Recognition: no theorem link
Building evidence-based knowledge bases from full-text literature for disease-specific biomedical reasoning
Pith reviewed 2026-05-14 01:12 UTC · model grok-4.3
The pith
An LLM-assisted pipeline creates structured evidence graphs from full-text cancer literature.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EvidenceNet uses an LLM-assisted pipeline to extract experimentally grounded findings as structured evidence records, normalize biomedical entities, score evidence quality, and connect related records through typed semantic relations, yielding high-fidelity datasets and graphs for HCC and CRC that enable evidence-aware analysis and reuse.
What carries the argument
LLM-assisted pipeline that extracts structured evidence records from full-text literature and builds typed semantic graphs from them.
If this is right
- The graphs support retrieval-augmented question answering.
- Future link prediction and target prioritization become possible using the networks.
- The records retain study design, provenance, and quantitative support for better reasoning.
- High component fidelity metrics back the usability for biomedical tasks.
Where Pith is reading between the lines
- The method could be applied to other diseases to build a larger interconnected evidence network.
- These graphs might be merged with existing ontologies to improve entity normalization consistency.
- Automated scoring could allow continuous updating as new literature appears.
- Testing the pipeline on non-cancer domains would show if it generalizes beyond biomedicine.
Load-bearing premise
The LLM-assisted pipeline accurately extracts, normalizes, scores quality, and connects records without introducing systematic errors or model-specific biases that the reported validation metrics would miss.
What would settle it
Manual annotation of a sample of full-text papers revealing frequent errors in entity linking or relation typing below the claimed accuracies would falsify the high-fidelity claim.
Figures

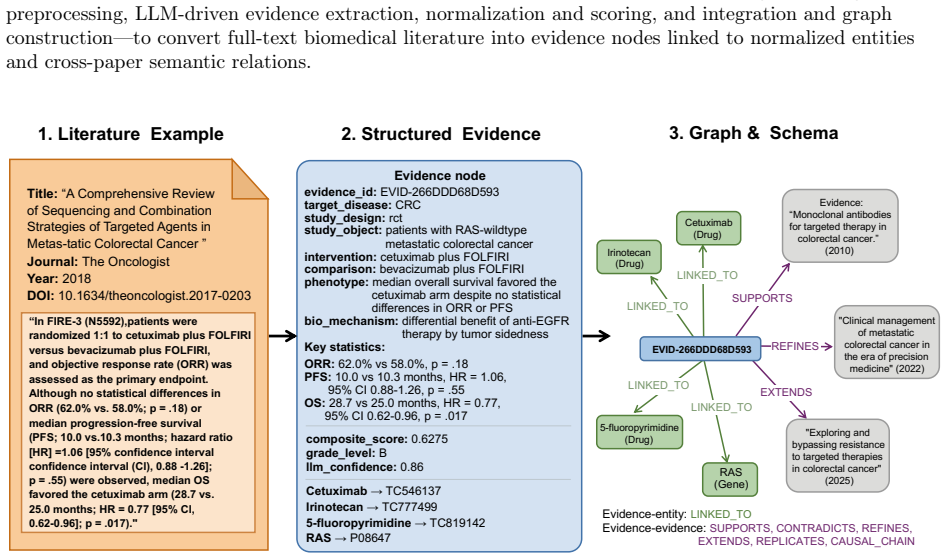
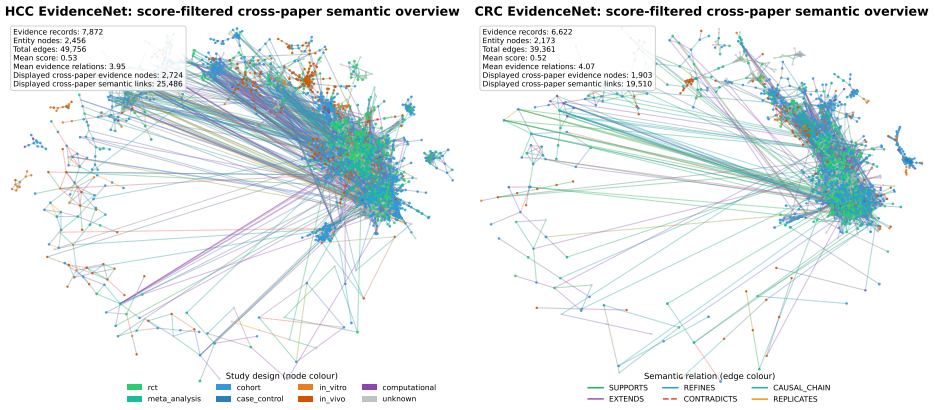


read the original abstract
Biomedical knowledge resources often either preserve evidence as unstructured text or compress it into flat triples that omit study design, provenance, and quantitative support. Here we present EvidenceNet, a disease-specific dataset of record-level evidence collections and corresponding graph representations derived from full-text biomedical literature. EvidenceNet uses a large language model (LLM)-assisted pipeline to extract experimentally grounded findings as structured evidence records, normalize biomedical entities, score evidence quality, and connect related records through typed semantic relations. We release EvidenceNet-HCC with 7,872 evidence records and a corresponding graph with 10,328 nodes and 49,756 edges, and EvidenceNet-CRC with 6,622 records and a corresponding graph with 8,795 nodes and 39,361 edges. Technical validation shows high component fidelity, including 98.3% field-level extraction accuracy, 100.0% high-confidence entity-link accuracy, 87.5% fusion integrity, and 90.0% semantic relation-type accuracy. Downstream analyses show that the data support retrieval-augmented question answering and graph-based tasks such as future link prediction and target prioritization. These results establish EvidenceNet as a disease-specific biomedical knowledge base dataset for evidence-aware analysis and reuse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EvidenceNet, a disease-specific biomedical knowledge base constructed from full-text literature via an LLM-assisted pipeline. The pipeline extracts structured evidence records (preserving study design, provenance, and quantitative details), normalizes entities, scores quality, and links records through typed semantic relations. It releases EvidenceNet-HCC (7,872 records; graph with 10,328 nodes, 49,756 edges) and EvidenceNet-CRC (6,622 records; graph with 8,795 nodes, 39,361 edges), reports technical validation metrics (98.3% field extraction accuracy, 100% high-confidence entity linking, 87.5% fusion integrity, 90% relation-type accuracy), and shows utility for retrieval-augmented QA and graph tasks such as link prediction and target prioritization.
Significance. If the validation holds, EvidenceNet provides a valuable, reusable resource that preserves richer evidence context than flat triples or unstructured text, supporting evidence-aware reasoning in specific diseases. The released graphs and downstream demonstrations (link prediction, prioritization) position it as a practical dataset for biomedical NLP and graph-based analyses.
major comments (1)
- [Abstract / Technical Validation] Abstract / Technical Validation: The reported metrics (98.3% field-level extraction accuracy, 100.0% high-confidence entity-link accuracy, 87.5% fusion integrity, 90.0% semantic relation-type accuracy) are presented without specifying the sampling frame, number of evaluated samples, inter-annotator agreement, or external gold-standard comparison. This is load-bearing for the central claim that the released graphs are reliable evidence collections, as it leaves open the possibility of undetected LLM-specific biases in quality scoring and fusion decisions propagating into the 49k-edge HCC graph.
minor comments (1)
- [Abstract] The abstract opening sentence would be clearer if it explicitly named the two target diseases (HCC and CRC) rather than deferring to the dataset names.
Simulated Author's Rebuttal
We thank the referee for their constructive review and positive assessment of EvidenceNet's potential as a reusable resource. We address the single major comment below and will incorporate the requested details into the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / Technical Validation] Abstract / Technical Validation: The reported metrics (98.3% field extraction accuracy, 100% high-confidence entity linking, 87.5% fusion integrity, 90% relation-type accuracy) are presented without specifying the sampling frame, number of evaluated samples, inter-annotator agreement, or external gold-standard comparison. This is load-bearing for the central claim that the released graphs are reliable evidence collections, as it leaves open the possibility of undetected LLM-specific biases in quality scoring and fusion decisions propagating into the 49k-edge HCC graph.
Authors: We agree that the current presentation of the technical validation metrics lacks sufficient methodological detail to allow full assessment of reliability and potential biases. In the revised manuscript we will expand the Technical Validation section (and add a dedicated subsection in Methods) to explicitly describe the sampling frame (stratified random sampling across study designs and publication years), the exact number of records manually reviewed for each metric, inter-annotator agreement scores between domain experts, and any external gold-standard comparisons performed. These additions will directly address concerns about undetected LLM-specific biases in quality scoring and fusion. revision: yes
Circularity Check
No circularity in LLM pipeline for evidence graph construction
full rationale
The paper constructs EvidenceNet datasets by applying an LLM-assisted extraction pipeline to external full-text literature, producing structured records, normalized entities, quality scores, and typed relations that are then assembled into graphs. The reported outputs (record counts, node/edge counts, and component-level accuracy metrics) are direct empirical results of this pipeline applied to source documents rather than quantities derived from fitted parameters, self-referential equations, or prior self-citations that reduce the claims to inputs by construction. Validation metrics are presented as separate fidelity checks on extraction, linking, fusion, and relation typing; they do not presuppose the final graph properties. No load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can extract structured evidence records from full-text biomedical literature with high field-level accuracy when guided by appropriate prompts.
Reference graph
Works this paper leans on
-
[1]
High-performance medicine: the convergence of human and artificial intelligence
Topol, Eric J. High-performance medicine: the convergence of human and artificial intelligence. Nature medicine25(1), 44–56 (2019)
work page 2019
-
[2]
Precision medicine and therapies of the future.Epilepsia62, S90–S105 (2021)
Sisodiya, Sanjay M. Precision medicine and therapies of the future.Epilepsia62, S90–S105 (2021). 21
work page 2021
-
[3]
Duffy, David J. Problems, challenges and promises: perspectives on precision medicine.Brief- ings in bioinformatics17(3), 494–504 (2016)
work page 2016
-
[4]
Bornmann, Lutz; Haunschild, Robin; Mutz, Rüdiger. Growth rates of modern science: a latent piecewise growth curve approach to model publication numbers from established and new literature databases.Humanities and Social Sciences Communications8(1), 224 (2021)
work page 2021
-
[5]
The landscape of biomedical research.Patterns5(6) (2024)
González-Márquez, Rita; Schmidt, Luca; Schmidt, Benjamin M; Berens, Philipp; Kobak, Dmitry. The landscape of biomedical research.Patterns5(6) (2024)
work page 2024
-
[6]
Goyal, Nandita; Singh, Navdeep. Named entity recognition and relationship extraction for biomedical text: A comprehensive survey, recent advancements, and future research directions. Neurocomputing618, 129171 (2025)
work page 2025
-
[7]
Stroganov, Oleg; Schedlbauer, Amber; Lorenzen, Emily; Kadhim, Alex; Lobanova, Anna; Lewis, David A; Glausier, Jill R. Unpacking unstructured data: A pilot study on extracting insights from neuropathological reports of Parkinson’s disease patients using large language models.Biology Methods and Protocols9(1), bpae072 (2024)
work page 2024
-
[8]
Seinen, Tom M; Fridgeirsson, Egill A; Ioannou, Solomon; Jeannetot, Daniel; John, Luis H; Kors, Jan A; Markus, Aniek F; Pera, Victor; Rekkas, Alexandros; Williams, Ross D; et al. Use of unstructured text in prognostic clinical prediction models: a systematic review.Journal of the American Medical Informatics Association29(7), 1292–1302 (2022)
work page 2022
-
[9]
Building a knowledge graph to enable preci- sion medicine.Scientific data10(1), 67 (2023)
Chandak, Payal; Huang, Kexin; Zitnik, Marinka. Building a knowledge graph to enable preci- sion medicine.Scientific data10(1), 67 (2023)
work page 2023
-
[10]
Himmelstein, Daniel Scott; Lizee, Antoine; Hessler, Christine; Brueggeman, Leo; Chen, Sab- rina L; Hadley, Dexter; Green, Ari; Khankhanian, Pouya; Baranzini, Sergio E. Systematic integration of biomedical knowledge prioritizes drugs for repurposing.eLife6, e26726 (2017). https://doi.org/10.7554/eLife.26726
-
[11]
Zhou, Cong; Cai, Chui-Pu; Huang, Xiao-Tian; Wu, Song; Yu, Jun-Lin; Wu, Jing-Wei; Fang, Jian-Song; Li, Guo-Bo. TarKG: a comprehensive biomedical knowledge graph for target dis- covery.Bioinformatics40(10), btae598 (2024)
work page 2024
-
[12]
The next generation of evidence-based medicine.Nature medicine29(1), 49–58 (2023)
Subbiah, Vivek. The next generation of evidence-based medicine.Nature medicine29(1), 49–58 (2023)
work page 2023
-
[13]
Formulating research questions for evidence-based studies
Hosseini, Mohammad-Salar; Jahanshahlou, Farid; Akbarzadeh, Mohammad Amin; Zarei, Mahdi; Vaez-Gharamaleki, Yosra. Formulating research questions for evidence-based studies. Journal of medicine, surgery, and public health2, 100046 (2024)
work page 2024
-
[14]
Armeni, Patrizio; Polat, Irem; De Rossi, Leonardo Maria; Diaferia, Lorenzo; Meregalli, Sev- erino; Gatti, Anna.Digitaltwinsinhealthcare: isitthebeginningofaneweraofevidence-based medicine? A critical review.Journal of personalized medicine12(8), 1255 (2022)
work page 2022
-
[15]
Jain, Ritu; Subramanian, Janakiraman; Rathore, Anurag S. A review of therapeutic failures in late-stage clinical trials.Expert Opinion on Pharmacotherapy24(3), 389–399 (2023)
work page 2023
-
[16]
Sun, Duxin; Gao, Wei; Hu, Hongxiang; Zhou, Simon. Why 90% of clinical drug development fails and how to improve it?Acta Pharmaceutica Sinica B12(7), 3049–3062 (2022). 22
work page 2022
-
[17]
Hallmarks of cancer: new dimensions.Cancer discovery12(1), 31–46 (2022)
Hanahan, Douglas. Hallmarks of cancer: new dimensions.Cancer discovery12(1), 31–46 (2022)
work page 2022
-
[18]
Kontomanolis, Emmanuel N; Koutras, Antonios; Syllaios, Athanasios; Schizas, Dimitrios; Mas- toraki, Aikaterini; Garmpis, Nikolaos; Diakosavvas, Michail; Angelou, Kyveli; Tsatsaris, Geor- gios; Pagkalos, Athanasios; et al. Role of oncogenes and tumor-suppressor genes in carcinogen- esis: a review.Anticancer research40(11), 6009–6015 (2020)
work page 2020
-
[19]
Amir-Behghadami, Mehrdad; Janati, Ali. Population, Intervention, Comparison, Outcomes and Study (PICOS) design as a framework to formulate eligibility criteria in systematic reviews. Emergency Medicine Journal(2020)
work page 2020
-
[20]
Brown, David. A review of the PubMed PICO tool: using evidence-based practice in health education.Health promotion practice21(4), 496–498 (2020)
work page 2020
-
[21]
Sutton, Reed T; Pincock, David; Baumgart, Daniel C; Sadowski, Daniel C; Fedorak, Richard N; Kroeker, Karen I. An overview of clinical decision support systems: benefits, risks, and strategies for success.NPJ digital medicine3(1), 17 (2020)
work page 2020
-
[22]
Clinical Decision-Support Sys- tems
Musen, Mark A; Middleton, Blackford; Greenes, Robert A. Clinical Decision-Support Sys- tems. InBiomedical Informatics: Computer Applications in Health Care and Biomedicine, pp. 795–840 (Springer International Publishing, Cham, 2021).https://doi.org/10.1007/ 978-3-030-58721-5_24
work page 2021
-
[23]
Lavecchia, Antonio. Explainable artificial intelligence in drug discovery: bridging predictive power and mechanistic insight.Wiley Interdisciplinary Reviews: Computational Molecular Sci- ence15(5), e70049 (2025)
work page 2025
-
[24]
Pham, Thai-Hoang; Qiu, Yue; Zeng, Jucheng; Xie, Lei; Zhang, Ping.Adeeplearningframework for high-throughput mechanism-driven phenotype compound screening and its application to COVID-19 drug repurposing.Nature machine intelligence3(3), 247–257 (2021)
work page 2021
-
[25]
Mohamed, S., Nováček, V. & Nounu, A. Discovering protein drug tar- gets using knowledge graph embeddings.Bioinformatics.36, 603-610 (2019,8), https://doi.org/10.1093/bioinformatics/btz600
-
[26]
Barabási, Albert-László; Gulbahce, Natali; Loscalzo, Joseph. Network medicine: a network- based approach to human disease.Nature reviews genetics12(1), 56–68 (2011)
work page 2011
-
[27]
Buphamalai, Pisanu; Kokotovic, Tomislav; Nagy, Vanja; Menche, Jörg. Network analysis re- veals rare disease signatures across multiple levels of biological organization.Nature communi- cations12(1), 6306 (2021)
work page 2021
-
[28]
Cha, Junha; Lee, Insuk. Single-cell network biology for resolving cellular heterogeneity in hu- man diseases.Experimental & molecular medicine52(11), 1798–1808 (2020)
work page 2020
-
[29]
Li, Qing; Geng, Shan; Luo, Hao; Wang, Wei; Mo, Ya-Qi; Luo, Qing; Wang, Lu; Song, Guan- Bin; Sheng, Jian-Peng; Xu, Bo. Signaling pathways involved in colorectal cancer: pathogenesis and targeted therapy.Signal Transduction and Targeted Therapy9(1), 266 (2024)
work page 2024
-
[30]
Zeng, Xuezhen; Ward, Simon E; Zhou, Jingying; Cheng, Alfred SL. Liver immune microen- vironment and metastasis from colorectal cancer-pathogenesis and therapeutic perspectives. Cancers13(10), 2418 (2021). 23
work page 2021
-
[31]
Large language models in medicine.Nature medicine 29(8), 1930–1940 (2023)
Thirunavukarasu, Arun James; Ting, Darren Shu Jeng; Elangovan, Kabilan; Gutierrez, Laura; Tan, Ting Fang; Ting, Daniel Shu Wei. Large language models in medicine.Nature medicine 29(8), 1930–1940 (2023)
work page 1930
-
[32]
The future landscape of large language models in medicine.Communications medicine3(1), 141 (2023)
Clusmann, Jan; Kolbinger, Fiona R; Muti, Hannah Sophie; Carrero, Zunamys I; Eckardt, Jan- Niklas; Laleh, Narmin Ghaffari; Löffler, Chiara Maria Lavinia; Schwarzkopf, Sophie-Caroline; Unger, Michaela; Veldhuizen, Gregory P; et al. The future landscape of large language models in medicine.Communications medicine3(1), 141 (2023)
work page 2023
-
[33]
Can large language models reason about medical questions?Patterns5(3) (2024)
Liévin, Valentin; Hother, Christoffer Egeberg; Motzfeldt, Andreas Geert; Winther, Ole. Can large language models reason about medical questions?Patterns5(3) (2024)
work page 2024
-
[34]
Large language models encode clinical knowledge.Nature620(7972), 172–180 (2023)
Singhal, Karan; Azizi, Shekoofeh; Tu, Tao; Mahdavi, S Sara; Wei, Jason; Chung, Hyung Won; Scales, Nathan; Tanwani, Ajay; Cole-Lewis, Heather; Pfohl, Stephen; et al. Large language models encode clinical knowledge.Nature620(7972), 172–180 (2023)
work page 2023
-
[35]
Song, Bosheng; Li, Fen; Liu, Yuansheng; Zeng, Xiangxiang. Deep learning methods for biomed- ical named entity recognition: a survey and qualitative comparison.Briefings in Bioinformatics 22(6), bbab282 (2021)
work page 2021
-
[36]
BERN2: an advanced neural biomedical named entity recognition and normalization tool
Sung, Mujeen; Jeong, Minbyul; Choi, Yonghwa; Kim, Donghyeon; Lee, Jinhyuk; Kang, Jaewoo. BERN2: an advanced neural biomedical named entity recognition and normalization tool. Bioinformatics38(20), 4837–4839 (2022)
work page 2022
-
[37]
Truhn, Daniel; Reis-Filho, Jorge; Kather, Jakob. Large language models should be used as scientific reasoning engines, not knowledge databases.Nature Medicine29(2023).https:// doi.org/10.1038/s41591-023-02594-z
-
[38]
Dagdelen, John; Dunn, Alexander; Lee, Sanghoon; Walker, Nicholas; Rosen, Andrew S; Ceder, Gerbrand; Persson, Kristin A; Jain, Anubhav. Structured information extraction from scientific text with large language models.Nature communications15(1), 1418 (2024)
work page 2024
-
[39]
Capa- bilities of gpt-4 on medical challenge problems
Nori, Harsha; King, Nicholas; McKinney, Scott Mayer; Carignan, Dean; Horvitz, Eric. Capabil- ities of GPT-4 on Medical Challenge Problems. (2023).https://arxiv.org/abs/2303.13375
-
[40]
Large lan- guage models are few-shot clinical information extractors
Agrawal, Monica; Hegselmann, Stefan; Lang, Hunter; Kim, Yoon; Sontag, David. Large lan- guage models are few-shot clinical information extractors. InProceedings of the 2022 Confer- ence on Empirical Methods in Natural Language Processing, pp. 1998–2022 (Association for Computational Linguistics, 2022).https://doi.org/10.18653/v1/2022.emnlp-main.130
-
[41]
Zero-Shot Information Extraction for Clinical Meta-Analysis using Large Language Models
Kartchner, David; Ramalingam, Selvi; Al-Hussaini, Irfan; Kronick, Olivia; Mitchell, Cassie. Zero-Shot Information Extraction for Clinical Meta-Analysis using Large Language Models. In Proceedings of the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks, pp. 396–405 (Association for Computational Linguistics, 2023).https://doi...
-
[42]
Hu, Danqing; Liu, Bing; Zhu, Xiaofeng; Lu, Xudong; Wu, Nan. Zero-shot information extrac- tion from radiological reports using ChatGPT.International Journal of Medical Informatics 183, 105321 (2024)
work page 2024
-
[43]
Chen, David; Alnassar, Saif Addeen; Avison, Kate Elizabeth; Huang, Ryan S; Raman, Srini- vas. Large language model applications for health information extraction in oncology: scoping review.JMIR cancer11, e65984 (2025). 24
work page 2025
-
[44]
Wang, Andy; Liu, Cong; Yang, Jingye; Weng, Chunhua. Fine-tuning large language models for rare disease concept normalization.Journal of the American Medical Informatics Association 31(9), 2076–2083 (2024)
work page 2076
-
[45]
OLaLa: Ontology Matching with Large Language Models
Hertling, Sven; Paulheim, Heiko. OLaLa: Ontology Matching with Large Language Models. In Proceedings of the 12th Knowledge Capture Conference 2023, pp.131–139(AssociationforCom- puting Machinery, New York, NY, USA, 2023).https://doi.org/10.1145/3587259.3627571
-
[46]
Shang, Yong; Tian, Yu; Lyu, Kewei; Zhou, Tianshu; Zhang, Ping; Chen, Jianghua; Li, Jingsong. Electronic health record–oriented knowledge graph system for collaborative clinical decision support using multicenter fragmented medical data: design and application study.Journal of Medical Internet Research26, e54263 (2024)
work page 2024
-
[47]
Jeong, Minbyul; Sohn, Jiwoong; Sung, Mujeen; Kang, Jaewoo. Improving medical reasoning through retrieval and self-reflection with retrieval-augmented large language models.Bioinfor- matics40(Supplement_1), i119–i129 (2024)
work page 2024
-
[48]
Zhao, Xuejiao; Liu, Siyan; Yang, Su-Yin; Miao, Chunyan. MedRAG: Enhancing Retrieval- augmented Generation with Knowledge Graph-Elicited Reasoning for Healthcare Copilot. In Proceedings of the ACM on Web Conference 2025, pp. 4442–4457 (Association for Computing Machinery, New York, NY, USA, 2025).https://doi.org/10.1145/3696410.3714782
-
[49]
Rationale-Guided Retrieval Augmented Generation for Medi- cal Question Answering
Sohn, Jiwoong; Park, Yein; Yoon, Chanwoong; Park, Sihyeon; Hwang, Hyeon; Sung, Mujeen; Kim, Hyunjae; Kang, Jaewoo. Rationale-Guided Retrieval Augmented Generation for Medi- cal Question Answering. InProceedings of the 2025 Conference of the Nations of the Ameri- cas Chapter of the Association for Computational Linguistics: Human Language Technologies (Vol...
-
[50]
Yan, Lian; Guan, Yi; Wang, Haotian; Lin, Yi; Yang, Yang; Wang, Boran; Jiang, Jingchi. Eirad: An evidence-based dialogue system with highly interpretable reasoning path for automatic diagnosis.IEEE Journal of Biomedical and Health Informatics28(10), 6141–6154 (2024)
work page 2024
-
[51]
Pub- MedQA: A dataset for biomedical research question answering
Jin, Qiao; Dhingra, Bhuwan; Liu, Zhengping; Cohen, William; Lu, Xinghua. PubMedQA: A Dataset for Biomedical Research Question Answering. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Con- ference on Natural Language Processing (EMNLP-IJCNLP), pp. 2567–2577 (Association for Computat...
-
[52]
Krithara, Anastasia; Nentidis, Anastasios; Bougiatiotis, Konstantinos; Paliouras, Georgios. BioASQ-QA: A manually curated corpus for Biomedical Question Answering.Scientific data 10(1), 170 (2023)
work page 2023
-
[53]
Evidence Inference 2.0: More Data, Better Models
DeYoung, Jay; Lehman, Eric; Nye, Benjamin; Marshall, Iain; Wallace, Byron C. Evidence Inference 2.0: More Data, Better Models. InProceedings of the 19th SIGBioMed Workshop on Biomedical Language Processing, pp. 123–132 (Association for Computational Linguistics, 2020).https://doi.org/10.18653/v1/2020.bionlp-1.13
-
[54]
node2vec: Scalable Feature Learning for Networks
Grover, Aditya; Leskovec, Jure. node2vec: Scalable Feature Learning for Networks. InPro- ceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 855–864 (Association for Computing Machinery, New York, NY, USA, 2016). https://doi.org/10.1145/2939672.2939754. 25
-
[55]
Semi-Supervised Classification with Graph Convolutional Networks
Kipf, Thomas N; Welling, Max. Semi-supervised classification with graph convolutional net- works.arXiv preprint arXiv:1609.02907(2016). Appendix A LLM prompts used in EvidenceNet To improve transparency and reproducibility, we summarize here the principal LLM prompts used in EvidenceNet construction and evaluation. Dynamic runtime content is represented b...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[56]
Only extract evidence explicitly stated in the text
-
[57]
If a paragraph contains multiple distinct experiments, extract them separately
-
[58]
The source_text field must be an exact verbatim quote
-
[59]
Do not treat background statements or prior work as new evidence
-
[60]
If a field is missing, set it to null. Output only valid JSON. Do not include markdown code blocks. [User prompt template] Extract all distinct pieces of experimental evidence from the following text segment (section: <SECTION>). Target disease context: <DISEASE> 26 Output a JSON object with a key "evidence" containing a list of evidence items. ### FEW-SH...
-
[61]
Fill in missing fields using information found elsewhere in the array
-
[62]
Add a "conflict_note" field only if two entries report directly contradictory numbers for the same metric
-
[63]
Remove only exact word-for-word duplicate entries
-
[64]
Keep all distinct experiments; do not merge experiments that merely study similar topics. Output a JSON object with a key "evidence" containing the list of enriched evidence items. Evidence to enrich: 27 <EVIDENCE JSON ARRAY> A.1.3 Prompt A3. Evidence-to-evidence relation verification. When rule-based semantic linking between evidence records was uncertai...
-
[65]
Generate a yes/no question that can be answered by this evidence
-
[66]
Provide the yes/no classification
-
[67]
Provide a concise explanation justified by the evidence. Output format (JSON): { "question": "Does [Intervention] cause [Outcome]...?", "class": "yes" or "no", "answer": "Yes. [Explanation...]" } A.2.2 Prompt A5. Retrieval-augmented QA answering. For QA evaluation, EvidenceNet was queried either alone or together with TarKG. The answering prompt required ...
-
[68]
- Relevant: direct mentions or conceptual matches
Filter the evidence. - Relevant: direct mentions or conceptual matches. 29 - Irrelevant: unrelated diseases or drugs
-
[69]
- If relevant evidence exists, answer based on it
Classify the answer as YES or NO. - If relevant evidence exists, answer based on it. - If all evidence is irrelevant, answer based on general knowledge rather than defaulting to "No"
-
[70]
Explain your reasoning and cite the evidence if used. OUTPUT FORMAT: CLASSIFICATION: [YES/NO] EXPLANATION: [Detailed reasoning] [EvidenceNet + TarKG version] You are an expert biomedical researcher. SOURCES: - EvidenceNet (Clinical Trials): specific experimental evidence - TarKG (Definitions): general biological definitions CONTEXT: <COMBINED_CONTEXT> QUE...
-
[71]
Filter the retrieved EvidenceNet evidence
-
[72]
Use TarKG for biological definitions if needed
-
[73]
- If relevant evidence exists, answer based on it
Classify the answer as YES or NO. - If relevant evidence exists, answer based on it. - If evidence is insufficient, answer using general biomedical knowledge. - Do not answer "No" solely because direct evidence is missing
-
[74]
Provide a brief explanation. OUTPUT FORMAT: CLASSIFICATION: [YES/NO] EXPLANATION: [Reasoning] [No-evidence fallback version] Question: <QUESTION> Task:
-
[75]
Classify the answer as YES or NO based on general biomedical knowledge
-
[76]
No specific evidence was found in the database, so rely entirely on internal knowledge. Output Format: CLASSIFICATION: [YES/NO] EXPLANATION: [Detailed explanation from general knowledge] 30
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.