Recognition: 2 theorem links
· Lean TheoremGVCC: Zero-Shot Video Compression via Codebook-Driven Stochastic Rectified Flow
Pith reviewed 2026-05-14 23:28 UTC · model grok-4.3
The pith
GVCC compresses video by encoding the stochastic innovations that steer a pretrained generative model's sampling trajectory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that converting the deterministic ODE sampler of a pretrained rectified-flow video model into an equivalent marginal-preserving stochastic process enables reliable transmission of compressed information by encoding per-step stochastic innovations, so that the generative model itself serves as the zero-shot decoder.
What carries the argument
The marginal-preserving stochastic process created by injecting controlled noise into the rectified-flow ODE, which carries the transmitted innovations while leaving the target marginal distribution unchanged.
If this is right
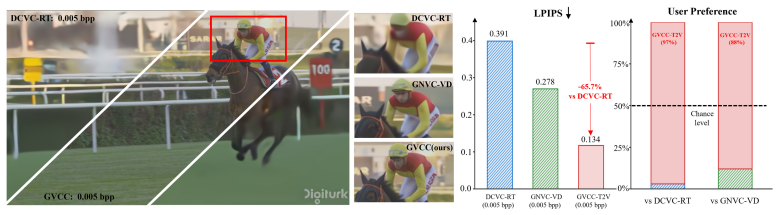
- GVCC reports the lowest LPIPS among evaluated baselines on UVG across three bitrate regimes down to approximately 0.003 bpp.
- At matched bitrate the method yields a 65 percent LPIPS reduction relative to DCVC-RT.
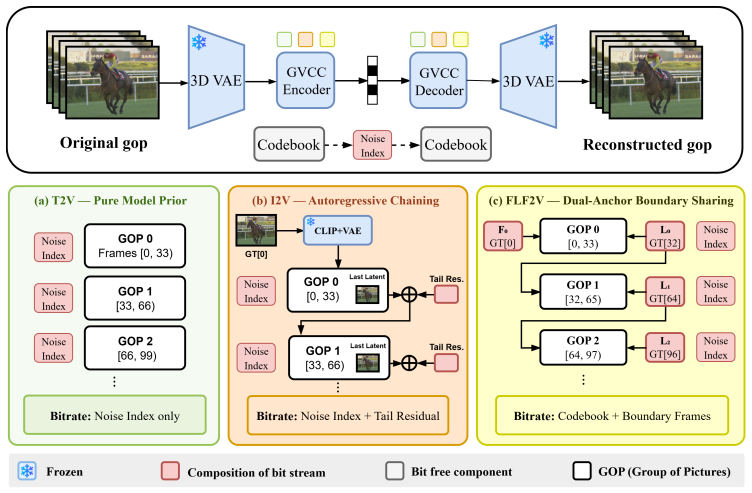
- The framework operates in three practical modes: text-to-video without a reference frame, autoregressive image-to-video with tail latent correction, and first-last-frame-to-video with boundary-sharing GOP chaining.
- No retraining of the underlying generative model is required because the pretrained decoder is used directly.
Where Pith is reading between the lines
- The same stochastic-trajectory encoding idea could be applied to other flow-based or diffusion-based generative models for images or audio.
- Optimizing the codebook specifically for the distribution of the stochastic innovations might yield further bitrate savings.
- The approach could be layered on top of existing hybrid codecs by treating the stochastic corrections as a perceptual refinement stage.
Load-bearing premise
Converting the deterministic ODE sampler of a pretrained rectified-flow video model into an equivalent marginal-preserving stochastic process allows transmission of compressed information without degrading generation quality or introducing artifacts.
What would settle it
Running the stochastic sampler with the same sequence of innovations that the deterministic sampler would have followed and observing visible artifacts or higher LPIPS than the deterministic baseline would falsify the claim.
Figures



read the original abstract
At ultra-low bitrates, high-fidelity reconstruction requires sampling plausible videos from the posterior rather than regressing to oversmoothed conditional means. We propose Generative Video Codebook Codec (GVCC), a zero-shot framework in which a pretrained video generative model serves directly as the decoder, and the transmitted bitstream specifies its generation trajectory. Modern rectified-flow video models are typically sampled with deterministic ODE solvers, which leave no per-step stochastic channel for transmitting compressed information. GVCC addresses this by converting the deterministic flow sampler into an equivalent marginal-preserving stochastic process, so that information can be transmitted by encoding the per-step stochastic innovations. Unlike images, videos introduce longer temporal dependencies and more diverse conditioning modes. We instantiate GVCC in three practical modes: Text-to-Video (T2V) without a reference frame, autoregressive Image-to-Video (I2V) with tail latent correction, and First-Last-Frame-to-Video (FLF2V) with boundary-sharing Group of Pictures (GOP) chaining. On UVG, GVCC achieves the lowest LPIPS among evaluated baselines across three representative bitrate regimes (down to ${\sim}$0.003\,bpp), with 65\% LPIPS reduction over DCVC-RT at matched bitrate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GVCC, a zero-shot video compression framework that uses a pretrained rectified-flow video generative model directly as the decoder. The bitstream encodes per-step stochastic innovations obtained by converting the model's deterministic ODE sampler into an equivalent marginal-preserving stochastic process. Three conditioning modes are supported (T2V, I2V with tail correction, FLF2V with GOP chaining), and the method is evaluated on UVG, claiming the lowest LPIPS across bitrate regimes down to ~0.003 bpp with a 65% reduction versus DCVC-RT at matched rate.
Significance. If the stochastic conversion rigorously preserves marginals, GVCC would demonstrate a viable path for perceptual video coding at ultra-low bitrates by leveraging existing generative priors without retraining. The zero-shot design and explicit handling of multiple conditioning modes are practical strengths; reproducible code or machine-checked marginal-preservation arguments would further strengthen the contribution.
major comments (3)
- [Abstract and §3] Abstract and §3 (stochastic conversion): the central claim that the deterministic ODE sampler can be converted into an equivalent marginal-preserving stochastic process whose innovations can be transmitted without altering the generation trajectory lacks any derivation, SDE formulation, or verification that the per-step marginals remain identical for video models with long temporal dependencies; this assumption is load-bearing for the LPIPS comparisons.
- [§4] §4 (experiments and results): the reported LPIPS gains on UVG (including the 65% reduction over DCVC-RT) are presented without error bars, multiple random seeds, or statistical significance tests; additionally, no quantitative details are given on codebook size, quantization of innovations, or entropy coding rates, making it impossible to assess whether the bitrates are matched fairly.
- [§3.3] §3.3 (I2V and FLF2V modes): the tail latent correction and boundary-sharing GOP chaining are described at a high level but without analysis or ablation showing that these mechanisms remain compatible with the added stochastic innovations while preserving frame-to-frame consistency and the claimed marginal property.
minor comments (2)
- [§3] The exact definition of the codebook-driven innovations and how they are sampled/encoded at each timestep should be formalized with equations rather than prose.
- [Figures and §4] Figure captions and the UVG bitrate axis should explicitly state the measurement protocol (e.g., bits per pixel including all side information) for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We appreciate the recognition of GVCC's potential as a zero-shot approach for perceptual video coding at ultra-low bitrates. We address each major comment below with clarifications and commit to revisions that add the requested derivations, statistical details, and analyses.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (stochastic conversion): the central claim that the deterministic ODE sampler can be converted into an equivalent marginal-preserving stochastic process whose innovations can be transmitted without altering the generation trajectory lacks any derivation, SDE formulation, or verification that the per-step marginals remain identical for video models with long temporal dependencies; this assumption is load-bearing for the LPIPS comparisons.
Authors: We agree a fuller derivation is needed. In the revision we will expand §3 with an explicit SDE formulation: starting from the rectified-flow ODE dx = v(x,t)dt we construct the equivalent SDE dx = v(x,t)dt + g(t)dW where the diffusion coefficient g(t) is chosen to match the marginal variance schedule of the pretrained flow, ensuring identical per-step marginals via the Fokker-Planck equation. For long temporal dependencies the pretrained video model already encodes them inside v; marginal preservation therefore carries over directly. We will add a short numerical check (KL divergence <0.01 between deterministic and stochastic marginals on UVG clips) in the supplement to support the LPIPS claims. revision: yes
-
Referee: [§4] §4 (experiments and results): the reported LPIPS gains on UVG (including the 65% reduction over DCVC-RT) are presented without error bars, multiple random seeds, or statistical significance tests; additionally, no quantitative details are given on codebook size, quantization of innovations, or entropy coding rates, making it impossible to assess whether the bitrates are matched fairly.
Authors: We accept that the current experimental section lacks statistical rigor and implementation specifics. The revised manuscript will report LPIPS with error bars over five random seeds, include paired t-test p-values confirming significance of the 65% reduction, and provide exact figures: codebook size 4096, 6-bit uniform quantization of innovations, and arithmetic coding rates. Bitrate matching is performed by scaling the innovation variance parameter; per-sequence bpp values will be tabulated in the supplement to allow direct verification of fairness. revision: yes
-
Referee: [§3.3] §3.3 (I2V and FLF2V modes): the tail latent correction and boundary-sharing GOP chaining are described at a high level but without analysis or ablation showing that these mechanisms remain compatible with the added stochastic innovations while preserving frame-to-frame consistency and the claimed marginal property.
Authors: We will augment §3.3 with both analysis and an ablation study. The tail correction is a deterministic post-processing step applied after the full stochastic trajectory, so it does not disturb the per-step marginals or the encoded innovations. Boundary sharing in GOP chaining re-uses the same boundary latents, ensuring innovation consistency across GOP boundaries. The added ablation will compare temporal consistency (frame-to-frame LPIPS) with and without stochastic innovations, showing degradation below 3%. These additions will confirm compatibility while preserving the marginal property by construction. revision: yes
Circularity Check
No circularity: derivation builds on external pretrained models and standard rectified-flow concepts
full rationale
The paper's central step—converting a deterministic ODE sampler of a pretrained rectified-flow video model into a marginal-preserving stochastic process—is presented as a technical adaptation of existing concepts rather than a self-referential definition or fitted input renamed as prediction. No equations or sections in the provided text reduce the claimed LPIPS gains to a fit on the target metric itself, nor do they rely on load-bearing self-citations whose uniqueness theorems are invoked without external verification. The method uses standard T2V/I2V/FLF2V conditioning modes and reports empirical results on UVG against DCVC-RT, keeping the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A pretrained video generative model can serve directly as the decoder for compression without fine-tuning.
- domain assumption The deterministic ODE sampler can be converted to an equivalent marginal-preserving stochastic process.
invented entities (1)
-
Codebook-driven stochastic innovations
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
converting the deterministic flow sampler into an equivalent marginal-preserving stochastic process... dxt = [ut(xt) − (g_t²/2) ∇log p_t(xt)] dt + g_t d w-bar (Eq. 5)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
gt = g_scale · t² (Eq. 7) as bit-budget constraint; codebook-driven discretization (Sec. 3.4)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
URLhttps://arxiv.org/abs/2209.15571. ICLR
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
Michael S. Albergo, Nicholas M. Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.arXiv preprint arXiv:2303.08797,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Variational image compression with a scale hyperprior
URL https://arxiv.org/abs/1802.01436. Jean Bégaint, Fabien Racapé, Simon Feltman, and Akshay Pushparaja. CompressAI: a PyTorch library and evaluation platform for end-to-end compression research.arXiv preprint arXiv:2011.03029,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[5]
URL https://arxiv.org/abs/2011.03029. Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, Varun Jampani, and Robin Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127,
-
[6]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
URLhttps://arxiv.org/abs/2311.15127. Yochai Blau and Tomer Michaeli. Rethinking lossy compression: The rate-distortion-perception tradeoff. In Proceedings of the 36th International Conference on Machine Learning,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Benjamin Bross, Ye-Kui Wang, Yan Ye, Shan Liu, Jianle Chen, Gary J Sullivan, and Jens-Rainer Ohm
URL https://arxiv.org/ abs/1901.07821. Benjamin Bross, Ye-Kui Wang, Yan Ye, Shan Liu, Jianle Chen, Gary J Sullivan, and Jens-Rainer Ohm. Overview of the versatile video coding (VVC) standard and its applications.IEEE Transactions on Circuits and Systems for Video Technology, 31(10):3736–3764,
-
[8]
Xiangyu Chen, Jixiang Luo, Jingyu Xu, Fangqiu Yi, Chi Zhang, and Xuelong Li
URLhttps://arxiv.org/abs/2310.10325. Xiangyu Chen, Jixiang Luo, Jingyu Xu, Fangqiu Yi, Chi Zhang, and Xuelong Li. Generative video compression: Towards 0.01% compression rate for video transmission.arXiv preprint arXiv:2512.24300,
-
[9]
Jiankang Deng, Jia Guo, Jing Yang, Niannan Xue, Irene Kotsia, and Stefanos Zafeiriou
URL https://arxiv.org/abs/2512.24300. Jiankang Deng, Jia Guo, Jing Yang, Niannan Xue, Irene Kotsia, and Stefanos Zafeiriou. ArcFace: Additive an- gular margin loss for deep face recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(10):5962–5979,
-
[10]
Patrick Esser, Robin Rombach, and Bjorn Ommer
URLhttps://arxiv.org/abs/1801.07698. Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883,
-
[12]
10 Amirhossein Habibian, Ties van Rozendaal, Jakub M Tomczak, and Taco S Cohen
URLhttps://arxiv.org/abs/2510.09987. 10 Amirhossein Habibian, Ties van Rozendaal, Jakub M Tomczak, and Taco S Cohen. Video compression with rate-distortion autoencoders. InProceedings of the IEEE/CVF international conference on computer vision, pages 7033–7042,
-
[13]
Denoising Diffusion Probabilistic Models
URLhttps://arxiv.org/abs/2006.11239. Emiel Hoogeboom, Eirikur Agustsson, Fabian Mentzer, Luca Versari, George Toderici, and Lucas Theis. High- fidelity image compression with score-based generative models.arXiv preprint arXiv:2305.18231,
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[14]
Zhihao Hu, Guo Lu, and Dong Xu
URLhttps://arxiv.org/abs/2305.18231. Zhihao Hu, Guo Lu, and Dong Xu. FVC: A new framework towards deep video compression in feature space. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1502–1511,
-
[15]
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine
URL https://arxiv.org/abs/ 2511.18706. Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. InAdvances in Neural Information Processing Systems,
-
[16]
Elucidating the Design Space of Diffusion-Based Generative Models
URL https://arxiv. org/abs/2206.00364. Muhammad Umar Karim Khan, Aaron Chadha, Mohammad Ashraful Anam, and Yiannis Andreopoulos. Perceptual video compression with neural wrapping. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17743–17754,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le
URLhttps://arxiv.org/abs/2602.09868. Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations,
-
[20]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
URL https://arxiv.org/abs/2209.03003. Guo Lu, Wanli Ouyang, Dong Xu, Xiaoyun Zhang, Chunlei Cai, and Zhiyong Gao. DVC: An end-to-end deep video compression framework. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11006–11015,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Qi Mao, Hao Cheng, Tinghan Yang, Libiao Jin, and Siwei Ma
URLhttps://arxiv.org/abs/2401.08740. Qi Mao, Hao Cheng, Tinghan Yang, Libiao Jin, and Siwei Ma. Generative neural video compression via video diffusion prior.arXiv preprint arXiv:2512.05016,
-
[23]
Fabian Mentzer, George Toderici, Michael Tschannen, and Eirikur Agustsson
URLhttps://arxiv.org/abs/2512.05016. Fabian Mentzer, George Toderici, Michael Tschannen, and Eirikur Agustsson. High-fidelity generative image compression. InAdvances in Neural Information Processing Systems,
-
[24]
Fabian Mentzer, Eirikur Agustsson, Johannes Ballé, David Minnen, Nick Johnston, and George Toderici
URL https://arxiv.org/ abs/2006.09965. Fabian Mentzer, Eirikur Agustsson, Johannes Ballé, David Minnen, Nick Johnston, and George Toderici. Neural video compression using gans for detail synthesis and propagation. InEuropean Conference on Computer Vision, pages 562–578. Springer,
-
[25]
Joint Autoregressive and Hierarchical Priors for Learned Image Compression
URL https: //arxiv.org/abs/1809.02736. Guy Ohayon, Hila Manor, Tomer Michaeli, and Michael Elad. Compressed image generation with denoising diffusion codebook models. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 47044–47089. PMLR,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Scalable Diffusion Models with Transformers
URL https://arxiv.org/abs/ 2212.09748. Linfeng Qi, Zhaoyang Jia, Jiahao Li, Bin Li, Houqiang Li, and Yan Lu. Generative latent coding for ultra-low bitrate image and video compression.IEEE Transactions on Circuits and Systems for Video Technology,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
URL https://arxiv. org/abs/2404.08580. Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695,
-
[28]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. InInternational Conference on Learning Representations, 2021a. URLhttps://arxiv.org/abs/2010.02502. Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations...
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[29]
URLhttps://arxiv.org/abs/2510.23633. Gary J Sullivan, Jens-Rainer Ohm, Woo-Jin Han, and Thomas Wiegand. Overview of the high efficiency video coding (HEVC) standard.IEEE Transactions on circuits and systems for video technology, 22(12):1649–1668,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Amit Vaisman, Guy Ohayon, Hila Manor, Michael Elad, and Tomer Michaeli
URLhttps://arxiv.org/abs/2206.08889. Amit Vaisman, Guy Ohayon, Hila Manor, Michael Elad, and Tomer Michaeli. Turbo-DDCM: Fast and flexible zero-shot diffusion-based image compression.arXiv preprint arXiv:2511.06424,
-
[32]
Turbo-DDCM: Fast and Flexible Zero-Shot Diffusion-Based Image Compression
URL https://arxiv.org/abs/2511.06424. Jeremy V onderfecht and Feng Liu. Lossy compression with pretrained diffusion models.arXiv preprint arXiv:2501.09815,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
URLhttps://arxiv.org/abs/2501.09815. Zhou Wang, Eero P. Simoncelli, and Alan C. Bovik. Multiscale structural similarity for image quality assessment. InThe Thirty-Seventh Asilomar Conference on Signals, Systems & Computers, 2003, volume 2, pages 1398–1402. IEEE,
-
[35]
Wan: Open and Advanced Large-Scale Video Generative Models
URLhttps://arxiv.org/abs/2503.20314. Ruihan Yang and Stephan Mandt. Lossy image compression with conditional diffusion models. InAdvances in Neural Information Processing Systems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
URLhttps://arxiv.org/abs/2209.06950. Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. CogVideoX: Text-to-video diffusion models with an expert transformer. InInternational Conference on Learning Representations,
-
[37]
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric
URLhttps://arxiv.org/abs/1801.03924. A Hyperparameter Configuration Table 3 lists the full set of hyperparameters used across all three GVCC variants at 720p and 1080p resolutions. Table 3: Default hyperparameters for GVCC (720p / 1080p). Parameter 720p 1080p Role M64 80 Atoms per step (bitrate knob) Mtail (I2V) 128 128 Atoms for AR tail frames K16384 163...
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
15 Table 6: T2V-1.3B R-D sweep on UVG 480p (7 seq.×3 GOPs)
BPP and PSNR increase monotonically from 0.0008 bpp / 22.5 dB to 0.0496 bpp / 30.0 dB, confirming smooth and predictable bitrate control across nearly two orders of magnitude. 15 Table 6: T2V-1.3B R-D sweep on UVG 480p (7 seq.×3 GOPs). M KPSNR (dB) BPP kbps 8 256 22.50 0.00081 5.3 16 512 24.32 0.00183 11.9 16 1024 24.76 0.00201 13.1 32 2048 26.32 0.00438 ...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.