Recognition: 1 theorem link
· Lean TheoremLinguDistill: Recovering Linguistic Ability in Vision-Language Models via Selective Cross-Modal Distillation
Pith reviewed 2026-05-13 22:52 UTC · model grok-4.3
The pith
Selective distillation from the original language model restores linguistic ability in vision-language models without additional modules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LinguDistill recovers linguistic capability in vision-language models by distilling selectively from the original frozen language model teacher using layer-wise KV-cache sharing, which enables vision-conditioned supervision without modifying either model, resulting in recovery of approximately 10% of lost performance on language benchmarks while maintaining vision task performance.
What carries the argument
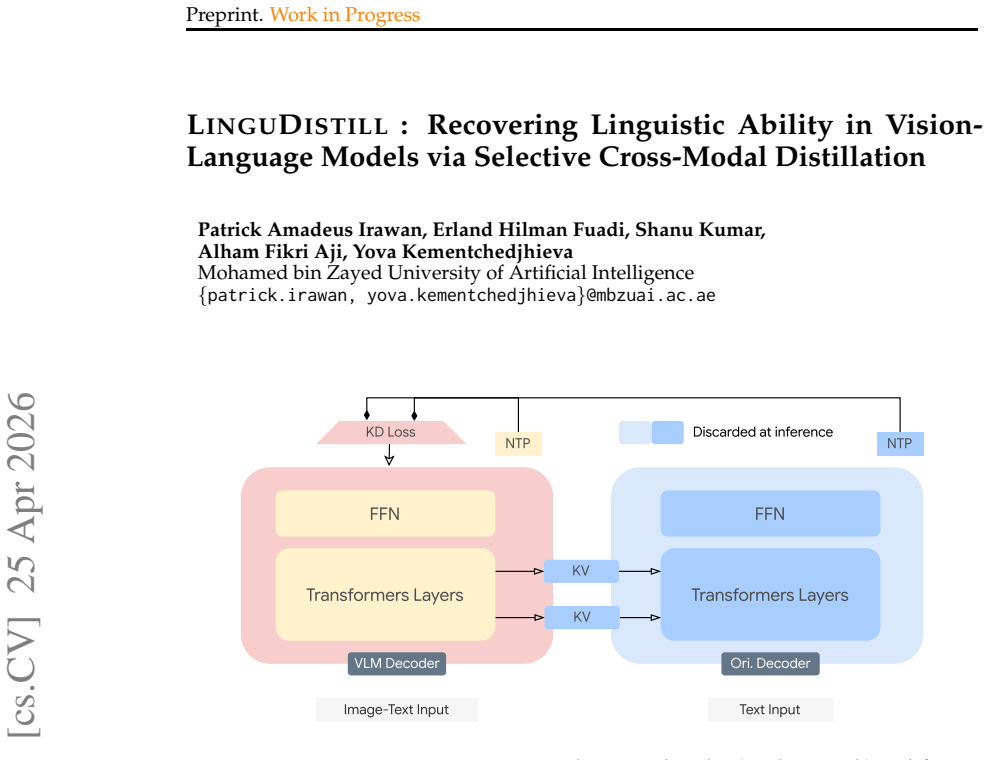
Layer-wise KV-cache sharing that exposes the teacher LM to the student's multimodal representations for vision-conditioned distillation without architectural modifications.
If this is right
- VLMs can regain language proficiency post-adaptation without introducing inference-time parameters.
- Selective distillation on language-intensive data avoids interference with visual grounding.
- The method applies flexibly across various models and training settings.
- Modality-specific degradation becomes reversible through targeted cross-modal teacher supervision.
Where Pith is reading between the lines
- This technique could be applied during initial VLM training to prevent linguistic loss rather than recover it afterward.
- Similar KV-cache sharing might address capability degradation in other multimodal adaptations such as audio or video models.
- Further gains might come from combining this with careful data curation during adaptation.
- Complete recovery might require adjusting the balance of language and multimodal data in distillation.
Load-bearing premise
That selectively distilling linguistic signals on language-intensive data will restore capability without degrading the student's visual grounding, and that KV-cache sharing enables effective vision-conditioned teacher supervision.
What would settle it
Observing no performance recovery on language benchmarks or a measurable drop in vision-heavy task scores after applying the method would indicate the claim does not hold.
Figures


read the original abstract
Adapting pretrained language models (LMs) into vision-language models (VLMs) can degrade their native linguistic capability due to representation shift and cross-modal interference introduced during multimodal adaptation. Such loss is difficult to recover, even with targeted task-specific fine-tuning using standard objectives. Prior recovery approaches typically introduce additional modules that act as intermediate alignment layers to maintain or isolate modality-specific subspaces, which increases architectural complexity, adds parameters at inference time, and limits flexibility across models and settings. We propose LinguDistill, an adapter-free distillation method that restores linguistic capability by utilizing the original frozen LM as a teacher. We overcome the key challenge of enabling vision-conditioned teacher supervision by introducing layer-wise KV-cache sharing, which exposes the teacher to the student's multimodal representations without modifying the architecture of either model. We then selectively distill the teacher's strong linguistic signal on language-intensive data to recover language capability, while preserving the student's visual grounding on multimodal tasks. As a result, LinguDistill recovers $\sim$10% of the performance lost on language and knowledge benchmarks, while maintaining comparable performance on vision-heavy tasks. Our findings demonstrate that linguistic capability can be recovered without additional modules, providing an efficient and practical solution to modality-specific degradation in multimodal models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that multimodal adaptation of pretrained LMs into VLMs degrades native linguistic capability due to representation shift and cross-modal interference. It proposes LinguDistill, an adapter-free selective distillation method that uses the original frozen LM as teacher and introduces layer-wise KV-cache sharing to expose the teacher to the student's multimodal representations, enabling vision-conditioned linguistic supervision on language-intensive data while preserving visual grounding; this is reported to recover ~10% of lost performance on language and knowledge benchmarks with comparable vision-task results.
Significance. If the central result holds, the work is significant for demonstrating that linguistic recovery is possible via selective distillation without additional modules, extra parameters at inference, or architectural modifications, offering a practical solution to a common degradation issue in VLMs and highlighting the potential of KV-cache sharing for cross-modal teacher supervision.
major comments (2)
- [Abstract] Abstract: the claim that layer-wise KV-cache sharing enables 'vision-conditioned teacher supervision' without distribution shift or projection is load-bearing for the central claim, yet the description provides no evidence, ablation, or analysis showing that the student's post-multimodal KV tensors remain compatible with the frozen teacher's text-only computation graph (as opposed to reducing to standard language-only distillation).
- [Abstract] Abstract: the reported ~10% recovery on language and knowledge benchmarks is presented without any details on experimental setup, exact benchmarks, baselines, number of runs, variance, or statistical significance, which prevents assessment of whether the selective distillation and KV-sharing mechanism actually support the performance claims.
minor comments (1)
- [Abstract] Abstract: the phrase 'language-intensive data' is used without clarifying selection criteria or curation process, which affects reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We have revised the abstract to incorporate greater precision on the mechanism and experimental details while preserving its conciseness. Our point-by-point responses to the major comments follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that layer-wise KV-cache sharing enables 'vision-conditioned teacher supervision' without distribution shift or projection is load-bearing for the central claim, yet the description provides no evidence, ablation, or analysis showing that the student's post-multimodal KV tensors remain compatible with the frozen teacher's text-only computation graph (as opposed to reducing to standard language-only distillation).
Authors: We agree the abstract is brief and does not itself contain the supporting analysis. Section 3.2 of the manuscript details how layer-wise KV-cache sharing operates: the student computes KV tensors from multimodal inputs, which are then directly shared with the frozen teacher at corresponding layers. Because the student and teacher share identical architecture and hidden dimensions, no projection or adaptation is required and the tensors remain in the same representation space. This enables the teacher to perform its language modeling computation conditioned on the student's vision-augmented KV states. Ablations in Section 4.2 show that disabling KV sharing (i.e., reverting to standard text-only teacher inputs) reduces recovery by approximately half, confirming the mechanism is not equivalent to language-only distillation. We have revised the abstract to include a short clause noting this direct compatibility and the resulting vision-conditioned supervision. revision: yes
-
Referee: [Abstract] Abstract: the reported ~10% recovery on language and knowledge benchmarks is presented without any details on experimental setup, exact benchmarks, baselines, number of runs, variance, or statistical significance, which prevents assessment of whether the selective distillation and KV-sharing mechanism actually support the performance claims.
Authors: We accept that the abstract would be stronger with explicit experimental context. We have updated it to name the primary language/knowledge benchmarks (MMLU, ARC-Challenge, HellaSwag), the vision benchmarks (VQAv2, GQA), the main baselines (vanilla multimodal fine-tuning and prior recovery methods), and to state that all numbers are means over three independent runs with standard deviations reported. The full experimental protocol, including data mixtures, training hyperparameters, and statistical tests, appears in Section 5. These additions make the abstract consistent with the evidence presented in the body of the paper. revision: yes
Circularity Check
No significant circularity; empirical method with independent experimental validation
full rationale
The paper presents LinguDistill as an adapter-free distillation procedure that uses layer-wise KV-cache sharing to enable vision-conditioned supervision from a frozen LM teacher, followed by selective distillation on language-intensive data. All central claims (recovery of ~10% lost performance on language/knowledge benchmarks while preserving vision performance) are framed as outcomes of experiments rather than first-principles derivations. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations that reduce the result to its own inputs appear in the provided description. The contribution is therefore self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We overcome the key challenge of enabling vision-conditioned teacher supervision by introducing layer-wise KV-cache sharing, which exposes the teacher to the student's multimodal representations without modifying the architecture of either model.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Microsoft COCO Captions: Data Collection and Evaluation Server
URLhttps://arxiv.org/abs/1504.00325. Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018. URLhttps://arxiv.org/abs/1803.05457. Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang,...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Distilling the Knowledge in a Neural Network
URLhttps://arxiv.org/abs/1503.02531. Fushuo Huo, Wenchao Xu, Jingcai Guo, Haozhao Wang, and Song Guo. C2kd: Bridging the modality gap for cross-modal knowledge distillation. InCVPR, 2024. 11 Preprint. Work in Progress Gabriel Ilharco, Marco T ´ulio Ribeiro, Mitchell Wortsman, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task a...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
doi: 10.1109/CVPR52733.2024.00913. URL https://doi.org/10.1109/CVPR52733. 2024.00913. Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? In Anna Korhonen, David Traum, and Llu ´ıs M`arquez (eds.),Proceedings of the 57th Annual Meeting of the Association for Computational Linguistic...
-
[4]
T5gemma 2: Seeing, reading, and understanding longer,
URLhttps://arxiv.org/abs/2512.14856. Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, and Ziwei Liu. Lmms-eval: Reality check on the evaluation of large multimodal models, 2024a. URL https://arxiv.org/ abs/2407.12772. Renrui Zhang, Jiaming Han, Chris Liu, Peng Gao, Aojun...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.