Recognition: 1 theorem link
· Lean TheoremLDMDroid: Leveraging LLMs for Detecting Data Manipulation Errors in Android Apps
Pith reviewed 2026-05-13 22:50 UTC · model grok-4.3
The pith
Large language models detect data manipulation errors in Android apps by guiding state-aware UI sequences and using visual checks for data changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LDMDroid enhances DMF triggering success by guiding LLMs through a state-aware process for generating UI event sequences. It also uses visual features to identify changes in data states, improving DME verification accuracy. Evaluated on 24 real-world Android apps, it demonstrates improved DMF triggering success rates compared to baselines and discovered 17 unique bugs, with 14 confirmed by developers and 11 fixed.
What carries the argument
The state-aware process for LLM-guided UI event sequence generation, paired with visual feature analysis for data state change detection, which together enable automated detection of data manipulation errors.
Load-bearing premise
That LLMs guided in a state-aware manner will generate UI sequences capable of triggering data manipulation functionalities reliably and that visual features will accurately reflect data state changes without significant errors.
What would settle it
Running the tool on the evaluated apps and finding that the reported bugs are not reproducible or that developers reject them as non-issues upon review.
Figures


read the original abstract
Android apps rely heavily on Data Manipulation Functionalities (DMFs) for handling app-specific data through CRUDS operations, making their correctness vital for reliability. However, detecting Data Manipulation Errors (DMEs) is challenging due to their dependence on specific UI interaction sequences and manifestation as logic bugs. Existing automated UI testing tools face two primary challenges: insufficient UI path coverage for adequate DMF triggering and reliance on manually written test scripts. To address these issues, we propose an automated approach using Large Language Models (LLMs) for DME detection. We developed LDMDroid, an automated UI testing framework for Android apps. LDMDroid enhances DMF triggering success by guiding LLMs through a state-aware process for generating UI event sequences. It also uses visual features to identify changes in data states, improving DME verification accuracy. We evaluated LDMDroid on 24 real-world Android apps, demonstrating improved DMF triggering success rates compared to baselines. LDMDroid discovered 17 unique bugs, with 14 confirmed by developers and 11 fixed. The tool is publicly available at https://github.com/runnnnnner200/LDMDroid.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LDMDroid, an automated UI testing framework that leverages LLMs in a state-aware process to generate UI event sequences for triggering Data Manipulation Functionalities (DMFs) in Android apps, employs visual features to detect data state changes for verifying Data Manipulation Errors (DMEs), and evaluates the approach on 24 real-world apps, reporting improved DMF triggering rates over baselines along with discovery of 17 unique bugs (14 developer-confirmed, 11 fixed).
Significance. If the central claims hold after addressing validation gaps, the work contributes a practical LLM-guided approach to automated detection of logic bugs in mobile apps that depend on specific UI sequences, with strengths in real-world evaluation, developer confirmations, and public tool release that support reproducibility and potential adoption in software engineering practice.
major comments (2)
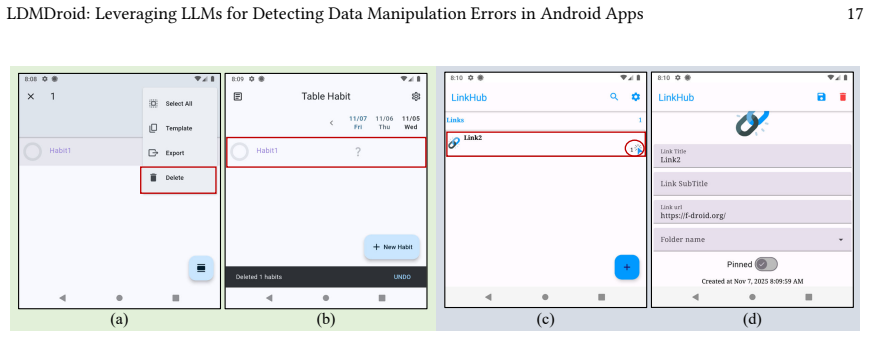
- [Evaluation] Evaluation section: the visual feature-based method for identifying data state changes (e.g., screen differences signaling CRUDS outcomes) lacks any reported precision/recall metrics or comparison against ground-truth techniques such as direct SQLite queries or file diffs. This assumption is load-bearing for the reliability of the 17 reported DMEs and their confirmation counts, as non-data UI updates or animations could produce false signals.
- [Abstract and Evaluation] Abstract and §4 (Evaluation): no quantitative details are supplied on the exact baselines, triggering success rate metrics, number of runs per app, or controls for LLM output variability (e.g., temperature, prompt sensitivity). These omissions leave the effectiveness claims only moderately supported despite the reported bug discoveries.
minor comments (2)
- [Methodology] Methodology: provide more explicit description of the state representation passed to the LLM and the exact prompting template used for sequence generation to improve reproducibility.
- [Evaluation] Ensure all tables reporting bug counts and confirmation status include clear definitions of 'unique' bugs and the criteria used for developer confirmation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important opportunities to strengthen the quantitative rigor of our evaluation, and we have revised the manuscript accordingly to address them directly. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the visual feature-based method for identifying data state changes (e.g., screen differences signaling CRUDS outcomes) lacks any reported precision/recall metrics or comparison against ground-truth techniques such as direct SQLite queries or file diffs. This assumption is load-bearing for the reliability of the 17 reported DMEs and their confirmation counts, as non-data UI updates or animations could produce false signals.
Authors: We agree that explicit validation metrics would further strengthen confidence in the visual detection component. In the revised manuscript we have added a dedicated validation paragraph in §4 that describes a post-hoc manual verification process: for a representative sample of test executions drawn from multiple apps we compared the visual signals against ground-truth SQLite queries and file-system diffs. The results of this comparison are reported in the revised version and show strong alignment, with discrepancies primarily attributable to transient UI animations that we now explicitly filter. All 17 reported DMEs were additionally validated through direct developer confirmation, providing an independent check against false positives. We have also clarified the visual feature extraction logic to better distinguish data-related state changes from other UI updates. revision: yes
-
Referee: [Abstract and Evaluation] Abstract and §4 (Evaluation): no quantitative details are supplied on the exact baselines, triggering success rate metrics, number of runs per app, or controls for LLM output variability (e.g., temperature, prompt sensitivity). These omissions leave the effectiveness claims only moderately supported despite the reported bug discoveries.
Authors: We accept that additional quantitative detail improves transparency. The revised manuscript expands §4 (and updates the abstract) to specify: the exact baseline tools and their configurations, triggering success rates together with measures of variability across runs, the number of independent runs executed per app, and the LLM hyperparameters (including temperature and prompt sensitivity controls) with the full prompt templates now provided in the appendix. These additions make the reported improvements in DMF triggering and the 17 discovered bugs more quantitatively grounded while preserving the focus on real-world developer-confirmed results. revision: yes
Circularity Check
No significant circularity in empirical tool evaluation
full rationale
The paper proposes LDMDroid as an LLM-guided UI testing framework for detecting data manipulation errors, evaluated empirically on 24 real-world Android apps. It reports improved triggering rates, discovery of 17 unique bugs, and external developer confirmations (14 confirmed, 11 fixed) without any mathematical derivations, equations, fitted parameters renamed as predictions, or self-citations that form the load-bearing justification for the central claims. The approach relies on external benchmarks and real-app validation rather than reducing results to self-defined inputs or internal loops, rendering the evaluation self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs guided by state-aware processes can generate effective UI event sequences to trigger DMFs
- domain assumption Visual features extracted from screen changes can accurately identify data state modifications for DME verification
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearLDMDroid enhances DMF triggering success by guiding LLMs through a state-aware process for generating UI event sequences. It also uses visual features to identify changes in data states
Reference graph
Works this paper leans on
-
[1]
Android. 2025. Monkey. https://developer.android.google.cn/studio/test/other-testing-tools/monkey
work page 2025
-
[2]
David Curry. 2025. Android Statistics (2025). https://www.businessofapps.com/data/android-statistics
work page 2025
-
[3]
F-Droid. 2025. F-Droid. https://f-droid.org
work page 2025
-
[4]
Github. 2025. Another Notes. https://github.com/maltaisn/another-notes-app
work page 2025
-
[5]
Github. 2025. [Bug] Settings Entry Mistakenly Treated as TO-DO List After Deleting Last TO-DO. https://github.com/SecUSo/privacy-friendly- todo-list/issues/158
work page 2025
-
[6]
GitHub. 2025. CPU Info. https://github.com/kamgurgul/cpu-info
work page 2025
-
[7]
GitHub. 2025. CycleStreets. https://github.com/cyclestreets/android
work page 2025
-
[8]
Github. 2025. Easy Notes. https://github.com/Kin69/EasyNotes
work page 2025
-
[9]
Github. 2025. Fridgey. https://github.com/NielsLee/FoodRecords
work page 2025
-
[10]
Github. 2025. Home Medkit. https://github.com/pewaru-333/HomeMedkit-App
work page 2025
-
[11]
Github. 2025. LinkHub. https://github.com/AmrDeveloper/LinkHub
work page 2025
-
[12]
Github. 2025. Material Notes. https://github.com/maelchiotti/LocalMaterialNotes
work page 2025
-
[13]
Github. 2025. MaterialFiles. https://github.com/zhanghai/MaterialFiles
work page 2025
-
[14]
Github. 2025. NoNonsense Notes. https://github.com/spacecowboy/NotePad
work page 2025
-
[15]
Github. 2025. Notally. https://github.com/OmGodse/Notally
work page 2025
-
[16]
Github. 2025. NotallyX. https://github.com/PhilKes/NotallyX
work page 2025
-
[17]
GitHub. 2025. OsmAnd. https://github.com/osmandapp/Osmand
work page 2025
-
[18]
Github. 2025. PFA Todo List. https://github.com/SecUSo/privacy-friendly-todo-list
work page 2025
-
[19]
GitHub. 2025. Photo Editor. https://github.com/burhanrashid52/PhotoEditor
work page 2025
-
[20]
Github. 2025. Play NotePad. https://github.com/mshdabiola/NotePad
work page 2025
-
[21]
Github. 2025. Print Notes. https://github.com/RoBoT095/printnotes
work page 2025
-
[22]
Github. 2025. Quillpad. https://github.com/quillpad/quillpad
work page 2025
-
[23]
Github. 2025. Rank My Favs. https://github.com/dessalines/rank-my-favs
work page 2025
-
[24]
Github. 2025. Read You. https://github.com/Ashinch/ReadYou
work page 2025
-
[25]
Github. 2025. Recurring Expense Tracker. https://github.com/DennisBauer/RecurringExpenseTracker
work page 2025
-
[26]
Github. 2025. Table Habit. https://github.com/FriesI23/mhabit
work page 2025
-
[27]
Github. 2025. Tasky. https://github.com/thatsmanmeet/Tasky
work page 2025
-
[28]
Github. 2025. To Don’t. https://github.com/Crazy-Marvin/ToDont
work page 2025
-
[29]
Google. 2025. Prompt Template in LDMDroid. https://docs.google.com/document/d/1asyf25458YNXkfM_4pQOaCEPBZj78lcCBQi7lcyxko8
work page 2025
-
[30]
Siyi Gu, Xiaoqiang Liu, Hui Guo, Bochun Cao, Baiyan Li, Lizhi Cai, and Hu Yun. 2024. Finding Deep-Hidden Bugs in Android Apps via Functional Semantics Guided Exploration. InTheoretical Aspects of Software Engineering: 18th International Symposium, TASE 2024, Guiyang, China, July 29 – Manuscript submitted to ACM 22 Xiangyang Xiao, Huaxun Huang, and Rongxin...
-
[31]
Tianxiao Gu, Chengnian Sun, Xiaoxing Ma, Chun Cao, Chang Xu, Yuan Yao, Qirun Zhang, Jian Lu, and Zhendong Su. 2019. Practical GUI Testing of Android Applications via Model Abstraction and Refinement. InProceedings of the 41st International Conference on Software Engineering (ICSE ’19). IEEE Press, Montreal, Quebec, Canada, 269–280. doi:10.1109/ICSE.2019.00042
-
[32]
Pingfan Kong, Li Li, Jun Gao, Kui Liu, Tegawendé F. Bissyandé, and Jacques Klein. 2019. Automated Testing of Android Apps: A Systematic Literature Review.IEEE Transactions on Reliability68, 1 (March 2019), 45–66. doi:10.1109/TR.2018.2865733
-
[33]
Yuanchun Li, Ziyue Yang, Yao Guo, and Xiangqun Chen. 2017. DroidBot: A Lightweight UI-guided Test Input Generator for Android. InProceedings of the 39th International Conference on Software Engineering Companion (ICSE-C ’17). IEEE Press, Buenos Aires, Argentina, 23–26. doi:10.1109/ICSE- C.2017.8
-
[34]
Yuanchun Li, Ziyue Yang, Yao Guo, and Xiangqun Chen. 2020. Humanoid: A Deep Learning-Based Approach to Automated Black-Box Android App Testing. InProceedings of the 34th IEEE/ACM International Conference on Automated Software Engineering (ASE ’19). IEEE Press, San Diego, California, 1070–1073. doi:10.1109/ASE.2019.00104
-
[35]
Zhe Liu, Chunyang Chen, Junjie Wang, Mengzhuo Chen, Boyu Wu, Xing Che, Dandan Wang, and Qing Wang. 2024. Make LLM a Testing Expert: Bringing Human-like Interaction to Mobile GUI Testing via Functionality-aware Decisions. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. ACM, Lisbon Portugal, 1–13. arXiv:2310.15780 doi:10...
-
[36]
Zhe Liu, Chunyang Chen, Junjie Wang, Mengzhuo Chen, Boyu Wu, Zhilin Tian, Yuekai Huang, Jun Hu, and Qing Wang. 2024. Testing the Limits: Unusual Text Inputs Generation for Mobile App Crash Detection with Large Language Model. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering (ICSE ’24). Association for Computing Machinery...
-
[37]
Zhengwei Lv, Chao Peng, Zhao Zhang, Ting Su, Kai Liu, and Ping Yang. 2023. Fastbot2: Reusable Automated Model-based GUI Testing for Android Enhanced by Reinforcement Learning. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering (ASE ’22). Association for Computing Machinery, New York, NY, USA, 1–5. doi:10.1145/355...
-
[38]
Leonardo Mariani, Mauro Pezzè, and Daniele Zuddas. 2018. Augusto: Exploiting Popular Functionalities for the Generation of Semantic GUI Tests with Oracles. InProceedings of the 40th International Conference on Software Engineering (ICSE ’18). Association for Computing Machinery, New York, NY, USA, 280–290. doi:10.1145/3180155.3180162
-
[39]
Minxue Pan, An Huang, Guoxin Wang, Tian Zhang, and Xuandong Li. 2020. Reinforcement Learning Based Curiosity-Driven Testing of Android Applications. InProceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA 2020). Association for Computing Machinery, New York, NY, USA, 153–164. doi:10.1145/3395363.3397354
-
[40]
Dezhi Ran, Hao Wang, Zihe Song, Mengzhou Wu, Yuan Cao, Ying Zhang, Wei Yang, and Tao Xie. 2024. Guardian: A Runtime Framework for LLM-Based UI Exploration. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA 2024). Association for Computing Machinery, New York, NY, USA, 958–970. doi:10.1145/3650212.3680334
-
[41]
Iflaah Salman, Ayse Tosun Misirli, and Natalia Juristo. 2015. Are Students Representatives of Professionals in Software Engineering Experiments?. InProceedings of the 37th International Conference on Software Engineering - Volume 1 (ICSE ’15). IEEE Press, Florence, Italy, 666–676
work page 2015
-
[42]
Yunpeng Song, Yiheng Bian, Yongtao Tang, Guiyu Ma, and Zhongmin Cai. 2024. VisionTasker: Mobile Task Automation Using Vision Based UI Understanding and LLM Task Planning. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology. ACM, Pittsburgh PA USA, 1–17. arXiv:2312.11190 doi:10.1145/3654777.3676386
-
[43]
Ting Su, Guozhu Meng, Yuting Chen, Ke Wu, Weiming Yang, Yao Yao, Geguang Pu, Yang Liu, and Zhendong Su. 2017. Guided, Stochastic Model-Based GUI Testing of Android Apps. InProceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering (ESEC/FSE 2017). Association for Computing Machinery, New York, NY, USA, 245–256. doi:10.1145/3106237.3106298
-
[44]
Ting Su, Yichen Yan, Jue Wang, Jingling Sun, Yiheng Xiong, Geguang Pu, Ke Wang, and Zhendong Su. 2021. Fully Automated Functional Fuzzing of Android Apps for Detecting Non-Crashing Logic Bugs.Proc. ACM Program. Lang.5, OOPSLA (Oct. 2021), 156:1–156:31. doi:10.1145/3485533
-
[45]
Jingling Sun, Ting Su, Jiayi Jiang, Jue Wang, Geguang Pu, and Zhendong Su. 2023. Property-Based Fuzzing for Finding Data Manipulation Errors in Android Apps. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2023). Association for Computing Machinery, New York, N...
-
[46]
Bryan Wang, Gang Li, and Yang Li. 2023. Enabling Conversational Interaction with Mobile UI Using Large Language Models. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23). Association for Computing Machinery, New York, NY, USA, 1–17. doi:10.1145/3544548.3580895
-
[47]
Jue Wang, Yanyan Jiang, Ting Su, Shaohua Li, Chang Xu, Jian Lu, and Zhendong Su. 2022. Detecting Non-Crashing Functional Bugs in Android Apps via Deep-State Differential Analysis. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2022). Association for Computing ...
-
[48]
Jue Wang, Yanyan Jiang, Chang Xu, Chun Cao, Xiaoxing Ma, and Jian Lu. 2020. ComboDroid: Generating High-Quality Test Inputs for Android Apps via Use Case Combinations. InProceedings of the ACM/IEEE 42nd International Conference on Software Engineering (ICSE ’20). Association for Computing Machinery, New York, NY, USA, 469–480. doi:10.1145/3377811.3380382
-
[49]
Zhenhailong Wang, Haiyang Xu, Junyang Wang, Xi Zhang, Ming Yan, Ji Zhang, Fei Huang, and Heng Ji. 2025. Mobile-Agent-E: Self-Evolving Mobile Assistant for Complex Tasks. arXiv:2501.11733 [cs] doi:10.48550/arXiv.2501.11733
-
[50]
Hao Wen, Yuanchun Li, Guohong Liu, Shanhui Zhao, Tao Yu, Toby Jia-Jun Li, Shiqi Jiang, Yunhao Liu, Yaqin Zhang, and Yunxin Liu. 2024. AutoDroid: LLM-powered Task Automation in Android. InProceedings of the 30th Annual International Conference on Mobile Computing and Networking. ACM, Manuscript submitted to ACM LDMDroid: Leveraging LLMs for Detecting Data ...
-
[51]
Hao Wen, Hongming Wang, Jiaxuan Liu, and Yuanchun Li. 2024. DroidBot-GPT: GPT-powered UI Automation for Android. arXiv:2304.07061 doi:10.48550/arXiv.2304.07061
-
[52]
Yiheng Xiong, Ting Su, Jue Wang, Jingling Sun, Geguang Pu, and Zhendong Su. 2024. General and Practical Property-based Testing for Android Apps. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (ASE ’24). Association for Computing Machinery, New York, NY, USA, 53–64. doi:10.1145/3691620.3694986
-
[53]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen
-
[54]
A Survey of Large Language Models
A Survey of Large Language Models. arXiv:2303.18223 [cs] doi:10.48550/arXiv.2303.18223
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.18223
-
[55]
Yu Zhao, Tingting Yu, Ting Su, Yang Liu, Wei Zheng, Jingzhi Zhang, and William G. J. Halfond. 2019. ReCDroid: Automatically Reproducing Android Application Crashes from Bug Reports. InProceedings of the 41st International Conference on Software Engineering (ICSE ’19). IEEE Press, Montreal, Quebec, Canada, 128–139. doi:10.1109/ICSE.2019.00030
-
[56]
Zhipu. 2025. Zhipu AI. https://www.zhipuai.cn/en Manuscript submitted to ACM
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.