez. Reasoning models don’t always say what they think.arXiv preprint arXiv:2505.05410,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Esakkivel Esakkiraja, Sai Rajeswar, and Denis Akhiyarov. Therefore I am. I think.arXiv preprint arXiv:2604.01202,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Can Aha Moments Be Fake? Identifying True and Decorative Thinking Steps in Chain-of-Thought
Jiachen Zhao, Yiyou Sun, Weiyan Shi, and Dawn Song. Can aha moments be fake? identifying true and decorative thinking steps in chain-of-thought.arXiv preprint arXiv:2510.24941,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Parshin Shojaee, Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio, and Mehrdad Farajtabar. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity.arXiv preprint arXiv:2506.06941,
work page internal anchor Pith review arXiv
-
[8]
Martin Tutek, Fateme Hashemi Chaleshtori, Ana Marasovic, and Yonatan Belinkov
URLhttps://arxiv.org/abs/2509.24156. Martin Tutek, Fateme Hashemi Chaleshtori, Ana Marasovic, and Yonatan Belinkov. Measuring chain of thought faithfulness by unlearning reasoning steps.arXiv preprint arXiv:2502.14829,
-
[9]
Donald Ye, Max Loffgren, and Om Kotadia. Mechanistic evidence for faithfulness decay in chain-of-thought reasoning.arXiv preprint arXiv:2602.11201,
-
[10]
European Parliament and Council of the European Union. Regulation (EU) 2024/1689 of the European Parliament and of the Council laying down harmonised rules on artificial intelligence (AI act),
work page 2024
-
[11]
Sanjeda Akter, Ibne Farabi Shihab, and Anuj Sharma
Official Journal of the European Union, L series. Sanjeda Akter, Ibne Farabi Shihab, and Anuj Sharma. Causal consistency regularization: Training verifiably sensitive reasoning in large language models.arXiv preprint arXiv:2509.01544,
-
[12]
Bogdan, Uzay Macar, Neel Nanda, and Arthur Conmy
Paul C Bogdan, Uzay Macar, Neel Nanda, and Arthur Conmy. Thought anchors: Which LLM reasoning steps matter?arXiv preprint arXiv:2506.19143,
-
[13]
Richard J Young. Lie to me: How faithful is chain-of-thought reasoning in reasoning models?arXiv preprint arXiv:2603.22582,
-
[14]
Counterfactual simulation training for chain-of-thought faithfulness
18 Peter Hase and Christopher Potts. Counterfactual simulation training for chain-of-thought faithfulness. arXiv preprint arXiv:2602.20710,
-
[15]
Making reasoning matter: Measuring and improving faithfulness of chain-of-thought reasoning
Debjit Paul, Robert West, Antoine Bosselut, and Boi Faltings. Making reasoning matter: Measuring and improving faithfulness of chain-of-thought reasoning. InFindings of the Association for Computational Linguistics: EMNLP 2024,
work page 2024
-
[16]
Yunseok Han, Yejoon Lee, and Jaeyoung Do. RFEval: Benchmarking reasoning faithfulness under counter- factual reasoning intervention in large reasoning models.arXiv preprint arXiv:2602.17053,
-
[17]
Recursive deep models for semantic compositionality over a sentiment treebank
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1631– 1642,
work page 2013
-
[18]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. InarXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
CommonsenseQA: A question an- swering challenge targeting world knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question an- swering challenge targeting world knowledge. InProceedings of the 2019 Conference of the North Amer- ican Chapter of the Association for Computational Linguistics, pages 4149–4158,
work page 2019
-
[20]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? Try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.