Recognition: no theorem link
A General Model for Deepfake Speech Detection: Diverse Bonafide Resources or Diverse AI-Based Generators
Pith reviewed 2026-05-14 22:12 UTC · model grok-4.3
The pith
Balancing bonafide speech resources with AI-generated samples is the key to training general deepfake speech detectors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By re-using and combining public Deepfake Speech Detection datasets to create one with balanced Bonafide Resources and AI-based Generators, deep-learning models trained on it demonstrate improved generality, as shown by superior cross-dataset evaluation results compared to unbalanced training.
What carries the argument
The balance between Bonafide Resources (BR) and AI-based Generators (AG) in the training dataset, which controls the detection threshold and enables cross-dataset generalization in Deepfake Speech Detection models.
If this is right
- Training data must include diverse real speech sources alongside multiple AI generation methods to avoid overfitting to specific fakes.
- The choice of threshold score in inference depends directly on the BR to AG ratio in training.
- Models trained on such balanced data maintain detection accuracy when evaluated on datasets created with different generators or recording setups.
- Reusing existing public datasets is sufficient to achieve the necessary balance without collecting new data.
Where Pith is reading between the lines
- Dataset creators should focus on equal proportions rather than maximizing volume of one type.
- This balance approach could extend to improving robustness in other audio classification tasks involving synthetic content.
- Future work might test whether the same principle applies when new generator types emerge after training.
Load-bearing premise
That re-using and combining existing public datasets creates a genuine balance without hidden biases from overlapping content or domain shifts.
What would settle it
A new deepfake speech dataset using a previously unseen AI generator and different recording conditions where the balanced model shows no improvement over models trained on unbalanced data would falsify the claim.
Figures







read the original abstract
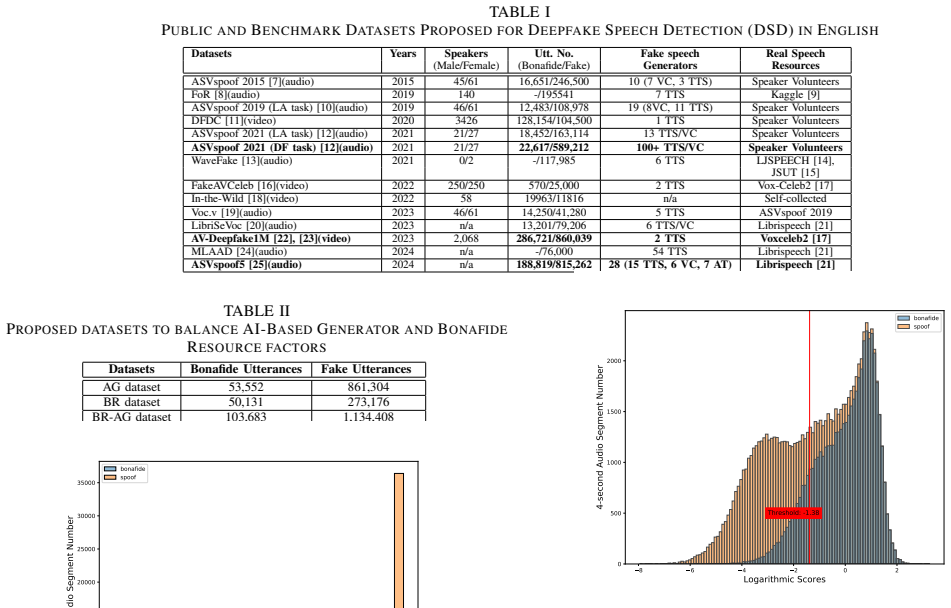
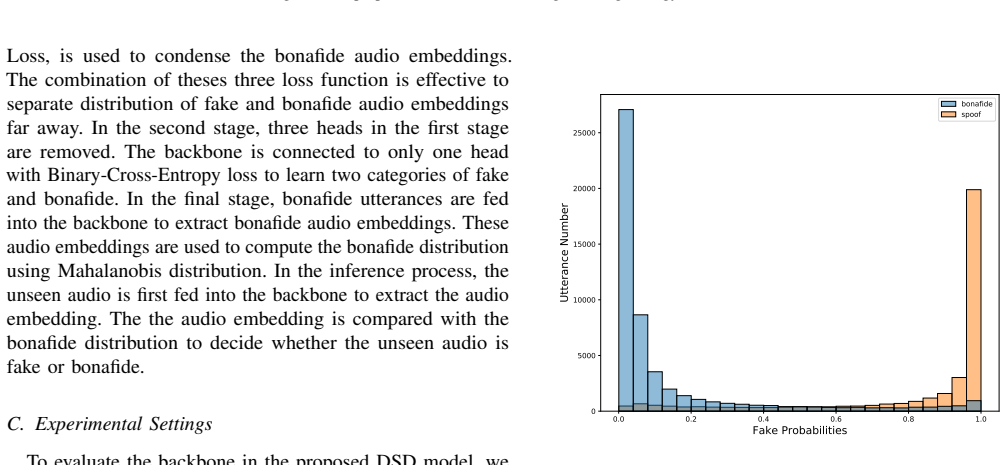
In this paper, we analyze two main factors of Bonafide Resource (BR) or AI-based Generator (AG) which affect the performance and the generality of a Deepfake Speech Detection (DSD) model. To this end, we first propose a deep-learning based model, referred to as the baseline. Then, we conducted experiments on the baseline by which we indicate how Bonafide Resource (BR) and AI-based Generator (AG) factors affect the threshold score used to detect fake or bonafide input audio in the inference process. Given the experimental results, a dataset, which re-uses public Deepfake Speech Detection (DSD) datasets and shows a balance between Bonafide Resource (BR) or AI-based Generator (AG), is proposed. We then train various deep-learning based models on the proposed dataset and conduct cross-dataset evaluation on different benchmark datasets. The cross-dataset evaluation results prove that the balance of Bonafide Resources (BR) and AI-based Generators (AG) is the key factor to train and achieve a general Deepfake Speech Detection (DSD) model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the balance between Bonafide Resources (BR) and AI-based Generators (AG) is the key factor for training a general Deepfake Speech Detection (DSD) model. It introduces a baseline deep-learning model, reports experiments showing how BR and AG influence detection threshold scores during inference, constructs a balanced dataset by reusing and combining existing public DSD corpora, trains multiple models on this dataset, and presents cross-dataset evaluations on benchmark sets to demonstrate improved generality.
Significance. If the result holds after appropriate controls, it would be significant for DSD research because it offers a practical, low-cost strategy for improving model generality by rebalancing existing public datasets rather than requiring new data collection or architectural innovations. This could standardize dataset curation practices and reduce reliance on single-source training corpora.
major comments (2)
- [Cross-dataset evaluation] The central claim that BR/AG balance is the operative variable for generality rests on cross-dataset results, yet the manuscript provides no ablation that holds total sample count, speaker overlap, acoustic conditions, and generator-specific artifacts fixed while varying only the BR:AG ratio. Without this isolation, the observed robustness cannot be attributed specifically to balance rather than incidental coverage of other dataset properties.
- [Experiments] The abstract states that experiments on the baseline model show how BR and AG affect the threshold score used for bonafide/fake classification, but supplies no quantitative values, error bars, statistical tests, or details on how thresholds were chosen or how balance was quantified (e.g., sample counts or diversity metrics per category). This leaves the reported threshold effects and the subsequent claim of generality without visible numerical support.
minor comments (1)
- [Abstract] The abstract uses 'Bonafide Resource (BR) or AI-based Generator (AG)' inconsistently with later 'and' phrasing; standardize the conjunction for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below, providing the strongest honest defense of our work while acknowledging where revisions are warranted to strengthen the presentation of results.
read point-by-point responses
-
Referee: [Cross-dataset evaluation] The central claim that BR/AG balance is the operative variable for generality rests on cross-dataset results, yet the manuscript provides no ablation that holds total sample count, speaker overlap, acoustic conditions, and generator-specific artifacts fixed while varying only the BR:AG ratio. Without this isolation, the observed robustness cannot be attributed specifically to balance rather than incidental coverage of other dataset properties.
Authors: We acknowledge that the manuscript does not include a fully controlled ablation isolating only the BR:AG ratio while fixing sample counts, speaker overlap, acoustic conditions, and generator artifacts. Such an experiment would require constructing new synthetic datasets with precisely matched properties, which is outside the scope of our proposed approach of reusing and rebalancing existing public corpora. Our evidence for the importance of balance instead comes from consistent performance gains in cross-dataset evaluations on multiple independent benchmarks when training on the balanced dataset versus unbalanced variants. We will add a dedicated limitations paragraph discussing the challenges of perfect isolation in public-data settings and include supplementary tables comparing key dataset statistics (e.g., speaker counts, duration distributions) across the configurations we tested. revision: partial
-
Referee: [Experiments] The abstract states that experiments on the baseline model show how BR and AG affect the threshold score used for bonafide/fake classification, but supplies no quantitative values, error bars, statistical tests, or details on how thresholds were chosen or how balance was quantified (e.g., sample counts or diversity metrics per category). This leaves the reported threshold effects and the subsequent claim of generality without visible numerical support.
Authors: The body of the manuscript reports quantitative threshold scores obtained under different BR/AG training ratios, but we agree that the abstract omits specific numerical values and that the methods section would benefit from greater transparency. We will revise the abstract to include representative quantitative results (e.g., threshold values and associated detection rates), add error bars and statistical significance tests to the relevant figures and tables, and expand the experimental setup subsection to explicitly state how thresholds were selected (via validation-set optimization) and how balance was quantified (sample counts per BR/AG category plus diversity metrics such as speaker and generator coverage). revision: yes
Circularity Check
No circularity: empirical claims rest on cross-dataset experiments without self-referential definitions or fitted predictions.
full rationale
The paper constructs a balanced BR/AG dataset by re-using existing public corpora, trains models on it, and reports cross-dataset evaluation metrics to support the claim that balance drives generality. No equations, parameters fitted to a subset then renamed as predictions, or self-citations are invoked to make the generality result equivalent to the input data by construction. The derivation chain consists of experimental outcomes rather than tautological redefinitions, satisfying the default expectation of non-circularity for empirical ML papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Deep-learning models trained on balanced BR/AG data will exhibit improved cross-dataset generalization for DSD
Reference graph
Works this paper leans on
-
[1]
A comprehensive survey with critical analysis for deepfake speech detection,
L. Pham, P. Lam, D. Tran, H. Tang, T. Nguyen, A. Schindler, F. Skopik, A. Polonsky, and H. C. Vu, “A comprehensive survey with critical analysis for deepfake speech detection,”Computer Science Review, vol. 57, p. 100757, 2025
work page 2025
-
[2]
XLSR-MamBo: Scaling the Hybrid Mamba-Attention Backbone for Audio Deepfake Detection
K.-H. Ng, T. Song, Y . WU, and Z. Xia, “Xlsr-mambo: Scaling the hybrid mamba-attention backbone for audio deepfake detection,”arXiv preprint arXiv:2601.02944, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Wavlm model ensemble for audio deepfake detection,
D. Combei, A. Stan, D. Oneata, and H. Cucu, “Wavlm model ensemble for audio deepfake detection,”arXiv preprint arXiv:2408.07414, 2024
-
[4]
Speech df arena: A leaderboard for speech deepfake detection models,
S. Dowerah, A. Kulkarni, A. Kulkarni, H. M. Tran, J. Kalda, A. Fe- dorchenko, B. Fauve, D. Lolive, T. Alum ¨ae, and M. M. Doss, “Speech df arena: A leaderboard for speech deepfake detection models,”arXiv preprint arXiv:2509.02859, 2025
-
[5]
Unsu- pervised Cross-Lingual Representation Learning for Speech Recognition,
A. Conneau, A. Baevski, R. Collobert, A. Mohamed, and M. Auli, “Unsu- pervised Cross-Lingual Representation Learning for Speech Recognition,” inProc. INTERSPEECH, 2021, pp. 2426–2430
work page 2021
-
[6]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing,
S. Chenet al., “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
work page 2022
-
[7]
Asvspoof 2015: the first automatic speaker verification spoofing and countermeasures challenge,
Z. Wu, T. Kinnunen, N. Evans, J. Yamagishi, C. Hanil c ¸i, M. Sahidullah, and A. Sizov, “Asvspoof 2015: the first automatic speaker verification spoofing and countermeasures challenge,” inProc. INTERSPEECH, 2015, pp. 2037–2041
work page 2015
-
[8]
For: A dataset for synthetic speech detection,
R. Reimao and V . Tzerpos, “For: A dataset for synthetic speech detection,” inInternational Conference on Speech Technology and Human-Computer Dialogue, 2019, pp. 1–10
work page 2019
-
[9]
Audio source used to generate for dataset,
“Audio source used to generate for dataset,” https://www.kaggle.com/ datasets/percevalw/englishfrench-translations, 2018
work page 2018
-
[10]
Asvspoof 2019: A large-scale public database of synthesized, converted and replayed speech,
X. Wanget al., “Asvspoof 2019: A large-scale public database of synthesized, converted and replayed speech,”Computer Speech & Language, vol. 64, p. 101114, 2020
work page 2019
-
[11]
The DeepFake Detection Challenge (DFDC) Dataset
B. Dolhansky, J. Bitton, B. Pflaum, J. Lu, R. Howes, M. Wang, and C. C. Ferrer, “The deepfake detection challenge (DFDC) dataset,”arXiv preprint arXiv:2006.07397, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[12]
Asvspoof 2021: accelerating progress in spoofed and deepfake speech detection,
J. Yamagishiet al., “Asvspoof 2021: accelerating progress in spoofed and deepfake speech detection,” inWorkshop-Automatic Speaker Verification and Spoofing Coutermeasures Challenge (ASVspoof), 2021
work page 2021
-
[13]
Wavefake: A data set to facilitate audio deepfake detection,
J. Frank and L. Sch ¨onherr, “Wavefake: A data set to facilitate audio deepfake detection,”NeurIPS, 2024
work page 2024
-
[14]
Efficient neural audio synthesis,
N. Kalchbrenner, E. Elsen, K. Simonyan, S. Noury, N. Casagrande, E. Lockhart, F. Stimberg, A. Oord, S. Dieleman, and K. Kavukcuoglu, “Efficient neural audio synthesis,” inProc. ICML, 2018, pp. 2410–2419
work page 2018
-
[15]
JSUT corpus: free large-scale Japanese speech corpus for end-to-end speech synthesis
R. Sonobe, S. Takamichi, and H. Saruwatari, “Jsut corpus: free large- scale japanese speech corpus for end-to-end speech synthesis,”arXiv preprint arXiv:1711.00354, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Fakeavceleb: A novel audio-video multimodal deepfake dataset,
H. Khalid, S. Tariq, M. Kim, and S. S. Woo, “Fakeavceleb: A novel audio-video multimodal deepfake dataset,” inThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021
work page 2021
-
[17]
V oxCeleb2: Deep Speaker Recognition,
J. S. Chung, A. Nagrani, and A. Zisserman, “V oxCeleb2: Deep Speaker Recognition,” inProc. INTERSPEECH, 2018, pp. 1086–1090
work page 2018
-
[18]
Does Audio Deepfake Detection Generalize?
N. M ¨uller, P. Czempin, F. Diekmann, A. Froghyar, and K. B ¨ottinger, “Does Audio Deepfake Detection Generalize?” inProc. INTERSPEECH, 2022, pp. 2783–2787
work page 2022
-
[19]
X. Wang and J. Yamagishi, “Spoofed training data for speech spoofing countermeasure can be efficiently created using neural vocoders,” inProc. ICASSP, 2023, pp. 1–5
work page 2023
-
[20]
Ai-synthesized voice detection using neural vocoder artifacts,
C. Sun, S. Jia, S. Hou, and S. Lyu, “Ai-synthesized voice detection using neural vocoder artifacts,” inProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 904–912
work page 2023
-
[21]
Librispeech: an asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: an asr corpus based on public domain audio books,” inProc. ICASSP, 2015, pp. 5206–5210
work page 2015
-
[22]
Av-deepfake1m: A large-scale llm-driven audio-visual deepfake dataset,
Z. Cai, S. Ghosh, A. P. Adatia, M. Hayat, A. Dhall, and K. Stefanov, “Av-deepfake1m: A large-scale llm-driven audio-visual deepfake dataset,” arXiv preprint arXiv:2311.15308, 2023
-
[23]
1m-deepfakes detection challenge,
“1m-deepfakes detection challenge,” https://deepfakes1m.github.io/, 2023
work page 2023
-
[24]
Mlaad: The multi-language audio anti-spoofing dataset,
N. M. M ¨uller, P. Kawa, W. H. Choong, E. Casanova, E. G ¨olge, T. M¨uller, P. Syga, P. Sperl, and K. B ¨ottinger, “Mlaad: The multi-language audio anti-spoofing dataset,” inProc. IJCNN, 2024, pp. 1–7
work page 2024
-
[25]
“The asvspoof 2024 challenge,” https://www.asvspoof.org/, 2024
work page 2024
-
[26]
Adam: A Method for Stochastic Optimization
P. K. Diederik and B. Jimmy, “Adam: A method for stochastic optimization,”CoRR, vol. abs/1412.6980, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[27]
L. Pham, D. Tran, P. Lam, F. Skopik, A. Schindler, S. Poletti, D. Fischinger, and M. Boyer, “Din-cts: Low-complexity depthwise- inception neural network with contrastive training strategy for deepfake speech detection,”arXiv preprint arXiv:2502.20225, 2025
-
[28]
Robust speech recognition via large-scale weak supervision,
A. Radfordet al., “Robust speech recognition via large-scale weak supervision,” inProc. ICML, 2023, pp. 28 492–28 518
work page 2023
-
[29]
T. B. Patel and H. A. Patil, “Combining evidences from mel cepstral, cochlear filter cepstral and instantaneous frequency features for detection of natural vs. spoofed speech.” inProc. INTERSPEECH, 2015, pp. 2062– 2066
work page 2015
-
[30]
A lip sync expert is all you need for speech to lip generation in the wild,
K. Prajwal, R. Mukhopadhyay, V . P. Namboodiri, and C. Jawahar, “A lip sync expert is all you need for speech to lip generation in the wild,” in Proc. ACM international conference on multimedia, 2020, pp. 484–492
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.