Recognition: 2 theorem links
· Lean TheoremPDGMM-VAE: A Variational Autoencoder with Adaptive Per-Dimension Gaussian Mixture Model Priors for Nonlinear ICA
Pith reviewed 2026-05-15 08:35 UTC · model grok-4.3
The pith
A variational autoencoder with per-dimension adaptive Gaussian mixture priors recovers independent non-Gaussian sources in nonlinear ICA by reducing permutation symmetry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
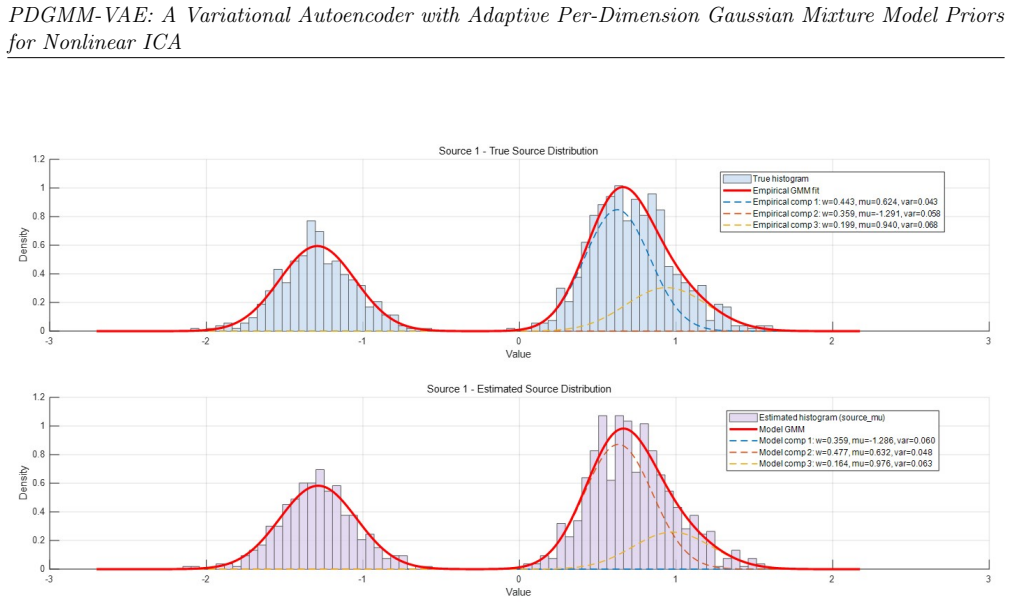
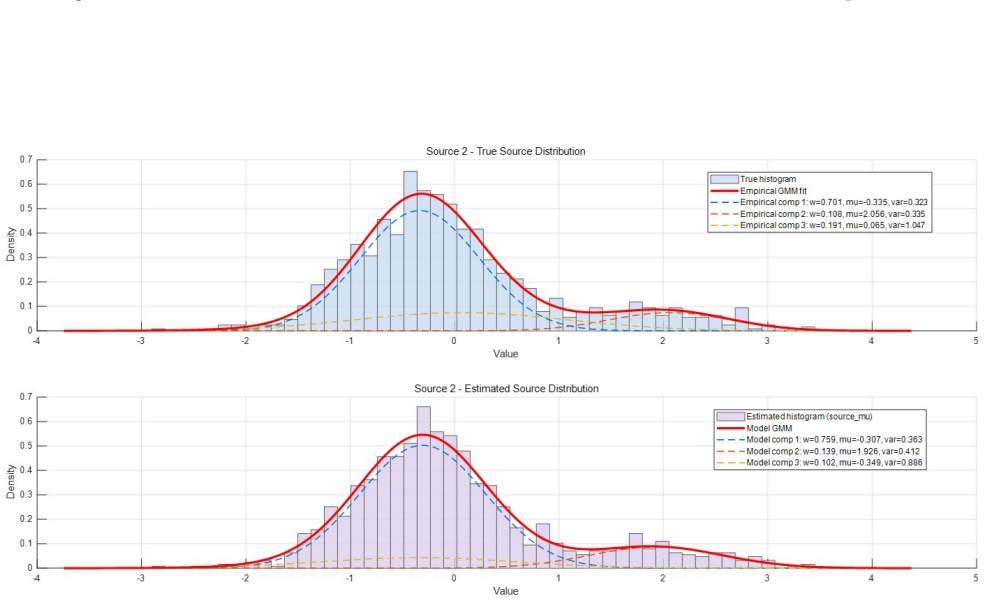
In PDGMM-VAE each latent dimension, treated as a source component, is given its own adaptive GMM prior whose parameters are learned jointly with the encoder and decoder. Heterogeneous per-dimension priors reduce latent permutation symmetry relative to homogeneous shared priors. The KL regularization from the adaptive GMM prior induces source-specific attraction behavior that accounts for source-wise specialization in training. The model also admits a weak recovery guarantee in an idealized linear low-noise regime.
What carries the argument
Adaptive per-dimension Gaussian mixture model priors that are jointly optimized to impose heterogeneous constraints on the latent variables and reduce permutation symmetry.
If this is right
- Each latent dimension can model a unique non-Gaussian source marginal inside a single VAE architecture.
- The framework unifies probabilistic encoding and decoding for nonlinear ICA tasks.
- KL-induced attraction explains the observed specialization of dimensions to individual sources.
- Weak source recovery holds in linear low-noise settings without additional post-processing.
Where Pith is reading between the lines
- Similar per-dimension adaptive priors could improve disentanglement in other latent variable models such as normalizing flows.
- Joint optimization of priors might eliminate the need for separate post-hoc permutation resolution steps common in ICA.
- Testing on high-dimensional data with unknown distributions would show whether the mixture components remain stable without manual tuning.
Load-bearing premise
The source marginals can be adequately represented by Gaussian mixture models whose parameters are jointly optimized with the VAE without creating additional identifiability issues.
What would settle it
Running controlled experiments on synthetic data with known non-Gaussian sources and verifying whether the learned per-dimension priors match the true source marginals while the sources are recovered without permutation swaps.
Figures









read the original abstract
Independent component analysis is a core framework within blind source separation for recovering latent source signals from observed mixtures under statistical independence assumptions. In this work, we propose PDGMM-VAE, a source-oriented variational autoencoder in which each latent dimension, interpreted explicitly as an individual source component, is assigned its own adaptive Gaussian mixture model prior. The proposed framework imposes heterogeneous per-dimension prior constraints, enabling different latent dimensions to model different non-Gaussian source marginals within a unified probabilistic encoder-decoder architecture. The parameters of these source-specific GMM priors are not fixed in advance, but are jointly learned together with the encoder and decoder under the overall training objective. Beyond the model construction itself, we provide a theoretical analysis clarifying why adaptive per-dimension prior design is meaningful in this setting. In particular, we show that heterogeneous per-dimension priors reduce latent permutation symmetry relative to homogeneous shared priors, and we further show that the KL regularization induced by the adaptive GMM prior creates source-specific attraction behavior that helps explain source-wise specialization during training. We also clarify the relation of the proposed model to the standard VAE and provide a weak recovery statement in an idealized linear low-noise regime. Experimental results on both linear and nonlinear mixing problems show that PDGMM-VAE can recover latent source signals and fit source-specific non-Gaussian marginals effectively. These results suggest that adaptive per-dimension mixture-prior design provides a principled and promising direction for VAE-based ICA and source-oriented generative modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PDGMM-VAE, a VAE for nonlinear ICA in which each latent dimension is assigned its own jointly-learned adaptive GMM prior. It claims that heterogeneous per-dimension priors reduce latent permutation symmetry relative to homogeneous shared priors, that the induced KL term produces source-specific attraction explaining specialization during training, and that the model achieves weak recovery in an idealized linear low-noise regime. Experiments on linear and nonlinear mixing problems are reported to show effective source recovery and marginal fitting.
Significance. If the symmetry-reduction and attraction arguments can be shown to be non-tautological and if the nonlinear identifiability claim can be placed on firmer footing, the work would offer a concrete mechanism for source-oriented priors inside VAEs that could improve specialization without hand-specified source distributions. The joint optimization of per-dimension GMM parameters is a distinctive design choice whose practical consequences for identifiability merit further scrutiny.
major comments (3)
- [Theoretical analysis] Theoretical analysis section: the claimed reduction in latent permutation symmetry is presented as a consequence of heterogeneous per-dimension priors, yet the argument appears to follow immediately from the model definition (distinct priors break exchangeability by construction). A self-contained derivation showing an additional, non-trivial effect beyond this definitional asymmetry is required.
- [Theoretical analysis] Theoretical analysis section: only a weak recovery statement is supplied for the linear low-noise regime. No formal identifiability theorem, proof sketch, or sufficient conditions are given for the nonlinear mixing case that constitutes the paper's primary target, leaving the central nonlinear-ICA claim without load-bearing theoretical support.
- [Experiments] Experiments section: recovery results are stated for both linear and nonlinear problems, but the manuscript supplies neither error bars, quantitative baseline comparisons, nor details on data exclusion or hyper-parameter sensitivity. This prevents assessment of whether the reported source-wise specialization is robust or merely consistent with the chosen prior form.
minor comments (2)
- [Abstract] Abstract: the summary of theoretical results mentions symmetry reduction and attraction behavior without any equation references or quantitative statements, reducing immediate clarity for readers.
- [Model definition] Notation: the per-dimension GMM parameters are described as jointly optimized, but the precise parameterization (means, variances, mixture weights per dimension) and their initialization are not stated explicitly, complicating reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the theoretical and experimental sections.
read point-by-point responses
-
Referee: [Theoretical analysis] Theoretical analysis section: the claimed reduction in latent permutation symmetry is presented as a consequence of heterogeneous per-dimension priors, yet the argument appears to follow immediately from the model definition (distinct priors break exchangeability by construction). A self-contained derivation showing an additional, non-trivial effect beyond this definitional asymmetry is required.
Authors: We agree that the basic breaking of exchangeability follows from assigning distinct priors. The non-trivial contribution we aim to highlight is the dynamic effect during training: the jointly optimized GMM parameters induce a source-specific attraction term in the KL divergence that encourages each latent dimension to specialize to a particular source marginal rather than remaining interchangeable. We will revise the theoretical analysis section to include a self-contained derivation that isolates this optimization-driven mechanism (including the gradient flow induced by the adaptive mixture weights) beyond the static model asymmetry. revision: yes
-
Referee: [Theoretical analysis] Theoretical analysis section: only a weak recovery statement is supplied for the linear low-noise regime. No formal identifiability theorem, proof sketch, or sufficient conditions are given for the nonlinear mixing case that constitutes the paper's primary target, leaving the central nonlinear-ICA claim without load-bearing theoretical support.
Authors: We acknowledge that the manuscript provides only a weak recovery guarantee for the idealized linear low-noise setting and does not contain a formal identifiability theorem for the general nonlinear case. Establishing sufficient conditions for nonlinear identifiability under adaptive GMM priors is a challenging open question that lies beyond the scope of the current work. In the revision we will expand the discussion to explicitly state the limitations of the theoretical claims, clarify that the nonlinear-ICA results are empirical, and add a brief proof sketch for the linear case to make the weak recovery statement more self-contained. revision: partial
-
Referee: [Experiments] Experiments section: recovery results are stated for both linear and nonlinear problems, but the manuscript supplies neither error bars, quantitative baseline comparisons, nor details on data exclusion or hyper-parameter sensitivity. This prevents assessment of whether the reported source-wise specialization is robust or merely consistent with the chosen prior form.
Authors: We thank the referee for this observation. The revised manuscript will include standard error bars computed over multiple random seeds, quantitative comparisons against standard VAE, iVAE, and other nonlinear ICA baselines using established metrics (e.g., mean correlation coefficient and Amari distance), and an appendix detailing hyper-parameter ranges, data preprocessing steps, and exclusion criteria. These additions will allow readers to evaluate the robustness of the observed source specialization. revision: yes
- A complete formal identifiability theorem with sufficient conditions for the nonlinear mixing case
Circularity Check
Symmetry reduction and source-specific attraction are direct consequences of heterogeneous per-dimension GMM prior and standard KL term
specific steps
-
self definitional
[Abstract]
"we show that heterogeneous per-dimension priors reduce latent permutation symmetry relative to homogeneous shared priors, and we further show that the KL regularization induced by the adaptive GMM prior creates source-specific attraction behavior that helps explain source-wise specialization during training"
The claimed reductions in symmetry and the source-specific attraction are immediate mathematical consequences of using distinct per-dimension GMM priors inside the standard VAE objective; the 'showing' restates the definitional implications of the architecture rather than deriving them from independent premises or external results.
full rationale
The paper's theoretical analysis claims to 'show' that heterogeneous per-dimension priors reduce latent permutation symmetry and that the induced KL term creates source-specific attraction explaining specialization. These statements appear in the abstract as load-bearing clarifications of why the design is meaningful. However, both properties follow immediately from assigning distinct adaptive GMM priors to each latent dimension and applying the standard VAE ELBO with KL regularization; no independent derivation, uniqueness theorem, or external constraint is required. The weak recovery result is explicitly restricted to an idealized linear low-noise regime, leaving the nonlinear ICA claims without additional support. This matches the self-definitional pattern: the 'predictions' reduce to restatements of the model definition itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-dimension GMM parameters
axioms (2)
- domain assumption Latent sources are statistically independent
- standard math Variational encoder-decoder can approximate the true posterior
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
heterogeneous per-dimension priors reduce latent permutation symmetry relative to homogeneous shared priors... KL regularization induced by the adaptive GMM prior creates source-specific attraction behavior
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
weak recovery statement in an idealized linear low-noise regime
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
StrADiff: A Structured Source-Wise Adaptive Diffusion Framework for Linear and Nonlinear Blind Source Separation
StrADiff recovers latent source trajectories from linear and nonlinear mixtures via source-wise adaptive diffusion and a Gaussian process prior in a single unsupervised end-to-end objective.
-
StrEBM: A Structured Latent Energy-Based Model for Blind Source Separation
StrEBM applies source-wise Gaussian-process-inspired energies with learnable length-scales to jointly optimize latent trajectories and observation mappings for recovering components from linear and nonlinear mixtures.
Reference graph
Works this paper leans on
- [1]
-
[2]
Shanahan, M. (2016). Deep unsupervised clustering with gaussian mixture variational autoencoders. arXiv preprint arXiv:1611.02648
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Falck, F., Zhang, H., Willetts, M., Nicholson, G., Yau, C., and Holmes, C. (2021). Multi-facet clustering variational autoencoders. InAdvances in Neural Information Processing Systems, volume 34, pages 13360–13371. Hyvärinen, A., Karhunen, J., and Oja, E. (2001).Independent Component Analysis. John Wiley & Sons. Hyvärinen, A., Khemakhem, I., and Morioka, ...
-
[4]
Jiang, Z., Zheng, Y., Tan, H., Tang, B., and Zhou, H. (2017). Variational deep embedding: An unsu- pervised and generative approach to clustering. InProceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, pages 1965–1972. IJCAI
work page 2017
-
[5]
Khemakhem, I., Kingma, D. P., Monti, R. P., and Hyvärinen, A. (2020). Variational autoencoders and nonlinear ica: A unifying framework. InProceedings of the Twenty-Third International Conference on Artificial Intelligence and Statistics, volume 108 ofProceedings of Machine Learning Research, pages 2207–2217. PMLR
work page 2020
- [6]
-
[7]
Li, X., Chen, Z., Poon, L. K. M., and Zhang, N. L. (2018). Learning latent superstructures in variational autoencoders for deep multidimensional clustering.arXiv preprint arXiv:1803.05206
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [8]
- [9]
- [10]
-
[11]
Willetts, M. and Paige, B. (2021). I don’t need u: Identifiable non-linear ica without side information. arXiv preprint arXiv:2106.05238
- [12]
- [13]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.