Recognition: 3 theorem links
· Lean TheoremScreening Is Enough
Pith reviewed 2026-05-13 22:13 UTC · model grok-4.3
The pith
Multiscreen replaces softmax attention with a screening step that computes bounded similarities and discards irrelevant keys via an explicit threshold.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Screening computes bounded query-key similarities and applies an explicit threshold to discard irrelevant keys before aggregation, supplying an independently interpretable measure of absolute relevance that standard attention lacks.
What carries the argument
Screening: bounded query-key similarities followed by an explicit threshold that discards irrelevant keys before aggregation.
Load-bearing premise
The explicit threshold can be chosen to discard irrelevant keys without accidentally removing useful information across diverse tasks.
What would settle it
Training runs in which varying the threshold produces sharp performance drops on held-out tasks of the same type would show that no single threshold works reliably.
Figures



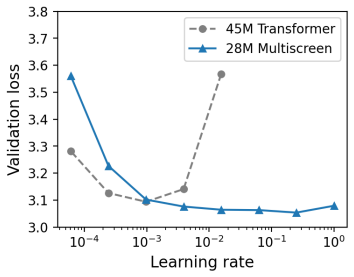



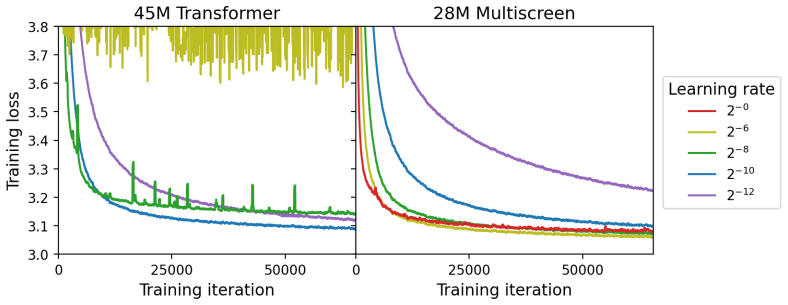


read the original abstract
A core limitation of standard softmax attention is that it does not provide an independently interpretable measure of query--key relevance: attention scores are unbounded, while attention weights are defined only relative to competing keys. Consequently, irrelevant keys cannot be explicitly rejected, and some attention mass is assigned even when no key is genuinely relevant. We introduce Multiscreen, a language-model architecture built around a mechanism we call screening, which enables absolute query--key relevance. Instead of redistributing attention across all keys, screening computes bounded query--key similarities and applies an explicit threshold, discarding irrelevant keys and aggregating the remaining keys without global competition. Across experiments, Multiscreen achieves comparable validation loss with roughly 30\% fewer parameters than a Transformer baseline and remains stable at substantially larger learning rates. It maintains stable long-context perplexity beyond the training context and shows little degradation in retrieval performance as context length increases. Finally, Multiscreen achieves lower full-context forward-pass latency at long context lengths.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Multiscreen, an alternative to standard Transformer attention based on a screening mechanism. Screening computes bounded query-key similarities and applies an explicit threshold to discard irrelevant keys, enabling absolute relevance without global competition in attention weights. The paper reports that this architecture achieves comparable validation loss to a Transformer baseline with roughly 30% fewer parameters, exhibits stability at larger learning rates, maintains long-context perplexity, and has lower latency at long contexts.
Significance. If substantiated, the result would be significant because it directly addresses the lack of absolute relevance in softmax attention by allowing explicit rejection of irrelevant keys. This could lead to more interpretable and efficient models. The reported parameter reduction and training stability are notable strengths, but the preliminary experimental support noted in the review limits the assessed impact at this stage.
major comments (2)
- Abstract: The abstract reports performance gains but provides no details on the experimental setup, baselines used, datasets, or potential limitations, which weakens support for the central claims of comparable validation loss and parameter efficiency.
- Screening mechanism: The explicit threshold applied to bounded query-key similarities lacks explicit justification, sensitivity analysis, or a rule for selection across tasks. This is load-bearing for the claim that screening is sufficient, as hand-tuning could mean the results hold only in regimes where no useful keys are discarded accidentally.
minor comments (1)
- Abstract: The phrase 'across experiments' is vague; specifying the tasks or number of experiments would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and have revised the manuscript to improve clarity and support for the claims.
read point-by-point responses
-
Referee: Abstract: The abstract reports performance gains but provides no details on the experimental setup, baselines used, datasets, or potential limitations, which weakens support for the central claims of comparable validation loss and parameter efficiency.
Authors: We agree that the original abstract omitted important context. The revised abstract now specifies the experimental setup, including pretraining on the C4 dataset, the matched-parameter Transformer baseline, and notes limitations such as the focus on decoder-only language modeling and the preliminary scope of long-context evaluations. revision: yes
-
Referee: Screening mechanism: The explicit threshold applied to bounded query-key similarities lacks explicit justification, sensitivity analysis, or a rule for selection across tasks. This is load-bearing for the claim that screening is sufficient, as hand-tuning could mean the results hold only in regimes where no useful keys are discarded accidentally.
Authors: The threshold is justified by the bounded similarity range of [-1, 1] produced by normalized query-key dot products, with zero serving as the natural cutoff for discarding negative (irrelevant) similarities. The revised manuscript adds a dedicated subsection with sensitivity analysis on the validation set, showing stable loss for thresholds in [-0.1, 0.1], and a selection heuristic based on the median similarity observed in early layers. A full cross-task rule is noted as future work. revision: yes
Circularity Check
No significant circularity; architecture defined independently
full rationale
The paper defines the Multiscreen architecture and screening mechanism directly via bounded query-key similarities plus an explicit threshold (no derivation that reduces to its own fitted outputs or predictions). Experimental claims of comparable loss with 30% fewer parameters and stability at large learning rates are presented as empirical observations, not as quantities forced by construction from the inputs. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The threshold choice is an explicit design parameter whose justification is external to any circular reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- screening threshold
axioms (1)
- domain assumption Compatibility with standard transformer layers
invented entities (1)
-
screening mechanism
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel matches?
matchesMATCHES: this paper passage directly uses, restates, or depends on the cited Recognition theorem or module.
screening computes bounded query–key similarities and applies an explicit threshold, discarding irrelevant keys and aggregating the remaining keys without global competition
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability matches?
matchesMATCHES: this paper passage directly uses, restates, or depends on the cited Recognition theorem or module.
relevance values (∈[0,1])... sets the relevance exactly to zero when sij ≤1−1/r
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
the screening unit can also represent the absence of relevant context
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Informa- tion Processing Systems, 2017
work page 2017
-
[2]
Rae, Anna Potapenko, Siddhant M
Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, Chloe Hillier, and Timothy P. Lillicrap. Compressive transformers for long-range sequence modelling. InInternational Conference on Learning Representations, 2020
work page 2020
-
[3]
Zoology: Measuring and improving recall in efficient language models
Simran Arora, Sabri Eyuboglu, Aman Timalsina, Isys Johnson, Michael Poli, James Zou, Atri Rudra, and Christopher Ré. Zoology: Measuring and improving recall in efficient language models. InInternational Conference on Learning Representations, 2024
work page 2024
-
[4]
Ken Shi and Gerald Penn. Semantic masking in a needle-in-a-haystack test for evaluating large language model long-text capabilities. InProceedings of the First Workshop on Writing Aids at the Crossroads of AI, Cognitive Science and NLP (WRAICOGS 2025), pages 16–23, 2025
work page 2025
- [5]
-
[6]
Selective attention: Enhancing transformer through principled context control
Xuechen Zhang, Xiangyu Chang, Mingchen Li, Amit Roy-Chowdhury, Jiasi Chen, and Samet Oymak. Selective attention: Enhancing transformer through principled context control. In Advances in Neural Information Processing Systems, 2024
work page 2024
-
[7]
André F. T. Martins and Ramón Fernandez Astudillo. From softmax to sparsemax: A sparse model of attention and multi-label classification. InInternational Conference on Machine Learning, 2016
work page 2016
-
[8]
Ben Peters, Vlad Niculae, and André F.T. Martins. Sparse sequence-to-sequence models. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019
work page 2019
-
[9]
Correia, Vlad Niculae, and André F.T
Gonçalo M. Correia, Vlad Niculae, and André F.T. Martins. Adaptively sparse transformers. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019
work page 2019
-
[10]
Native sparse attention: Hardware-aligned and natively trainable sparse attention
Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Yuxing Wei, Lean Wang, Zhiping Xiao, Yuqing Wang, Chong Ruan, Ming Zhang, Wen- feng Liang, and Wangding Zeng. Native sparse attention: Hardware-aligned and natively trainable sparse attention. InProceedings of the 63rd Annual Meeting of the Association for Computation...
work page 2025
-
[11]
Retrievalattention: Accelerating long-context LLM inference via vector retrieval
Di Liu, Meng Chen, Baotong Lu, Huiqiang Jiang, Zhenhua Han, Qianxi Zhang, Qi Chen, Chengruidong Zhang, Bailu Ding, Kai Zhang, Chen Chen, Fan Yang, Yuqing Yang, and Lili Qiu. Retrievalattention: Accelerating long-context LLM inference via vector retrieval. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[12]
Theory, analysis, and best practices for sigmoid self-attention
Jason Ramapuram, Federico Danieli, Eeshan Dhekane, Floris Weers, Dan Busbridge, Pierre Ablin, Tatiana Likhomanenko, Jagrit Digani, Zijin Gu, Amitis Shidani, and Russ Webb. Theory, analysis, and best practices for sigmoid self-attention. InInternational Conference on Learning Representations, 2025
work page 2025
-
[13]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. In First Conference on Language Modeling, 2024
work page 2024
-
[14]
Fu, Tri Dao, Stephen Baccus, Yoshua Bengio, Stefano Ermon, and Christopher Ré
Michael Poli, Stefano Massaroli, Eric Nguyen, Daniel Y . Fu, Tri Dao, Stephen Baccus, Yoshua Bengio, Stefano Ermon, and Christopher Ré. Hyena hierarchy: Towards larger convolutional language models. InInternational Conference on Machine Learning, 2023
work page 2023
-
[15]
Retentive Network: A Successor to Transformer for Large Language Models
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive network: A successor to transformer for large language models.arXiv preprint arXiv:2307.08621, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Samba: Simple hybrid state space models for efficient unlimited context language modeling
Liliang Ren, Yang Liu, Yadong Lu, Yelong Shen, Chen Liang, and Weizhu Chen. Samba: Simple hybrid state space models for efficient unlimited context language modeling. InInternational Conference on Learning Representations, 2025
work page 2025
-
[17]
Train short, test long: Attention with linear biases enables input length extrapolation
Ofir Press, Noah Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. InInternational Conference on Learning Representations, 2022
work page 2022
-
[18]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
work page 2024
-
[19]
Extending Context Window of Large Language Models via Positional Interpolation
Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpolation.arXiv preprint arXiv:2306.15595, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Longrope: Extending llm context window beyond 2 million tokens
Yiran Ding, Li Lyna Zhang, Chengruidong Zhang, Yuanyuan Xu, Ning Shang, Jiahang Xu, Fan Yang, and Mao Yang. Longrope: Extending llm context window beyond 2 million tokens. In International Conference on Machine Learning, 2024. 16
work page 2024
-
[21]
Functional interpo- lation for relative positions improves long context transformers
Shanda Li, Chong You, Guru Guruganesh, Joshua Ainslie, Santiago Ontanon, Manzil Zaheer, Sumit Sanghai, Yiming Yang, Sanjiv Kumar, and Srinadh Bhojanapalli. Functional interpo- lation for relative positions improves long context transformers. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[22]
The impact of positional encoding on length generalization in transformers
Amirhossein Kazemnejad, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Payel Das, and Siva Reddy. The impact of positional encoding on length generalization in transformers. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[23]
Length generalization of causal transformers without position encoding
Jie Wang, Tao Ji, Yuanbin Wu, Hang Yan, Tao Gui, Qi Zhang, Xuan-Jing Huang, and Xiaoling Wang. Length generalization of causal transformers without position encoding. InFindings of the Association for Computational Linguistics: ACL 2024, 2024
work page 2024
-
[24]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173, 2024
work page 2024
-
[25]
Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines.arXiv preprint arXiv:1410.5401, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[26]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, a...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Random-access infinite context length for trans- formers
Amirkeivan Mohtashami and Martin Jaggi. Random-access infinite context length for trans- formers. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[28]
Needle in a haystack - pressure testing llms, 2023
Greg Kamradt. Needle in a haystack - pressure testing llms, 2023. Accessed on Jan 19, 2024
work page 2023
-
[29]
Conditional image generation with pixelcnn decoders
Aaron van den Oord, Nal Kalchbrenner, Oriol Vinyals, Lasse Espeholt, Alex Graves, and Koray Kavukcuoglu. Conditional image generation with pixelcnn decoders. InAdvances in Neural Information Processing Systems, 2016
work page 2016
-
[30]
Language modeling with gated convolutional networks
Yann N Dauphin, Angela Fan, Michael Auli, and David Grangier. Language modeling with gated convolutional networks. InInternational Conference on Machine Learning, 2017
work page 2017
-
[31]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer.arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[32]
Attention is not only a weight: Analyzing transformers with vector norms
Goro Kobayashi, Tatsuki Kuribayashi, Sho Yokoi, and Kentaro Inui. Attention is not only a weight: Analyzing transformers with vector norms. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, 2020
work page 2020
-
[33]
Zhiyu Guo, Hidetaka Kamigaito, and Taro Watanabe. Attention score is not all you need for token importance indicator in kv cache reduction: Value also matters. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024
work page 2024
-
[34]
Stefan Elfwing, Eiji Uchibe, and Kenji Doya. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning.Neural networks, 107:3–11, 2018
work page 2018
-
[35]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
work page 2019
-
[36]
SlimPajama: A 627B token cleaned and deduplicated version of RedPajama
Daria Soboleva, Faisal Al-Khateeb, Robert Myers, Jacob R Steeves, Joel Hestness, and Nolan Dey. SlimPajama: A 627B token cleaned and deduplicated version of RedPajama. https://www.cerebras.net/blog/ slimpajama-a-627b-token-cleaned-and-deduplicated-version-of-redpajama , 2023. 17
work page 2023
-
[37]
Redpajama: an open dataset for training large language models
Maurice Weber, Daniel Fu, Quentin Anthony, Yonatan Oren, Shane Adams, Anton Alexandrov, Xiaozhong Lyu, Huu Nguyen, Xiaozhe Yao, Virginia Adams, Ben Athiwaratkun, Rahul Cha- lamala, Kezhen Chen, Max Ryabinin, Tri Dao, Percy Liang, Christopher Ré, Irina Rish, and Ce Zhang. Redpajama: an open dataset for training large language models. InAdvances in Neural I...
work page 2024
-
[38]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar van der Wal. Pythia: A suite for analyzing large language models across training and scaling. InInternational Conference on Machine Learning, 2023
work page 2023
-
[40]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
work page 2019
-
[41]
Needle in a haystack - pressure testing llms, 2023
Arize AI. Needle in a haystack - pressure testing llms, 2023. Accessed on Jan 19, 2024
work page 2023
-
[42]
Philippe Tillet, H. T. Kung, and David Cox. Triton: an intermediate language and compiler for tiled neural network computations. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, 2019
work page 2019
-
[43]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InNorth American Chapter of the Association for Computational Linguistics, 2019. 18 A Transformer Baseline Configurations We provide detailed architecture configurations for the Transformer baseline models use...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.