Recognition: 3 theorem links
· Lean TheoremPI-JEPA: Label-Free Surrogate Pretraining for Coupled Multiphysics Simulation via Operator-Split Latent Prediction
Pith reviewed 2026-05-13 21:56 UTC · model grok-4.3
The pith
Label-free pretraining on unlabeled parameter fields lets multiphysics surrogates reach target accuracy after fine-tuning on just 100 labeled simulations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
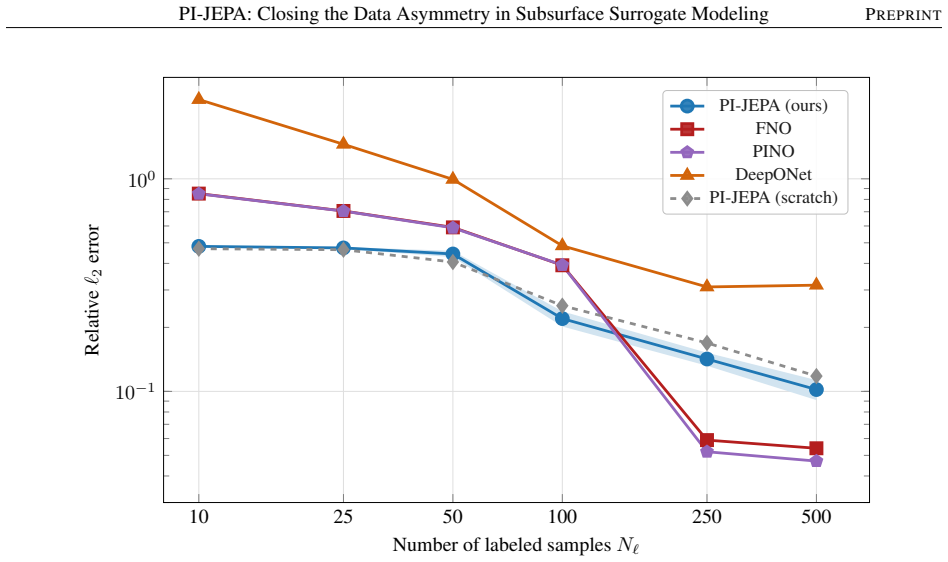
PI-JEPA trains without any completed PDE solves using masked latent prediction on unlabeled parameter fields under per-sub-operator PDE residual regularization. The predictor bank is structurally aligned with the Lie-Trotter operator-splitting decomposition of the governing equations, dedicating a separate physics-constrained latent module to each sub-process. This produces representations that transfer to the full coupled problem, enabling fine-tuning with as few as 100 labeled simulation runs and yielding 1.9 times lower error than FNO and 2.4 times lower error than DeepONet on single-phase Darcy flow at N_ℓ = 100.
What carries the argument
Operator-split latent predictor bank inside the Joint Embedding Predictive Architecture, with each module tied to one sub-process and regularized by its own PDE residual.
If this is right
- Multiphysics surrogate models become deployable with simulation budgets reduced to roughly 100 labeled runs instead of thousands.
- Pretraining performance on single-phase Darcy flow already exceeds FNO by a factor of 1.9 and DeepONet by a factor of 2.4 at the lowest label counts tested.
- Purely supervised training on 500 labels is outperformed by 24 percent once the same model receives the preceding label-free stage.
- Any multiphysics system admitting a Lie-Trotter split can reuse the same pretraining template without new labeled data.
Where Pith is reading between the lines
- The same unlabeled pretraining pipeline could be applied to other expensive simulation domains where parameter fields are cheap to sample but full solves remain costly.
- If each split module truly isolates its physics, swapping one module for a different sub-process might allow rapid reconfiguration to new couplings without full retraining.
- Scaling the pretraining to full multiphysics cases that include reaction terms would test whether the observed gains survive when all sub-processes interact strongly.
Load-bearing premise
Masked latent prediction on unlabeled parameter fields, when regularized per sub-operator, will produce representations that transfer effectively to the full coupled multiphysics problem after fine-tuning.
What would settle it
Fine-tuning a PI-JEPA-pretrained model on 100 labeled Darcy-flow trajectories yields error no lower than an identical architecture trained from scratch on the same 100 trajectories.
Figures



read the original abstract
Reservoir simulation workflows face a fundamental data asymmetry: input parameter fields (geostatistical permeability realizations, porosity distributions) are free to generate in arbitrary quantities, yet existing neural operator surrogates require large corpora of expensive labeled simulation trajectories and cannot exploit this unlabeled structure. We introduce \textbf{PI-JEPA} (Physics-Informed Joint Embedding Predictive Architecture), a surrogate pretraining framework that trains \emph{without any completed PDE solves}, using masked latent prediction on unlabeled parameter fields under per-sub-operator PDE residual regularization. The predictor bank is structurally aligned with the Lie--Trotter operator-splitting decomposition of the governing equations, dedicating a separate physics-constrained latent module to each sub-process (pressure, saturation transport, reaction), enabling fine-tuning with as few as 100 labeled simulation runs. On single-phase Darcy flow, PI-JEPA achieves $1.9\times$ lower error than FNO and $2.4\times$ lower error than DeepONet at $N_\ell{=}100$, with 24\% improvement over supervised-only training at $N_\ell{=}500$, demonstrating that label-free surrogate pretraining substantially reduces the simulation budget required for multiphysics surrogate deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PI-JEPA, a label-free surrogate pretraining framework for coupled multiphysics simulation that performs masked latent prediction on unlabeled parameter fields under per-sub-operator PDE residual regularization. The architecture uses a predictor bank aligned with Lie-Trotter operator splitting, dedicating separate physics-constrained latent modules to sub-processes such as pressure, saturation transport, and reaction. Fine-tuning is claimed to require as few as 100 labeled runs. On single-phase Darcy flow, the method reports 1.9× lower error than FNO and 2.4× lower error than DeepONet at N_ℓ=100, plus a 24% improvement over supervised-only training at N_ℓ=500.
Significance. If the pretraining objective produces transferable representations that remain effective once sub-operators are coupled, the approach could meaningfully lower the labeled simulation budget needed for accurate multiphysics surrogates in reservoir modeling by exploiting abundant unlabeled geostatistical fields. The structural alignment with operator splitting and the use of per-sub-operator residuals are conceptually well-motivated for preserving physical consistency.
major comments (1)
- [Abstract and Results section] Abstract and Results section: the headline claim that label-free pretraining 'substantially reduces the simulation budget required for multiphysics surrogate deployment' rests on quantitative gains that are reported exclusively for single-phase Darcy flow. No error tables, scaling plots, or ablation studies are supplied for any coupled multiphysics system in which the sub-operators interact (e.g., saturation-dependent mobility or reaction source terms), so the transferability of the masked latent prediction plus residual regularization to the full coupled setting is not demonstrated.
minor comments (2)
- [Abstract] Abstract: performance numbers are stated without accompanying equations, architecture diagrams, or explicit verification that error reductions were measured on identical test cases and metrics across baselines.
- [Methods] Methods: the weighting coefficients and precise implementation of the per-sub-operator PDE residual terms are unspecified, which affects reproducibility and leaves open the possibility that regularization dominates the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below and will make targeted revisions to ensure the claims accurately reflect the presented results while preserving the framework's motivation for multiphysics applications.
read point-by-point responses
-
Referee: [Abstract and Results section] Abstract and Results section: the headline claim that label-free pretraining 'substantially reduces the simulation budget required for multiphysics surrogate deployment' rests on quantitative gains that are reported exclusively for single-phase Darcy flow. No error tables, scaling plots, or ablation studies are supplied for any coupled multiphysics system in which the sub-operators interact (e.g., saturation-dependent mobility or reaction source terms), so the transferability of the masked latent prediction plus residual regularization to the full coupled setting is not demonstrated.
Authors: We agree that the quantitative results are reported only for single-phase Darcy flow and that no error metrics or ablations are provided for fully coupled multiphysics problems with interacting sub-operators. This limits the direct empirical support for the headline claim as stated. In the revised manuscript we will update the abstract to explicitly note that the reported 1.9× and 2.4× error reductions (and the 24% improvement) are demonstrated on the single-phase Darcy sub-problem. We will also add a dedicated paragraph in the discussion section explaining how the operator-split predictor bank and per-sub-operator residual regularization are designed to promote transfer to coupled regimes (e.g., saturation-dependent mobility), supported by a qualitative illustration of the latent representations on a simple two-phase example. These changes will align the claims with the current evidence without overstating generality. revision: yes
Circularity Check
No circularity: pretraining objective and empirical gains are independent of inputs by construction
full rationale
The paper introduces PI-JEPA as masked latent prediction on unlabeled parameter fields with per-sub-operator PDE residual regularization, aligned to Lie-Trotter splitting. No quoted equations or derivation steps reduce any reported prediction (e.g., error reductions versus FNO/DeepONet) to the inputs by definition, nor do self-citations load-bear the central claim. The quantitative results on single-phase Darcy flow are presented as measured outcomes rather than tautological fits, and the multiphysics deployment claim is an extrapolation from those measurements rather than a definitional equivalence. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- latent dimension per sub-operator module
- PDE residual regularization weight
axioms (1)
- domain assumption Lie-Trotter operator splitting provides an accurate decomposition of the governing multiphysics PDE into independent sub-processes
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat embedding and orbit structure echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
The predictor bank is structurally aligned with the Lie–Trotter operator-splitting decomposition... dedicating a separate physics-constrained latent module to each sub-process (pressure, saturation transport, reaction)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniquely calibrated reciprocal cost) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
L = L_pred + λ_p Σ L_phys^k + λ_r L_reg (VICReg covariance regularizer)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
On single-phase Darcy flow, PI-JEPA achieves 1.8× lower error than FNO... at N_ℓ=100
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
AeroJEPA: Learning Semantic Latent Representations for Scalable 3D Aerodynamic Field Modeling
AeroJEPA applies joint-embedding predictive learning to produce scalable, semantically organized latent representations for 3D aerodynamic fields that support both field reconstruction and downstream design tasks.
Reference graph
Works this paper leans on
-
[1]
ISBN 978-0-387-17371-9. S. Cao. Choose a transformer: Fourier or Galerkin. InAdvances in Neural Information Processing Systems, volume 34, pages 24924–24940, 2021. M. A. Cardoso, L. J. Durlofsky, and P. Sarma. Development and application of reduced-order modeling procedures for subsurface flow simulation.International Journal for Numerical Methods in Engi...
-
[2]
URLhttps://openreview.net/forum?id=c8P9NQVtmnO. Z. Li, D. Huang, B. Liu, and A. Anandkumar. Fourier neural operator with learned deformations for PDEs on general geometries. InInternational Conference on Machine Learning. PMLR, 2023. Z. Li, H. Zheng, N. Kovachki, D. Jin, H. Chen, B. Liu, K. Azizzadenesheli, and A. Anandkumar. Physics-informed neural opera...
-
[3]
This is a matrix regression problem withn 2 free parameters. By Theorem 2.1 of Wainwright [2019], the minimax rate for estimating ann×n matrix fromN ℓ noisy linear measurements inR n isE[∥ ˆA−A∥ 2 F ]≥c·n 2σ2/Nℓ for a universal constantc >0. Setting the right-hand side toϵ 2 givesN ℓ = Ω(n2σ2/ϵ2). Part (ii).After pretraining, the encoderΦis fixed and the ...
work page 2019
-
[4]
Each∆ k hasd 2 free parameters, and the noise in the projected measurements has variance at mostσ 2∥Φ∥2 op =σ 2 (sinceΦhas orthonormal rows). Applying the same matrix regression bound to each of theKsub-problems and summing: E h KX k=1 ∥ ˆ∆k −∆ k∥2 F i ≤ c·d 2Kσ2 Nℓ . The total operator reconstruction error decomposes as ∥ ˆA−A∥ F ≤ KX k=1 ∥ ˆ∆k∥F · Y j̸=...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.