Recognition: 2 theorem links
· Lean TheoremReMemNav: A Rethinking and Memory-Augmented Framework for Zero-Shot Object Navigation
Pith reviewed 2026-05-15 01:05 UTC · model grok-4.3
The pith
ReMemNav combines episodic memory buffers and dual-modal rethinking with vision-language models to cut hallucinations and deadlocks in zero-shot object navigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
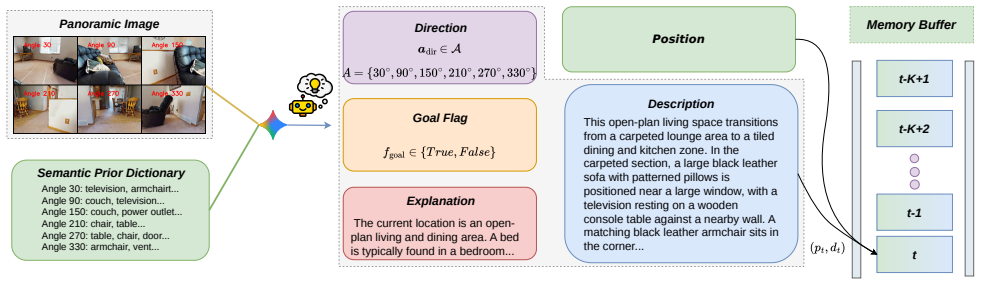
ReMemNav integrates panoramic semantic priors and episodic memory with VLMs by anchoring spatial reasoning via the Recognize Anything Model, applying an adaptive dual-modal rethinking mechanism on an episodic semantic buffer queue to verify target visibility and correct decisions, and deriving feasible actions from depth masks for low-level execution, which raises success rate and SPL on HM3D v0.1, v0.2, and MP3D relative to existing training-free zero-shot methods.
What carries the argument
The adaptive dual-modal rethinking mechanism built around an episodic semantic buffer queue, which stores historical observations and actively verifies whether the target is visible before committing to new actions.
If this is right
- Navigation agents reach unseen targets more often across HM3D and MP3D scenes without task-specific training.
- Exploration paths become shorter and more efficient as measured by SPL, because deadlocks are broken by memory-based corrections.
- High-level semantic instructions from the VLM map more reliably onto low-level spatial moves via depth-derived action sequences.
- The same buffer-and-rethink loop could reduce repeated visits to already-seen areas in other indoor navigation settings.
Where Pith is reading between the lines
- Adding similar memory queues to other VLM-driven robotic tasks might improve long-horizon instruction following in changing scenes.
- The framework's reliance on episodic buffers suggests it could be tested on real robots to see how sensor noise affects the rethinking step.
- Extending the buffer to store multi-step reasoning traces might allow handling of compound instructions like 'find the chair then the lamp'.
Load-bearing premise
The episodic semantic buffer queue and rethinking step can reliably detect and fix VLM mistakes such as false target detections without introducing fresh errors or needing per-environment adjustments.
What would settle it
An experiment in which targets are placed behind partial occlusions or near visually similar distractors, measuring whether success rate falls below the baseline when the buffer queue fails to override repeated VLM hallucinations.
Figures




read the original abstract
Zero-shot object navigation requires agents to locate unseen target objects in unfamiliar environments without prior maps or task-specific training which remains a significant challenge. Although recent advancements in vision-language models(VLMs) provide promising commonsense reasoning capabilities for this task, these models still suffer from spatial hallucinations, local exploration deadlocks, and a disconnect between high-level semantic intent and low-level control. In this regard, we propose a novel hierarchical navigation framework named ReMemNav, which seamlessly integrates panoramic semantic priors and episodic memory with VLMs. We introduce the Recognize Anything Model to anchor the spatial reasoning process of the VLM. We also design an adaptive dual-modal rethinking mechanism based on an episodic semantic buffer queue. The proposed mechanism actively verifies target visibility and corrects decisions using historical memory to prevent deadlocks. For low-level action execution, ReMemNav extracts a sequence of feasible actions using depth masks, allowing the VLM to select the optimal action for mapping into actual spatial movement. Extensive evaluations on HM3D and MP3D demonstrate that ReMemNav outperforms existing training-free zero-shot baselines in both success rate and exploration efficiency. Specifically, we achieve significant absolute performance improvements, with SR and SPL increasing by 1.7% and 7.0% on HM3D v0.1, 18.2% and 11.1% on HM3D v0.2, and 8.7% and 7.9% on MP3D.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ReMemNav, a hierarchical framework for zero-shot object navigation that integrates panoramic semantic priors and episodic memory with VLMs. It anchors VLM spatial reasoning via the Recognize Anything Model, introduces an adaptive dual-modal rethinking mechanism based on an episodic semantic buffer queue to verify target visibility and break deadlocks, and uses depth masks to extract feasible low-level actions. Evaluations on HM3D v0.1/v0.2 and MP3D report absolute SR/SPL gains of 1.7%/7.0%, 18.2%/11.1%, and 8.7%/7.9% over training-free baselines.
Significance. If the gains prove robust and directly attributable to the rethinking mechanism, the work would meaningfully advance training-free ZSON by addressing VLM hallucinations and deadlocks through memory augmentation without task-specific training. The combination of semantic priors, buffer-based correction, and VLM-guided action selection offers a practical engineering path for more reliable navigation in unseen environments.
major comments (3)
- [Experiments] Experiments section: The abstract and results claim concrete SR/SPL gains (e.g., +18.2% SR on HM3D v0.2) but supply no experimental protocol details, baseline implementations, statistical tests, run variance, or ablation results. This leaves the attribution of improvements to the episodic buffer queue unverified and load-bearing for the central claim.
- [Method] Method section (adaptive dual-modal rethinking): The headline performance is ascribed to the episodic semantic buffer queue verifying target visibility and correcting VLM decisions. No quantitative breakdown is given on correction frequency versus false-positive rate, nor on whether per-environment threshold tuning is required; without this or an ablation removing the queue, the net gains could be artifacts of prompt/scene distribution rather than a robust advance.
- [§4.3] §4.3 (low-level control): The depth-mask action extraction and VLM selection step is described at high level but lacks concrete mapping rules from mask-derived candidates to spatial actions under partial observability, making reproducibility of the reported efficiency gains (SPL) difficult to assess.
minor comments (2)
- [Method] Notation for the episodic semantic buffer queue (size, update rule, similarity metric) is introduced without a formal definition or pseudocode, complicating exact re-implementation.
- [Figures] Figure captions for navigation trajectories do not indicate whether the shown paths include rethinking corrections or baseline runs, reducing clarity of the qualitative results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen experimental rigor, methodological transparency, and reproducibility without altering the core claims.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The abstract and results claim concrete SR/SPL gains (e.g., +18.2% SR on HM3D v0.2) but supply no experimental protocol details, baseline implementations, statistical tests, run variance, or ablation results. This leaves the attribution of improvements to the episodic buffer queue unverified and load-bearing for the central claim.
Authors: We agree that the current Experiments section requires expansion for verifiability. In the revised manuscript we will add: full protocol details (episode counts, environment configurations, and evaluation metrics); explicit descriptions of baseline reproductions; statistical significance tests (paired t-tests with p-values); variance across multiple runs (standard deviations from at least three random seeds); and dedicated ablation studies that isolate the episodic semantic buffer queue. A new table will also quantify rethinking correction frequency and false-positive rates to directly support attribution of the reported gains. revision: yes
-
Referee: [Method] Method section (adaptive dual-modal rethinking): The headline performance is ascribed to the episodic semantic buffer queue verifying target visibility and correcting VLM decisions. No quantitative breakdown is given on correction frequency versus false-positive rate, nor on whether per-environment threshold tuning is required; without this or an ablation removing the queue, the net gains could be artifacts of prompt/scene distribution rather than a robust advance.
Authors: We will augment the Method section with quantitative metrics on the rethinking mechanism, including correction frequency, false-positive rate, and confirmation that the adaptive thresholds are fixed and environment-agnostic rather than tuned per scene. A new ablation study that disables the episodic buffer queue will be included to isolate its contribution and rule out prompt or distribution artifacts. revision: yes
-
Referee: [§4.3] §4.3 (low-level control): The depth-mask action extraction and VLM selection step is described at high level but lacks concrete mapping rules from mask-derived candidates to spatial actions under partial observability, making reproducibility of the reported efficiency gains (SPL) difficult to assess.
Authors: We will expand §4.3 with explicit mapping rules and pseudocode that detail how mask-derived candidate actions are converted to spatial movements. The revision will address partial observability explicitly, distinguishing cases where the target is absent from the current view (triggering exploration) from cases where it is visible (prioritizing directed approach), thereby enabling full reproduction of the SPL improvements. revision: yes
Circularity Check
No significant circularity; empirical engineering framework with independent evaluation claims
full rationale
The paper describes ReMemNav as a hierarchical framework combining VLMs, panoramic priors, episodic memory, and an adaptive rethinking mechanism. All reported gains (SR/SPL improvements on HM3D v0.1/v0.2 and MP3D) are presented as outcomes of empirical evaluation rather than any derivation, equation, or fitted parameter. No self-definitional steps, fitted-input predictions, load-bearing self-citations, uniqueness theorems, or ansatz smuggling appear in the abstract or described structure. The central claims rest on external benchmark results and are not reduced to the inputs by construction. This is a standard empirical contribution whose performance numbers are falsifiable outside the paper's own definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs provide reliable commonsense reasoning for navigation when anchored by Recognize Anything Model
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
adaptive dual-modal rethinking mechanism based on an episodic semantic buffer queue... verifies target visibility and corrects decisions
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
episodic memory buffer queue... sliding-window... capacity K=10
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
D. Batra, A. Gokaslan, A. Kembhavi, O. Maksymets, R. Mottaghi, M. Savva, A. Toshev, and E. Wijmans, “Objectnav revisited: On evaluation of embodied agents navigating to objects,”arXiv preprint arXiv:2006.13171, 2020
-
[2]
Zson: Zero-shot object-goal navigation using multimodal goal embed- dings,
A. Majumdar, G. Aggarwal, B. Devnani, J. Hoffman, and D. Batra, “Zson: Zero-shot object-goal navigation using multimodal goal embed- dings,”Advances in Neural Information Processing Systems, vol. 35, pp. 32 340–32 352, 2022
2022
-
[3]
Offline visual representation learning for embodied navigation,
K. Yadav, R. Ramrakhya, A. Majumdar, V .-P. Berges, S. Kuhar, D. Ba- tra, A. Baevski, and O. Maksymets, “Offline visual representation learning for embodied navigation,” inWorkshop on Reincarnating Reinforcement Learning at ICLR 2023, 2023
2023
-
[4]
Ovrl-v2: A simple state-of-art baseline for imagenav and objectnav,
K. Yadav, A. Majumdar, R. Ramrakhya, N. Yokoyama, A. Baevski, Z. Kira, O. Maksymets, and D. Batra, “Ovrl-v2: A simple state-of-art baseline for imagenav and objectnav,”arXiv preprint arXiv:2303.07798, 2023
-
[5]
Bridging zero-shot object navigation and foundation models through pixel-guided navigation skill,
W. Cai, S. Huang, G. Cheng, Y . Long, P. Gao, C. Sun, and H. Dong, “Bridging zero-shot object navigation and foundation models through pixel-guided navigation skill,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 5228–5234
2024
-
[6]
Esc: Exploration with soft commonsense constraints for zero-shot object navigation,
K. Zhou, K. Zheng, C. Pryor, Y . Shen, H. Jin, L. Getoor, and X. E. Wang, “Esc: Exploration with soft commonsense constraints for zero-shot object navigation,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 42 829–42 842
2023
-
[7]
How to not train your dragon: Training-free embodied object goal navigation with semantic frontiers,
J. Chen, G. Li, S. Kumar, B. Ghanem, and F. Yu, “How to not train your dragon: Training-free embodied object goal navigation with semantic frontiers,”arXiv preprint arXiv:2305.16925, 2023
-
[8]
L. Zhong, C. Gao, Z. Ding, Y . Liao, H. Ma, S. Zhang, X. Zhou, and S. Liu, “Topv-nav: Unlocking the top-view spatial reasoning potential of mllm for zero-shot object navigation,”arXiv preprint arXiv:2411.16425, 2024
-
[9]
V oronav: V oronoi-based zero-shot object navigation with large language model,
P. Wu, Y . Mu, B. Wu, Y . Hou, J. Ma, S. Zhang, and C. Liu, “V oronav: V oronoi-based zero-shot object navigation with large language model,” arXiv preprint arXiv:2401.02695, 2024
-
[10]
Thda: Treasure hunt data augmentation for semantic navigation,
O. Maksymets, V . Cartillier, A. Gokaslan, E. Wijmans, W. Galuba, S. Lee, and D. Batra, “Thda: Treasure hunt data augmentation for semantic navigation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 374–15 383
2021
-
[11]
Simple but effective: Clip embeddings for embodied ai,
A. Khandelwal, L. Weihs, R. Mottaghi, and A. Kembhavi, “Simple but effective: Clip embeddings for embodied ai,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 14 829–14 838
2022
-
[12]
Habitat- web: Learning embodied object-search strategies from human demon- strations at scale,
R. Ramrakhya, E. Undersander, D. Batra, and A. Das, “Habitat- web: Learning embodied object-search strategies from human demon- strations at scale,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5173–5183
2022
-
[13]
Learning active camera for multi-object navigation,
P. Chen, D. Ji, K. Lin, W. Hu, W. Huang, T. Li, M. Tan, and C. Gan, “Learning active camera for multi-object navigation,”Advances in Neural Information Processing Systems, vol. 35, pp. 28 670–28 682, 2022
2022
-
[14]
Film: Following instructions in language with modular methods.arXiv preprint arXiv:2110.07342, 2021
S. Y . Min, D. S. Chaplot, P. Ravikumar, Y . Bisk, and R. Salakhutdinov, “Film: Following instructions in language with modular methods,” arXiv preprint arXiv:2110.07342, 2021
-
[15]
Jarvis: A neuro-symbolic commonsense reason- ing framework for conversational embodied agents,
K. Zheng, K. Zhou, J. Gu, Y . Fan, J. Wang, Z. Di, X. He, and X. E. Wang, “Jarvis: A neuro-symbolic commonsense reason- ing framework for conversational embodied agents,”arXiv preprint arXiv:2208.13266, 2022
-
[16]
Openfmnav: Towards open-set zero-shot object navigation via vision-language foundation models,
Y . Kuang, H. Lin, and M. Jiang, “Openfmnav: Towards open-set zero-shot object navigation via vision-language foundation models,” inFindings of the Association for Computational Linguistics: NAACL 2024, 2024, pp. 338–351
2024
-
[17]
L3mvn: Leveraging large language models for visual target navigation,
B. Yu, H. Kasaei, and M. Cao, “L3mvn: Leveraging large language models for visual target navigation,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 3554–3560
2023
-
[18]
Navigation with large language models: Semantic guesswork as a heuristic for planning,
D. Shah, M. R. Equi, B. Osi ´nski, F. Xia, B. Ichter, and S. Levine, “Navigation with large language models: Semantic guesswork as a heuristic for planning,” inConference on Robot Learning. PMLR, 2023, pp. 2683–2699
2023
-
[19]
Cows on pasture: Baselines and benchmarks for language-driven zero-shot object navigation,
S. Y . Gadre, M. Wortsman, G. Ilharco, L. Schmidt, and S. Song, “Cows on pasture: Baselines and benchmarks for language-driven zero-shot object navigation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 23 171–23 181
2023
-
[20]
Prioritized semantic learning for zero-shot instance navigation,
X. Sun, L. Liu, H. Zhi, R. Qiu, and J. Liang, “Prioritized semantic learning for zero-shot instance navigation,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 161–178
2024
-
[21]
Imagine before go: Self-supervised generative map for object goal navigation,
S. Zhang, X. Yu, X. Song, X. Wang, and S. Jiang, “Imagine before go: Self-supervised generative map for object goal navigation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 16 414–16 425
2024
-
[22]
D. Goetting, H. G. Singh, and A. Loquercio, “End-to-end navigation with vision language models: Transforming spatial reasoning into question-answering,”arXiv preprint arXiv:2411.05755, 2024
-
[23]
Grounded language-image pre-training,
L. H. Li, P. Zhang, H. Zhang, J. Yang, C. Li, Y . Zhong, L. Wang, L. Yuan, L. Zhang, J.-N. Hwanget al., “Grounded language-image pre-training,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 965–10 975
2022
-
[24]
X. Guo, R. Zhang, Y . Duan, Y . He, D. Nie, W. Huang, C. Zhang, S. Liu, H. Zhao, and L. Chen, “Surds: Benchmarking spatial un- derstanding and reasoning in driving scenarios with vision language models,”arXiv preprint arXiv:2411.13112, 2024
-
[25]
Vlfm: Vision- language frontier maps for zero-shot semantic navigation,
N. Yokoyama, S. Ha, D. Batra, J. Wang, and B. Bucher, “Vlfm: Vision- language frontier maps for zero-shot semantic navigation,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 42–48
2024
-
[26]
Recognize anything: A strong image tagging model,
Y . Zhang, X. Huang, J. Ma, Z. Li, Z. Luo, Y . Xie, Y . Qin, T. Luo, Y . Li, S. Liuet al., “Recognize anything: A strong image tagging model,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 1724–1732
2024
-
[27]
Zero-shot object searching using large-scale object relationship prior,
H. Chen, R. Xu, S. Cheng, P. A. Vela, and D. Xu, “Zero-shot object searching using large-scale object relationship prior,”arXiv preprint arXiv:2303.06228, 2023
-
[28]
Zero experience required: Plug & play modular transfer learning for semantic visual navigation,
Z. Al-Halah, S. K. Ramakrishnan, and K. Grauman, “Zero experience required: Plug & play modular transfer learning for semantic visual navigation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 17 031–17 041
2022
-
[29]
Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames,
E. Wijmans, A. Kadian, A. Morcos, S. Lee, I. Essa, D. Parikh, M. Savva, and D. Batra, “Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames,”arXiv preprint arXiv:1911.00357, 2019
-
[30]
Visual language maps for robot navigation,
C. Huang, O. Mees, A. Zeng, and W. Burgard, “Visual language maps for robot navigation,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 10 608–10 615
2023
-
[31]
Wmnav: Integrating vision-language models into world models for object goal navigation,
D. Nie, X. Guo, Y . Duan, R. Zhang, and L. Chen, “Wmnav: Integrating vision-language models into world models for object goal navigation,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 2392–2399
2025
-
[32]
Think global, act local: Dual-scale graph transformer for vision-and-language navigation,
S. Chen, P.-L. Guhur, M. Tapaswi, C. Schmid, and I. Laptev, “Think global, act local: Dual-scale graph transformer for vision-and-language navigation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 16 537–16 547
2022
-
[33]
L. Wang, Z. He, J. Li, R. Xia, M. Hu, C. Yao, C. Liu, Y . Tang, and Q. Chen, “Clash: Collaborative large-small hierarchical frame- work for continuous vision-and-language navigation,”arXiv preprint arXiv:2512.10360, 2025
-
[34]
Doraemon: Decentralized ontology-aware reliable agent with enhanced memory oriented navigation,
T. Gu, L. Li, X. Wang, C. Gong, J. Gong, Z. Zhang, Y . Xie, L. Ma, and X. Tan, “Doraemon: Decentralized ontology-aware reliable agent with enhanced memory oriented navigation,”arXiv preprint arXiv:2505.21969, 2025
-
[35]
Swiftsage: A generative agent with fast and slow thinking for complex interactive tasks,
B. Y . Lin, Y . Fu, K. Yang, F. Brahman, S. Huang, C. Bhagavatula, P. Ammanabrolu, Y . Choi, and X. Ren, “Swiftsage: A generative agent with fast and slow thinking for complex interactive tasks,”Advances in Neural Information Processing Systems, vol. 36, pp. 23 813–23 825, 2023
2023
-
[36]
M. Wei, C. Wan, J. Peng, X. Yu, Y . Yang, D. Feng, W. Cai, C. Zhu, T. Wang, J. Panget al., “Ground slow, move fast: A dual-system foundation model for generalizable vision-and-language navigation,” arXiv preprint arXiv:2512.08186, 2025
-
[37]
Learning to explore using active neural slam,
D. S. Chaplot, D. Gandhi, S. Gupta, A. Gupta, and R. Salakhutdi- nov, “Learning to explore using active neural slam,”arXiv preprint arXiv:2004.05155, 2020
-
[38]
Heal: An empirical study on hallucinations in embodied agents driven by large language models,
T. Chakraborty, U. Ghosh, X. Zhang, F. F. Niloy, Y . Dong, J. Li, A. K. Roy-Chowdhury, and C. Song, “Heal: An empirical study on hallucinations in embodied agents driven by large language models,” arXiv preprint arXiv:2506.15065, 2025
-
[39]
Ecbench: Can multi-modal foundation models understand the egocentric world? a holistic embodied cog- nition benchmark,
R. Dang, Y . Yuan, W. Zhang, Y . Xin, B. Zhang, L. Li, L. Wang, Q. Zeng, X. Li, and L. Bing, “Ecbench: Can multi-modal foundation models understand the egocentric world? a holistic embodied cog- nition benchmark,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 24 593–24 602
2025
-
[40]
Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
S. K. Ramakrishnan, A. Gokaslan, E. Wijmans, O. Maksymets, A. Clegg, J. Turner, E. Undersander, W. Galuba, A. Westbury, A. X. Changet al., “Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai,”arXiv preprint arXiv:2109.08238, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[41]
Matterport3D: Learning from RGB-D Data in Indoor Environments
A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niessner, M. Savva, S. Song, A. Zeng, and Y . Zhang, “Matterport3d: Learning from rgb-d data in indoor environments,”arXiv preprint arXiv:1709.06158, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation,
H. Yin, X. Xu, Z. Wu, J. Zhou, and J. Lu, “Sg-nav: Online 3d scene graph prompting for llm-based zero-shot object navigation,”Advances in neural information processing systems, vol. 37, pp. 5285–5307, 2024
2024
-
[43]
Unigoal: Towards universal zero-shot goal-oriented navigation,
H. Yin, X. Xu, L. Zhao, Z. Wang, J. Zhou, and J. Lu, “Unigoal: Towards universal zero-shot goal-oriented navigation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, 2025, pp. 19 057–19 066
2025
-
[44]
Instructnav: Zero-shot system for generic instruction navigation in unexplored environment,
Y . Long, W. Cai, H. Wang, G. Zhan, and H. Dong, “Instructnav: Zero-shot system for generic instruction navigation in unexplored environment,”arXiv preprint arXiv:2406.04882, 2024
-
[45]
Multi-floor zero-shot object navigation policy,
L. Zhang, H. Wang, E. Xiao, X. Zhang, Q. Zhang, Z. Jiang, and R. Xu, “Multi-floor zero-shot object navigation policy,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 6416–6422
2025
-
[46]
Panonav: Mapless zero-shot object navigation with panoramic scene parsing and dynamic memory,
Q. Jin, Y . Wu, and C. Chen, “Panonav: Mapless zero-shot object navigation with panoramic scene parsing and dynamic memory,”arXiv preprint arXiv:2511.06840, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.