Recognition: 2 theorem links
· Lean TheoremStrADiff: A Structured Source-Wise Adaptive Diffusion Framework for Linear and Nonlinear Blind Source Separation
Pith reviewed 2026-05-13 17:15 UTC · model grok-4.3
The pith
StrADiff recovers latent source trajectories from linear and nonlinear mixtures through per-source adaptive diffusion in one unsupervised objective.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By equipping each latent dimension with its own adaptive reverse diffusion mechanism and coupling it to a structured prior such as a Gaussian process, the framework directly recovers latent source trajectories from observed mixtures via a single end-to-end objective that jointly optimizes source-wise generation, structural regularization, and observation-space reconstruction, without requiring supervised labels or post-processing steps.
What carries the argument
source-wise adaptive reverse diffusion mechanism that assigns an independent diffusion process to each latent dimension to drive direct recovery from mixtures
If this is right
- Latent sources are recovered directly through joint optimization of generation, regularization, and reconstruction without separate post-processing.
- A Gaussian process prior imposes temporal organization on each recovered trajectory while the framework remains open to other structured priors.
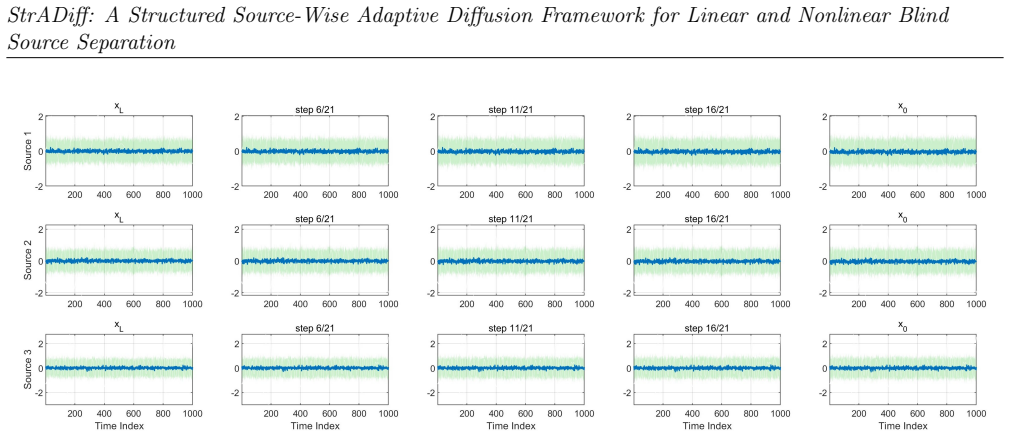
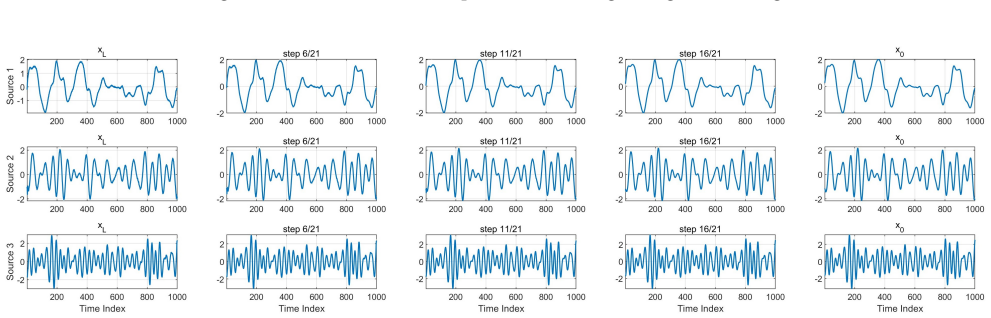
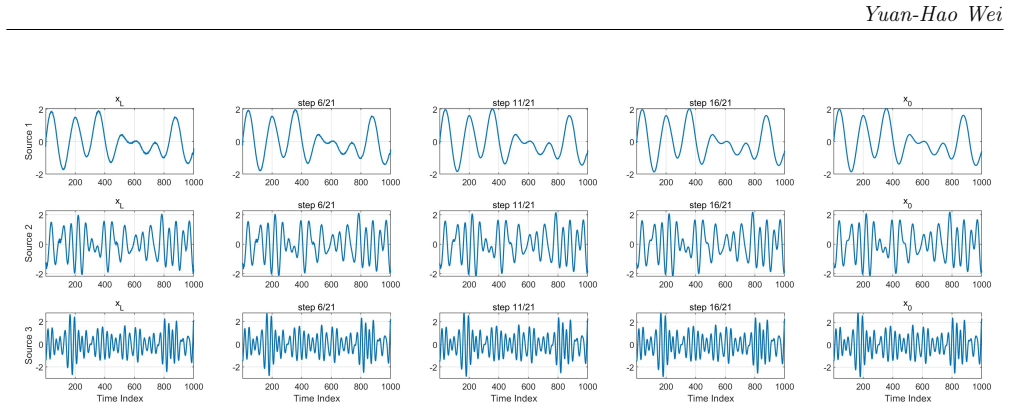
- The method yields stable performance on linear mixtures and only moderate degradation on nonlinear mixtures.
- Theoretical analysis establishes the induced pushforward source law and a conditional weak recovery statement in the idealized linear low-noise regime.
- Each source branch can be read as an independent explanatory factor, opening a route to structured latent modeling beyond classical signal separation.
Where Pith is reading between the lines
- The per-dimension diffusion design may generalize to other modalities such as images or graphs if suitable structured priors are substituted for the Gaussian process.
- The coupling between source recovery and prior adaptation could be tested by ablating the prior strength and checking whether trajectory coherence collapses.
- If the framework scales to high-dimensional data, it might provide a practical route toward identifiable nonlinear representation learning under explicit structural assumptions.
Load-bearing premise
Assigning a separate adaptive reverse diffusion process to each latent dimension is sufficient to disentangle and recover the underlying sources without any labels or additional post-processing.
What would settle it
Running the model on synthetic linear mixtures with known ground-truth sources and measuring that the recovered trajectories show high mean-squared error relative to the originals would falsify the direct recovery claim.
Figures




read the original abstract
This paper presents StrADiff, a Structured Source-Wise Adaptive Diffusion Framework for unsupervised blind source separation under linear and nonlinear mixing. The framework treats each latent dimension as a source branch and assigns to it an individual adaptive reverse diffusion mechanism, so that latent sources are recovered directly from observed mixtures through a single end-to-end objective, without supervised source labels or separate post-processing. Source-wise generation, structural regularization, and observation-space reconstruction are optimized jointly during training. In this instantiation, a Gaussian process (GP) prior is used as one example of a source-wise structured prior to impose temporal organization on each recovered trajectory; the framework itself is not restricted to GP priors and can in principle incorporate other structured priors. Theoretical components clarify the induced pushforward source law, the sample-level role of the structured prior, the coupling between source recovery and prior adaptation, and a conditional weak recovery statement in an idealized linear low-noise regime. Experiments on linear and nonlinear mixtures show that StrADiff can recover meaningful latent source trajectories in an unsupervised manner, with particularly stable performance in the linear case and moderate degradation under nonlinear mixing. Beyond classical signal separation, a source branch may also be interpreted as an independent, disentangled, or otherwise interpretable explanatory factor under suitable structural assumptions, suggesting a broader route toward structured latent modeling and future identifiable nonlinear representation learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes StrADiff, a structured source-wise adaptive diffusion framework for unsupervised blind source separation under both linear and nonlinear mixing. Each latent dimension is treated as a source branch with its own adaptive reverse diffusion process; these are jointly optimized with a structured prior (exemplified by a Gaussian process) via a single end-to-end objective that performs source recovery, structural regularization, and observation-space reconstruction without supervised labels or post-processing. Theoretical elements address the induced pushforward source law, the sample-level role of the prior, recovery-prior coupling, and a conditional weak recovery result in the idealized linear low-noise regime. Experiments on linear and nonlinear mixtures indicate that meaningful latent trajectories can be recovered, with stable performance in the linear case and moderate degradation under nonlinear mixing.
Significance. If the claims hold, the work offers a new route for unsupervised source separation by combining per-source adaptive diffusion with structured priors, potentially extending classical BSS methods and supporting broader structured latent modeling. The joint optimization of generation, regularization, and reconstruction in a diffusion setting is a technically interesting direction, and the explicit separation of the general framework from the GP instantiation is a positive design choice.
major comments (2)
- [Theoretical components] The conditional weak recovery statement is supplied only for an idealized linear low-noise regime; no analogous identifiability argument or recovery guarantee is provided for the nonlinear mixing case, which is central to the manuscript's claim of applicability to both linear and nonlinear mixtures.
- [Experiments] The experimental evaluation reports qualitative recovery of trajectories but supplies no quantitative metrics, baseline comparisons, ablation studies, or error analysis, preventing assessment of whether the observed performance constitutes a meaningful advance over existing BSS techniques.
minor comments (1)
- [Abstract] The abstract would benefit from a clearer demarcation between the general StrADiff framework and the specific GP-prior instantiation to prevent readers from conflating the two.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating where revisions will be made to improve clarity and rigor while honestly noting limitations that cannot be fully resolved within the current scope.
read point-by-point responses
-
Referee: [Theoretical components] The conditional weak recovery statement is supplied only for an idealized linear low-noise regime; no analogous identifiability argument or recovery guarantee is provided for the nonlinear mixing case, which is central to the manuscript's claim of applicability to both linear and nonlinear mixtures.
Authors: We agree that the provided conditional weak recovery result applies only to the idealized linear low-noise setting. Deriving an analogous guarantee for nonlinear mixing is substantially more difficult due to the lack of general identifiability results for nonlinear BSS and the added complexity of the diffusion-based recovery mechanism. In the revision we will explicitly delimit the scope of the theoretical claims, state that nonlinear applicability rests on empirical evidence, and add a brief discussion of the challenges in extending the analysis. We cannot supply a full nonlinear recovery guarantee at this time. revision: partial
-
Referee: [Experiments] The experimental evaluation reports qualitative recovery of trajectories but supplies no quantitative metrics, baseline comparisons, ablation studies, or error analysis, preventing assessment of whether the observed performance constitutes a meaningful advance over existing BSS techniques.
Authors: We accept this criticism. The current experiments focus on qualitative trajectory recovery. We will augment the experimental section with quantitative metrics (e.g., mean squared error and Pearson correlation on recovered sources), comparisons to standard baselines including linear ICA, kernel ICA, and other nonlinear BSS approaches, ablation studies isolating the contributions of the source-wise adaptive diffusion and the GP prior, and error analysis across noise levels and degrees of nonlinearity. These additions will be included in the revised manuscript. revision: yes
- Providing a recovery or identifiability guarantee for the nonlinear mixing case
Circularity Check
No significant circularity; derivation is self-contained via explicit model definition and joint optimization
full rationale
The paper defines StrADiff explicitly as a framework assigning per-source adaptive reverse diffusion branches plus a structured prior (e.g., GP), then optimizes a single end-to-end objective combining generation, regularization, and reconstruction. The conditional weak recovery statement is restricted to an idealized linear low-noise regime and is presented as a derived property of that setup rather than a tautology. No step reduces a claimed prediction or uniqueness result to a fitted parameter or self-citation by construction; the nonlinear claims rest on empirical behavior rather than an unverified identifiability theorem. The derivation chain therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A Gaussian process prior imposes useful temporal organization on each recovered source trajectory.
- domain assumption The induced pushforward source law and conditional weak recovery statement hold in an idealized linear low-noise regime.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 2.9 (Weak recovery in the linear low-noise limit)... conditional weak recovery statement in an idealized linear low-noise regime
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
source-wise Gaussian process prior... length-scale ℓ_k... Lprior = 1/2Tn Σ [T log(2π) + log|K(k)| + s(k)⊤K(k)−1 s(k)]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
StrEBM: A Structured Latent Energy-Based Model for Blind Source Separation
StrEBM applies source-wise Gaussian-process-inspired energies with learnable length-scales to jointly optimize latent trajectories and observation mappings for recovering components from linear and nonlinear mixtures.
Reference graph
Works this paper leans on
-
[1]
Understanding disentangling in $\beta$-VAE
Burgess, C. P., Higgins, I., Pal, A., Matthey, L., Watters, N., Desjardins, G., and Lerchner, A. (2018). Understanding disentangling inβ-vae.arXiv preprint arXiv:1804.03599
work page Pith review arXiv 2018
-
[2]
Chung, H., Kim, J., McCann, M. T., Klasky, M. L., and Ye, J. C. (2023). Diffusion posterior sampling for general noisy inverse problems. InInternational Conference on Learning Representations. Hälvä, H. and Hyvärinen, A. (2020). Hidden markov nonlinear ICA: Unsupervised learning from non- stationary time series. InProceedings of the 36th Conference on Unc...
work page 2023
-
[3]
Ho, J., Jain, A., and Abbeel, P. (2020). Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems, volume 33, pages 6840–6851
work page 2020
-
[4]
Hill, F., and Lerchner, A. (2024). Soda: Bottleneck diffusion models for representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23115– 23127. Hyvärinen, A., Khemakhem, I., and Morioka, H. (2023). Nonlinear independent component analysis for principled disentanglement in unsupervised deep learni...
work page 2024
-
[5]
Jayaram, V. and Thickstun, J. (2020). Source separation with deep generative priors. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 4724–4735. PMLR
work page 2020
-
[6]
Jayashankar, T., Lee, G. C. F., Lancho, A., Weiss, A., Polyanskiy, Y., and Wornell, G. W. (2023). Score- based source separation with applications to digital communication signals
work page 2023
-
[7]
Jun, Y., Park, J., Choo, K., Choi, T. E., and Hwang, S. J. (2025). Disentangling disentangled representa- tions: Towards improved latent units via diffusion models. InProceedings of the Winter Conference on Applications of Computer Vision, pages 3559–3569
work page 2025
-
[8]
Khemakhem, I., Kingma, D. P., Monti, R. P., and Hyvärinen, A. (2020). Variational autoencoders and nonlinear ICA: A unifying framework. InProceedings of the 23rd International Conference on Artificial Intelligence and Statistics, volume 108 ofProceedings of Machine Learning Research, pages 2207–2217. PMLR
work page 2020
-
[9]
Kivva, B., Rajendran, G., Ravikumar, P., and Aragam, B. (2022). Identifiability of deep generative models without auxiliary information. InAdvances in Neural Information Processing Systems, volume 35, pages 15687–15701
work page 2022
-
[10]
Preechakul, K., Chatthee, N., Wizadwongsa, S., and Suwajanakorn, S. (2022). Diffusion autoencoders: Toward a meaningful and decodable representation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10619–10629. 21 StrADiff: A Structured Source-Wise Adaptive Diffusion Framework for Linear and Nonlinear Blind Sourc...
work page 2022
-
[11]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695
work page 2022
-
[12]
Scheibler, R., Hershey, J. R., Doucet, A., and Li, H. (2025). Source separation by flow matching
work page 2025
-
[13]
Song, J., Vahdat, A., Mardani, M., Kautz, J., and Ermon, S. (2022). Solving inverse problems in medical imaging with score-based generative models. InInternational Conference on Learning Representations
work page 2022
-
[14]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., and Poole, B. (2021b). Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[15]
Wagner-Carena, S., Akhmetzhanova, A., and Erickson, S. (2025). A data-driven prism: Multi-view source separation with diffusion model priors. NeurIPS 2025 poster, OpenReview
work page 2025
-
[16]
Glass, J. R. (2025). Can diffusion models disentangle? a theoretical perspective. NeurIPS 2025 poster, OpenReview
work page 2025
-
[17]
Wei, Y. et al. (2024). Innovative blind source separation techniques combining gaussian process algorithms and variational autoencoders with applications in structural health monitoring
work page 2024
-
[18]
Wei, Y.-H. and Sun, Y.-J. (2026). Pdgmm-vae: A variational autoencoder with adaptive per-dimension gaussian mixture model priors for nonlinear ica.arXiv preprint arXiv:2603.23547
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Xiang, W., Yang, H., Huang, D., and Wang, Y. (2023). Denoising diffusion autoencoders are unified self- supervised learners. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15802–15812
work page 2023
-
[20]
Xu, Z., Fan, X., Wang, Z.-Q., Jiang, X., and Roy Choudhury, R. (2025). Arraydps: Unsupervised blind speech separation with a diffusion prior. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 69160–69188. PMLR
work page 2025
-
[21]
Yang, T., Lan, C., Lu, Y., and Zheng, N. (2024). Diffusion model with cross attention as an inductive bias for disentanglement. InAdvances in Neural Information Processing Systems, volume 37, pages 82465–82492
work page 2024
-
[22]
Yang, T., Wang, Y., Lu, Y., and Zheng, N. (2023). Disdiff: Unsupervised disentanglement of diffusion probabilistic models. NeurIPS 2023 poster, OpenReview. 22
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.