Why AI-Generated Text Detection Fails: Evidence from Explainable AI Beyond Benchmark Accuracy
Pith reviewed 2026-05-15 00:45 UTC · model grok-4.3
The pith
AI text detectors achieve high benchmark scores but fail to generalize across domains and generators
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
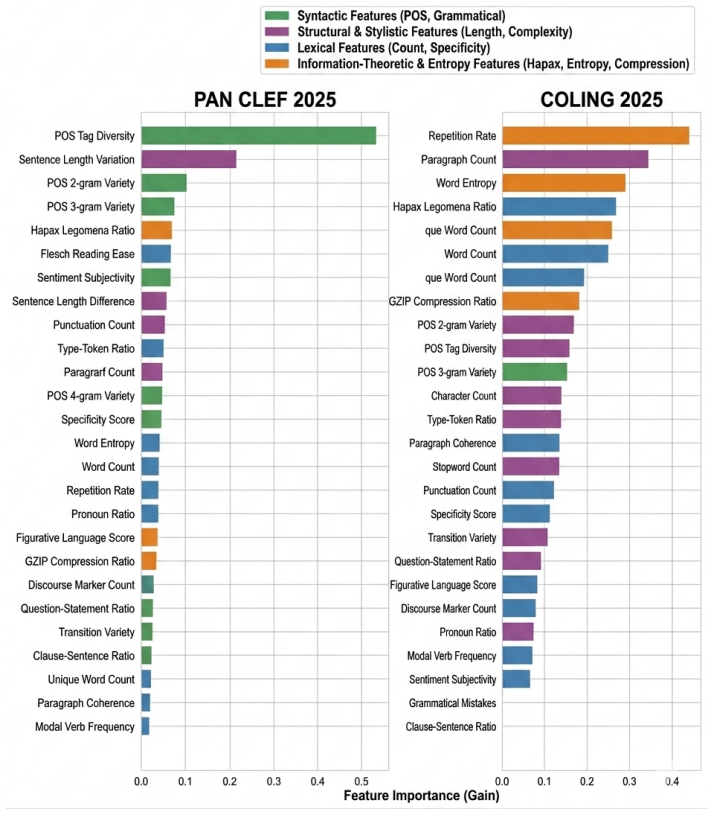
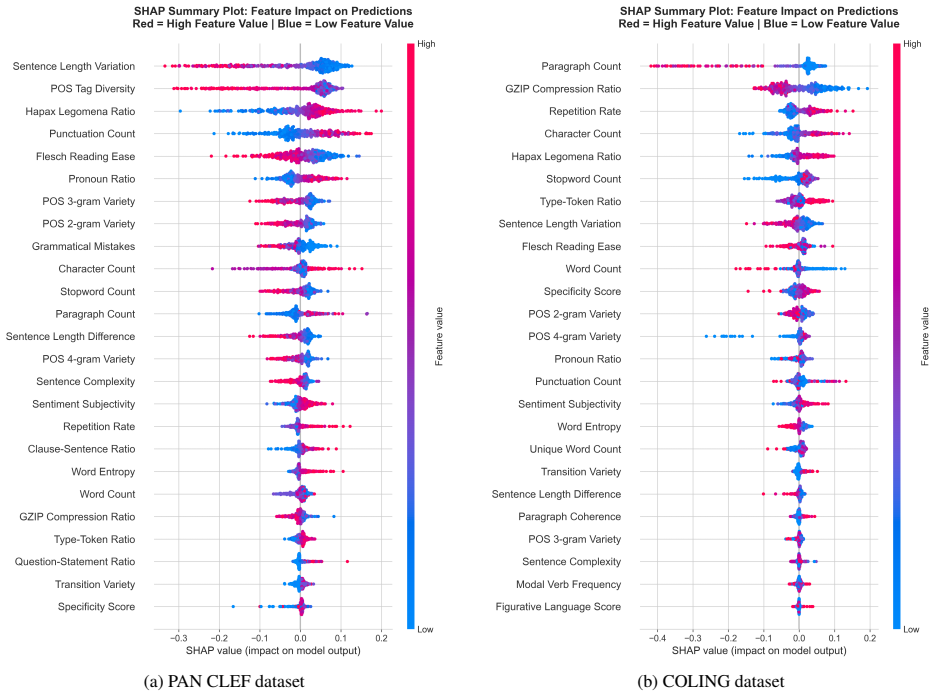
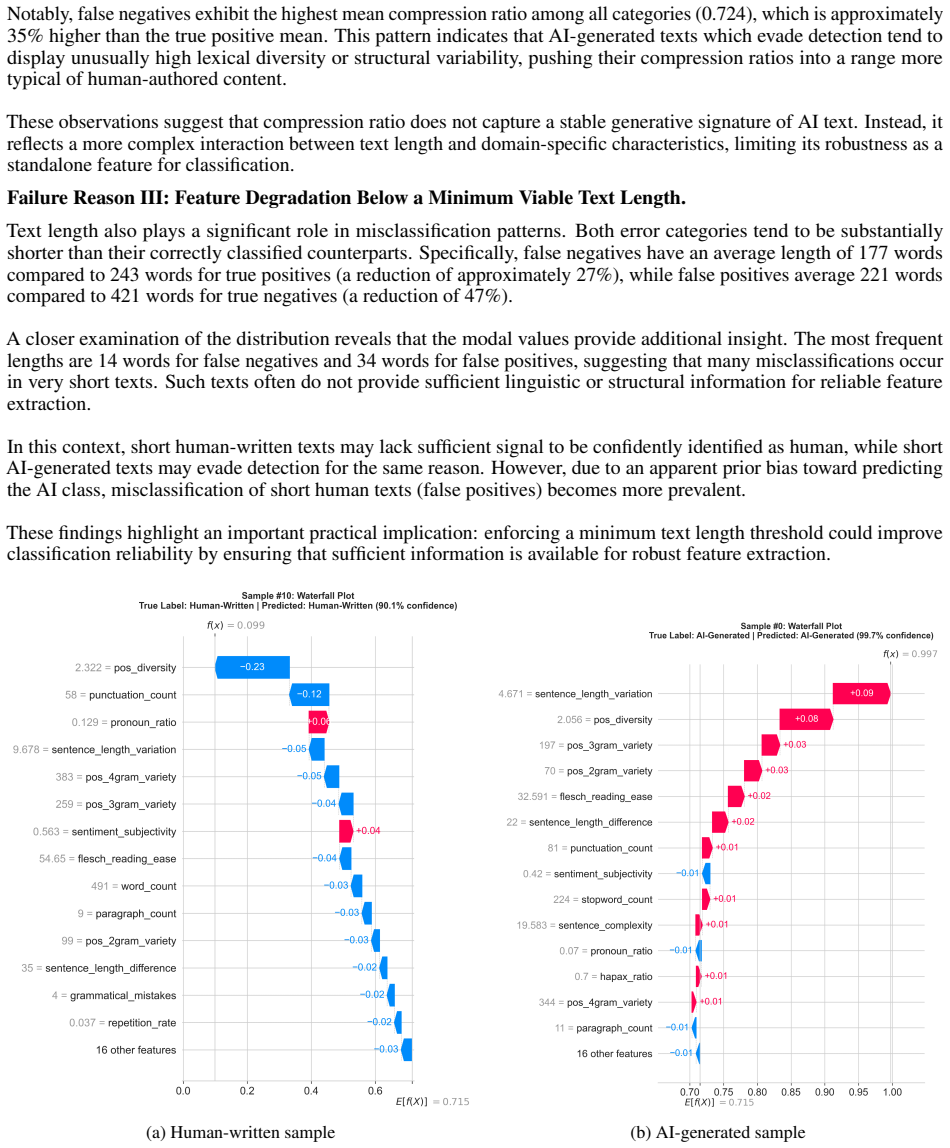
Contemporary AI text detectors do not identify stable signals of machine authorship. Instead, they rely on dataset-specific stylistic cues. This is evidenced by high in-domain performance on the PAN CLEF 2025 and COLING 2025 corpora that collapses under cross-domain and cross-generator evaluation. SHAP explanations confirm that the most influential features change markedly across datasets, and error analysis shows that the features most useful in training are also the most vulnerable to shifts in domain, formatting, and text length.
What carries the argument
Linguistic features combined with SHAP-based explanations to reveal varying feature importance across different datasets and generators
If this is right
- Classifiers with high in-domain accuracy will degrade significantly under distribution shift to new domains or generators.
- The most influential features identified by SHAP differ between datasets, pointing to reliance on stylistic artifacts.
- The features most discriminative in training data are the ones most susceptible to domain shift and other variations.
- Robust detectors require signals that remain stable across settings rather than in-domain discriminators.
Where Pith is reading between the lines
- Detectors could be improved by selecting or engineering features that are invariant to domain and length variations.
- Current benchmark evaluations may overestimate real-world reliability of AI text detectors.
- Instance-level explanations could be used to debug and refine detectors for better generalization.
- Similar generalization failures may occur in other NLP tasks that rely on stylistic or surface-level features.
Load-bearing premise
That the 30 linguistic features and the two benchmark corpora capture the key distribution shifts and that SHAP values correctly identify reliance on artifacts rather than true authorship signals.
What would settle it
A detector that maintains high accuracy on texts from new, unseen domains and generators while showing consistent feature importance rankings across all test sets would contradict the generalization failure claim.
Figures




read the original abstract
The widespread adoption of Large Language Models (LLMs) has made the detection of AI-Generated text a pressing and complex challenge. Although many detection systems report high benchmark accuracy, their reliability in real-world settings remains uncertain, and their interpretability is often unexplored. In this work, we investigate whether contemporary detectors genuinely identify machine authorship or merely exploit dataset-specific artefacts. We propose an interpretable detection framework that integrates linguistic feature engineering, machine learning, and explainable AI techniques. When evaluated on two prominent benchmark corpora, namely PAN CLEF 2025 and COLING 2025, our model trained on 30 linguistic features achieves leaderboard-competitive performance, attaining an F1 score of 0.9734. However, systematic cross-domain and cross-generator evaluation reveals substantial generalisation failure: classifiers that excel in-domain degrade significantly under distribution shift. Using SHAP- based explanations, we show that the most influential features differ markedly between datasets, indicating that detectors often rely on dataset-specific stylistic cues rather than stable signals of machine authorship. Further investigation with in-depth error analysis exposes a fundamental tension in linguistic-feature-based AI text detection: the features that are most discriminative on in-domain data are also the features most susceptible to domain shift, formatting variation, and text-length effects. We believe that this knowledge helps build AI detectors that are robust across different settings. To support replication and practical use, we release an open-source Python package that returns both predictions and instance-level explanations for individual texts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that AI-generated text detectors achieving high in-domain accuracy (F1=0.9734 using a 30-feature linguistic model on PAN CLEF 2025 and COLING 2025) fail to generalize, as shown by substantial degradation under cross-domain and cross-generator shifts; SHAP attributions indicate reliance on dataset-specific stylistic cues rather than stable authorship signals, with an accompanying open-source package for predictions and explanations.
Significance. If the core results hold, the work provides concrete evidence via cross-domain tests and post-hoc explanations that benchmark success does not imply robustness, highlighting a practical barrier to reliable deployment. The combination of linguistic feature analysis, SHAP, and error analysis offers actionable diagnostics for improving detectors, and the released package supports replication.
major comments (3)
- [Abstract and Experiments] Abstract and Experiments section: The central claim addresses 'contemporary detectors' broadly, yet all reported results (in-domain F1, cross-domain degradation, and SHAP feature rankings) are obtained exclusively from a 30-feature hand-crafted linguistic model. No evaluation is provided on prevalent transformer-based detectors (e.g., fine-tuned RoBERTa or DeBERTa), leaving open whether the observed artifact reliance and generalization failure are properties of shallow feature sets or of machine-authorship detection in general.
- [Cross-domain evaluation] Cross-domain evaluation (implied §4–5): The reported performance drops under distribution shift are load-bearing for the generalization-failure claim, but the manuscript does not detail the precise cross-generator protocols (which generators appear in each corpus), length-normalization steps, or statistical tests confirming that the degradation exceeds what would be expected from topic or formatting shifts alone.
- [SHAP analysis] SHAP analysis (implied §5): While SHAP values are used to show differing top features across the two corpora, the paper does not report controls for feature correlations with text length or formatting artifacts; without these, it remains possible that the 'dataset-specific' attributions partly reflect sensitivity of the chosen linguistic features rather than a fundamental limitation of authorship signals.
minor comments (2)
- [References] Ensure the two benchmark corpora are fully cited with exact versions and access dates in the references section.
- [Results] The abstract states an F1 of 0.9734; report the corresponding precision, recall, and baseline comparisons in the main results table for completeness.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important areas for improving the clarity and robustness of our claims. We address each major comment point by point below and will revise the manuscript accordingly to incorporate the suggested clarifications and additional analyses.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The central claim addresses 'contemporary detectors' broadly, yet all reported results (in-domain F1, cross-domain degradation, and SHAP feature rankings) are obtained exclusively from a 30-feature hand-crafted linguistic model. No evaluation is provided on prevalent transformer-based detectors (e.g., fine-tuned RoBERTa or DeBERTa), leaving open whether the observed artifact reliance and generalization failure are properties of shallow feature sets or of machine-authorship detection in general.
Authors: We agree that the scope of our experiments is limited to the interpretable 30-feature linguistic model. This design choice was intentional to enable direct SHAP-based explanations of feature reliance, which forms the core of our contribution on why detection fails. Transformer-based detectors are indeed more prevalent in contemporary practice, but our results provide evidence that even simple, transparent models succeed in-domain by exploiting unstable artifacts. In the revision, we will update the abstract, introduction, and add a dedicated limitations section to explicitly narrow the claims to linguistic feature-based detectors while discussing the potential extension to neural models and calling for future comparative studies. revision: yes
-
Referee: [Cross-domain evaluation] Cross-domain evaluation (implied §4–5): The reported performance drops under distribution shift are load-bearing for the generalization-failure claim, but the manuscript does not detail the precise cross-generator protocols (which generators appear in each corpus), length-normalization steps, or statistical tests confirming that the degradation exceeds what would be expected from topic or formatting shifts alone.
Authors: This is a valid request for greater methodological transparency. The revised manuscript will expand the experimental setup and evaluation sections to specify: the exact generators used in the PAN CLEF 2025 and COLING 2025 corpora, the length-normalization procedure (including whether length was treated as a feature or texts were truncated/padded), and the application of statistical tests such as paired t-tests or McNemar's test to establish that cross-domain degradation is significant beyond topic or formatting variations. revision: yes
-
Referee: [SHAP analysis] SHAP analysis (implied §5): While SHAP values are used to show differing top features across the two corpora, the paper does not report controls for feature correlations with text length or formatting artifacts; without these, it remains possible that the 'dataset-specific' attributions partly reflect sensitivity of the chosen linguistic features rather than a fundamental limitation of authorship signals.
Authors: We appreciate this concern regarding potential confounds. In the revision, we will augment the SHAP analysis section with explicit controls: reporting correlations between the highest-attribution features and text length, and recomputing SHAP explanations on length-matched data subsets. These additions will help demonstrate whether the dataset-specific feature rankings persist independently of length or formatting effects, thereby strengthening the evidence that the attributions reflect genuine reliance on unstable stylistic cues. revision: yes
Circularity Check
No circularity: claims rest on independent cross-domain experiments and post-hoc attributions
full rationale
The paper trains standard ML classifiers on 30 hand-crafted linguistic features, reports actual in-domain F1 on held-out test splits, measures degradation on separate cross-domain and cross-generator corpora, and applies SHAP post-hoc to the trained models. None of these steps define a quantity in terms of itself, rename a fitted parameter as a prediction, or rely on self-citation chains for the central result. The derivation chain is therefore self-contained empirical evaluation rather than tautological.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosurereality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Using SHAP-based explanations, we show that the most influential features differ markedly between datasets
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Understanding the false positive rate for sentences of our ai writing detection capability, June
Annie Chechitelli. Understanding the false positive rate for sentences of our ai writing detection capability, June
-
[2]
Accessed: 2026-04-21
work page 2026
-
[3]
Student Generative AI Survey 2025
Josh Freeman. Student Generative AI Survey 2025. Policy Note 61, Higher Education Policy Institute (HEPI), February 2025. Accessed: 2026-01-08
work page 2025
-
[4]
Soumya Suvra Ghosal, Souradip Chakraborty, Jonas Geiping, Furong Huang, Dinesh Manocha, and Am- rit Singh Bedi. Towards possibilities & impossibilities of ai-generated text detection: A survey.arXiv preprint arXiv:2310.15264, 2023
-
[5]
SemEval-2024 task 8: Multidomain, multimodel and multilingual machine-generated text detection
Wang Yuxia et al. SemEval-2024 task 8: Multidomain, multimodel and multilingual machine-generated text detection. In Atul Kr. Ojha, A. Seza Do ˘gruöz, Harish Tayyar Madabushi, Giovanni Da San Martino, Sara Rosenthal, and Aiala Rosá, editors,Proceedings of the 18th International Workshop on Semantic Evaluation (SemEval-2024), pages 2057–2079, Mexico City, ...
work page 2024
-
[6]
Janek Bevendorff, Daryna Dementieva, Maik Fröbe, Bela Gipp, André Greiner-Petter, Jussi Karlgren, Maximilian Mayerl, Preslav Nakov, Alexander Panchenko, Martin Potthast, et al. Overview of pan 2025: V oight-kampff 19 generative ai detection, multilingual text detoxification, multi-author writing style analysis, and generative plagiarism detection. InInter...
work page 2025
-
[7]
International Conference on Computational Linguistics
Firoj Alam, Preslav Nakov, Nizar Habash, Iryna Gurevych, Shammur Chowdhury, Artem Shelmanov, Yuxia Wang, Ekaterina Artemova, Mucahid Kutlu, and George Mikros, editors.Proceedings of the 1st Workshop on GenAI Content Detection (GenAIDetect), Abu Dhabi, UAE, January 2025. International Conference on Computational Linguistics
work page 2025
-
[8]
Can AI-Generated Text be Reliably Detected?
Vinu Sankar Sadasivan, Aounon Kumar, Sriram Balasubramanian, Wenxiao Wang, and Soheil Feizi. Can ai-generated text be reliably detected?arXiv preprint arXiv:2303.11156, 2023
work page Pith review arXiv 2023
-
[9]
Watermarks in the sand: impossibility of strong watermarking for language models
Hanlin Zhang, Benjamin L Edelman, Danilo Francati, Daniele Venturi, Giuseppe Ateniese, and Boaz Barak. Watermarks in the sand: impossibility of strong watermarking for language models. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[10]
Jiazhou Ji, Ruizhe Li, Shujun Li, Jie Guo, Weidong Qiu, Zheng Huang, Chiyu Chen, Xiaoyu Jiang, and Xinru Lu. Detecting machine-generated texts: Not just "ai vs humans" and explainability is complicated, 2025
work page 2025
-
[11]
Styloai: Distinguishing ai-generated content with stylometric analysis
Chidimma Opara. Styloai: Distinguishing ai-generated content with stylometric analysis. InInternational conference on artificial intelligence in education, pages 105–114. Springer, 2024
work page 2024
-
[12]
Linguistic characteristics of ai-generated text: A survey.arXiv preprint arXiv:2510.05136, 2025
Luka Terˇcon and Kaja Dobrovoljc. Linguistic characteristics of ai-generated text: A survey.arXiv preprint arXiv:2510.05136, 2025
-
[13]
Zhiwei Yang, Zhengjie Feng, Rongxin Huo, Huiru Lin, Hanghan Zheng, Ruichi Nie, and Hongrui Chen. The imitation game revisited: A comprehensive survey on recent advances in ai-generated text detection.Expert Systems with Applications, 272:126694, 2025
work page 2025
-
[14]
Shushanta Pudasaini, Luis Miralles-Pechuán, David Lillis, and Marisa Llorens Salvador. Survey on ai-generated plagiarism detection: The impact of large language models on academic integrity.Journal of Academic Ethics, pages 1–34, 2024
work page 2024
-
[15]
Xiaomeng Hu, Pin-Yu Chen, and Tsung-Yi Ho. Radar: Robust ai-text detection via adversarial learning.Advances in neural information processing systems, 36:15077–15095, 2023
work page 2023
-
[16]
RAID: A shared benchmark for robust evaluation of machine-generated text detectors
Liam Dugan, Alyssa Hwang, Filip Trhlík, Andrew Zhu, Josh Magnus Ludan, Hainiu Xu, Daphne Ippolito, and Chris Callison-Burch. RAID: A shared benchmark for robust evaluation of machine-generated text detectors. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12463–12492, Bangkok, Thail...
work page 2024
-
[18]
Shushanta Pudasaini, Luis Miralles, David Lillis, and Marisa Llorens Salvador. Benchmarking AI text detection: Assessing detectors against new datasets, evasion tactics, and enhanced LLMs. In Firoj Alam, Preslav Nakov, Nizar Habash, Iryna Gurevych, Shammur Chowdhury, Artem Shelmanov, Yuxia Wang, Ekaterina Artemova, Mucahid Kutlu, and George Mikros, editor...
work page 2025
-
[19]
GLTR: Statistical detection and visualization of generated text
Sebastian Gehrmann, Hendrik Strobelt, and Alexander Rush. GLTR: Statistical detection and visualization of generated text. In Marta R. Costa-jussà and Enrique Alfonseca, editors,Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 111–116, Florence, Italy, July
-
[20]
Association for Computational Linguistics
-
[21]
GenAI content detection task 1: English and multilingual machine-generated text detection: AI vs
Yuxia Wang, Artem Shelmanov, Jonibek Mansurov, Akim Tsvigun, Vladislav Mikhailov, Rui Xing, Zhuohan Xie, Jiahui Geng, Giovanni Puccetti, Ekaterina Artemova, Jinyan Su, Minh Ngoc Ta, Mervat Abassy, Kareem Ashraf Elozeiri, Saad El Dine Ahmed El Etter, Maiya Goloburda, Tarek Mahmoud, Raj Vardhan Tomar, Nurkhan Laiyk, Osama Mohammed Afzal, Ryuto Koike, Masahi...
work page 2025
-
[22]
Kamrujjaman Mobin and Md Saiful Islam
MD. Kamrujjaman Mobin and Md Saiful Islam. LuxVeri at GenAI detection task 1: Inverse perplexity weighted ensemble for robust detection of AI-generated text across English and multilingual contexts. In Firoj Alam, Preslav Nakov, Nizar Habash, Iryna Gurevych, Shammur Chowdhury, Artem Shelmanov, Yuxia Wang, Ekaterina 20 Artemova, Mucahid Kutlu, and George M...
work page 2025
-
[23]
Enhancing AI Text Detection with Frozen Pretrained Encoders and Ensemble Learning
Shushanta Pudasaini, Luis Miralles-Pechúán, David Lillis, and Marisa Llorens Salvador. Enhancing AI Text Detection with Frozen Pretrained Encoders and Ensemble Learning. InWorking Notes of CLEF 2025 – Conference and Labs of the Evaluation Forum, volume 4038 ofCEUR Workshop Proceedings, Madrid, Spain, 2025. CEUR- WS.org
work page 2025
-
[24]
Sepyan Purnama Kristanto and Lutfi Hakim. A theoretically grounded hybrid ensemble for reliable detection of llm-generated text.arXiv preprint arXiv:2511.22153, 2025
-
[25]
Adven Masih, Bushra Afzal, Shamyla Firdoos, Jabar Mahmood, Aitizaz Ali, Mohamed Shabbir Abdulnabi, and Daniel Musafiri Balungu. Classifying human vs. ai text with machine learning and explainable transformer models. Scientific Reports, 15(1):43310, 2025
work page 2025
-
[26]
Najjar, Huthaifa Ashqar, Omar Darwish, and Eman A
Ayat A. Najjar, Huthaifa Ashqar, Omar Darwish, and Eman A. Hammad. Leveraging explainable ai for llm text attribution: Differentiating human-written and multiple llm-generated text.Information (Switzerland), 16(9):767, sep 2025
work page 2025
-
[27]
Steven Bird, Ewan Klein, and Edward Loper.Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit. O’Reilly Media, 2009
work page 2009
-
[28]
spacy: Industrial-strength natural language processing in python, 2020
Matthew Honnibal, Ines Montani, Sofie Van Landeghem, and Adriane Boyd. spacy: Industrial-strength natural language processing in python, 2020
work page 2020
-
[29]
A rule-based style and grammar checker
Daniel Naber. A rule-based style and grammar checker. Diploma thesis, Bielefeld University, 2003
work page 2003
-
[30]
Textblob: Simplified text processing
Steven Loria. Textblob: Simplified text processing. https://textblob.readthedocs.io/, 2018. Accessed: 2026-02-12
work page 2018
-
[31]
Scikit-learn: Machine learning in python.Journal of Machine Learning Research, 12:2825–2830, 2011
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake Vanderplas, Alexandre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot, and Édouard Duchesnay. Scikit-learn: Machine learning in python.Journal of Machine Learning Research...
work page 2011
-
[32]
Ghostbuster: Detecting text ghostwritten by large language models
Vivek Verma, Eve Fleisig, Nicholas Tomlin, and Dan Klein. Ghostbuster: Detecting text ghostwritten by large language models. In Kevin Duh, Helena Gomez, and Steven Bethard, editors,Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 17...
work page 2024
-
[33]
Exploring the limitations of detecting machine-generated text
Jad Doughman, Osama Mohammed Afzal, Hawau Olamide Toyin, Shady Shehata, Preslav Nakov, and Zeerak Talat. Exploring the limitations of detecting machine-generated text. InProceedings of the 31st International Conference on Computational Linguistics, pages 4274–4281, 2025
work page 2025
-
[34]
Isabelle Guyon, Jason Weston, Stephen Barnhill, and Vladimir Vapnik. Gene selection for cancer classification using support vector machines.Machine Learning, 46(1–3):389–422, 2002
work page 2002
-
[35]
Sayar Ul Hassan, Jameel Ahamed, and Khaleel Ahmad. Analytics of machine learning-based algorithms for text classification.Sustainable operations and computers, 3:238–248, 2022
work page 2022
-
[36]
Support-vector networks.Machine learning, 20(3):273–297, 1995
Corinna Cortes and Vladimir Vapnik. Support-vector networks.Machine learning, 20(3):273–297, 1995
work page 1995
-
[37]
Haowei Hua and Co-Jiayu Yao. Investigating generative ai models and detection techniques: impacts of tok- enization and dataset size on identification of ai-generated text.Frontiers in Artificial Intelligence, 7:1469197, 2024
work page 2024
-
[38]
Sen Yan, Zhiyi Wang, and David Dobolyi. An explainable framework for assisting the detection of ai-generated textual content.Decision Support Systems, page 114498, 2025
work page 2025
-
[39]
mdok of kinit: Robustly fine-tuned llm for binary and multiclass ai-generated text detection, 2025
Dominik Macko. mdok of kinit: Robustly fine-tuned llm for binary and multiclass ai-generated text detection, 2025
work page 2025
-
[40]
S.S. Shapiro and M.B. Wilk. An analysis of variance test for normality.Biometrika, 52(3):591–611, 1965
work page 1965
-
[41]
One-class learning for ai-generated essay detection.Applied Sciences, 13(13):7901, 2023
Roberto Corizzo and Sebastian Leal-Arenas. One-class learning for ai-generated essay detection.Applied Sciences, 13(13):7901, 2023. 21
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.