Recognition: no theorem link
A Lightweight High-Throughput Collective-Capable NoC for Large-Scale ML Accelerators
Pith reviewed 2026-05-14 22:29 UTC · model grok-4.3
The pith
A NoC with direct compute access to cores accelerates multicast by 5.3x and reductions by 2.8x for ML accelerators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors show that a collective-capable NoC built around Direct Compute Access delivers 5.3x geomean speedup on multicast and 2.8x on reduction for payloads between 1 and 32 KiB, translating into estimated 3.8x and 2.4x overall performance gains plus 1.17x energy savings in GEMM workloads on large meshes, all at a 16.9 percent router-area cost compared with a baseline unicast design.
What carries the argument
Direct Compute Access (DCA), a mechanism that grants the interconnect fabric direct access to the cores' computational resources so reductions can be executed inside the network with high throughput.
Load-bearing premise
That the 16.9 percent router area overhead stays acceptable and that in-network reductions introduce neither new pipeline stalls nor coherence problems when used inside full GEMM workloads on large meshes.
What would settle it
End-to-end latency and energy measurements of complete GEMM workloads executed on a large-mesh simulator or prototype that includes the new NoC versus an otherwise identical baseline that uses only unicast traffic.
Figures



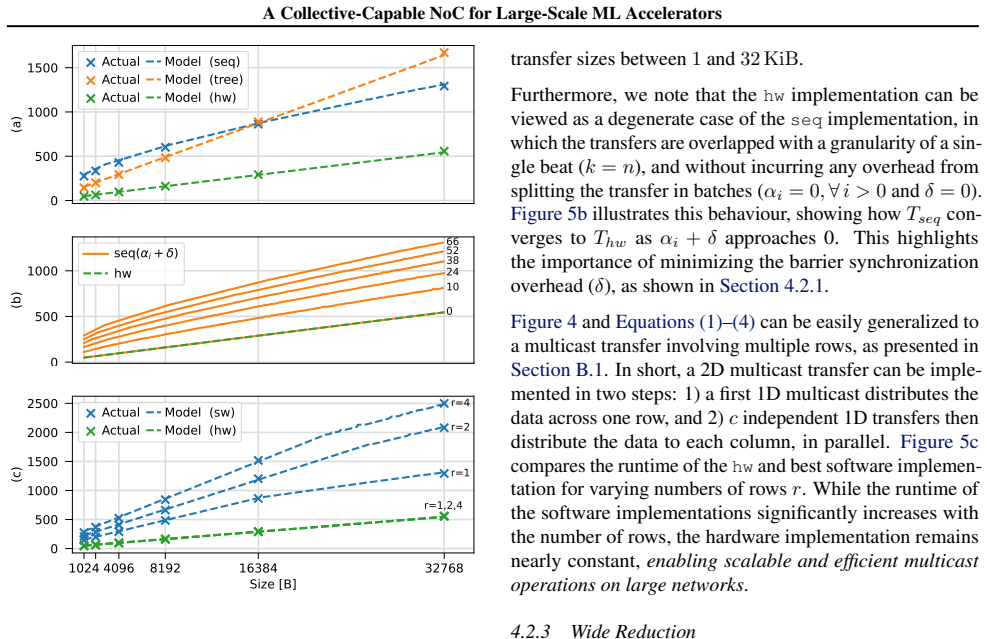









read the original abstract
The exponential increase in Machine Learning (ML) model size and complexity has driven unprecedented demand for high-performance acceleration systems. As technology scaling enables the integration of thousands of computing elements onto a single die, the boundary between distributed and on-chip systems has blurred, making efficient on-chip collective communication increasingly critical. In this work, we present a lightweight, collective-capable Network on Chip (NoC) that supports efficient barrier synchronization alongside scalable, high-bandwidth multicast and reduction operations, co-designed for the next generation of ML accelerators. We introduce Direct Compute Access (DCA), a novel paradigm that grants the interconnect fabric direct access to the cores' computational resources, enabling high-throughput in-network reductions with a small 16.9% router area overhead. Through in-network hardware acceleration, we achieve 5.3x and 2.8x geomean speedups on multicast and reduction operations involving between 1 and 32 KiB of data, respectively. Furthermore, by keeping communication off the critical path in GEMM workloads, these features allow our architecture to scale efficiently to large meshes, resulting in up to 3.8x and 2.4x estimated performance gains through multicast and reduction support, respectively, compared to a baseline unicast NoC architecture, and up to 1.17x estimated energy savings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a lightweight collective-capable NoC for large-scale ML accelerators, introducing Direct Compute Access (DCA) to enable high-throughput in-network multicast, reduction, and barrier operations with a reported 16.9% router area overhead. It claims geomean speedups of 5.3x on multicast and 2.8x on reduction for 1-32 KiB data sizes, which translate to estimated GEMM performance gains of up to 3.8x and 2.4x respectively versus a unicast baseline, plus 1.17x energy savings, by keeping collectives off the critical path in large meshes.
Significance. If the off-critical-path assumption and translation from isolated collective benchmarks to full GEMM workloads hold, the work would offer a practical, low-overhead approach to scaling on-chip communication in thousand-core ML accelerators. The emphasis on hardware-accelerated collectives with quantified area cost addresses a timely bottleneck in distributed tensor computations.
major comments (2)
- [Abstract] Abstract: the headline 3.8x/2.4x GEMM gains and 1.17x energy savings rest on the unverified premise that DCA-enabled reductions can be overlapped with compute without pipeline stalls, coherence round-trips, or mesh-scale congestion; no cycle-accurate traces, barrier insertion analysis, or sensitivity results for >32x32 arrays are supplied to substantiate this.
- [Abstract] Abstract: the 5.3x multicast and 2.8x reduction geomean speedups are measured only on standalone 1-32 KiB collectives; without explicit methodology, error bars, or workload traces, it is impossible to assess how reduction completion latency interacts with GEMM tile scheduling.
minor comments (1)
- [Abstract] Abstract: simulation assumptions, baseline router configuration, mesh dimensions, and energy model details are omitted, making the reported numbers difficult to reproduce or compare.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the concerns regarding the abstract's performance claims and evaluation methodology below, providing clarifications while noting where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline 3.8x/2.4x GEMM gains and 1.17x energy savings rest on the unverified premise that DCA-enabled reductions can be overlapped with compute without pipeline stalls, coherence round-trips, or mesh-scale congestion; no cycle-accurate traces, barrier insertion analysis, or sensitivity results for >32x32 arrays are supplied to substantiate this.
Authors: The GEMM gains are estimates obtained by combining measured collective latencies with an analytical model of tile scheduling that assumes overlap is feasible. DCA is explicitly designed to enable this overlap by granting the NoC direct access to compute units for in-network reductions, avoiding core stalls and keeping collectives off the critical path. We agree that additional validation would be beneficial and will incorporate cycle-accurate simulation traces, barrier insertion analysis, and sensitivity results for meshes up to 64x64 in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the 5.3x multicast and 2.8x reduction geomean speedups are measured only on standalone 1-32 KiB collectives; without explicit methodology, error bars, or workload traces, it is impossible to assess how reduction completion latency interacts with GEMM tile scheduling.
Authors: The reported geomean speedups come from cycle-accurate NoC simulations of standalone multicast and reduction operations across 1-32 KiB data sizes, with the full simulation methodology and configuration details provided in the Evaluation section. We will revise the manuscript to add error bars to the speedup figures, expand the explicit methodology description, and include a clearer discussion of how the measured latencies map to GEMM tile scheduling under the non-blocking collective assumption. Full end-to-end workload traces are outside the paper's primary scope on NoC microarchitecture but can be referenced via the analytical model. revision: partial
Circularity Check
No circularity: empirical hardware measurements and estimates stand independently
full rationale
This is a hardware architecture paper presenting a NoC design with Direct Compute Access for collectives. All headline claims (5.3x/2.8x geomean speedups on 1-32 KiB collectives, 3.8x/2.4x estimated GEMM gains, 1.17x energy savings, 16.9% router area overhead) are presented as direct outcomes of RTL simulation, synthesis, and workload modeling. No equations, fitted parameters, or self-citations are used to derive the performance numbers; the results are obtained by running the proposed hardware against a baseline unicast NoC on the same traffic patterns. The derivation chain is therefore self-contained and externally falsifiable via reproduction of the reported cycle counts and area numbers.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Direct Compute Access (DCA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Amdahl, G. M. Validity of the single processor approach to achieving large scale computing capabilities. InPro- ceedings of the April 18-20, 1967, Spring Joint Computer Conference, AFIPS ’67 (Spring), pp. 483–485, New York, NY , USA,
work page 1967
-
[2]
URL https://arxiv. org/abs/2512.17589. Dice, D. and Kogan, A. Optimizing inference performance of transformers on cpus. InProceedings of the 1st Work- shop on Machine Learning and Systems,
-
[3]
Feldmann, A., Golden, C., Yang, Y ., Emer, J. S., and Sanchez, D. Azul: An accelerator for sparse itera- tive solvers leveraging distributed on-chip memory. In 2024 57th IEEE/ACM International Symposium on Mi- croarchitecture (MICRO), pp. 643–656,
work page 2024
-
[4]
doi: 10.1109/MICRO61859.2024.00054. Firoozshahian, A., Coburn, J., Levenstein, R., Nattoji, R., Kamath, A., Wu, O., Grewal, G., Aepala, H., Jakka, B., Dreyer, B., Hutchin, A., Diril, U., Nair, K., Aredestani, E. K., Schatz, M., Hao, Y ., Komuravelli, R., Ho, K., Abu Asal, S., Shajrawi, J., Quinn, K., Sreedhara, N., Kansal, P., Wei, W., Jayaraman, D., Chen...
-
[5]
Power-efficient tree- based multicast support for Networks-on-Chip
Hu, W., Lu, Z., Jantsch, A., and Liu, H. Power-efficient tree- based multicast support for Networks-on-Chip. In16th Asia and South Pacific Design Automation Conference (ASP-DAC 2011), pp. 363–368,
work page 2011
-
[6]
Karami, R., Moar, C., Kao, S.-C., and Kwon, H. Nongemm bench: Understanding the performance horizon of the latest ml workloads with nongemm workloads.arXiv preprint arXiv:2404.11788,
-
[7]
doi: 10.1109/HPCA61900. 2025.00049. Lie, S. Wafer-scale AI: GPU impossible performance. In Proceedings of the 36th IEEE Hot Chips Symposium (HCS), pp. 1–71. IEEE,
-
[8]
NVIDIA Collective Communication Library (NCCL)
NVIDIA. NVIDIA Collective Communication Library (NCCL). https://developer.nvidia.com/nccl, 2024a. Ac- cessed: 2025-05-03. NVIDIA.NVIDIA Scalable Hierarchical Aggregation and Reduction Protocol (SHARP), Revision 3.9.0, 2024b. Ac- cessed: 2025-05-03. Ouyang, Y ., Tang, F., Hu, C., Zhou, W., and Wang, Q. MMNNN: A tree-based multicast mechanism for NoC- based...
work page 2025
-
[9]
Rodrigo, S., Flich, J., Duato, J., and Hummel, M
doi: 10.1109/MM.2024.3423692. Rodrigo, S., Flich, J., Duato, J., and Hummel, M. Efficient unicast and multicast support for CMPs. In2008 41st IEEE/ACM International Symposium on Microarchitec- ture, pp. 364–375,
-
[10]
https://www.synopsys.com/ implementation-and-signoff/rtl-synthesis-test/ fusion-compiler.html. Tirumala, A. and Wong, R. NVIDIA blackwell platform: Advancing generative AI and accelerated computing. In 2024 IEEE Hot Chips 36 Symposium (HCS), pp. 1–33,
work page 2024
-
[11]
Wang, L., Jin, Y ., Kim, H., and Kim, E. J. Recursive par- titioning multicast: A bandwidth-efficient routing for Networks-on-Chip. InProceedings of the 2009 3rd ACM/IEEE International Symposium on Networks-on- Chip, NOCS ’09, pp. 64–73, USA,
work page 2009
-
[12]
DeepOHeat: Operator Learning-based Ultra-fast Thermal Simulation in 3D-IC Design,
doi: 10.1109/DAC56929.2023.10247897. Yavits, L., Morad, A., and Ginosar, R. The effect of com- munication and synchronization on Amdahl’s law in mul- ticore systems.Parallel Comput., 40(1):1–16, January
-
[13]
is an on-chip communication protocol defined by Arm as part of the AMBA specification. It or- ganizes transactions into five independent channels: read address (AR), read data (R), write address (AW), write data (W), and write response (B), each using valid/ready hand- shaking. AXI supportsbursttransactions: a single address transaction (AR or AW) can be ...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.