Recognition: no theorem link
Security in LLM-as-a-Judge: A Comprehensive SoK
Pith reviewed 2026-05-14 00:09 UTC · model grok-4.3
The pith
LLM-as-a-Judge systems face security risks as both targets of attacks and tools for launching them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
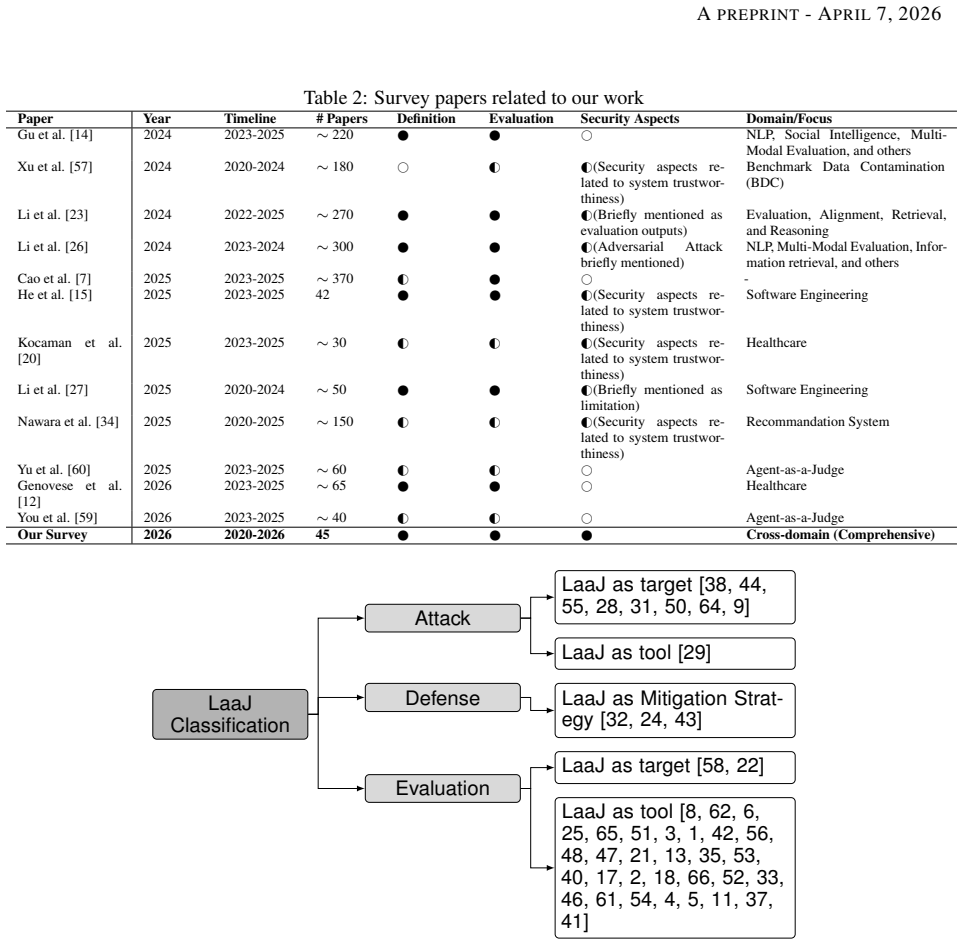
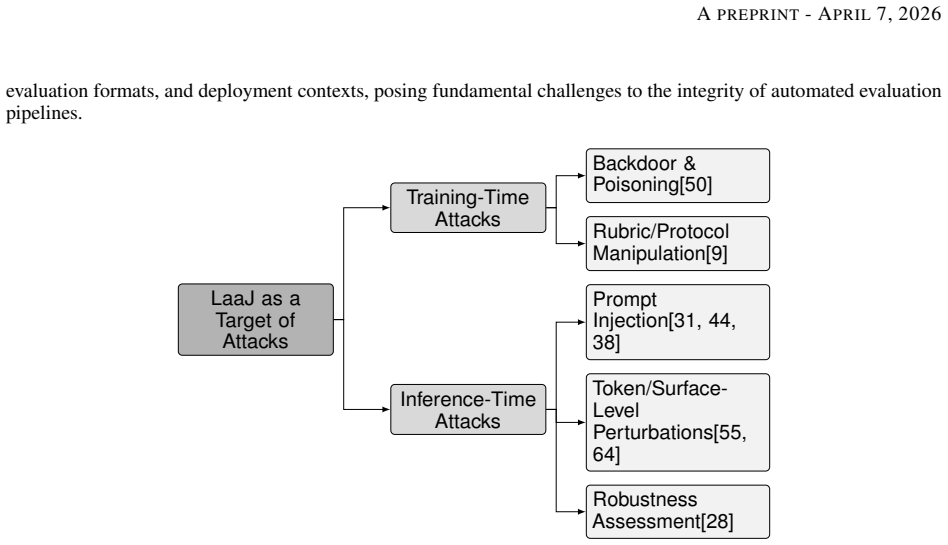
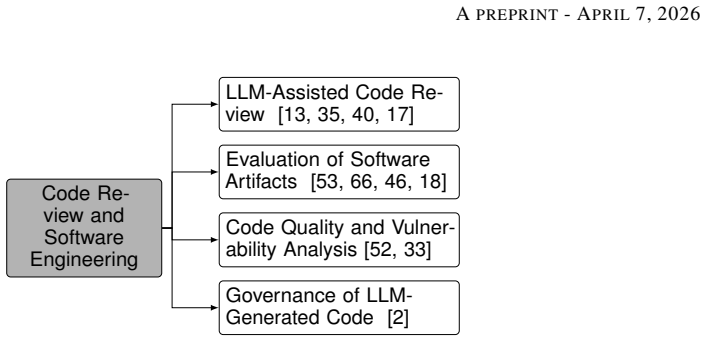
The paper claims that LLM-as-a-Judge systems introduce distinct security risks that previous work has not yet organized. By reviewing the selected studies it shows these risks fall into four roles: the judge as target of manipulation, the judge as instrument for attacks, the judge as component in defenses, and the judge as evaluator in security tasks. Comparative analysis of the 45 papers reveals shared limitations, emerging threats, and open challenges for making such systems more robust.
What carries the argument
A four-role taxonomy that places each use of LLM-as-a-Judge into one of four positions within the security landscape: target, attack vector, defense mechanism, or application tool.
Load-bearing premise
The 45 chosen studies from the initial 863 works fully capture the security landscape of LLM-as-a-Judge without major omissions or selection bias.
What would settle it
A new survey that identifies a sizable set of LaaJ security papers from 2020-2026 whose threats or defenses fall outside all four roles in the taxonomy.
Figures





read the original abstract
LLM-as-a-Judge (LaaJ) is a novel paradigm in which powerful language models are used to assess the quality, safety, or correctness of generated outputs. While this paradigm has significantly improved the scalability and efficiency of evaluation processes, it also introduces novel security risks and reliability concerns that remain largely unexplored. In particular, LLM-based judges can become both targets of adversarial manipulation and instruments through which attacks are conducted, potentially compromising the trustworthiness of evaluation pipelines. In this paper, we present the first Systematization of Knowledge (SoK) focusing on the security aspects of LLM-as-a-Judge systems. We perform a comprehensive literature review across major academic databases, analyzing 863 works and selecting 45 relevant studies published between 2020 and 2026. Based on this study, we propose a taxonomy that organizes recent research according to the role played by LLM-as-a-Judge in the security landscape, distinguishing between attacks targeting LaaJ systems, attacks performed through LaaJ, defenses leveraging LaaJ for security purposes, and applications where LaaJ is used as an evaluation strategy in security-related domains. We further provide a comparative analysis of existing approaches, highlighting current limitations, emerging threats, and open research challenges. Our findings reveal significant vulnerabilities in LLM-based evaluation frameworks, as well as promising directions for improving their robustness and reliability. Finally, we outline key research opportunities that can guide the development of more secure and trustworthy LLM-as-a-Judge systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to present the first Systematization of Knowledge (SoK) on the security aspects of LLM-as-a-Judge (LaaJ) systems. It conducts a literature review across major academic databases, analyzing 863 works and selecting 45 relevant studies published between 2020 and 2026. Based on this review, the authors propose a taxonomy organizing research by the role of LaaJ in the security landscape: attacks targeting LaaJ systems, attacks performed through LaaJ, defenses leveraging LaaJ for security purposes, and applications where LaaJ serves as an evaluation strategy in security-related domains. The work includes a comparative analysis of approaches, identification of limitations and emerging threats, and an outline of open research challenges and opportunities for improving robustness and trustworthiness of LaaJ systems.
Significance. If the selection of 45 studies is comprehensive and the four-role taxonomy accurately partitions the space without material omissions, this SoK would provide a timely synthesis of an emerging area, highlighting vulnerabilities in LLM-based evaluation pipelines and identifying directions for more secure systems. The systematic literature review approach and focus on security-specific roles represent a clear organizational contribution to the field.
major comments (2)
- [Abstract] Abstract: The claim of analyzing 863 works and selecting 45 relevant studies is presented without any details on search strings, databases queried, inclusion/exclusion criteria, screening process, or inter-rater reliability. This is load-bearing for the 'first SoK' and 'comprehensive' assertions, as it leaves the taxonomy's grounding and coverage unverifiable and open to potential bias or omissions (e.g., post-2024 works or non-English sources).
- [Taxonomy and comparative analysis sections] Taxonomy presentation (throughout the comparative analysis sections): The four-role taxonomy is introduced as organizing the security landscape, but the manuscript provides no explicit justification, coverage analysis, or discussion of boundary cases to demonstrate that it partitions the space without significant gaps, such as LaaJ uses in red-teaming that may not fit neatly into the defined roles.
minor comments (1)
- [Abstract] Abstract: The date range 'published between 2020 and 2026' includes future years; clarify whether this reflects a projection, preprint inclusion, or typographical issue.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our SoK. We agree that greater transparency on the literature review process and explicit justification for the taxonomy will strengthen the paper. We will make the requested revisions in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of analyzing 863 works and selecting 45 relevant studies is presented without any details on search strings, databases queried, inclusion/exclusion criteria, screening process, or inter-rater reliability. This is load-bearing for the 'first SoK' and 'comprehensive' assertions, as it leaves the taxonomy's grounding and coverage unverifiable and open to potential bias or omissions (e.g., post-2024 works or non-English sources).
Authors: We agree the abstract should include a concise summary of the methodology to support the claims. The full manuscript (Section 2) already details the process: search strings such as ('LLM-as-a-Judge' OR 'LLM judge') AND (security OR adversarial OR robustness), databases (IEEE Xplore, ACM DL, arXiv, Google Scholar), inclusion criteria (2020-2026 peer-reviewed works focused on LaaJ security, excluding non-English and purely capability-focused papers), two-author PRISMA-style screening, and inter-rater reliability (Cohen's kappa = 0.82). We will revise the abstract to state: 'following a systematic PRISMA-guided review of 863 papers across major databases with explicit inclusion criteria, yielding 45 studies.' This makes the grounding verifiable while preserving the 'first SoK' claim. revision: yes
-
Referee: [Taxonomy and comparative analysis sections] Taxonomy presentation (throughout the comparative analysis sections): The four-role taxonomy is introduced as organizing the security landscape, but the manuscript provides no explicit justification, coverage analysis, or discussion of boundary cases to demonstrate that it partitions the space without significant gaps, such as LaaJ uses in red-teaming that may not fit neatly into the defined roles.
Authors: We acknowledge that an explicit justification subsection would improve clarity. The taxonomy is derived from the distinct functional roles observed across the 45 papers (target of attacks, vector for attacks, defensive mechanism, and evaluation tool in security domains), as motivated in the introduction and elaborated with comparative tables in Sections 4-7 that assign every selected paper without overlap. Red-teaming examples are covered under 'attacks performed through LaaJ' when LaaJ generates or evaluates adversarial prompts. We will add a new subsection (3.1) providing (a) derivation rationale from the reviewed literature, (b) coverage analysis confirming no material omissions in the 45 papers, and (c) explicit discussion of boundary cases including red-teaming, hybrid uses, and why they map to the four roles. This addresses the partition concern directly. revision: yes
Circularity Check
No circularity: pure literature synthesis with no derivations or self-referential reductions
full rationale
This SoK paper performs a literature review (863 works screened to 45) and proposes a four-role taxonomy for security aspects of LLM-as-a-Judge. No equations, fitted parameters, predictions, or derivations exist. The central claim of being the 'first SoK' rests on the external review process and selection criteria rather than any internal construction that reduces to its own inputs by definition. No self-citation chains, ansatzes, or renamings of known results are load-bearing in a circular manner. The work is self-contained against external benchmarks as a synthesis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 45 selected studies adequately represent the key security research on LLM-as-a-Judge published 2020-2026
Reference graph
Works this paper leans on
-
[1]
Alignllm: Alignment-based evaluation using ensemble of llms-as-judges for q&a
Ramitha Abeyratne, Nirmalie Wiratunga, Kyle Martin, Ikechukwu Nkisi-Orji, and Lasal Jayawardena. Alignllm: Alignment-based evaluation using ensemble of llms-as-judges for q&a. InInternational conference on case-based reasoning, pages 21–36. Springer, 2025
work page 2025
-
[2]
Llm-based explainable detection of llm-generated code in python programming courses
Jeonghun Baek, Tetsuro Yamazaki, Akimasa Morihata, Junichiro Mori, Yoko Yamakata, Kenjiro Taura, and Shigeru Chiba. Llm-based explainable detection of llm-generated code in python programming courses. In Proceedings of the 57th ACM Technical Symposium on Computer Science Education V . 1, pages 80–86, 2026
work page 2026
-
[3]
Krisztian Balog, Don Metzler, and Zhen Qin. Rankers, judges, and assistants: Towards understanding the interplay of llms in information retrieval evaluation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 3865–3875, 2025. 27 APREPRINT- APRIL7, 2026
work page 2025
-
[4]
Loris Belcastro, Carmine Carlucci, Cristian Cosentino, Pietro Liò, and Fabrizio Marozzo. Enhancing network security using knowledge graphs and large language models for explainable threat detection.Future Generation Computer Systems, page 108160, 2025
work page 2025
-
[5]
Francesco Blefari, Cristian Cosentino, Francesco Aurelio Pironti, Angelo Furfaro, and Fabrizio Marozzo. Cyberrag: An agentic rag cyber attack classification and reporting tool.Future Generation Computer Systems, page 108186, 2025
work page 2025
-
[6]
Riccardo Cantini, Alessio Orsino, Massimo Ruggiero, and Domenico Talia. Benchmarking adversarial robustness to bias elicitation in large language models: Scalable automated assessment with llm-as-a-judge.Machine Learning, 114(11):249, 2025
work page 2025
-
[7]
Yixin Cao, Shibo Hong, Xinze Li, Jiahao Ying, Yubo Ma, Haiyuan Liang, Yantao Liu, Zijun Yao, Xiaozhi Wang, Dan Huang, et al. Toward generalizable evaluation in the llm era: A survey beyond benchmarks.arXiv preprint arXiv:2504.18838, 2025
-
[8]
Toward holistic evaluation of recommender systems powered by generative models
Yashar Deldjoo, Nikhil Mehta, Maheswaran Sathiamoorthy, Shuai Zhang, Pablo Castells, and Julian McAuley. Toward holistic evaluation of recommender systems powered by generative models. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 3932–3942, 2025
work page 2025
-
[9]
Rubrics as an attack surface: Stealthy preference drift in llm judges, 2026
Ruomeng Ding, Yifei Pang, He Sun, Yizhong Wang, Zhiwei Steven Wu, and Zhun Deng. Rubrics as an attack surface: Stealthy preference drift in llm judges, 2026
work page 2026
-
[10]
A survey on in-context learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, et al. A survey on in-context learning. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 1107–1128, 2024
work page 2024
-
[11]
Yasir Ali Farrukh, Syed Wali, Irfan Khan, and Nathaniel D Bastian. Xg-nid: Dual-modality network intrusion detection using a heterogeneous graph neural network and large language model.Expert Systems with Applications, 287:128089, 2025
work page 2025
-
[12]
Ariana Genovese, Lars Hegstrom, Srinivasagam Prabha, Cesar A Gomez-Cabello, Syed Ali Haider, Bernardo Collaco, Nadia G Wood, and Antonio Jorge Forte. Artificial authority: The promise and perils of llm judges in healthcare.Bioengineering, 13(1):108, 2026
work page 2026
-
[13]
Saul Goldman, Hong Yi Lin, Jirat Pasuksmit, Patanamon Thongtanunam, Kla Tantithamthavorn, Zhe Wang, Ray Zhang, Ali Behnaz, Fan Jiang, Michael Siers, et al. What types of code review comments do developers most frequently resolve? In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 3760–3765. IEEE, 2025
work page 2025
-
[14]
A survey on llm-as-a-judge.The Innovation, 2024
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al. A survey on llm-as-a-judge.The Innovation, 2024
work page 2024
-
[15]
Junda He, Jieke Shi, Terry Yue Zhuo, Christoph Treude, Jiamou Sun, Zhenchang Xing, Xiaoning Du, and David Lo. Llm-as-a-judge for software engineering: Literature review, vision, and the road ahead.ACM Transactions on Software Engineering and Methodology, 2025
work page 2025
-
[16]
Detecting chatgpt-generated code submissions in a cs1 course using machine learning models
Muntasir Hoq, Yang Shi, Juho Leinonen, Damilola Babalola, Collin Lynch, Thomas Price, and Bita Akram. Detecting chatgpt-generated code submissions in a cs1 course using machine learning models. InProceedings of the 55th ACM Technical Symposium on Computer Science Education V . 1, SIGCSE 2024, page 526–532, New York, NY , USA, 2024. Association for Computi...
work page 2024
-
[17]
Combining large language models with static analyzers for code review generation
Imen Jaoua, Oussama Ben Sghaier, and Houari Sahraoui. Combining large language models with static analyzers for code review generation. In2025 IEEE/ACM 22nd International Conference on Mining Software Repositories (MSR), pages 174–186. IEEE, 2025
work page 2025
-
[18]
Hao Ji, Kotha Aditya, Sebastian Escalante, and Yunjian Qiu. Codegen-3d: A benchmark for evaluating llms in zero-shot and iterative 3d modeling in blender.IEEE Access, 2026
work page 2026
-
[19]
Enkelejda Kasneci, Kathrin Seßler, Stefan Küchemann, Maria Bannert, Daryna Dementieva, Frank Fischer, Urs Gasser, Georg Groh, Stephan Günnemann, Eyke Hüllermeier, et al. Chatgpt for good? on opportunities and challenges of large language models for education.Learning and individual differences, 103:102274, 2023
work page 2023
-
[20]
Veysel Kocaman, Mustafa Aytu˘g Kaya, Andrei Marian Feier, and David Talby. Clinical large language model evaluation by expert review (clever): Framework development and validation.JMIR AI, 4(1):e72153, 2025
work page 2025
-
[21]
Rurage: Robust universal rag evaluator for fast and affordable qa performance testing
Nikita Krayko, Ivan Sidorov, Fedor Laputin, Alexander Panchenko, Daria Galimzianova, and Vasily Konovalov. Rurage: Robust universal rag evaluator for fast and affordable qa performance testing. InEuropean Conference on Information Retrieval, pages 135–145. Springer, 2025. 28 APREPRINT- APRIL7, 2026
work page 2025
-
[22]
Biasscope: Towards automated detection of bias in llm-as-a-judge evaluation, 2026
Peng Lai, Zhihao Ou, Yong Wang, Longyue Wang, Jian Yang, Yun Chen, and Guanhua Chen. Biasscope: Towards automated detection of bias in llm-as-a-judge evaluation, 2026
work page 2026
-
[23]
From generation to judgment: Opportunities and challenges of llm-as-a-judge
Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, et al. From generation to judgment: Opportunities and challenges of llm-as-a-judge. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2757–2791, 2025
work page 2025
-
[24]
Who’s your judge? on the detectability of llm-generated judgments, 2025
Dawei Li, Zhen Tan, Chengshuai Zhao, Bohan Jiang, Baixiang Huang, Pingchuan Ma, Abdullah Alnaibari, Kai Shu, and Huan Liu. Who’s your judge? on the detectability of llm-generated judgments, 2025
work page 2025
-
[25]
Lexrag: Benchmarking retrieval-augmented generation in multi-turn legal consultation conversation
Haitao Li, Yifan Chen, Hu YiRan, Qingyao Ai, Junjie Chen, Xiaoyu Yang, Jianhui Yang, Yueyue Wu, Zeyang Liu, and Yiqun Liu. Lexrag: Benchmarking retrieval-augmented generation in multi-turn legal consultation conversation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 3606–3615, 2025
work page 2025
-
[26]
Llms-as-judges: A comprehensive survey on llm-based evaluation methods, 2024
Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu. Llms-as-judges: A comprehensive survey on llm-based evaluation methods, 2024
work page 2024
-
[27]
Hao Li, Cor-Paul Bezemer, and Ahmed E Hassan. Software engineering and foundation models: Insights from industry blogs using a jury of foundation models. In2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), pages 307–318. IEEE, 2025
work page 2025
-
[28]
Songze Li, Chuokun Xu, Jiaying Wang, Xueluan Gong, Chen Chen, Jirui Zhang, Jun Wang, Kwok-Yan Lam, and Shouling Ji. Llms cannot reliably judge (yet?): A comprehensive assessment on the robustness of llm-as-a-judge, 2025
work page 2025
-
[29]
Compromising llm driven embodied agents with contextual backdoor attacks
Aishan Liu, Yuguang Zhou, Xianglong Liu, Tianyuan Zhang, Siyuan Liang, Jiakai Wang, Yanjun Pu, Tianlin Li, Junqi Zhang, Wenbo Zhou, et al. Compromising llm driven embodied agents with contextual backdoor attacks. IEEE Transactions on Information Forensics and Security, 2025
work page 2025
-
[30]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts, 2023
work page 2023
-
[31]
Adversarial attacks on llm-as-a-judge systems: Insights from prompt injections, 2025
Narek Maloyan and Dmitry Namiot. Adversarial attacks on llm-as-a-judge systems: Insights from prompt injections, 2025
work page 2025
-
[32]
Qiheng Mao, Zhenhao Li, Xing Hu, Kui Liu, Xin Xia, and Jianling Sun. Towards explainable vulnerability detection with large language models.IEEE Transactions on Software Engineering, 2025
work page 2025
-
[33]
Impromptu: a framework for model-driven prompt engineering: S
Sergio Morales, Robert Clarisó, and Jordi Cabot. Impromptu: a framework for model-driven prompt engineering: S. morales et al.Software and Systems Modeling, 24(6):1627–1645, 2025
work page 2025
-
[34]
Dina Nawara and Rasha Kashef. A comprehensive survey on llm-powered recommender systems: from discrimi- native, generative to multi-modal paradigms.IEEE Access, 2025
work page 2025
-
[35]
Doriane Olewicki, Leuson Da Silva, Oussama Ben Sghaier, Suhaib Mujahid, Arezou Amini, Benjamin Mah, Marco Castelluccio, Sarra Habchi, Foutse Khomh, and Bram Adams. Impact of an llm-based review assistant in practice: A mixed open-/closed-source case study.IEEE Transactions on Software Engineering, 2026
work page 2026
-
[36]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Pierre Isabelle, Eugene Charniak, and Dekang Lin, editors,Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA, July
-
[37]
Association for Computational Linguistics
-
[38]
Samuele Pasini, Jinhan Kim, Tommaso Aiello, Rocío Cabrera Lozoya, Antonino Sabetta, and Paolo Tonella. Evaluating and improving the robustness of security attack detectors generated by llms.Empirical Software Engineering, 31(2):35, 2026
work page 2026
-
[39]
Is llm-as-a-judge robust? investigating universal adversarial attacks on zero-shot llm assessment
Vyas Raina, Adian Liusie, and Mark Gales. Is llm-as-a-judge robust? investigating universal adversarial attacks on zero-shot llm assessment. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 7499–7517, 2024
work page 2024
-
[40]
Codebleu: a method for automatic evaluation of code synthesis, 2020
Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. Codebleu: a method for automatic evaluation of code synthesis, 2020
work page 2020
-
[41]
Harnessing large language models for curated code reviews
Oussama Ben Sghaier, Martin Weyssow, and Houari Sahraoui. Harnessing large language models for curated code reviews. In2025 IEEE/ACM 22nd International Conference on Mining Software Repositories (MSR), pages 187–198. IEEE, 2025. 29 APREPRINT- APRIL7, 2026
work page 2025
-
[42]
Minghao Shao, Nanda Rani, Kimberly Milner, Haoran Xi, Meet Udeshi, Saksham Aggarwal, Venkata Sai Charan Putrevu, Sandeep Kumar Shukla, Prashanth Krishnamurthy, Farshad Khorrami, Ramesh Karri, and Muhammad Shafique. Towards effective offensive security llm agents: Hyperparameter tuning, llm as a judge, and a lightweight ctf benchmark, 2025
work page 2025
-
[43]
Ke Shen and Mayank Kejriwal. Defining and evaluating decision and composite risk in language models applied to natural language inference.Engineering Applications of Artificial Intelligence, 161:112253, 2025
work page 2025
-
[44]
Gptracker: A large-scale measurement of misused gpts
Xinyue Shen, Yun Shen, Michael Backes, and Yang Zhang. Gptracker: A large-scale measurement of misused gpts. In2025 IEEE Symposium on Security and Privacy (SP), pages 336–354. IEEE, 2025
work page 2025
-
[45]
Optimization- based prompt injection attack to llm-as-a-judge
Jiawen Shi, Zenghui Yuan, Yinuo Liu, Yue Huang, Pan Zhou, Lichao Sun, and Neil Zhenqiang Gong. Optimization- based prompt injection attack to llm-as-a-judge. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pages 660–674, 2024
work page 2024
-
[46]
Judging the judges: A systematic study of position bias in llm-as-a-judge
Lin Shi, Chiyu Ma, Wenhua Liang, Xingjian Diao, Weicheng Ma, and Soroush V osoughi. Judging the judges: A systematic study of position bias in llm-as-a-judge. InProceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics, pages 292...
work page 2025
-
[47]
Towards a human-in-the-loop framework for reliable patch evaluation using an llm-as-a-judge, 2025
Sherry Shi, Renyao Wei, Michele Tufano, José Cambronero, Runxiang Cheng, Franjo Ivanˇci´c, and Pat Rondon. Towards a human-in-the-loop framework for reliable patch evaluation using an llm-as-a-judge, 2025
work page 2025
-
[48]
Akarsth Kumar Singh and Shang-Hsien Hsieh. Multi-llm-based augmentation and synthetic data generation of construction schedules and task descriptions with slm-as-a-judge assessment.Advanced Engineering Informatics, 69:103825, 2026
work page 2026
-
[49]
Lucia Larise Stavarache. Enhancing fine-tuning llm evaluation: A study on calibration and metrics for industry- specific ai alignment. In2025 IEEE Conference on Artificial Intelligence (CAI), pages 1247–1250. IEEE, 2025
work page 2025
-
[50]
Large language models in medicine.Nature medicine, 29(8):1930–1940, 2023
Arun James Thirunavukarasu, Darren Shu Jeng Ting, Kabilan Elangovan, Laura Gutierrez, Ting Fang Tan, and Daniel Shu Wei Ting. Large language models in medicine.Nature medicine, 29(8):1930–1940, 2023
work page 1930
-
[51]
Badjudge: Backdoor vulnerabilities of llm-as-a-judge, 2025
Terry Tong, Fei Wang, Zhe Zhao, and Muhao Chen. Badjudge: Backdoor vulnerabilities of llm-as-a-judge, 2025
work page 2025
-
[52]
Manipulating multimodal agents via cross-modal prompt injection
Le Wang, Zonghao Ying, Tianyuan Zhang, Siyuan Liang, Shengshan Hu, Mingchuan Zhang, Aishan Liu, and Xianglong Liu. Manipulating multimodal agents via cross-modal prompt injection. InProceedings of the 33rd ACM International Conference on Multimedia, pages 10955–10964, 2025
work page 2025
-
[53]
Shiyu Wang, Yuyao Jiang, Shuaijianni Xu, Yiwen Liu, Ming Yin, and Guofeng He. Fine-tuning a vulnerability- specific large language model for a hybrid software vulnerability detection method.Engineering Applications of Artificial Intelligence, 165:113410, 2026
work page 2026
-
[54]
Multi-dimensional assessment of crowdsourced testing reports via llms
Yue Wang, Yuan Zhao, Shengcheng Yu, and Zhenyu Chen. Multi-dimensional assessment of crowdsourced testing reports via llms. In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 1794–1806. IEEE, 2025
work page 2025
-
[55]
Jade Webb, Faranak Abri, and Sayma Akther. Synthetic social engineering scenario generation using llms for awareness-based attack resilience.IEEE Access, 2025
work page 2025
-
[56]
Zhipeng Wei, Yuqi Liu, and N. Benjamin Erichson. Emoji attack: Enhancing jailbreak attacks against judge llm detection, 2025
work page 2025
-
[57]
Boyan Xu, Guanlan Wu, Zihao Li, Guangming Xu, Huabin Zeng, Rui Tong, and How Yong Ng. Towards domain- adapted large language models for water and wastewater management: methods, datasets and benchmarking.npj Clean Water, 8(1):82, 2025
work page 2025
-
[58]
Benchmark data contamination of large language models: A survey, 2024
Cheng Xu, Shuhao Guan, Derek Greene, and M-Tahar Kechadi. Benchmark data contamination of large language models: A survey, 2024
work page 2024
-
[59]
Justice or prejudice? quantifying biases in llm-as-a-judge, 2024
Jiayi Ye, Yanbo Wang, Yue Huang, Dongping Chen, Qihui Zhang, Nuno Moniz, Tian Gao, Werner Geyer, Chao Huang, Pin-Yu Chen, Nitesh V Chawla, and Xiangliang Zhang. Justice or prejudice? quantifying biases in llm-as-a-judge, 2024
work page 2024
-
[60]
Runyang You, Hongru Cai, Caiqi Zhang, Qiancheng Xu, Meng Liu, Tiezheng Yu, Yongqi Li, and Wenjie Li. Agent-as-a-judge, 2026
work page 2026
-
[61]
When ais judge ais: The rise of agent-as-a-judge evaluation for llms, 2025
Fangyi Yu. When ais judge ais: The rise of agent-as-a-judge evaluation for llms, 2025
work page 2025
-
[62]
Leveraging large language models to detect npm malicious packages
Nusrat Zahan, Philipp Burckhardt, Mikola Lysenko, Feross Aboukhadijeh, and Laurie Williams. Leveraging large language models to detect npm malicious packages. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE), pages 2625–2637. IEEE, 2025. 30 APREPRINT- APRIL7, 2026
work page 2025
-
[63]
Lsrp: A leader-subordinate retrieval framework for privacy-preserving cloud-device collaboration
Yingyi Zhang, Pengyue Jia, Xianneng Li, Derong Xu, Maolin Wang, Yichao Wang, Zhaocheng Du, Huifeng Guo, Yong Liu, Ruiming Tang, et al. Lsrp: A leader-subordinate retrieval framework for privacy-preserving cloud-device collaboration. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 3889–3900, 2025
work page 2025
-
[64]
A survey of large language models, 2026
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. A survey of large language models, 2026
work page 2026
-
[65]
One token to fool llm-as-a-judge, 2025
Yulai Zhao, Haolin Liu, Dian Yu, Sunyuan Kung, Meijia Chen, Haitao Mi, and Dong Yu. One token to fool llm-as-a-judge, 2025
work page 2025
-
[66]
Rescriber: Smaller-llm-powered user-led data minimization for llm-based chatbots
Jijie Zhou, Eryue Xu, Yaoyao Wu, and Tianshi Li. Rescriber: Smaller-llm-powered user-led data minimization for llm-based chatbots. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–28, 2025
work page 2025
-
[67]
Se-jury: An llm-as-ensemble-judge metric for narrowing the gap with human evaluation in se
Xin Zhou, Kisub Kim, Ting Zhang, Martin Weyssow, Luís F Gomes, Guang Yang, Kui Liu, Xin Xia, and David Lo. Se-jury: An llm-as-ensemble-judge metric for narrowing the gap with human evaluation in se. In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE), pages 2606–2618. IEEE, 2025
work page 2025
-
[68]
ICE-score: Instructing large language models to evaluate code
Terry Yue Zhuo. ICE-score: Instructing large language models to evaluate code. In Yvette Graham and Matthew Purver, editors,Findings of the Association for Computational Linguistics: EACL 2024, pages 2232–2242, St. Julian’s, Malta, March 2024. Association for Computational Linguistics. 31
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.