Recognition: 2 theorem links
· Lean TheoremMultimodal Language Models Cannot Spot Spatial Inconsistencies
Pith reviewed 2026-05-13 23:08 UTC · model grok-4.3
The pith
Multimodal language models fail to identify objects that violate 3D motion consistency between two scene views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
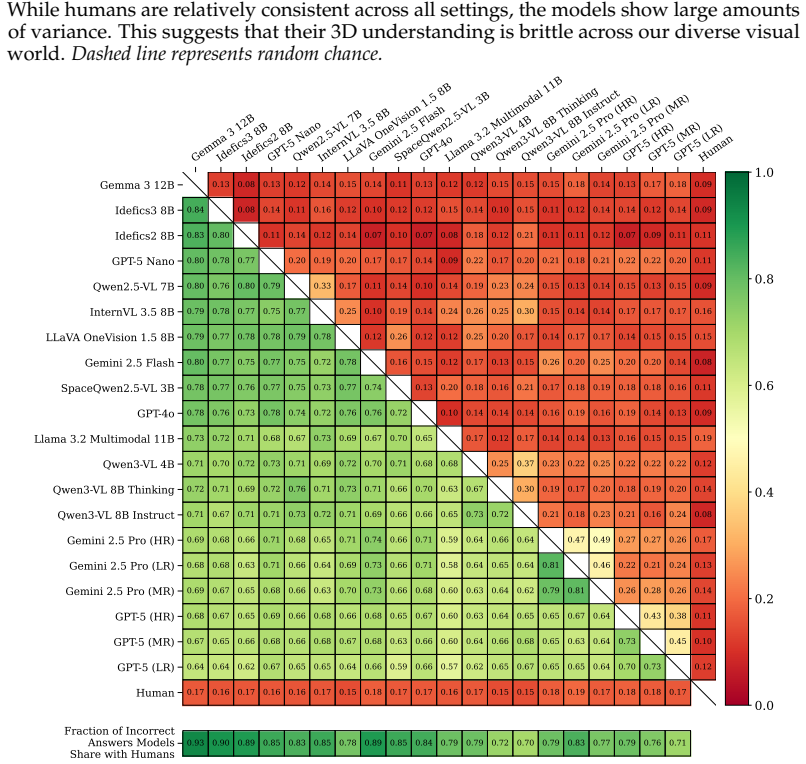
Given two views of the same scene, state-of-the-art multimodal language models cannot reliably name the object whose placement violates 3D motion consistency, in contrast to human observers who succeed at high rates. Model accuracy fluctuates markedly with scene attributes and remains far below human levels, indicating an incomplete internal representation of 3D structure.
What carries the argument
A generation procedure that produces image pairs from multi-view scenes differing only by a controlled 3D motion inconsistency.
Load-bearing premise
The generated image pairs contain no 2D artifacts or other shortcuts that models could exploit instead of reasoning about true 3D geometry.
What would settle it
If models reach human-level accuracy on the pairs and their detection rate drops sharply when the 3D inconsistency is removed while 2D appearance is held constant, the claim of inability to spot spatial inconsistencies would be falsified.
Figures
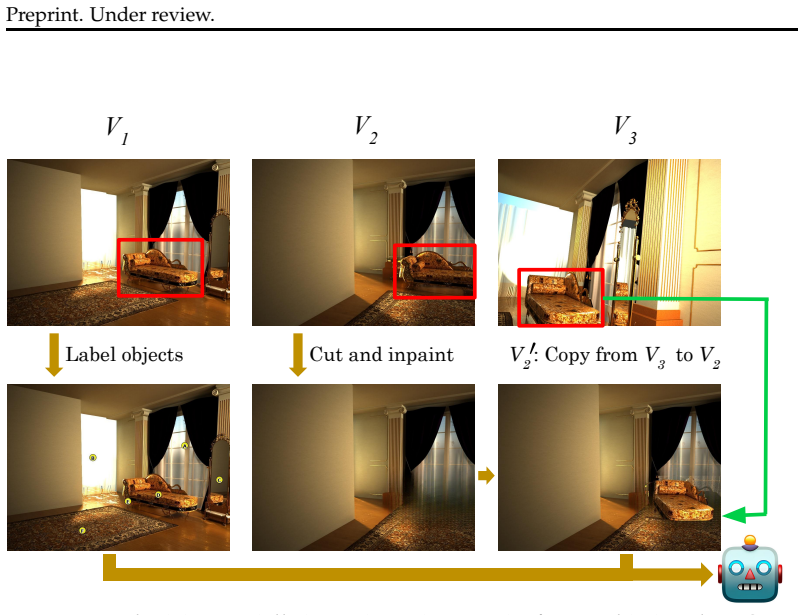



read the original abstract
Spatial consistency is a fundamental property of the visual world and a key requirement for models that aim to understand physical reality. Despite recent advances, multimodal large language models (MLLMs) often struggle to reason about 3D geometry across multiple views. Rather than asking models to describe scene attributes, we introduce a more challenging task: given two views of the same scene, identify the object that violates 3D motion consistency. We propose a simple and scalable method for generating realistic, spatially inconsistent image pairs from multi-view scenes, enabling systematic evaluation of this capability. Our results show that state-of-the-art MLLMs significantly underperform human observers and exhibit substantial variability across different scene attributes, revealing a fragile and incomplete understanding of 3D structure. We hope our findings underscore the need for approaches that develop a more deeply grounded understanding of the physical world.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a new task for multimodal large language models (MLLMs): given two views of the same scene, identify the object that violates 3D motion consistency. The authors propose a simple and scalable method to generate realistic, spatially inconsistent image pairs from multi-view scenes. They report that state-of-the-art MLLMs significantly underperform human observers and exhibit substantial variability across scene attributes, indicating a fragile and incomplete understanding of 3D structure.
Significance. If the generation procedure can be shown to isolate genuine 3D inconsistencies without introducing correlated 2D cues, the results would provide a concrete demonstration of a limitation in current MLLMs' spatial reasoning that is relevant to applications requiring physical-world understanding. The work supplies a new evaluation protocol and documents attribute-dependent variability, both of which could usefully guide future model development. The purely empirical nature of the study makes the strength of these conclusions dependent on the quality of the synthetic data and the completeness of the experimental reporting.
major comments (2)
- [Generation method] Generation method section: The central claim that the synthesized pairs differ solely in true 3D motion consistency (and therefore that model failures reflect absence of 3D reasoning) is load-bearing for the interpretation of the headline result. The manuscript must supply explicit validation—human ratings for seam/lighting/texture artifacts or quantitative metrics on edge continuity and illumination consistency—otherwise the observed performance gap could be explained by sensitivity to low-level 2D statistics rather than geometric understanding.
- [Results] Results section: The abstract states that MLLMs 'significantly underperform' humans, yet the provided text supplies no dataset sizes, exact model versions, statistical tests, confidence intervals, or baseline comparisons. Without these details the magnitude and reliability of the reported gap cannot be assessed, weakening the claim of 'substantial variability across different scene attributes.'
minor comments (2)
- The abstract would benefit from a single quantitative highlight (e.g., average accuracy for the best MLLM versus humans) to give readers an immediate sense of effect size.
- Clarify the source multi-view datasets used for pair generation and any filtering criteria applied to ensure scene diversity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that additional validation of the generation procedure and more complete experimental reporting are needed to strengthen the claims. We address each major comment below and will incorporate the suggested changes in the revised manuscript.
read point-by-point responses
-
Referee: [Generation method] Generation method section: The central claim that the synthesized pairs differ solely in true 3D motion consistency (and therefore that model failures reflect absence of 3D reasoning) is load-bearing for the interpretation of the headline result. The manuscript must supply explicit validation—human ratings for seam/lighting/texture artifacts or quantitative metrics on edge continuity and illumination consistency—otherwise the observed performance gap could be explained by sensitivity to low-level 2D statistics rather than geometric understanding.
Authors: We agree that explicit validation is essential to rule out low-level 2D confounds. In the revised manuscript we will add (i) human ratings on a random sample of 200 generated pairs assessing seam, lighting, and texture artifacts on a 5-point scale, and (ii) quantitative metrics including edge-continuity scores (via Canny edge overlap) and illumination-consistency measures (via histogram intersection on luminance channels). These additions will be reported in a new subsection of the Generation Method section. revision: yes
-
Referee: [Results] Results section: The abstract states that MLLMs 'significantly underperform' humans, yet the provided text supplies no dataset sizes, exact model versions, statistical tests, confidence intervals, or baseline comparisons. Without these details the magnitude and reliability of the reported gap cannot be assessed, weakening the claim of 'substantial variability across different scene attributes.'
Authors: We will expand the Results section to report: total number of image pairs (N=2,400), exact model versions (GPT-4o-2024-08, Claude-3.5-Sonnet, Gemini-1.5-Pro, LLaVA-1.6-34B), statistical tests (paired t-tests with Bonferroni correction and 95% confidence intervals), and additional baselines (random guessing, single-view object detection). The abstract will be updated to reference the scale of the evaluation. These details were present in the supplementary material but will now be moved to the main text. revision: yes
Circularity Check
No circularity: purely empirical evaluation study
full rationale
The paper introduces a task of identifying 3D motion inconsistencies in image pairs and proposes a generation method for creating such pairs from multi-view scenes. It then reports experimental results showing MLLMs underperform humans. No mathematical derivations, equations, fitted parameters, or self-referential definitions are present. The central claims rest on direct empirical comparisons to human observers and are self-contained against external benchmarks, with no reduction of results to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-view scenes from existing datasets can be altered to create realistic 3D motion inconsistencies
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
identify the object that violates 3D motion consistency... simple and scalable method for generating realistic, spatially inconsistent image pairs
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[3]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[4]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[5]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
-
[6]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Anand Bhattad, Konpat Preechakul, and Alexei A Efros. Visual jenga: Discovering object dependencies via counterfactual inpainting. arXiv preprint arXiv:2503.21770, 2025
-
[9]
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brian Ichter, Danny Driess, Pete Florence, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. arXiv preprint arXiv:2401.12168, 2024. URL https://arxiv.org/abs/2401.12168
-
[10]
Evaluating mllms with multimodal multi-image reasoning benchmark
Ziming Cheng, Binrui Xu, Lisheng Gong, Zuhe Song, Tianshuo Zhou, Shiqi Zhong, Siyu Ren, Mingxiang Chen, Xiangchao Meng, Yuxin Zhang, et al. Evaluating mllms with multimodal multi-image reasoning benchmark. arXiv preprint arXiv:2506.04280, 2025
-
[11]
Physbench: Benchmarking and enhancing vision-language models for physical world understanding
Wei Chow, Jiageng Mao, Boyi Li, Daniel Seita, Vitor Guizilini, and Yue Wang. Physbench: Benchmarking and enhancing vision-language models for physical world understanding. arXiv preprint arXiv:2501.16411, 2025
-
[12]
Mm-spatial: Exploring 3d spatial understanding in multimodal llms
Erik Daxberger, Nina Wenzel*, David Griffiths*, Haiming Gang, Justin Lazarow, Gefen Kohavi, Kai Kang, Marcin Eichner, Yinfei Yang, Afshin Dehghan, and Peter Grasch. Mm-spatial: Exploring 3d spatial understanding in multimodal llms. In ICCV, 2025. URL https://arxiv.org/abs/2503.13111
-
[13]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. arXiv preprint arXiv:2404.12390, 2024
-
[14]
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al. Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp...
work page 2024
-
[15]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021. URL https://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning
Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp.\ 2901--2910, 2017
work page 2017
-
[17]
What matters when building vision-language models?, 2024
Hugo Laurençon, Léo Tronchon, Matthieu Cord, and Victor Sanh. What matters when building vision-language models?, 2024. URL https://arxiv.org/abs/2405.02246
-
[18]
Genai-bench: Evaluating and improving compositional text-to-visual generation
Baiqi Li, Zhiqiu Lin, Deepak Pathak, Jiayao Li, Yixin Fei, Kewen Wu, Tiffany Ling, Xide Xia, Pengchuan Zhang, Graham Neubig, and Deva Ramanan. Genai-bench: Evaluating and improving compositional text-to-visual generation. 2024 a
work page 2024
-
[19]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024 b
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
11plus-bench: Demystifying multimodal llm spatial reasoning with cognitive-inspired analysis
Chengzu Li, Wenshan Wu, Huanyu Zhang, Qingtao Li, Zeyu Gao, Yan Xia, Jos \'e Hern \'a ndez-Orallo, Ivan Vuli \'c , and Furu Wei. 11plus-bench: Demystifying multimodal llm spatial reasoning with cognitive-inspired analysis. arXiv preprint arXiv:2508.20068, 2025 a
-
[21]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 22195--22206, 2024 c
work page 2024
-
[22]
Videohallu: Evaluating and mitigating multi-modal hallucinations on synthetic video understanding
Zongxia Li, Xiyang Wu, Guangyao Shi, Yubin Qin, Hongyang Du, Fuxiao Liu, Tianyi Zhou, Dinesh Manocha, and Jordan Lee Boyd-Graber. Videohallu: Evaluating and mitigating multi-modal hallucinations on synthetic video understanding. arXiv preprint arXiv:2505.01481, 2025 b
-
[23]
Evaluating text-to-visual generation with image-to-text generation
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. Evaluating text-to-visual generation with image-to-text generation. arXiv preprint arXiv:2404.01291, 2024
-
[24]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 22160--22169, 2024
work page 2024
-
[25]
Zero-1-to-3: Zero-shot one image to 3d object, 2023
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. Zero-1-to-3: Zero-shot one image to 3d object, 2023
work page 2023
-
[26]
Grace Luo, Jonathan Granskog, Aleksander Holynski, and Trevor Darrell. Dual-process image generation. In ICCV, 2025
work page 2025
-
[27]
3dsrbench: A comprehensive 3d spatial reasoning benchmark
Wufei Ma, Haoyu Chen, Guofeng Zhang, Yu-Cheng Chou, Jieneng Chen, Celso de Melo, and Alan Yuille. 3dsrbench: A comprehensive 3d spatial reasoning benchmark. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 6924--6934, 2025
work page 2025
-
[28]
Zixian Ma, Jerry Hong, Mustafa Omer Gul, Mona Gandhi, Irena Gao, and Ranjay Krishna. Crepe: Can vision-language foundation models reason compositionally? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 10910--10921, 2023
work page 2023
-
[29]
Meta. The llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M. Susskind. Hypersim : A photorealistic synthetic dataset for holistic indoor scene understanding. In International Conference on Computer Vision (ICCV) 2021, 2021
work page 2021
-
[31]
Resolution-robust large mask inpainting with fourier convolutions
Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor Lempitsky. Resolution-robust large mask inpainting with fourier convolutions. arXiv preprint arXiv:2109.07161, 2021
-
[32]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ram \'e , Morgane Rivi \`e re, et al. Gemma 3 technical report. arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Winoground: Probing vision and language models for visio-linguistic compositionality
Tristan Thrush, Ryan Jiang, Max Bartolo, Amanpreet Singh, Adina Williams, Douwe Kiela, and Candace Ross. Winoground: Probing vision and language models for visio-linguistic compositionality. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 5238--5248, 2022
work page 2022
-
[34]
Hsiao-Yu Tung, Mingyu Ding, Zhenfang Chen, Daniel Bear, Chuang Gan, Josh Tenenbaum, Dan Yamins, Judith Fan, and Kevin Smith. Physion++: Evaluating physical scene understanding that requires online inference of different physical properties. Advances in Neural Information Processing Systems, 36: 0 67048--67068, 2023
work page 2023
-
[35]
Equivariant similarity for vision-language foundation models
Tan Wang, Kevin Lin, Linjie Li, Chung-Ching Lin, Zhengyuan Yang, Hanwang Zhang, Zicheng Liu, and Lijuan Wang. Equivariant similarity for vision-language foundation models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp.\ 11998--12008, 2023
work page 2023
-
[36]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Vinoground: Scrutinizing lmms over dense temporal reasoning with short videos
Jianrui Zhang, Cai Mu, and Yong Jae Lee. Vinoground: Scrutinizing lmms over dense temporal reasoning with short videos. arXiv, 2024. URL https://arxiv.org/abs/2410.02763
-
[38]
Controlling video generation with vision language models, 2026
Longtao Zheng, Ruiqing Wang, Deheng Ye, and Bo An. Controlling video generation with vision language models, 2026. URL https://openreview.net/forum?id=6SC61wyq8w
work page 2026
-
[39]
Stable virtual camera: Generative view synthesis with diffusion models
Jensen (Jinghao) Zhou, Hang Gao, Vikram Voleti, Aaryaman Vasishta, Chun-Han Yao, Mark Boss, Philip Torr, Christian Rupprecht, and Varun Jampani. Stable virtual camera: Generative view synthesis with diffusion models. arXiv preprint, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.