Recognition: no theorem link
DecepGPT: Schema-Driven Deception Detection with Multicultural Datasets and Robust Multimodal Learning
Pith reviewed 2026-05-15 01:05 UTC · model grok-4.3
The pith
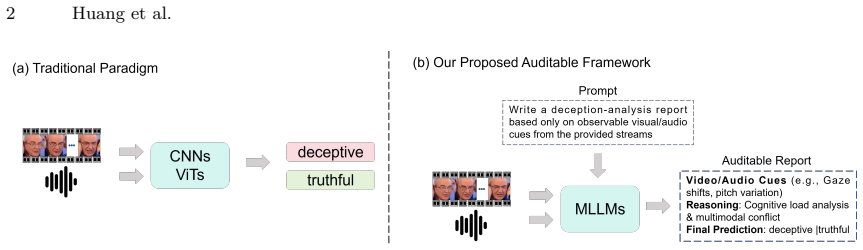
DecepGPT augments existing deception benchmarks with cue descriptions and reasoning chains, adds a large multicultural dataset, and introduces two modules to reach state-of-the-art detection that transfers across domains and cultures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By converting binary-labeled deception videos into schema-augmented datasets that contain cue descriptions and explicit reasoning chains, and by training with Stabilized Individuality-Commonality Synergy plus Distilled Modality Consistency on the new T4-Deception collection, the method produces verifiable multimodal predictions that outperform prior work in both in-domain accuracy and cross-domain generalization across cultural contexts.
What carries the argument
Stabilized Individuality-Commonality Synergy (SICS) that combines learnable global priors with sample-adaptive residuals followed by polarity-aware recalibration, together with Distilled Modality Consistency (DMC) that uses knowledge distillation to align unimodal and fused predictions.
If this is right
- Models can output auditable step-by-step reports instead of opaque binary decisions in security and legal settings.
- Training on the multicultural T4-Deception set reduces reliance on culture-specific shortcuts.
- The two modules stabilize learning when labeled deception data remain scarce.
- Cross-domain transfer improves without requiring new labeled samples from every target domain.
- Knowledge-distillation alignment discourages any single modality from dominating the final prediction.
Where Pith is reading between the lines
- The same cue-augmentation pattern could be applied to other high-stakes multimodal tasks such as medical diagnosis or misinformation detection to increase explainability.
- If the reasoning chains prove robust, they could serve as supervision for smaller models in resource-constrained environments.
- Real-world deployment would still require testing on continuous video streams rather than the short clips used here.
Load-bearing premise
The manually supplied cue descriptions and reasoning chains added to the datasets accurately reflect real deception signals rather than annotator bias or post-hoc justification.
What would settle it
Re-train the same architecture on the original unaugmented benchmarks without the added cue descriptions and reasoning chains, then measure whether cross-domain and cross-cultural accuracy drops to the level of prior methods.
Figures







read the original abstract
Multimodal deception detection aims to identify deceptive behavior by analyzing audiovisual cues for forensics and security. In these high-stakes settings, investigators need verifiable evidence connecting audiovisual cues to final decisions, along with reliable generalization across domains and cultural contexts. However, existing benchmarks provide only binary labels without intermediate reasoning cues. Datasets are also small with limited scenario coverage, leading to shortcut learning. We address these issues through three contributions. First, we construct reasoning datasets by augmenting existing benchmarks with structured cue-level descriptions and reasoning chains, enabling model output auditable reports. Second, we release T4-Deception, a multicultural dataset based on the unified ``To Tell The Truth'' television format implemented across four countries. With 1695 samples, it is the largest non-laboratory deception detection dataset. Third, we propose two modules for robust learning under small-data conditions. Stabilized Individuality-Commonality Synergy (SICS) refines multimodal representations by synergizing learnable global priors with sample-adaptive residuals, followed by a polarity-aware adjustment that bi-directionally recalibrates representations. Distilled Modality Consistency (DMC) aligns modality-specific predictions with the fused multimodal predictions via knowledge distillation to prevent unimodal shortcut learning. Experiments on three established benchmarks and our novel dataset demonstrate that our method achieves state-of-the-art performance in both in-domain and cross-domain scenarios, while exhibiting superior transferability across diverse cultural contexts. The datasets and codes will be released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DecepGPT, a multimodal deception detection framework that augments existing benchmarks with manually constructed cue-level descriptions and reasoning chains for auditable outputs, releases the T4-Deception multicultural dataset (1695 samples across four countries in a unified 'To Tell The Truth' format), and proposes two modules—Stabilized Individuality-Commonality Synergy (SICS) for refining multimodal representations via global priors and adaptive residuals, and Distilled Modality Consistency (DMC) for aligning unimodal and fused predictions via knowledge distillation. It claims state-of-the-art in-domain and cross-domain performance with superior cultural transferability on three established benchmarks plus the new dataset.
Significance. If the manual cue annotations are shown to capture reproducible deception signals independent of annotator bias and the performance claims are supported by ablations and metrics, the work would advance verifiable, generalizable deception detection by addressing binary-label limitations and shortcut learning, while providing the largest non-laboratory multicultural dataset for the field.
major comments (1)
- [§3] §3 (Dataset Construction): The augmentation of benchmarks with structured cue-level descriptions and reasoning chains is presented as the first contribution enabling auditable reports, yet no inter-annotator agreement scores, expert validation, or ablation results (e.g., performance with vs. without the added chains on original binary labels) are reported. This is load-bearing for the SOTA and cross-cultural transfer claims, as the SICS/DMC modules and T4-Deception results may simply reproduce the annotation schema rather than independent audiovisual signals.
minor comments (2)
- [Abstract] The abstract asserts SOTA performance without any quantitative metrics, error bars, or implementation details; these should be summarized upfront even if detailed in §4.
- [§4] Notation for SICS (e.g., the polarity-aware adjustment) and DMC (distillation loss) could be clarified with explicit equations in §4 to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback, particularly on the dataset construction. We address the concern point by point below and will incorporate the suggested validations in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Dataset Construction): The augmentation of benchmarks with structured cue-level descriptions and reasoning chains is presented as the first contribution enabling auditable reports, yet no inter-annotator agreement scores, expert validation, or ablation results (e.g., performance with vs. without the added chains on original binary labels) are reported. This is load-bearing for the SOTA and cross-cultural transfer claims, as the SICS/DMC modules and T4-Deception results may simply reproduce the annotation schema rather than independent audiovisual signals.
Authors: We agree that the absence of reported inter-annotator agreement (IAA) scores, expert validation details, and targeted ablations weakens the substantiation of the cue-augmentation contribution. The cue-level descriptions and reasoning chains were constructed by trained annotators following a protocol derived from established deception literature (e.g., verbal and nonverbal cue taxonomies), but these details and metrics were omitted from the initial submission. In the revised manuscript we will add: (1) IAA scores (Cohen’s kappa and percentage agreement) computed across multiple annotators for both cue descriptions and reasoning chains; (2) a brief description of the annotation guidelines and any expert review performed; and (3) ablation experiments that train and evaluate the full SICS+DMC pipeline on the original binary labels versus the augmented reasoning-chain versions of the same benchmarks. These results will isolate whether performance gains derive from audiovisual signals or merely from the annotation schema, directly addressing the load-bearing concern for the reported SOTA and cross-cultural transfer claims. revision: yes
Circularity Check
No circularity; empirical claims rest on independent dataset evaluations
full rationale
The paper constructs augmented reasoning datasets via manual cue annotations and introduces SICS and DMC modules for multimodal fusion, then reports SOTA results on three benchmarks plus the new T4-Deception dataset. No equations, derivations, or fitted parameters are shown that reduce by construction to the inputs. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of known results occurs. The central performance and transferability claims are supported by cross-dataset experiments rather than self-referential definitions, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deception detection using real-life trial data
Ver´ onica P´ erez-Rosas, Mohamed Abouelenien, Rada Mihalcea, and Mihai Burzo. Deception detection using real-life trial data. InProceedings of the 2015 ACM on international conference on multimodal interaction, pages 59–66, 2015
2015
-
[2]
Audio-visual deception detection: Dolos dataset and parameter-efficient crossmodal learning
Xiaobao Guo, Nithish Muthuchamy Selvaraj, Zitong Yu, Adams Wai-Kin Kong, Bingquan Shen, and Alex Kot. Audio-visual deception detection: Dolos dataset and parameter-efficient crossmodal learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22135–22145, 2023
2023
-
[3]
Accuracy of deception judgments.Personality and social psychology Review, 10(3):214–234, 2006
Charles F Bond Jr and Bella M DePaulo. Accuracy of deception judgments.Personality and social psychology Review, 10(3):214–234, 2006
2006
-
[4]
Verbal and nonverbal clues for real-life deception detection
Ver´ onica P´ erez-Rosas, Mohamed Abouelenien, Rada Mihalcea, Yao Xiao, CJ Linton, and Mihai Burzo. Verbal and nonverbal clues for real-life deception detection. InProceedings of the 2015 conference on empirical methods in natural language processing, pages 2336–2346, 2015
2015
-
[5]
Facialcuenet: unmasking deception-an interpretable model for criminal interrogation using facial expressions: Iy kim et al.Applied Intelligence, 53(22):27413– 27427, 2023
Borum Nam, Joo Young Kim, Beomjun Bark, Yeongmyeong Kim, Jiyoon Kim, Soon Won So, Hyung Youn Choi, and In Young Kim. Facialcuenet: unmasking deception-an interpretable model for criminal interrogation using facial expressions: Iy kim et al.Applied Intelligence, 53(22):27413– 27427, 2023
2023
-
[6]
Cross-cultural deception detection
Ver´ onica P´ erez-Rosas and Rada Mihalcea. Cross-cultural deception detection. InProceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 440–445, 2014
2014
-
[7]
Bag-of-lies: A multimodal dataset for deception detection
Viresh Gupta, Mohit Agarwal, Manik Arora, Tanmoy Chakraborty, Richa Singh, and Mayank Vatsa. Bag-of-lies: A multimodal dataset for deception detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 1–8, 2019
2019
-
[8]
Shortcut learning in deep neural networks.Nature Machine Intelli- gence, 2(11):665–673
Robert Geirhos, J¨ orn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. Shortcut learning in deep neural networks.Nature Machine Intelli- gence, 2(11):665–673
-
[9]
Deception detection in videos
Zhe Wu, Bharat Singh, Larry Davis, and V Subrahmanian. Deception detection in videos. InProceed- ings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[10]
Benchmarking cross-domain audio-visual deception detection.arXiv preprint arXiv:2405.06995, 2024
Xiaobao Guo, Zitong Yu, Nithish Muthuchamy Selvaraj, Bingquan Shen, Adams Wai-Kin Kong, and Alex C Kot. Benchmarking cross-domain audio-visual deception detection.arXiv preprint arXiv:2405.06995, 2024
-
[11]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. volume 36, pages 34892–34916, 2023
2023
-
[12]
Hidden in plain sight: Evaluation of the deception detection capabilities of llms in multimodal settings
Md Messal Monem Miah, Adrita Anika, Xi Shi, and Ruihong Huang. Hidden in plain sight: Evaluation of the deception detection capabilities of llms in multimodal settings. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 31013–31034, 2025
2025
-
[13]
Misa: Modality-invariant and-specific representations for multimodal sentiment analysis
Devamanyu Hazarika, Roger Zimmermann, and Soujanya Poria. Misa: Modality-invariant and-specific representations for multimodal sentiment analysis. InProceedings of the 28th ACM international conference on multimedia, pages 1122–1131, 2020
2020
-
[14]
Domain separation networks.Advances in neural information processing systems, 29, 2016
Konstantinos Bousmalis, George Trigeorgis, Nathan Silberman, Dilip Krishnan, and Dumitru Erhan. Domain separation networks.Advances in neural information processing systems, 29, 2016. DecepGPT 13
2016
-
[15]
Learning discriminative multi- relation representations for multimodal sentiment analysis.Information Sciences, 641:119125, 2023
Zemin Tang, Qi Xiao, Xu Zhou, Yangfan Li, Cen Chen, and Kenli Li. Learning discriminative multi- relation representations for multimodal sentiment analysis.Information Sciences, 641:119125, 2023
2023
-
[16]
Gated Multimodal Units for Information Fusion
John Arevalo, Thamar Solorio, Manuel Montes-y G´ omez, and Fabio A Gonz´ alez. Gated multimodal units for information fusion.arXiv preprint arXiv:1702.01992, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Balanced multimodal learning via on-the-fly gradient modulation
Xiaokang Peng, Yake Wei, Andong Deng, Dong Wang, and Di Hu. Balanced multimodal learning via on-the-fly gradient modulation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8238–8247, 2022
2022
-
[18]
Moddrop: adaptive multi- modal gesture recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(8):1692–1706, 2015
Natalia Neverova, Christian Wolf, Graham Taylor, and Florian Nebout. Moddrop: adaptive multi- modal gesture recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(8):1692–1706, 2015
2015
-
[19]
Adaptive unimodal regulation for balanced multimodal information acquisition
Chengxiang Huang, Yake Wei, Zequn Yang, and Di Hu. Adaptive unimodal regulation for balanced multimodal information acquisition. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 25854–25863, 2025
2025
-
[20]
Miami university deception detection database.Behavior research methods, 51(1):429–439, 2019
E Paige Lloyd, Jason C Deska, Kurt Hugenberg, Allen R McConnell, Brandon T Humphrey, and Jonathan W Kunstman. Miami university deception detection database.Behavior research methods, 51(1):429–439, 2019
2019
-
[21]
Deception detection and remote physiological monitoring: A dataset and baseline experimental results
Jeremy Speth, Nathan Vance, Adam Czajka, Kevin W Bowyer, Diane Wright, and Patrick Flynn. Deception detection and remote physiological monitoring: A dataset and baseline experimental results. In2021 IEEE International Joint Conference on Biometrics, pages 1–8, 2021
2021
-
[22]
Box of lies: Multimodal deception detection in dialogues
Felix Soldner, Ver´ onica P´ erez-Rosas, and Rada Mihalcea. Box of lies: Multimodal deception detection in dialogues. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 1768–1777, 2019
2019
-
[23]
Zheng Lian, Haiyang Sun, Licai Sun, Jiangyan Yi, Bin Liu, and Jianhua Tao. Affectgpt: Dataset and framework for explainable multimodal emotion recognition.arXiv preprint arXiv:2407.07653, 2024
-
[24]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InInternational conference on machine learning, pages 28492–28518, 2023
2023
-
[25]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763, 2021
2021
-
[26]
Mer 2024: Semi-supervised learning, noise robustness, and open- vocabulary multimodal emotion recognition
Zheng Lian, Haiyang Sun, Licai Sun, Zhuofan Wen, Siyuan Zhang, Shun Chen, Hao Gu, Jinming Zhao, Ziyang Ma, Xie Chen, et al. Mer 2024: Semi-supervised learning, noise robustness, and open- vocabulary multimodal emotion recognition. InProceedings of the 2nd International Workshop on Multimodal and Responsible Affective Computing, pages 41–48, 2024
2024
-
[27]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Os- trow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms.arXiv preprint arXiv:2406.07476, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Lienet: a deep convolution neural network framework for detecting deception.IEEE transactions on cognitive and developmental systems, 14(3):971–984, 2021
Mohan Karnati, Ayan Seal, Anis Yazidi, and Ondrej Krejcar. Lienet: a deep convolution neural network framework for detecting deception.IEEE transactions on cognitive and developmental systems, 14(3):971–984, 2021
2021
-
[31]
Affakt: A hierarchical optimal transport based method for affective facial knowledge transfer in video deception detection
Zihan Ji, Xuetao Tian, and Ye Liu. Affakt: A hierarchical optimal transport based method for affective facial knowledge transfer in video deception detection. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 1336–1344, 2025
2025
-
[32]
Changli Tang, Yixuan Li, Yudong Yang, Jimin Zhuang, Guangzhi Sun, Wei Li, Zejun Ma, and Chao Zhang. video-salmonn 2: Caption-enhanced audio-visual large language models.arXiv preprint arXiv:2506.15220, 2025
-
[33]
Mlp-mixer: An all-mlp architecture for vision.Advances in neural information processing systems, 34:24261–24272, 2021
Ilya O Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Un- terthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, et al. Mlp-mixer: An all-mlp architecture for vision.Advances in neural information processing systems, 34:24261–24272, 2021
2021
-
[34]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 14 Huang et al. Appendix A Comprehensive Analysis of T4-Deception Fig. A1: Cross-cultural distribu- tion of deceptive signatures across 10 behavi...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.