Recognition: unknown
Unleashing Spatial Reasoning in Multimodal Large Language Models via Textual Representation Guided Reasoning
Pith reviewed 2026-05-15 00:04 UTC · model grok-4.3
The pith
TRACE prompting lets MLLMs create text-based 3D maps from video to answer spatial questions more accurately.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
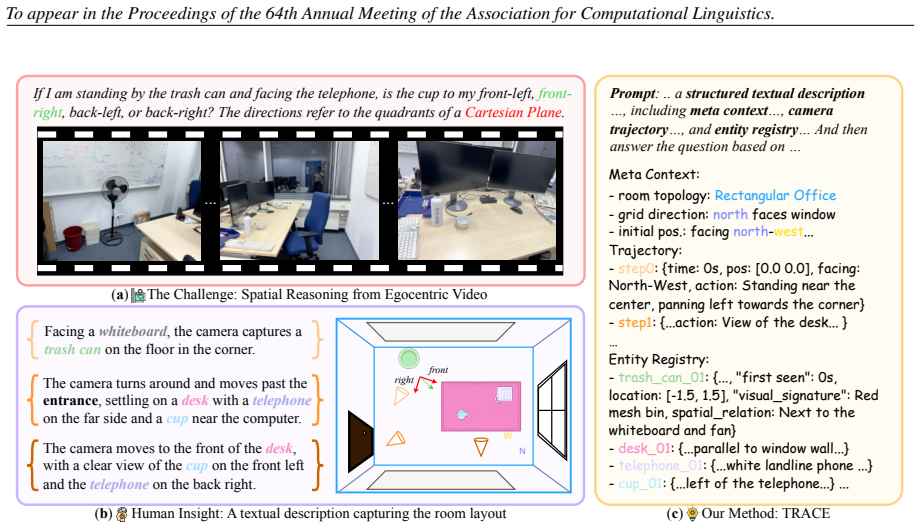
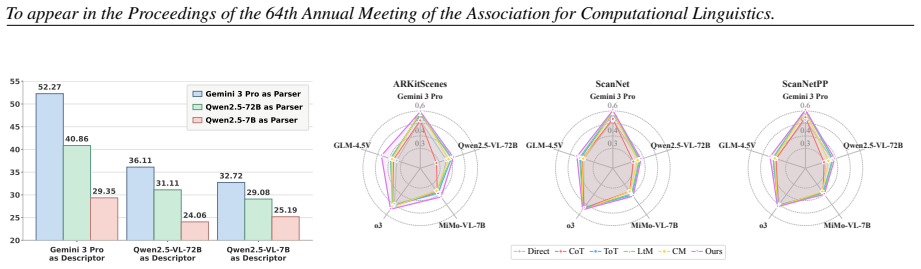
TRACE induces MLLMs to output text-based allocentric representations of 3D scenes from egocentric video inputs as intermediate reasoning traces. By encoding meta-context, camera trajectories, and detailed object entities, these traces enable more structured spatial reasoning, producing notable and consistent accuracy gains on VSI-Bench and OST-Bench across diverse MLLM backbones that vary in scale and training schema.
What carries the argument
TRACE (Textual Representation of Allocentric Context from Egocentric Video), a prompting method that generates text-based 3D environment descriptions as intermediate reasoning traces for spatial question answering.
If this is right
- TRACE outperforms prior prompting strategies on VSI-Bench and OST-Bench for spatial reasoning tasks.
- The improvements hold across MLLMs with different parameter scales and training schemas.
- Ablation studies confirm that encoding meta-context, trajectories, and object entities each contribute to the gains.
- Detailed analyses identify specific bottlenecks in current MLLM 3D spatial reasoning from video.
Where Pith is reading between the lines
- The text representations could be combined with external geometry tools to verify or correct the intermediate steps in real applications.
- TRACE-style prompts might transfer to related tasks such as video-based action planning or object manipulation.
- Making the representations use more explicit coordinate formats or graphs rather than free text could further reduce ambiguity.
- Success with text intermediates points to a broader pattern where language scaffolds can compensate for missing geometric modules in MLLMs.
Load-bearing premise
MLLMs can reliably generate accurate and complete text-based allocentric representations of 3D environments from egocentric video without introducing errors that propagate to downstream spatial reasoning.
What would settle it
A test set with known ground-truth 3D layouts where TRACE-generated texts are measured for accuracy against the layout and spatial answer accuracy is compared when texts are forced to be accurate versus deliberately inaccurate.
Figures



read the original abstract
Existing Multimodal Large Language Models (MLLMs) struggle with 3D spatial reasoning, as they fail to construct structured abstractions of the 3D environment depicted in video inputs. To bridge this gap, drawing inspiration from cognitive theories of allocentric spatial reasoning, we investigate how to enable MLLMs to model and reason over text-based spatial representations of video. Specifically, we introduce Textual Representation of Allocentric Context from Egocentric Video (TRACE), a prompting method that induces MLLMs to generate text-based representations of 3D environments as intermediate reasoning traces for more accurate spatial question answering. TRACE encodes meta-context, camera trajectories, and detailed object entities to support structured spatial reasoning over egocentric videos. Extensive experiments on VSI-Bench and OST-Bench demonstrate that TRACE yields notable and consistent improvements over prior prompting strategies across a diverse range of MLLM backbones, spanning different parameter scales and training schemas. We further present ablation studies to validate our design choices, along with detailed analyses that probe the bottlenecks of 3D spatial reasoning in MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TRACE, a prompting method that induces MLLMs to produce intermediate text-based allocentric representations of 3D environments from egocentric video inputs. These representations encode meta-context, camera trajectories, and detailed object entities to support improved spatial question answering. Experiments on VSI-Bench and OST-Bench report consistent gains over prior prompting baselines across multiple MLLM backbones of varying scales and training regimes, supported by ablation studies.
Significance. If the observed gains prove attributable to the structured allocentric modeling rather than prompt-length artifacts, the work offers a training-free, cognitively motivated technique for eliciting spatial reasoning in existing MLLMs. The cross-backbone evaluation and ablation analyses provide useful empirical grounding for the design choices.
major comments (3)
- [Experiments] Experiments section: the abstract and results claim consistent improvements but supply no quantitative effect sizes, confidence intervals, or statistical significance tests; without these, it is impossible to assess whether the gains exceed what would be expected from longer or more detailed prompts alone.
- [Method and Analysis] Method and Analysis sections: the central claim rests on the assumption that the generated textual representations faithfully capture 3D structure, yet the paper provides no direct fidelity evaluation (e.g., comparison against ground-truth 3D annotations or human judgments of completeness and accuracy); end-task accuracy alone cannot distinguish genuine allocentric modeling from generic chain-of-thought scaffolding.
- [Ablation studies] Ablation studies: the reported ablations do not isolate the contribution of each representational component (meta-context, trajectories, object entities) while holding total token count fixed, leaving open whether performance differences arise from content structure or from variations in prompt length and detail.
minor comments (2)
- [Abstract] Abstract: the phrase 'notable and consistent improvements' is used without accompanying numerical values or baseline comparisons, reducing informativeness for readers.
- [Introduction] Notation: the acronym TRACE is introduced without an explicit expansion on first use in the main text, although the abstract provides it.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully addressed each major comment below and outline the revisions we will make to strengthen the empirical support and clarify the contributions of TRACE.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the abstract and results claim consistent improvements but supply no quantitative effect sizes, confidence intervals, or statistical significance tests; without these, it is impossible to assess whether the gains exceed what would be expected from longer or more detailed prompts alone.
Authors: We agree that reporting effect sizes, confidence intervals, and statistical significance tests is essential for rigorously evaluating the improvements. In the revised manuscript, we will add quantitative effect sizes (e.g., absolute and relative accuracy gains with standard deviations across runs), 95% confidence intervals, and p-values from paired statistical tests such as the Wilcoxon signed-rank test. To directly address the prompt-length concern, we will include a new control baseline in which baseline prompts are padded with neutral descriptive text to match the token count of TRACE prompts, allowing us to isolate the contribution of the structured allocentric content. revision: yes
-
Referee: [Method and Analysis] Method and Analysis sections: the central claim rests on the assumption that the generated textual representations faithfully capture 3D structure, yet the paper provides no direct fidelity evaluation (e.g., comparison against ground-truth 3D annotations or human judgments of completeness and accuracy); end-task accuracy alone cannot distinguish genuine allocentric modeling from generic chain-of-thought scaffolding.
Authors: We acknowledge that direct fidelity evaluation would provide stronger evidence for the allocentric modeling claim. Although the VSI-Bench and OST-Bench datasets do not include explicit 3D ground-truth annotations, we will add a human evaluation study on a representative subset of videos. Annotators will rate the completeness and accuracy of the generated meta-context, trajectories, and object entities against the video content, with inter-annotator agreement reported. We will also analyze the correlation between these fidelity scores and downstream QA performance to differentiate structured spatial representations from generic chain-of-thought effects. revision: yes
-
Referee: [Ablation studies] Ablation studies: the reported ablations do not isolate the contribution of each representational component (meta-context, trajectories, object entities) while holding total token count fixed, leaving open whether performance differences arise from content structure or from variations in prompt length and detail.
Authors: We agree that holding token count fixed is necessary to isolate the structural contributions. In the revised ablation studies, we will re-conduct the component ablations while adjusting prompt lengths to be approximately equal across conditions (e.g., by inserting neutral filler text where components are removed). This controlled setup will demonstrate that observed performance differences arise from the specific allocentric representational structure rather than token-count variations. revision: yes
Circularity Check
No circularity: empirical prompting method evaluated on external benchmarks
full rationale
The paper introduces TRACE as a prompting intervention that induces MLLMs to produce text-based allocentric representations (meta-context, camera trajectories, object entities) from egocentric video, then evaluates end-task accuracy gains on VSI-Bench and OST-Bench across multiple backbones. No equations, derivations, or fitted parameters are presented that reduce any claimed prediction or result to the same inputs by construction. The approach draws inspiration from external cognitive theories and reports ablation studies plus benchmark comparisons; no self-citation load-bearing, self-definitional steps, or renaming of known results appear in the derivation chain. The central claim remains an empirical observation on independent test sets rather than a tautological reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MLLMs can generate structured text representations of 3D scenes that preserve spatial relations when given appropriate meta-context and trajectory cues.
invented entities (1)
-
TRACE prompting template
no independent evidence
Forward citations
Cited by 2 Pith papers
-
Beyond Localization: A Comprehensive Diagnosis of Perspective-Conditioned Spatial Reasoning in MLLMs from Omnidirectional Images
MLLMs exhibit a large perception-reasoning gap on perspective-conditioned spatial reasoning in omnidirectional images, with accuracy falling from 57% on basic direction tasks to under 1% on compositional reasoning, th...
-
Beyond Localization: A Comprehensive Diagnosis of Perspective-Conditioned Spatial Reasoning in MLLMs from Omnidirectional Images
A new benchmark reveals MLLMs achieve only 13% or lower accuracy on advanced perspective-conditioned spatial tasks in omnidirectional images, with RL reward shaping raising a 7B model from 31% to 60% in controlled settings.
Reference graph
Works this paper leans on
-
[1]
Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923. Gilad Baruch, Zhuoyuan Chen, Afshin Dehghan, Yuri Feigin, Peter Fu, Thomas Gebauer, Daniel Kurz, Tal Dimry, Brandon Joffe, Arik Schwartz, and Elad Shulman. 2021. ARKitscenes: A diverse real-world dataset for 3d indoor scene understanding using mo- bile RGB-d data. InThirty-fifth Conference on Ne...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProc. Computer Vision and Pattern Recognition (CVPR), IEEE. Erik Daxberger, Nina Wenzel, David Griffiths, Haim- ing Gang, Justin Lazarow, Gefen Kohavi, Kai Kang, Marcin Eichner, Yinfei Yang, Afshin Dehghan, and 1 others. 2025. Mm-spatial: Exploring 3d spatial understanding in multimodal llms...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing
Critic: Large language models can self-correct with tool-interactive critiquing.arXiv preprint arXiv:2305.11738. Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
3d-llm: Injecting the 3d world into large lan- guage models.Advances in Neural Information Pro- cessing Systems, 36:20482–20494. Zeyi Huang, Yuyang Ji, Xiaofang Wang, Nikhil Mehta, Tong Xiao, Donghyun Lee, Sigmund Vanvalken- burgh, Shengxin Zha, Bolin Lai, Licheng Yu, and 1 others. 2025. Building a mind palace: Structuring environment-grounded semantic gr...
-
[5]
arXiv preprint arXiv:2409.18125 (2024)
Tree of thoughts: Deliberate problem solving with large language models. InAdvances in Neural Information Processing Systems, volume 36, pages 11809–11822. Curran Associates, Inc. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh in...
-
[6]
Focus ONLY on these categories
We provide the categories to care about in this scene: {CATEGORIES_OF_INTEREST}. Focus ONLY on these categories
-
[7]
Estimate the center location of each instance within the provided categories, assuming the entire scene is represented by a 10x10 grid
-
[8]
If a category contains multiple instances, include all of them
-
[9]
Each object’s estimated location should accurately reflect its real position in the scene, preserving the relative spatial relationships among all objects. [Output] Present the estimated center locations for each object as a list within a dictionary. STRICTLYfollow this JSON format: {"CATE- GORY NAME": ["(X_1,Y_1)", ...], ...}. Answer format: - {POST_PROM...
-
[10]
Coordinate System Rules (Room-Aligned Allocentric Frame) – Origin: the camera starting position is ex- actly[0.0, 0.0]on the floor plane. – Major Axes (+Y / +X): Align the coordi- nate system with thedominant wallsorfloor gridof the room rather than the camera’s ini- tial viewing direction.: – define ‘+Y’ along that dominant struc- tural direction; – defi...
-
[11]
Meta-Context Rules You must infer and report: – room_topology: the overall spatial struc- ture of the observed environment, such as ‘rect- angular bedroom‘, ‘L-shaped office‘, or ‘nar- row hallway connected to kitchen‘ – grid_alignment: the structural cue used to define the allocentric axes – initial_camera_heading: the camera’s initial facing direction r...
-
[12]
2s") – pos: Estimated [x, y] of the camera. – facing: Cardinal direction and axis (e.g.,
Trajectory Rules You must log the camera path continuously. Output a trajectory step forevery significant camera movement. –step: Sequential ID. – time: Timestamp of the step (e.g., "2s") – pos: Estimated [x, y] of the camera. – facing: Cardinal direction and axis (e.g., "North (+Y)"). – action: Short description of the camera motion or viewpoint change
-
[13]
Entity Registry Rules You must register every visible entity individ- ually. Never group objects. For each entity, include: – id: unique identifier such as chair_01, door_01 –category –first_seen_at –estimated_pos:[x, y] – approx_size: [width, height, depth] – visual_signature: short appearance- based description for disambiguation – spatial_relation: at ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.