Recognition: no theorem link
Fine-Tuning Large Language Models for Cooperative Tactical Deconfliction of Small Unmanned Aerial Systems
Pith reviewed 2026-05-14 21:35 UTC · model grok-4.3
The pith
Fine-tuning an LLM on air-traffic simulator data improves cooperative drone separation decisions and cuts near-collisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that supervised LoRA fine-tuning of the Qwen-Math-7B model on rule-consistent deconfliction datasets generated from the BlueSky simulator substantially improves decision accuracy, consistency, and separation performance in cooperative tactical deconfliction tasks for small unmanned aerial systems, producing significant reductions in near mid-air collisions relative to the pretrained model.
What carries the argument
The simulation-to-language data generation pipeline that turns BlueSky air-traffic simulator outputs into rule-consistent language datasets used to align LLM outputs with human operator heuristics for multi-agent deconfliction.
If this is right
- Supervised LoRA fine-tuning raises decision accuracy on validation datasets relative to the base model.
- The tuned models exhibit higher output consistency and improved aircraft separation in closed-loop simulations.
- Near mid-air collision counts drop significantly when the fine-tuned model is used for tactical deconfliction.
- Group-relative policy optimization adds coordination gains but reduces robustness against heterogeneous agent policies.
Where Pith is reading between the lines
- The method could support higher-density autonomous drone operations by shifting more separation responsibility from centralized controllers to onboard models.
- The same simulation-to-language pipeline might be reused for other safety-critical multi-agent tasks such as coordinated ground vehicle routing.
- Real-world deployment would still require additional handling of sensor noise, latency, and regulatory constraints not present in the simulator.
- Hybrid architectures that combine the fine-tuned LLM with formal verification layers could provide stronger safety guarantees.
Load-bearing premise
The simulation-to-language pipeline produces datasets that accurately reflect real safety practices and the resulting model will generalize to actual partially observable flight conditions.
What would settle it
A physical flight test in which the fine-tuned model controls multiple real sUAS in dense airspace and produces no measurable drop in near mid-air collision rate compared with the pretrained model.
Figures





read the original abstract
The growing deployment of small Unmanned Aerial Systems (sUASs) in low-altitude airspaces has increased the need for reliable tactical deconfliction under safety-critical constraints. Tactical deconfliction involves short-horizon decision-making in dense, partially observable, and heterogeneous multi-agent environments, where both cooperative separation assurance and operational efficiency must be maintained. While Large Language Models (LLMs) exhibit strong reasoning capabilities, their direct application to air traffic control remains limited by insufficient domain grounding and unpredictable output inconsistency. This paper investigates LLMs as decision-makers in cooperative multi-agent tactical deconfliction using fine-tuning strategies that align model outputs to human operator heuristics. We propose a simulation-to-language data generation pipeline based on the BlueSky air traffic simulator that produces rule-consistent deconfliction datasets reflecting established safety practices. A pretrained Qwen-Math-7B model is fine-tuned using two parameter-efficient strategies: supervised fine-tuning with Low-Rank Adaptation (LoRA) and preference-based fine-tuning combining LoRA with Group-Relative Policy Optimization (GRPO). Experimental results on validation datasets and closed-loop simulations demonstrate that supervised LoRA fine-tuning substantially improves decision accuracy, consistency, and separation performance compared to the pretrained LLM, with significant reductions in near mid-air collisions. GRPO provides additional coordination benefits but exhibits reduced robustness when interacting with heterogeneous agent policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a simulation-to-language data generation pipeline using the BlueSky air traffic simulator to create rule-consistent datasets for tactical deconfliction of sUAS. It fine-tunes a pretrained Qwen-Math-7B model via supervised LoRA and a combined LoRA+GRPO approach, then evaluates the resulting models on held-out validation data and closed-loop simulations, claiming substantial gains in decision accuracy, consistency, and reductions in near mid-air collisions relative to the base LLM, with GRPO offering extra coordination benefits at the cost of robustness under heterogeneous policies.
Significance. If the performance gains are reproducible and the simulation fidelity holds, the work would demonstrate a practical route for grounding LLMs in safety-critical multi-agent aviation tasks without full retraining. The simulation-to-language pipeline and parameter-efficient alignment to operator heuristics are technically interesting contributions that could inform future LLM deployment in robotics and air-traffic domains, though the absence of external validation currently caps the immediate significance.
major comments (3)
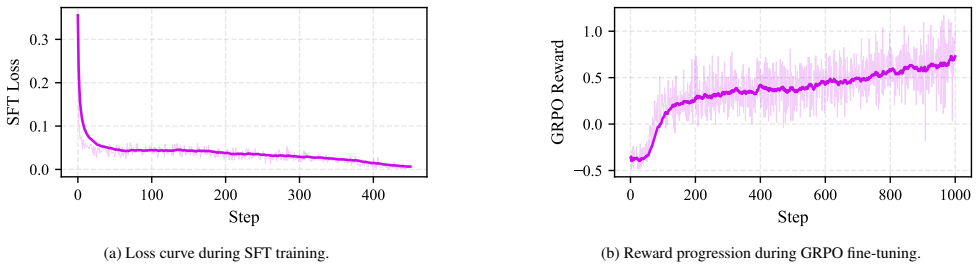
- [§4] §4 (Experimental Results) and abstract: the claimed improvements in decision accuracy, consistency, and NMAC reduction are stated without any numerical values, error bars, statistical tests, or data-exclusion criteria, preventing verification that the gains are load-bearing rather than artifacts of the evaluation protocol.
- [§3.2, §4.3] §3.2 and §4.3 (closed-loop simulations): all reported metrics are obtained inside the identical BlueSky environment used to synthesize the training language data, so the evaluation does not test generalization to sensor noise, wind, non-cooperative intruders, or communication dropouts; this directly undermines the claim that the fine-tuned models will perform in real partially observable heterogeneous settings.
- [§4.3] §4.3 (GRPO results): the statement that GRPO “exhibits reduced robustness when interacting with heterogeneous agent policies” is presented without quantitative metrics (e.g., NMAC rate increase, accuracy drop) or a controlled ablation that isolates the distributional shift, leaving the coordination-benefit claim unsupported.
minor comments (2)
- [§3.3] Notation for the preference dataset and reward model in the GRPO section is introduced without an explicit equation or pseudocode, making the training objective difficult to reconstruct.
- [Figure 5] Figure captions for the closed-loop trajectories do not specify the number of Monte-Carlo runs or the exact policy parameters of the baseline agents, reducing reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. We address each major comment below with point-by-point responses. We agree with several observations and will revise the manuscript accordingly to strengthen the presentation and temper claims where evidence is limited.
read point-by-point responses
-
Referee: §4 (Experimental Results) and abstract: the claimed improvements in decision accuracy, consistency, and NMAC reduction are stated without any numerical values, error bars, statistical tests, or data-exclusion criteria, preventing verification that the gains are load-bearing rather than artifacts of the evaluation protocol.
Authors: We agree that the abstract and the summary statements in §4 present the improvements only qualitatively. This was an oversight in the manuscript preparation. In the revised version we will insert the concrete numerical results (accuracy, consistency scores, NMAC rates), report standard deviations or error bars across repeated trials, include statistical significance tests, and explicitly state the data-exclusion criteria applied during evaluation. revision: yes
-
Referee: §3.2 and §4.3 (closed-loop simulations): all reported metrics are obtained inside the identical BlueSky environment used to synthesize the training language data, so the evaluation does not test generalization to sensor noise, wind, non-cooperative intruders, or communication dropouts; this directly undermines the claim that the fine-tuned models will perform in real partially observable heterogeneous settings.
Authors: We concur that all closed-loop results were generated inside the same BlueSky simulator used for data synthesis. Consequently, the current experiments do not address robustness to sensor noise, wind, non-cooperative agents, or communication dropouts. We will revise the manuscript to state this limitation explicitly, remove or qualify any language implying direct applicability to real-world partially observable heterogeneous settings, and frame the work as an initial demonstration within a controlled simulation environment. revision: yes
-
Referee: §4.3 (GRPO results): the statement that GRPO “exhibits reduced robustness when interacting with heterogeneous agent policies” is presented without quantitative metrics (e.g., NMAC rate increase, accuracy drop) or a controlled ablation that isolates the distributional shift, leaving the coordination-benefit claim unsupported.
Authors: The referee correctly notes that the robustness claim for GRPO lacks supporting numbers. In the revision we will add the specific quantitative metrics (NMAC rate increases and accuracy drops under heterogeneous policies) together with a description of the controlled ablation that isolates the distributional shift, thereby grounding the statement in the experimental data. revision: yes
Circularity Check
No significant circularity; empirical gains measured on held-out simulator data
full rationale
The paper generates training data via a BlueSky-based pipeline, fine-tunes a pretrained LLM with LoRA or GRPO, and reports accuracy/consistency/NMAC improvements on validation datasets plus closed-loop simulations. No equations, parameters, or self-citations reduce the reported gains to quantities defined by the same fitted values used in training. Evaluation follows standard held-out splits within the simulator; this is self-contained empirical validation rather than a definitional or fitted-input reduction. No load-bearing self-citation chains or ansatz smuggling appear in the derivation.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Separation Assurance between Heterogeneous Fleets of Small Unmanned Aerial Systems via Multi-Agent Reinforcement Learning
Heterogeneous drone fleets using independent attention-enhanced PPOA2C policies reach equilibria that maintain safe separation, outperforming some rule-based baselines but favoring stronger configurations.
-
Separation Assurance between Heterogeneous Fleets of Small Unmanned Aerial Systems via Multi-Agent Reinforcement Learning
Multi-agent RL policies for heterogeneous sUAS fleets reach equilibria for safe separation in package delivery simulations, outperforming some rule-based baselines but favoring stronger configurations.
Reference graph
Works this paper leans on
-
[1]
Qwen-Math: Mathematical Rea- soning Models from Alibaba Cloud AI
Alibaba Group AI Team. Qwen-Math: Mathematical Rea- soning Models from Alibaba Cloud AI. Technical report, Alibaba Group, 2024. 5
work page 2024
-
[2]
Concrete Problems in AI Safety, 2016
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Chris- tiano, John Schulman, and Dan Man ´e. Concrete Problems in AI Safety, 2016. 2
work page 2016
-
[3]
Automatic Control With Human-Like Reasoning: Exploring Language Model Embodied Air Traffic Agents
Justas Andriu ˇskeviˇcius and Junzi Sun. Automatic Control With Human-Like Reasoning: Exploring Language Model Embodied Air Traffic Agents. In14th SESAR Innovation Days, SIDS 2024, 2024. 2
work page 2024
-
[4]
Yuhang Bai, Zhihong Deng, Wei Liu, et al. Qwen Technical Report.arXiv preprint arXiv:2309.16609, 2023. 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Marc Brittain and Peng Wei. Autonomous separation as- surance in an high-density en route sector: A deep multi- agent reinforcement learning approach. In2019 IEEE In- telligent Transportation Systems Conference (ITSC), pages 3256–3262, 2019. 2
work page 2019
-
[6]
Fabio Suim Chagas, Neno Ruseno, and Aurilla Aure- lie Arntzen Bechina. Artificial Intelligence Approaches for UA V Deconfliction: A Comparative Review and Framework Proposal.Automation, 6(4), 2025. 1
work page 2025
-
[7]
Long Cheng, Bowen Zhou, and Xinyi Zhang. From Lan- guage to Action: A Review of Large Language Models as Autonomous Agents and Tool Users.Artificial Intelligence Review, 59:71, 2026. 1
work page 2026
-
[8]
The Use of Intent Information in an Airborne Self-Separation Assistance Display Design
Stijn Van Dam, Max Mulder, and Ren ´e Paassen. The Use of Intent Information in an Airborne Self-Separation Assistance Display Design. InAIAA Guidance, Navigation, and Control Conference, 2009. 1
work page 2009
-
[9]
What Did I Do Wrong? Quantifying LLMs’ Sensitivity and Consistency to Prompt Engineer- ing
Federico Errica, Davide Sanvito, Giuseppe Siracusano, and Roberto Bifulco. What Did I Do Wrong? Quantifying LLMs’ Sensitivity and Consistency to Prompt Engineer- ing. InProceedings of the 2025 Conference of the Na- tions of the Americas Chapter of the Association for Com- putational Linguistics: Human Language Technologies (Vol- ume 1: Long Papers), pages...
work page 2025
-
[10]
FAA Makes Drone History in Dallas Area, 2024
Federal Aviation Administration. FAA Makes Drone History in Dallas Area, 2024. 1
work page 2024
-
[11]
Amazon Prime Air Amendment to Operations Specifications (OpSpecs)
Federal Aviation Administration. Amazon Prime Air Amendment to Operations Specifications (OpSpecs). Tech- nical report, U.S. Department of Transportation, 2025. 4
work page 2025
-
[12]
Aviation-Specific Large Language Model Fine-Tuning and LLM-as-a-Judge Evalua- tion
Kathleen Ge and William Coupe. Aviation-Specific Large Language Model Fine-Tuning and LLM-as-a-Judge Evalua- tion. InAIAA AVIATION FORUM AND ASCEND 2025, page 3712, 2025. 2
work page 2025
-
[13]
Dewi Gould, George De Ath, Ben Carvell, and Nick Pepper. AirTrafficGen: Configurable Air Traffic Scenario Genera- tion with Large Language Models.ArXiv, abs/2508.02269,
-
[14]
Bryan Guan, Tanya Roosta, Peyman Passban, and Mehdi Rezagholizadeh. The Order Effect: Investigating Prompt Sensitivity to Input Order in LLMs.arXiv preprint arXiv:2502.04134, 2025. 1
-
[15]
BlueSky ATC Simula- tor Project: an Open Data and Open Source Approach
Jacco Hoekstra and Joost Ellerbroek. BlueSky ATC Simula- tor Project: an Open Data and Open Source Approach. 2016. 2, 3
work page 2016
-
[16]
J.M Hoekstra, R.N.H.W van Gent, and R.C.J Ruigrok. De- signing for safety: the ‘free flight’ air traffic management concept.Reliability Engineering & System Safety, 75(2): 215–232, 2002. 1
work page 2002
-
[17]
Hu, Yelong Shen, Phillip Wallis, et al
Edward J. Hu, Yelong Shen, Phillip Wallis, et al. LoRA: Low-Rank Adaptation of Large Language Models. InIn- ternational Conference on Learning Representations (ICLR),
-
[18]
Math- Prompter: Mathematical Reasoning using Large Language Models, 2023
Shima Imani, Liang Du, and Harsh Shrivastava. Math- Prompter: Mathematical Reasoning using Large Language Models, 2023. 1
work page 2023
-
[19]
Hantao Jiang et al. Training Large Language Models on Nar- row Tasks Can Lead to Broad Misalignment.Nature, 649: 584–589, 2026. 1
work page 2026
-
[20]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. InProceedings of the 36th International Conference on Neural Information Processing Systems, Red Hook, NY , USA, 2022. Curran Associates Inc. 1
work page 2022
-
[21]
Yucheng Liu. Large language models for air transportation: A critical review.Journal of the Air Transport Research So- ciety, 2:100024, 2024. 2
work page 2024
- [22]
-
[23]
Shayne Loft, Penelope Sanderson, Andrew Neal, and Mark Mooij. Modeling and Predicting Mental Workload in En Route Air Traffic Control: Critical Review and Broader Im- plications.Human Factors, 49(3):376–399, 2007. 1
work page 2007
-
[24]
Probing LLMs for Logical Reasoning
Francesco Manigrasso, Stefan Schouten, Lia Morra, and Pe- ter Bloem. Probing LLMs for Logical Reasoning. InNeural- Symbolic Learning and Reasoning: 18th International Con- ference, NeSy 2024, Proceedings, Part I, page 257–278, Berlin, Heidelberg, 2024. Springer-Verlag. 1
work page 2024
-
[25]
Y . L. Marquand. FAA Authorises Zipline and Wing for BV- LOS Operations in Dallas, 2024. 1
work page 2024
-
[26]
Training language models to follow instructions with human feedback
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Car- roll Wainwright, Pamela Mishkin, et al. Training language models to follow instructions with human feedback.arXiv preprint arXiv:2203.02155, 2022. 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Bizhao Pang, Kin Huat Low, and Chen Lv. Adaptive con- flict resolution for multi-UA V 4D routes optimization using stochastic fractal search algorithm.Transportation Research Part C: Emerging Technologies, 139:103666, 2022. 1
work page 2022
-
[28]
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
Qwen Team. Qwen2.5 Technical Report.arXiv preprint arXiv:2410.13848, 2024. 5
work page internal anchor Pith review arXiv 2024
-
[29]
Review of Conflict Resolution Methods for Manned and Unmanned Aviation.Aerospace, 7(6):79, 2020
Marta Ribeiro, Joost Ellerbroek, and Jacco Hoekstra. Review of Conflict Resolution Methods for Manned and Unmanned Aviation.Aerospace, 7(6):79, 2020. 1
work page 2020
-
[30]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandku- mar. V oyager: An Open-Ended Embodied Agent with Large Language Models.Transactions on Machine Learning Re- search, 2024. 1
work page 2024
-
[31]
Liya Wang, Jason Chou, Xin Zhou, Alex Tien, and Diane M. Baumgartner. AviationGPT: A Large Language Model for the Aviation Domain.ArXiv, abs/2311.17686, 2023. 2
-
[32]
Meet the drones taking delivery to new heights
Wing. Meet the drones taking delivery to new heights. https://wing.com/technology, 2024. Accessed: January 2026. 4
work page 2024
-
[33]
Liangqi Yuan, Chuhao Deng, Dong-Jun Han, Inseok Hwang, Sabine Brunswicker, and Christopher G. Brinton. Next- Generation LLM for UA V: From Natural Language to Au- tonomous Flight.arXiv preprint arXiv:2510.21739, 2025. 1 Supplementary Material This supplementary document accompanies the main paper and provides additional implementation details to support r...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.