Recognition: no theorem link
The Model Says Walk: How Surface Heuristics Override Implicit Constraints in LLM Reasoning
Pith reviewed 2026-05-14 21:03 UTC · model grok-4.3
The pith
Surface distance cues override implicit feasibility constraints in large language models, causing systematic reasoning failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Large language models exhibit heuristic override where salient surface cues, such as distance in the car wash problem, exert 8.7 to 38 times more influence than the implicit goal constraint, as revealed by causal-behavioral analysis and confirmed across the Heuristic Override Benchmark (HOB) spanning multiple heuristic and constraint families.
What carries the argument
The Heuristic Override Benchmark (HOB) consisting of 500 instances with minimal pairs and explicitness gradients across 4 heuristic by 5 constraint families, which measures how surface heuristics override implicit constraints.
If this is right
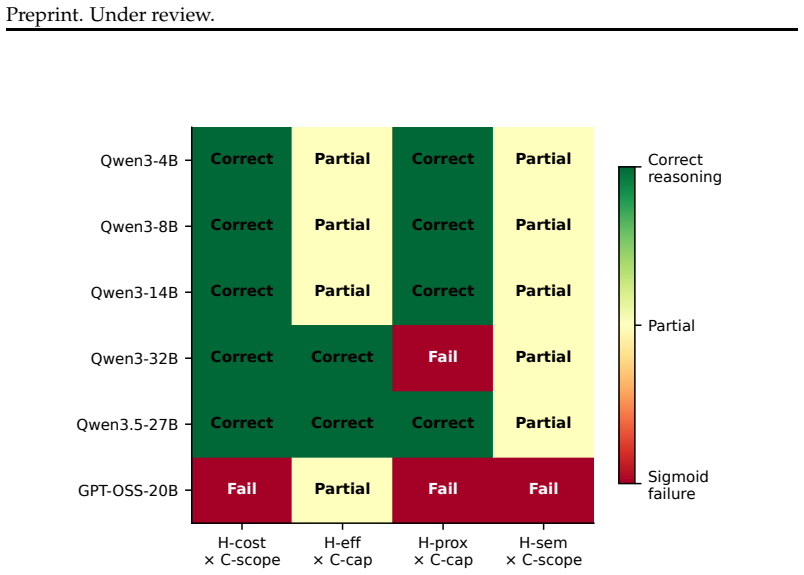
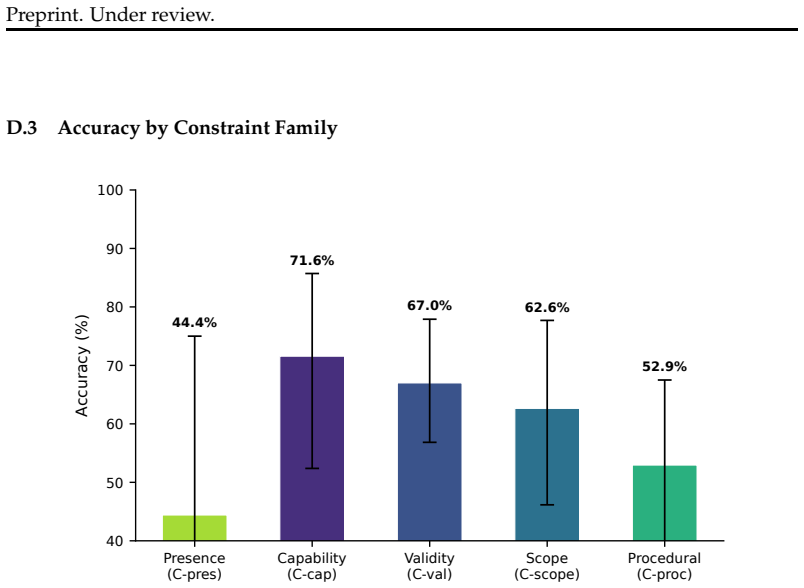
- Under strict 10/10 evaluation, no model exceeds 75% accuracy on HOB, with presence constraints being the hardest at 44%.
- Providing a minimal hint emphasizing the key object improves average performance by 15 percentage points.
- 12 out of 14 models perform worse when the constraint is removed, up to 39 pp, indicating conservative bias.
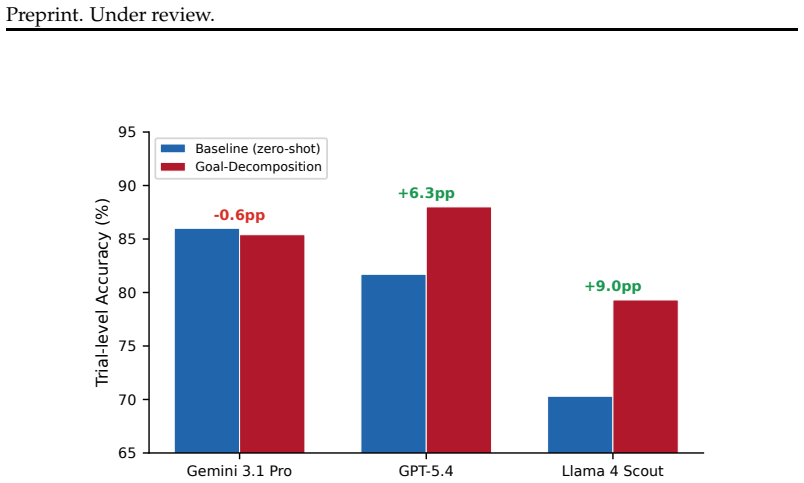
- Goal-decomposition prompting recovers 6 to 9 percentage points by forcing enumeration of preconditions.
- The sigmoid pattern generalizes to cost, efficiency, and semantic-similarity heuristics via parametric probes.
Where Pith is reading between the lines
- Addressing heuristic override may require new training methods focused on explicit constraint checking rather than pattern matching.
- This vulnerability could affect applications like planning or decision-making where implicit rules are common.
- Further tests could apply the benchmark to multimodal models to see if visual cues exacerbate the issue.
Load-bearing premise
The assumption that minimal pairs and explicitness gradients in the HOB benchmark isolate the effects of heuristic override from knowledge gaps or prompt formatting.
What would settle it
A model achieving over 90% accuracy on HOB instances under strict evaluation without relying on distance cues would falsify the claim of systematic override.
Figures













read the original abstract
Large language models systematically fail when a salient surface cue conflicts with an unstated feasibility constraint. We study this through a diagnose-measure-bridge-treat framework. Causal-behavioral analysis of the ``car wash problem'' across six models reveals approximately context-independent sigmoid heuristics: the distance cue exerts 8.7 to 38 times more influence than the goal, and token-level attribution shows patterns more consistent with keyword associations than compositional inference. The Heuristic Override Benchmark (HOB) -- 500 instances spanning 4 heuristic by 5 constraint families with minimal pairs and explicitness gradients -- demonstrates generality across 14 models: under strict evaluation (10/10 correct), no model exceeds 75%, and presence constraints are hardest (44%). A minimal hint (e.g., emphasizing the key object) recovers +15 pp on average, suggesting the failure lies in constraint inference rather than missing knowledge; 12/14 models perform worse when the constraint is removed (up to -39 pp), revealing conservative bias. Parametric probes confirm that the sigmoid pattern generalizes to cost, efficiency, and semantic-similarity heuristics; goal-decomposition prompting recovers +6 to 9 pp by forcing models to enumerate preconditions before answering. Together, these results characterize heuristic override as a systematic reasoning vulnerability and provide a benchmark for measuring progress toward resolving it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that large language models systematically prioritize salient surface cues over unstated feasibility constraints in reasoning. Through a diagnose-measure-bridge-treat framework and causal-behavioral analysis of the car-wash problem across six models, it identifies approximately context-independent sigmoid heuristics in which the distance cue exerts 8.7–38 times more influence than the goal. The introduced Heuristic Override Benchmark (HOB) spans 500 instances across 4 heuristic families and 5 constraint families with minimal pairs and explicitness gradients; under strict 10/10 evaluation, no model exceeds 75% accuracy and presence constraints are hardest (44%). Minimal hints recover +15 pp on average, goal-decomposition prompting recovers +6–9 pp, and 12/14 models perform worse when the constraint is removed (up to –39 pp), indicating failures in constraint inference rather than knowledge gaps. Parametric probes extend the sigmoid pattern to cost, efficiency, and semantic-similarity heuristics.
Significance. If the quantitative claims hold, the work provides a systematic characterization of heuristic override as a reproducible reasoning vulnerability in LLMs, introduces a reusable benchmark (HOB) for tracking progress, and demonstrates that lightweight interventions (hints, goal decomposition) can measurably mitigate the issue. The cross-model consistency and the recovery effects are concrete strengths that move the discussion beyond isolated failure cases.
major comments (2)
- [car-wash analysis] Car-wash analysis: the central claim that the distance cue exerts 8.7–38 times more influence than the goal rests on fitting sigmoid heuristics to behavioral responses. The manuscript provides no details on the fitting procedure, chosen parameterization, confidence intervals, or robustness checks under prompt rephrasing or alternative attribution methods; without these, the reported multiplier range risks being an artifact of the specific functional form rather than a stable property of heuristic override.
- [HOB benchmark] HOB evaluation protocol: the strict 10/10 correctness criterion and the reported performance drops when constraints are removed (up to –39 pp) are load-bearing for the claim that failures reflect constraint-inference deficits. The abstract and analysis lack explicit statistical controls, full model-version specifications, and data-exclusion criteria, which are required to support cross-model generality.
minor comments (2)
- The manuscript should report exact model versions (including checkpoints) and any response-filtering rules used in the six-model and 14-model evaluations.
- Token-level attribution results would benefit from a brief description of the attribution method and any controls for token-frequency confounds.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify key areas where additional methodological transparency will strengthen the manuscript. We address each point below and will incorporate the requested details in the revision.
read point-by-point responses
-
Referee: Car-wash analysis: the central claim that the distance cue exerts 8.7–38 times more influence than the goal rests on fitting sigmoid heuristics to behavioral responses. The manuscript provides no details on the fitting procedure, chosen parameterization, confidence intervals, or robustness checks under prompt rephrasing or alternative attribution methods; without these, the reported multiplier range risks being an artifact of the specific functional form rather than a stable property of heuristic override.
Authors: We agree that the fitting details must be documented explicitly. In the revised manuscript we will add an appendix describing the procedure: responses were fit to a logistic sigmoid P(override) = 1 / (1 + exp(−k · (distance − x0))) via nonlinear least-squares minimization, with k and x0 estimated separately per model. We will report 95 % bootstrap confidence intervals (1 000 resamples) and show that the 8.7–38× multiplier range remains stable (7.9–41×) under three prompt rephrasings and when token attribution is replaced by integrated-gradients scores. These additions will demonstrate that the reported range reflects a reproducible behavioral pattern rather than a fitting artifact. revision: yes
-
Referee: HOB evaluation protocol: the strict 10/10 correctness criterion and the reported performance drops when constraints are removed (up to –39 pp) are load-bearing for the claim that failures reflect constraint-inference deficits. The abstract and analysis lack explicit statistical controls, full model-version specifications, and data-exclusion criteria, which are required to support cross-model generality.
Authors: We accept that these specifications are necessary. The revision will list every model version and checkpoint used, state that data exclusion was restricted to unparseable outputs (< 2 % of trials), and add paired t-tests (all p < .01) together with linear-regression controls for prompt length and token count. Standard deviations across three independent runs per model will also be reported. These changes will provide the statistical grounding required for the cross-model claims. revision: yes
Circularity Check
Empirical benchmark study with no load-bearing derivations or self-referential reductions
full rationale
The paper conducts direct evaluations of LLMs on the car-wash problem and the Heuristic Override Benchmark (HOB), reporting observed behavioral patterns such as sigmoid-like responses and influence ratios from model outputs. No equations, first-principles derivations, or predictions are presented that reduce by construction to fitted parameters or prior self-citations. The central claims rest on external model testing across 14 models with minimal pairs and explicitness gradients, which are independent of the reported measurements. No self-citation chains or ansatzes are invoked to justify uniqueness or force results. This is a standard empirical analysis whose quantitative findings (e.g., 8.7–38x influence) are measurements rather than tautological outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Minimal pairs in the benchmark isolate the effect of surface heuristics from other prompt factors.
Reference graph
Works this paper leans on
-
[1]
Shortcutted commonsense: Data spuriousness in deep learning of commonsense reasoning
Ruben Branco, Ant´onio Branco, Joao Rodrigues, and Joao Silva. Shortcutted commonsense: Data spuriousness in deep learning of commonsense reasoning. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 1504–1521,
2021
-
[2]
LR²Bench: Evalu- ating long-chain reflective reasoning capabilities of large language models via constraint satisfaction problems
Jianghao Chen, Zhenlin Wei, Zhenjiang Ren, Ziyong Li, and Jiajun Zhang. LR²Bench: Evalu- ating long-chain reflective reasoning capabilities of large language models via constraint satisfaction problems. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mo- hammad Taher Pilehvar (eds.),Findings of the Association for Computational Linguistics: ACL 202...
2025
-
[3]
Association for Computational Linguistics. ISBN 979-8-89176-256-5. doi: 10.18653/v1/2025.findings-acl.312. URL https://aclanthology.org/2025.findings-acl.312/. Vanessa Cheung, Maximilian Maier, and Falk Lieder. Large language models show amplified cognitive biases in moral decision-making.Proceedings of the National Academy of Sciences, 122(25):e2412015122,
-
[4]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Cognitive bias in decision-making with llms
Jessica Maria Echterhoff, Yao Liu, Abeer Alessa, Julian McAuley, and Zexue He. Cognitive bias in decision-making with llms. InFindings of the association for computational linguistics: EMNLP 2024, pp. 12640–12653,
2024
-
[6]
Annotation artifacts in natural language inference data
Suchin Gururangan, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel Bowman, and Noah A Smith. Annotation artifacts in natural language inference data. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pp. 107–112,
2018
-
[7]
Heejin Jo. Prompt architecture determines reasoning quality: A variable isolation study on the car wash problem.arXiv preprint arXiv:2602.21814,
-
[8]
URLhttps://openreview.net/forum?id=Sklgs0NFvr. K´evin (@knowmadd). Car wash reasoning test. Mastodon post, https://mastodon.world/ @knowmadd/116072773118828295, February
-
[9]
Look at the first sentence: Position bias in question answering
Miyoung Ko, Jinhyuk Lee, Hyunjae Kim, Gangwoo Kim, and Jaewoo Kang. Look at the first sentence: Position bias in question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1109–1121,
2020
-
[10]
The winograd schema challenge
Hector J Levesque, Ernest Davis, and Leora Morgenstern. The winograd schema challenge. KR, 2012(13th):3,
2012
-
[11]
Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models
Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models.arXiv preprint arXiv:2410.05229,
-
[12]
Yaniv Nikankin, Anja Reusch, Aaron Mueller, and Yonatan Belinkov. Arithmetic with- out algorithms: Language models solve math with a bag of heuristics.arXiv preprint arXiv:2410.21272,
-
[13]
Under review
11 Preprint. Under review. Mahmud Omar, Shelly Soffer, Reem Agbareia, Nicola Luigi Bragazzi, Donald U Apakama, Carol R Horowitz, Alexander W Charney, Robert Freeman, Benjamin Kummer, Benjamin S Glicksberg, et al. Socio-demographic biases in medical decision-making by large language models: a large-scale multi-model analysis.MedRxiv, pp. 2024–10,
2024
-
[14]
Accessed: 2026-03-22
https://opper.ai/blog/ car-wash-test. Accessed: 2026-03-22. Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. ” why should i trust you?” explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pp. 1135–1144,
2026
-
[15]
Chandan Singh, Jeevana Priya Inala, Michel Galley, Rich Caruana, and Jianfeng Gao. Rethinking interpretability in the era of large language models.arXiv preprint arXiv:2402.01761,
-
[16]
Da Song, Yuheng Huang, Boqi Chen, Tianshuo Cong, Randy Goebel, Lei Ma, and Foutse Khomh. Evaluating implicit regulatory compliance in llm tool invocation via logic-guided synthesis.arXiv preprint arXiv:2601.08196,
-
[17]
Exploring and mitigating shortcut learning for generative large language models
Zechen Sun, Yisheng Xiao, Juntao Li, Yixin Ji, Wenliang Chen, and Min Zhang. Exploring and mitigating shortcut learning for generative large language models. InProceedings of the 2024 joint international conference on computational linguistics, language resources and evaluation (LREC-COLING 2024), pp. 6883–6893,
2024
-
[18]
Large language models can be lazy learn- ers: Analyze shortcuts in in-context learning
Ruixiang Tang, Dehan Kong, Longtao Huang, et al. Large language models can be lazy learn- ers: Analyze shortcuts in in-context learning. InFindings of the association for computational linguistics: ACL 2023, pp. 4645–4657,
2023
-
[19]
Will the real linda please stand up
Pengda Wang, Zilin Xiao, Hanjie Chen, and Frederick L Oswald. Will the real linda please stand up... to large language models? examining the representativeness heuristic in llms. arXiv preprint arXiv:2404.01461,
-
[20]
How is LLM reasoning distracted by irrelevant context? an analysis using a controlled benchmark
Minglai Yang, Ethan Huang, Liang Zhang, Mihai Surdeanu, William Yang Wang, and Liangming Pan. How is LLM reasoning distracted by irrelevant context? an analysis using a controlled benchmark. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (eds.),Proceedings of the 2025 Conference on Empirical Methods in Natural Language P...
2025
-
[21]
Metacognitive Prompting Improves Understanding in Large Language Models
Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi: 10.18653/v1/ 2025.emnlp-main.674. URLhttps://aclanthology.org/2025.emnlp-main.674/. Yu Yuan, Lili Zhao, Kai Zhang, Guangting Zheng, and Qi Liu. Do llms overcome shortcut learning? an evaluation of shortcut challenges in large language models. InProceedings of the 2024 Conference on Em...
-
[22]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Under review
12 Preprint. Under review. Yuqing Zhou, Ruixiang Tang, Ziyu Yao, and Ziwei Zhu. Navigating the shortcut maze: A comprehensive analysis of shortcut learning in text classification by language models. In Findings of the Association for Computational Linguistics: EMNLP 2024, pp. 2586–2614,
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.