Recognition: 2 theorem links
· Lean TheoremTowards Efficient Large Vision-Language Models: A Comprehensive Survey on Inference Strategies
Pith reviewed 2026-05-14 21:37 UTC · model grok-4.3
The pith
A survey organizes techniques to accelerate large vision-language model inference into four categories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
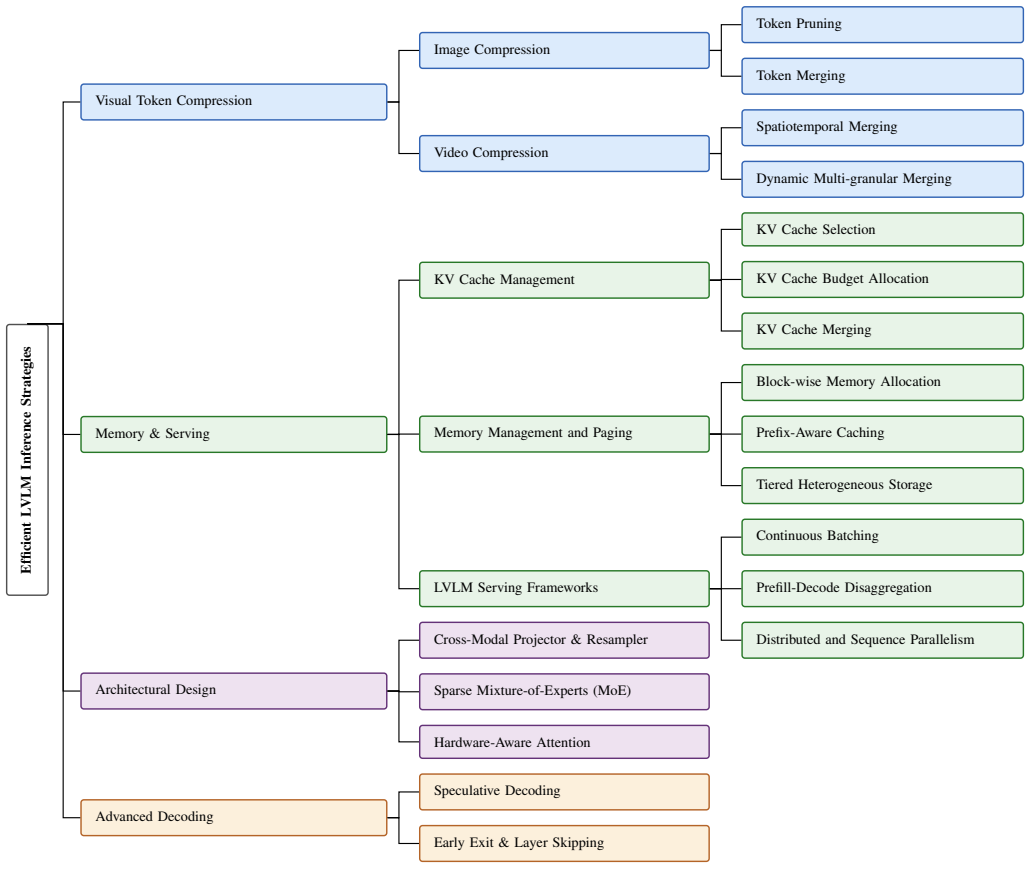
The paper presents a comprehensive survey of the current state-of-the-art techniques for accelerating LVLM inference and introduces a systematic taxonomy that categorizes existing optimization frameworks into four primary dimensions: visual token compression, memory management and serving, efficient architectural design, and advanced decoding strategies. It further critically examines the limitations of these current methodologies and identifies critical open problems to inspire future research directions in efficient multimodal systems.
What carries the argument
The four-dimension taxonomy that groups optimization frameworks for LVLM inference acceleration.
If this is right
- Visual token compression reduces the quadratic complexity of attention mechanisms caused by high-resolution inputs.
- Memory management and serving techniques improve efficiency when deploying large models at scale.
- Efficient architectural designs lower the overall computational load during inference.
- Advanced decoding strategies accelerate the output generation process.
- Critical examination of current limitations helps define open problems for future multimodal efficiency research.
Where Pith is reading between the lines
- The taxonomy could serve as a reference frame for researchers to classify and compare new inference methods consistently.
- Combining techniques across the four dimensions might produce efficiency improvements larger than any single category alone.
- Real-world benchmarks on high-resolution multimodal tasks could test whether the taxonomy covers emerging approaches.
- Resolving the identified open problems may support wider use of these models on devices with limited compute resources.
Load-bearing premise
That the four-dimension taxonomy is systematic and complete and that the identified limitations accurately reflect the full literature.
What would settle it
A new optimization method for LVLM inference that cannot be placed in any of the four taxonomy dimensions or that shows the stated limitations do not hold across recent work.
Figures

read the original abstract
Although Large Vision Language Models (LVLMs) have demonstrated impressive multimodal reasoning capabilities, their scalability and deployment are constrained by massive computational requirements. In particular, the massive amount of visual tokens from high-resolution input data aggravates the situation due to the quadratic complexity of attention mechanisms. To address these issues, the research community has developed several optimization frameworks. This paper presents a comprehensive survey of the current state-of-the-art techniques for accelerating LVLM inference. We introduce a systematic taxonomy that categorizes existing optimization frameworks into four primary dimensions: visual token compression, memory management and serving, efficient architectural design, and advanced decoding strategies. Furthermore, we critically examine the limitations of these current methodologies and identify critical open problems to inspire future research directions in efficient multimodal systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper surveys techniques for accelerating inference in Large Vision-Language Models (LVLMs). It introduces a systematic four-dimension taxonomy covering visual token compression, memory management and serving, efficient architectural design, and advanced decoding strategies, while critically examining limitations of current methods and identifying open problems to guide future work.
Significance. If the taxonomy proves systematic and the coverage representative, the survey could serve as a useful reference for organizing the literature on LVLM efficiency, helping researchers navigate deployment challenges in multimodal systems.
minor comments (1)
- [Abstract] Abstract: the claim of a 'systematic taxonomy' would be strengthened by briefly stating the paper-selection criteria or number of works reviewed.
Simulated Author's Rebuttal
We thank the referee for their summary of our survey on inference optimization techniques for Large Vision-Language Models. We appreciate the acknowledgment that a systematic four-dimension taxonomy covering visual token compression, memory management and serving, efficient architectural design, and advanced decoding strategies, along with discussion of limitations and open problems, could serve as a useful reference for the community. We note the 'uncertain' recommendation but observe that no specific major comments were provided in the report.
Circularity Check
No circularity: survey with external literature review only
full rationale
This is a survey paper that introduces a four-dimension taxonomy to organize existing LVLM inference acceleration techniques drawn from the broader literature. No derivations, equations, fitted parameters, predictions, or self-referential chains appear in the abstract or described structure. The taxonomy is presented as an organizational framework rather than a result derived from internal assumptions or prior self-citations. All claims rest on external references, satisfying the condition for a self-contained review with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe introduce a systematic taxonomy that categorizes existing optimization frameworks into four primary dimensions: visual token compression, memory management and serving, efficient architectural design, and advanced decoding strategies.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearThe primary objective of visual token compression is to identify and drop/merge such tokens as early as possible to alleviate the computational overhead
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 41st International Conference on Machine Learning
Agarwal, S., Acun, B., Hosmer, B., Elhoushi, M., Lee, Y ., Venkataraman, S., Papailiopoulos, D., Wu, C.J.: Chai: clustered head attention for efficient llm inference. In: Proceedings of the 41st International Conference on Machine Learning. pp. 291–312 (2024)
work page 2024
-
[2]
Advances in neural information processing systems35, 23716–23736 (2022)
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y ., Lenc, K., Mensch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems35, 23716–23736 (2022)
work page 2022
-
[3]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Alvar, S.R., Singh, G., Akbari, M., Zhang, Y .: Di- vprune: Diversity-based visual token pruning for large multimodal models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 9392– 9401 (2025)
work page 2025
-
[4]
Bai, J., Bai, S., Chu, Y ., Cui, Z., Dang, K., Deng, X., Fan, Y ., Ge, W., Han, Y ., Huang, F., et al.: Qwen technical report. arXiv preprint arXiv:2309.16609 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-vl: A frontier large vision- language model with versatile abilities. arXiv preprint arXiv:2308.129661(2), 3 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Token Merging: Your ViT But Faster
Bolya, D., Fu, C.Y ., Dai, X., Zhang, P., Feichtenhofer, C., Hoffman, J.: Token merging: Your vit but faster. arXiv preprint arXiv:2210.09461 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Striped attention: Faster ring attention for causal transformers
Brandon, W., Nrusimha, A., Qian, K., Ankner, Z., Jin, T., Song, Z., Ragan-Kelley, J.: Striped attention: Faster ring attention for causal transformers. arXiv preprint arXiv:2311.09431 (2023)
-
[8]
In: Second Conference on Lan- guage Modeling (2025), https://openreview.net/forum? id=ayi7qezU87
Cai, Z., Zhang, Y ., Gao, B., Liu, Y ., Li, Y ., Liu, T., Lu, K., Xiong, W., Dong, Y ., Hu, J., Xiao, W.: PyramidKV: Dynamic KV cache compression based on pyramidal information funneling. In: Second Conference on Lan- guage Modeling (2025), https://openreview.net/forum? id=ayi7qezU87
work page 2025
-
[9]
arXiv preprint arXiv:2305.17530 (2023)
Cao, Q., Paranjape, B., Hajishirzi, H.: Pumer: Pruning and merging tokens for efficient vision language models. arXiv preprint arXiv:2305.17530 (2023)
-
[10]
In: European Conference on Computer Vision
Chen, L., Zhao, H., Liu, T., Bai, S., Lin, J., Zhou, C., Chang, B.: An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision- language models. In: European Conference on Computer Vision. pp. 19–35. Springer (2024)
work page 2024
-
[11]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24185–24198 (2024)
work page 2024
-
[12]
Chiang, W.L., Li, Z., Lin, Z., Sheng, Y ., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y ., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023)2(3), 6 (2023)
work page 2023
-
[13]
Dao, T.: Flashattention-2: Faster attention with better parallelism and work partitioning. In: The Twelfth Inter- national Conference on Learning Representations (2024), https://openreview.net/forum?id=mZn2Xyh9Ec
work page 2024
-
[14]
Advances in neural information processing systems35, 16344–16359 (2022)
Dao, T., Fu, D., Ermon, S., Rudra, A., R ´e, C.: Flashat- tention: Fast and memory-efficient exact attention with io-awareness. Advances in neural information processing systems35, 16344–16359 (2022)
work page 2022
-
[15]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Devoto, A., Zhao, Y ., Scardapane, S., Minervini, P.: A simple and effective l 2 norm-based strategy for kv cache compression. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 18476–18499 (2024)
work page 2024
-
[16]
Fan, S., Jiang, X., Li, X., Meng, X., Han, P., Shang, S., Sun, A., Wang, Y .: Not all layers of llms are necessary during inference. In: Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, IJCAI-25. pp. 5083–5091 (2025)
work page 2025
-
[17]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Fu, T., Liu, T., Han, Q., Dai, G., Yan, S., Yang, H., Ning, X., Wang, Y .: Framefusion: Combining similarity and importance for video token reduction on large vision language models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 22654–22663 (October 2025)
work page 2025
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Gagrani, M., Goel, R., Jeon, W., Park, J., Lee, M., Lott, C.: On speculative decoding for multimodal large language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8285–8289 (2024)
work page 2024
-
[19]
In: First conference on language modeling (2024)
Gu, A., Dao, T.: Mamba: Linear-time sequence model- ing with selective state spaces. In: First conference on language modeling (2024)
work page 2024
-
[20]
arXiv preprint arXiv:2401.08671 (2024)
Holmes, C., Tanaka, M., Wyatt, M., Awan, A.A., Rasley, J., Rajbhandari, S., Aminabadi, R.Y ., Qin, H., Bakhtiari, A., Kurilenko, L., et al.: Deepspeed-fastgen: High-throughput text generation for llms via mii and deepspeed-inference. arXiv preprint arXiv:2401.08671 (2024)
-
[21]
Hooper, C.R.C., Kim, S., Mohammadzadeh, H., Mah- eswaran, M., Zhao, S., Paik, J., Mahoney, M.W., Keutzer, K., Gholami, A.: Squeezed attention: Accelerating long context length llm inference. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers). pp. 32631–32652 (2025)
work page 2025
-
[22]
arXiv preprint arXiv:2406.17565 (2024)
Hu, C., Huang, H., Hu, J., Xu, J., Chen, X., Xie, T., Wang, C., Wang, S., Bao, Y ., Sun, N., et al.: Mem- serve: Context caching for disaggregated llm serving with elastic memory pool. arXiv preprint arXiv:2406.17565 (2024)
-
[23]
ACM Transactions on Architecture and Code Optimization22(2), 1–24 (2025)
Hu, C., Huang, H., Xu, L., Chen, X., Wang, C., Xu, J., Chen, S., Feng, H., Wang, S., Bao, Y ., et al.: Shuffle- infer: Disaggregate llm inference for mixed downstream workloads. ACM Transactions on Architecture and Code Optimization22(2), 1–24 (2025)
work page 2025
-
[24]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Hyun, J., Hwang, S., Han, S.H., Kim, T., Lee, I., Wee, D., Lee, J.Y ., Kim, S.J., Shim, M.: Multi-granular spatio- temporal token merging for training-free acceleration of video llms. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 23990–24000 (2025)
work page 2025
-
[25]
Jang, D., Park, S., Yang, J.Y ., Jung, Y ., Yun, J., Kundu, S., Kim, S.Y ., Yang, E.: LANTERN: Accelerating vi- sual autoregressive models with relaxed speculative de- coding. In: The Thirteenth International Conference on Learning Representations (2025), https://openreview.net/ forum?id=98d7DLMGdt
work page 2025
-
[26]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Ji, Y ., Zhang, J., Xia, H., Chen, J., Shou, L., Chen, G., Li, H.: Specvlm: Enhancing speculative decoding of video llms via verifier-guided token pruning. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 7216–7230 (2025)
work page 2025
-
[27]
Jiang, A., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D., Casas, D., Bressand, F., Lengyel, G., Lam- ple, G., Saulnier, L., et al.: Mistral 7b. arxiv 2023. arXiv preprint arXiv:2310.06825 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jin, P., Takanobu, R., Zhang, W., Cao, X., Yuan, L.: Chat-univi: Unified visual representation empowers large language models with image and video understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13700–13710 (2024)
work page 2024
-
[29]
Kang, J., Shu, H., Li, W., Zhai, Y ., Chen, X.: Vis- pec: Accelerating vision-language models with vision- aware speculative decoding. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025), https://openreview.net/forum?id=x2BsIdJJJW
work page 2025
-
[30]
In: International conference on machine learning
Katharopoulos, A., Vyas, A., Pappas, N., Fleuret, F.: Transformers are rnns: Fast autoregressive transformers with linear attention. In: International conference on machine learning. pp. 5156–5165. PMLR (2020)
work page 2020
-
[31]
Kim, J.H., Yeom, J., Yun, S., Song, H.O.: Com- pressed context memory for online language model in- teraction. In: The Twelfth International Conference on Learning Representations (2024), https://openreview.net/ forum?id=64kSvC4iPg
work page 2024
-
[32]
In: Proceedings of the 29th symposium on operating systems principles
Kwon, W., Li, Z., Zhuang, S., Sheng, Y ., Zheng, L., Yu, C.H., Gonzalez, J., Zhang, H., Stoica, I.: Efficient mem- ory management for large language model serving with pagedattention. In: Proceedings of the 29th symposium on operating systems principles. pp. 611–626 (2023)
work page 2023
-
[33]
In: European Confer- ence on Computer Vision
Li, Y ., Wang, C., Jia, J.: Llama-vid: An image is worth 2 tokens in large language models. In: European Confer- ence on Computer Vision. pp. 323–340. Springer (2024)
work page 2024
-
[34]
Advances in Neural Information Processing Systems37, 22947– 22970 (2024)
Li, Y ., Huang, Y ., Yang, B., Venkitesh, B., Locatelli, A., Ye, H., Cai, T., Lewis, P., Chen, D.: Snapkv: Llm knows what you are looking for before generation. Advances in Neural Information Processing Systems37, 22947– 22970 (2024)
work page 2024
-
[35]
IEEE Transactions on Multimedia (2026)
Lin, B., Tang, Z., Ye, Y ., Huang, J., Zhang, J., Pang, Y ., Jin, P., Ning, M., Luo, J., Yuan, L.: Moe-llava: Mixture of experts for large vision-language models. IEEE Transactions on Multimedia (2026)
work page 2026
-
[36]
arXiv preprint arXiv:2401.02669 (2024)
Lin, B., Zhang, C., Peng, T., Zhao, H., Xiao, W., Sun, M., Liu, A., Zhang, Z., Li, L., Qiu, X., et al.: Infinite-llm: Ef- ficient llm service for long context with distattention and distributed kvcache. arXiv preprint arXiv:2401.02669 (2024)
-
[37]
Liu, H., Zaharia, M., Abbeel, P.: Ringattention with blockwise transformers for near-infinite context. In: The Twelfth International Conference on Learning Representations (2024), https://openreview.net/forum? id=WsRHpHH4s0
work page 2024
-
[38]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, H., Li, C., Li, Y ., Lee, Y .J.: Improved baselines with visual instruction tuning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26296–26306 (2024)
work page 2024
-
[39]
Advances in neural information processing systems 36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y .J.: Visual instruction tun- ing. Advances in neural information processing systems 36, 34892–34916 (2023)
work page 2023
-
[40]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, Z., Zhu, L., Shi, B., Zhang, Z., Lou, Y ., Yang, S., Xi, H., Cao, S., Gu, Y ., Li, D., et al.: Nvila: Efficient frontier visual language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4122–4134 (2025)
work page 2025
-
[41]
In: European Conference on Computer Vision
McKinzie, B., Gan, Z., Fauconnier, J.P., Dodge, S., Zhang, B., Dufter, P., Shah, D., Du, X., Peng, F., Belyi, A., et al.: Mm1: methods, analysis and insights from multimodal llm pre-training. In: European Conference on Computer Vision. pp. 304–323. Springer (2024)
work page 2024
-
[42]
In: Proceedings of the 41st International Conference on Machine Learning
Nawrot, P., Ła ´ncucki, A., Chochowski, M., Tarjan, D., Ponti, E.M.: Dynamic memory compression: retrofitting llms for accelerated inference. In: Proceedings of the 41st International Conference on Machine Learning. pp. 37396–37412 (2024)
work page 2024
-
[43]
arXiv preprint arXiv:2603.14549 (2026)
Pathak, S., Han, B.: Asap: Attention-shift-aware pruning for efficient lvlm inference. arXiv preprint arXiv:2603.14549 (2026)
-
[44]
Qin, Z., Cao, Y ., Lin, M., Hu, W., Fan, S., Cheng, K., Lin, W., Li, J.: CAKE: Cascading and adaptive KV cache eviction with layer preferences. In: The Thirteenth International Conference on Learning Representations (2025), https://openreview.net/forum?id=EQgEMAD4kv
work page 2025
-
[45]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
work page 2021
-
[46]
In: International con- ference on machine learning
Rajbhandari, S., Li, C., Yao, Z., Zhang, M., Aminabadi, R.Y ., Awan, A.A., Rasley, J., He, Y .: Deepspeed-moe: Advancing mixture-of-experts inference and training to power next-generation ai scale. In: International con- ference on machine learning. pp. 18332–18346. PMLR (2022)
work page 2022
-
[47]
In: Proceedings of the 41st International Conference on Machine Learning
Ribar, L., Chelombiev, I., Hudlass-Galley, L., Blake, C., Luschi, C., Orr, D.: Sparq attention: bandwidth-efficient llm inference. In: Proceedings of the 41st International Conference on Machine Learning. pp. 42558–42583 (2024)
work page 2024
-
[48]
Advances in Neural Information Processing Systems37, 68658–68685 (2024)
Shah, J., Bikshandi, G., Zhang, Y ., Thakkar, V ., Ramani, P., Dao, T.: Flashattention-3: Fast and accurate attention with asynchrony and low-precision. Advances in Neural Information Processing Systems37, 68658–68685 (2024)
work page 2024
-
[49]
In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision
Shang, Y ., Cai, M., Xu, B., Lee, Y .J., Yan, Y .: Llava- prumerge: Adaptive token reduction for efficient large multimodal models. In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision. pp. 22857– 22867 (2025)
work page 2025
-
[50]
Shao, K., Tao, K., Qin, C., You, H., Sui, Y ., Wang, H.: Holitom: Holistic token merging for fast video large lan- guage models. arXiv preprint arXiv:2505.21334 (2025)
-
[51]
arXiv preprint arXiv:2503.11187 (2025)
Shen, L., Gong, G., He, T., Zhang, Y ., Liu, P., Zhao, S., Ding, G.: Fastvid: Dynamic density pruning for fast video large language models. arXiv preprint arXiv:2503.11187 (2025)
-
[52]
In: International Confer- ence on Machine Learning
Shen, X., Xiong, Y ., Zhao, C., Wu, L., Chen, J., Zhu, C., Liu, Z., Xiao, F., Varadarajan, B., Bordes, F., et al.: Longvu: Spatiotemporal adaptive compression for long video-language understanding. In: International Confer- ence on Machine Learning. pp. 54582–54599. PMLR (2025)
work page 2025
-
[53]
In: International Conference on Machine Learning
Sheng, Y ., Zheng, L., Yuan, B., Li, Z., Ryabinin, M., Chen, B., Liang, P., R´e, C., Stoica, I., Zhang, C.: Flexgen: High-throughput generative inference of large language models with a single gpu. In: International Conference on Machine Learning. pp. 31094–31116. PMLR (2023)
work page 2023
-
[54]
In: Proceedings of the 31st International Conference on Computational Linguistics
Song, D., Wang, W., Chen, S., Wang, X., Guan, M.X., Wang, B.: Less is more: A simple yet effective token reduction method for efficient multi-modal llms. In: Proceedings of the 31st International Conference on Computational Linguistics. pp. 7614–7623 (2025)
work page 2025
-
[55]
In: Proceedings of the 41st International Con- ference on Machine Learning
Tang, J., Zhao, Y ., Zhu, K., Xiao, G., Kasikci, B., Han, S.: Quest: query-aware sparsity for efficient long-context llm inference. In: Proceedings of the 41st International Con- ference on Machine Learning. pp. 47901–47911 (2024)
work page 2024
-
[56]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Tao, K., Qin, C., You, H., Sui, Y ., Wang, H.: Dycoke: Dynamic compression of tokens for fast video large language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18992–19001 (2025)
work page 2025
-
[57]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozi `ere, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Alma- hairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
Advances in neural information processing systems30(2017)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: At- tention is all you need. Advances in neural information processing systems30(2017)
work page 2017
-
[60]
Wan, Z., Wu, X., Zhang, Y ., Xin, Y ., Tao, C., Zhu, Z., Wang, X., Luo, S., Xiong, J., Wang, L., Zhang, M.: $\text{D} {2}\text{O}$: Dynamic discriminative operations for efficient long-context inference of large language models. In: The Thirteenth International Con- ference on Learning Representations (2025), https:// openreview.net/forum?id=HzBfoUdjHt
work page 2025
-
[61]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wang, H., Nie, Y ., Ye, Y ., Wang, Y ., Li, S., Yu, H., Lu, J., Huang, C.: Dynamic-vlm: Simple dynamic vi- sual token compression for videollm. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 20812–20823 (2025)
work page 2025
-
[62]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Wang, X., Zhang, J., Wang, T., Zhang, H., Zheng, F.: Seeing more, saying more: Lightweight language experts are dynamic video token compressors. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 541–558 (2025)
work page 2025
-
[63]
arXiv preprint arXiv:2401.09486 (2024)
Wang, Y ., Xiao, Z.: Loma: Lossless compressed memory attention. arXiv preprint arXiv:2401.09486 (2024)
-
[64]
In: Proceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles
Wu, B., Liu, S., Zhong, Y ., Sun, P., Liu, X., Jin, X.: Loongserve: Efficiently serving long-context large language models with elastic sequence parallelism. In: Proceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles. pp. 640–654 (2024)
work page 2024
-
[65]
Fast distributed inference serving for large language models.arXiv preprint arXiv:2305.05920,
Wu, B., Zhong, Y ., Zhang, Z., Liu, S., Liu, F., Sun, Y ., Huang, G., Liu, X., Jin, X.: Fast distributed infer- ence serving for large language models. arXiv preprint arXiv:2305.05920 (2023)
-
[66]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Wu, Z., Chen, X., Pan, Z., Liu, X., Liu, W., Dai, D., Gao, H., Ma, Y ., Wu, C., Wang, B., et al.: Deepseek-vl2: Mixture-of-experts vision-language mod- els for advanced multimodal understanding. arXiv preprint arXiv:2412.10302 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
Advances in neural information processing systems37, 119638–119661 (2024)
Xiao, C., Zhang, P., Han, X., Xiao, G., Lin, Y ., Zhang, Z., Liu, Z., Sun, M.: Infllm: Training-free long-context extrapolation for llms with an efficient context memory. Advances in neural information processing systems37, 119638–119661 (2024)
work page 2024
-
[68]
Xiao, G., Tian, Y ., Chen, B., Han, S., Lewis, M.: Efficient streaming language models with attention sinks. In: The Twelfth International Conference on Learning Representations (2024), https://openreview.net/ forum?id=NG7sS51zVF
work page 2024
-
[69]
Xing, L., Huang, Q., Dong, X., Lu, J., Zhang, P., Zang, Y ., Cao, Y ., He, C., Wang, J., Wu, F., et al.: Pyramid- drop: Accelerating your large vision-language models via pyramid visual redundancy reduction. arXiv preprint arXiv:2410.17247 (2024)
-
[70]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yang, S., Chen, Y ., Tian, Z., Wang, C., Li, J., Yu, B., Jia, J.: Visionzip: Longer is better but not necessary in vision language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 19792– 19802 (2025)
work page 2025
-
[71]
Ye, L., Tao, Z., Huang, Y ., Li, Y .: Chunkattention: Efficient self-attention with prefix-aware kv cache and two-phase partition. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguis- tics (V olume 1: Long Papers). pp. 11608–11620 (2024)
work page 2024
-
[72]
In: 16th USENIX symposium on operating systems design and implementation (OSDI 22)
Yu, G.I., Jeong, J.S., Kim, G.W., Kim, S., Chun, B.G.: Orca: A distributed serving system for{Transformer- Based}generative models. In: 16th USENIX symposium on operating systems design and implementation (OSDI 22). pp. 521–538 (2022)
work page 2022
-
[73]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Yunzhuzhang, Lu, Y ., Wang, T., Rao, F., Yang, Y ., Zhu, L.: Flexselect: Flexible token selection for efficient long video understanding. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
work page 2025
-
[74]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language image pre-training. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11975–11986 (2023)
work page 2023
-
[75]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Zhang, H., Fu, Y .: Vqtoken: Neural discrete token repre- sentation learning for extreme token reduction in video large language models. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
work page 2025
-
[76]
In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision
Zhang, Q., Cheng, A., Lu, M., Zhang, R., Zhuo, Z., Cao, J., Guo, S., She, Q., Zhang, S.: Beyond text- visual attention: Exploiting visual cues for effective token pruning in vlms. In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision. pp. 20857– 20867 (2025)
work page 2025
-
[77]
Zhang, Y ., Fan, C.K., Ma, J., Zheng, W., Huang, T., Cheng, K., Gudovskiy, D., Okuno, T., Nakata, Y ., Keutzer, K., et al.: Sparsevlm: Visual token sparsifica- tion for efficient vision-language model inference. arXiv preprint arXiv:2410.04417 (2024)
-
[78]
Advances in Neural Information Processing Systems36, 34661–34710 (2023)
Zhang, Z., Sheng, Y ., Zhou, T., Chen, T., Zheng, L., Cai, R., Song, Z., Tian, Y ., R ´e, C., Barrett, C., et al.: H2o: Heavy-hitter oracle for efficient generative inference of large language models. Advances in Neural Information Processing Systems36, 34661–34710 (2023)
work page 2023
-
[79]
Advances in neural information processing systems37, 62557–62583 (2024)
Zheng, L., Yin, L., Xie, Z., Sun, C., Huang, J., Yu, C.H., Cao, S., Kozyrakis, C., Stoica, I., Gonzalez, J.E., et al.: Sglang: Efficient execution of structured language model programs. Advances in neural information processing systems37, 62557–62583 (2024)
work page 2024
-
[80]
Zheng, Z., Ji, X., Fang, T., Zhou, F., Liu, C., Peng, G.: Batchllm: Optimizing large batched llm inference with global prefix sharing and throughput-oriented token batching. arXiv preprint arXiv:2412.03594 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.