Recognition: no theorem link
From SWE-ZERO to SWE-HERO: Execution-free to Execution-based Fine-tuning for Software Engineering Agents
Pith reviewed 2026-05-13 21:40 UTC · model grok-4.3
The pith
A two-stage fine-tuning process converts execution-free code reasoning into execution-based engineering performance, letting 32B open models resolve 62 percent of SWE-bench tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By first training on 300k execution-free trajectories to master code semantics and repository-level reasoning, then refining with 13k execution-backed trajectories through an evolutionary strategy, the resulting SWE-HERO models convert semantic intuitions into rigorous engineering workflows, with the 32B variant resolving 62.2 percent of tasks on SWE-bench Verified and 44.1 percent on the multilingual benchmark.
What carries the argument
The evolutionary refinement strategy that transitions execution-free semantic mastery into execution-based engineering behavior using targeted execution feedback.
If this is right
- Open models of 32B parameters can reach competitive resolution rates on repository-level software engineering tasks through staged distillation.
- Training exclusively on Python trajectories still supports strong zero-shot transfer to other programming languages.
- The released trajectory datasets make the method reproducible and allow direct extension by other researchers.
- Avoiding execution during the first training stage lowers the overall compute cost while preserving final performance.
- The two-stage separation shows that semantic understanding can be built before adding execution constraints.
Where Pith is reading between the lines
- The same staged pattern of first building broad understanding then adding execution feedback could apply to agent tasks outside software engineering, such as data analysis or scientific simulation.
- Execution feedback appears most effective once semantic foundations are already present, which may guide data collection priorities in other domains.
- Further increases in the number of execution-based trajectories or use of different base models could test whether the reported performance scales further.
Load-bearing premise
The 300k execution-free and 13k execution-based trajectories distilled from the frontier model contain high-quality examples free of systematic biases that the refinement process can reliably convert into correct engineering actions.
What would settle it
Testing the trained 32B agent on a fresh held-out portion of SWE-bench Verified problems and measuring whether the resolution rate stays at or above 62.2 percent when every edit is strictly verified by execution.
Figures






read the original abstract
We introduce SWE-ZERO to SWE-HERO, a two-stage SFT recipe that achieves state-of-the-art results on SWE-bench by distilling open-weight frontier LLMs. Our pipeline replaces resource-heavy dependencies with an evolutionary refinement strategy: (1) SWE-ZERO utilizes large-scale, execution-free trajectories to master code semantics and repository-level reasoning, and (2) SWE-HERO applies targeted, execution-backed refinement to transition these semantic intuitions into rigorous engineering workflows. Our empirical results set a new benchmark for open-source models of comparable size. We release a dataset of 300k SWE-ZERO and 13k SWE-HERO trajectories distilled from Qwen3-Coder-480B, alongside a suite of agents based on the Qwen2.5-Coder series. Notably, SWE-HERO-32B achieves a 62.2% resolution rate on SWE-bench Verified. Furthermore, despite being trained exclusively on Python, our agents demonstrate robust zero-shot transferability on SWE-bench Multilingual, reaching 44.1% and confirming the paradigm's generalizability across diverse languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a two-stage supervised fine-tuning pipeline called SWE-ZERO to SWE-HERO for software engineering agents. SWE-ZERO distills 300k execution-free trajectories from Qwen3-Coder-480B to instill code semantics and repository-level reasoning, while SWE-HERO applies evolutionary refinement on 13k execution-based trajectories to convert these into reliable engineering workflows. The authors report that the resulting SWE-HERO-32B model reaches 62.2% resolution on SWE-bench Verified and 44.1% zero-shot on SWE-bench Multilingual despite Python-only training data, claiming new state-of-the-art results among open-source models of comparable size. They also release the full set of 300k + 13k trajectories.
Significance. If the results hold after addressing the validation gaps, the work would provide a resource-efficient route to high-performing SE agents by deferring execution costs until the refinement stage. The public release of the 300k SWE-ZERO and 13k SWE-HERO trajectories is a clear strength that supplies the community with large-scale, distilled data for further experimentation. The zero-shot multilingual transfer result further suggests that the learned behaviors may generalize beyond the training language.
major comments (2)
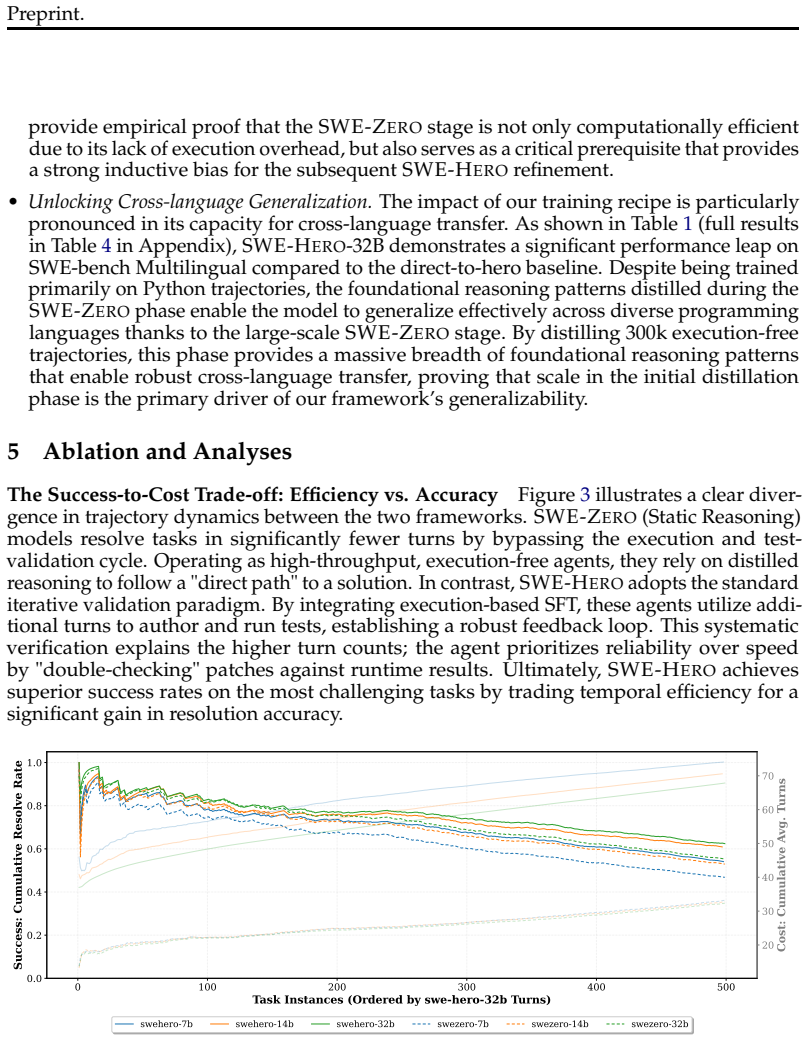
- [§4 (Results)] The headline 62.2% resolution rate on SWE-bench Verified (Abstract and §4) is presented without an ablation that trains a comparable model directly on the 13k execution-based trajectories alone. This comparison is required to isolate whether the SWE-ZERO stage contributes beyond what targeted execution-based SFT can achieve on its own.
- [§3.1 (SWE-ZERO Trajectory Generation)] No quantitative audit or residual-error analysis is reported for the 300k execution-free trajectories generated in the SWE-ZERO stage (§3.1). Because these trajectories are never execution-verified, it remains unclear whether the subsequent evolutionary refinement reliably corrects teacher-model semantic or repository-level mistakes, which is load-bearing for the pipeline's central claim.
minor comments (1)
- [Abstract] The abstract claims 'state-of-the-art results' for open-source models but does not list the exact prior scores or model sizes being surpassed; a one-line reference to the strongest baseline in §4 would improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our two-stage SWE-ZERO to SWE-HERO pipeline. The comments highlight important aspects for strengthening the empirical claims, and we address each point below with commitments to revisions where feasible.
read point-by-point responses
-
Referee: [§4 (Results)] The headline 62.2% resolution rate on SWE-bench Verified (Abstract and §4) is presented without an ablation that trains a comparable model directly on the 13k execution-based trajectories alone. This comparison is required to isolate whether the SWE-ZERO stage contributes beyond what targeted execution-based SFT can achieve on its own.
Authors: We agree that this ablation would strengthen the isolation of the SWE-ZERO stage's contribution. Our design is motivated by the observation that large-scale execution-free trajectories provide foundational semantic and repository-level priors that enable more effective learning from the smaller set of execution-based trajectories; direct SFT on 13k complex trajectories alone risks underfitting due to limited coverage. To address the concern directly, we will add this ablation in the revised manuscript by training a Qwen2.5-Coder-32B baseline solely on the 13k SWE-HERO trajectories and reporting its SWE-bench Verified performance alongside the full pipeline results. revision: yes
-
Referee: [§3.1 (SWE-ZERO Trajectory Generation)] No quantitative audit or residual-error analysis is reported for the 300k execution-free trajectories generated in the SWE-ZERO stage (§3.1). Because these trajectories are never execution-verified, it remains unclear whether the subsequent evolutionary refinement reliably corrects teacher-model semantic or repository-level mistakes, which is load-bearing for the pipeline's central claim.
Authors: We acknowledge the value of a quantitative audit for transparency on the unverified 300k trajectories. A full audit across all 300k is impractical at this scale, but the evolutionary refinement in SWE-HERO is explicitly designed to use execution feedback to detect and correct semantic and repository-level errors from the teacher. In the revision, we will add a sample-based residual-error analysis: we will randomly sample 500 SWE-ZERO trajectories, categorize common error types (semantic misunderstandings, incorrect repository navigation, etc.), and demonstrate via the corresponding refined SWE-HERO trajectories how execution-based evolution resolves a substantial fraction of these issues. revision: partial
Circularity Check
No circularity in empirical distillation pipeline
full rationale
The paper describes a two-stage empirical fine-tuning procedure that generates trajectories from an external frontier model (Qwen3-Coder-480B), applies execution-free then execution-based SFT to smaller Qwen2.5-Coder models, and reports resolution rates on the independent SWE-bench Verified and Multilingual benchmarks. No equations, self-definitional relations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the derivation chain. All performance numbers are produced by standard supervised fine-tuning followed by external evaluation; the pipeline remains falsifiable against held-out test sets and does not reduce any claimed result to a quantity defined by its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Distilled trajectories from Qwen3-Coder-480B provide sufficiently accurate and diverse supervision for both stages
Reference graph
Works this paper leans on
-
[1]
Anthropic . Claude 4 sonnet. https://www.anthropic.com/claude/sonnet, 2025 a . Accessed: 2025-08-31
work page 2025
-
[2]
Anthropic . Introducing claude opus 4.5. https://www.anthropic.com/news/claude-opus-4-5, November 2025 b . Accessed: 2026-03-17
work page 2025
-
[3]
Ibragim Badertdinov, Alexander Golubev, Maksim Nekrashevich, Anton Shevtsov, Simon Karasik, Andrei Andriushchenko, Maria Trofimova, Daria Litvintseva, and Boris Yangel. SWE -rebench: An automated pipeline for task collection and decontaminated evaluation of software engineering agents. In The Thirty-ninth Annual Conference on Neural Information Processing...
work page 2025
-
[4]
Qwen3-coder-next technical report.arXiv preprint arXiv:2603.00729, 2026
Ruisheng Cao, Mouxiang Chen, Jiawei Chen, Zeyu Cui, Yunlong Feng, Binyuan Hui, Yuheng Jing, Kaixin Li, Mingze Li, Junyang Lin, Zeyao Ma, Kashun Shum, Xuwu Wang, Jinxi Wei, Jiaxi Yang, Jiajun Zhang, Lei Zhang, Zongmeng Zhang, Wenting Zhao, and Fan Zhou. Qwen3-coder-next technical report, 2026. URL https://arxiv.org/abs/2603.00729
-
[5]
Skyrl-agent: Efficient rl training for multi-turn llm agent.arXiv preprint arXiv:2511.16108, 2025
Shiyi Cao, Dacheng Li, Fangzhou Zhao, Shuo Yuan, Sumanth R. Hegde, Connor Chen, Charlie Ruan, Tyler Griggs, Shu Liu, Eric Tang, Richard Liaw, Philipp Moritz, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. Skyrl-agent: Efficient rl training for multi-turn llm agent, 2025. URL https://arxiv.org/abs/2511.16108
-
[6]
Cwm: An open-weights llm for research on code generation with world models
Jade Copet, Quentin Carbonneaux, Gal Cohen, Jonas Gehring, Jacob Kahn, Jannik Kossen, Felix Kreuk, Emily McMilin, Michel Meyer, Yuxiang Wei, et al. Cwm: An open-weights llm for research on code generation with world models. arXiv preprint arXiv:2510.02387, 2025
-
[7]
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenhao Xu, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Erhang Li, Fangqi Zhou, Fangyun Lin, Fucong Dai, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Ha...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
davinci-env: Open swe environment synthesis at scale, 2026
Dayuan Fu, Shenyu Wu, Yunze Wu, Zerui Peng, Yaxing Huang, Jie Sun, Ji Zeng, Mohan Jiang, Lin Zhang, Yukun Li, Jiarui Hu, Liming Liu, Jinlong Hou, and Pengfei Liu. davinci-env: Open swe environment synthesis at scale, 2026. URL https://arxiv.org/abs/2603.13023
-
[9]
GLM-5: from Vibe Coding to Agentic Engineering
GLM-5-Team, :, Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, Chenzheng Zhu, Congfeng Yin, Cunxiang Wang, Gengzheng Pan, Hao Zeng, Haoke Zhang, Haoran Wang, Huilong Chen, Jiajie Zhang, Jian Jiao, Jiaqi Guo, Jingsen Wang, Jingzhao Du, Jinzhu Wu, Kedong Wang, Lei Li, Lin Fan, Lucen Zho...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Training long-context, multi-turn software engineering agents with reinforcement learning, 2025
Alexander Golubev, Maria Trofimova, Sergei Polezhaev, Ibragim Badertdinov, Maksim Nekrashevich, Anton Shevtsov, Simon Karasik, Sergey Abramov, Andrei Andriushchenko, Filipp Fisin, Sergei Skvortsov, and Boris Yangel. Training long-context, multi-turn software engineering agents with reinforcement learning, 2025. URL https://arxiv.org/abs/2508.03501
-
[11]
Gemini 3 flash: frontier intelligence built for speed
Google . Gemini 3 flash: frontier intelligence built for speed. https://blog.google/products-and-platforms/products/gemini/gemini-3-flash/, December 2025
work page 2025
-
[12]
Lianghong Guo, Yanlin Wang, Caihua Li, Wei Tao, Pengyu Yang, Jiachi Chen, Haoyu Song, Duyu Tang, and Zibin Zheng. Swe-factory: Your automated factory for issue resolution training data and evaluation benchmarks, 2026. URL https://arxiv.org/abs/2506.10954
-
[13]
SWE-Swiss : A multi-task fine-tuning and RL recipe for high-performance issue resolution
Zhenyu He, Qingping Yang, Wei Sheng, Xiaojian Zhong, Kechi Zhang, Chenxin An, Wenlei Shi, Tianle Cai, Di He, Jiaze Chen, and Jingjing Xu. SWE-Swiss : A multi-task fine-tuning and RL recipe for high-performance issue resolution. Notion Blog / GitHub Repository, 2025. URL https://github.com/zhenyuhe00/SWE-Swiss. Accessed: 2026-03-17
work page 2025
-
[14]
Qwen2.5-Coder Technical Report
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, Kai Dang, Yang Fan, Yichang Zhang, An Yang, Rui Men, Fei Huang, Bo Zheng, Yibo Miao, Shanghaoran Quan, Yunlong Feng, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. Qwen2.5-coder technical report, 2024. URL https://arxiv.org/a...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
R2e-gym: Procedural environment generation and hybrid verifiers for scaling open-weights SWE agents
Naman Jain, Jaskirat Singh, Manish Shetty, Tianjun Zhang, Liang Zheng, Koushik Sen, and Ion Stoica. R2e-gym: Procedural environment generation and hybrid verifiers for scaling open-weights SWE agents. In Second Conference on Language Modeling, 2025. URL https://openreview.net/forum?id=7evvwwdo3z
work page 2025
-
[16]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE -bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=VTF8yNQM66
work page 2024
-
[17]
mini-swe-agent-plus: The 100-line AI agent that solves GitHub issues with text-edit tool
Kwai-Klear . mini-swe-agent-plus: The 100-line AI agent that solves GitHub issues with text-edit tool. https://github.com/Kwai-Klear/mini-swe-agent-plus, 2025. GitHub repository
work page 2025
-
[18]
M. Luo, N. Jain, J. Singh, S. Tan, A. Patel, Q. Wu, A. Ariyak, C. Cai, T. Venkat, S. Zhu, B. Athiwaratkun, M. Roongta, C. Zhang, L. E. Li, R. A. Popa, K. Sen, and I. Stoica. DeepSWE : Training a fully open-sourced, state-of-the-art coding agent by scaling RL . https://www.together.ai/blog/deepswe, Jul. 2025. Together AI Blog post. Accessed: 2025-12-22
work page 2025
-
[19]
Swe-gpt: A process-centric language model for automated software improvement
Yingwei Ma, Rongyu Cao, Yongchang Cao, Yue Zhang, Jue Chen, Yibo Liu, Yuchen Liu, Binhua Li, Fei Huang, and Yongbin Li. Swe-gpt: A process-centric language model for automated software improvement. Proceedings of the ACM on Software Engineering, 2 0 (ISSTA): 0 2362--2383, 2025
work page 2025
-
[20]
Minimax m2.5: Built for real-world productivity
MiniMax . Minimax m2.5: Built for real-world productivity. https://www.minimax.io/news/minimax-m25, February 2026. Accessed: 2026-03-17
work page 2026
-
[21]
OpenAI . Introducing GPT-5.2 . https://openai.com/index/introducing-gpt-5-2/, December 2025
work page 2025
-
[22]
Training software engineering agents and verifiers with SWE -gym
Jiayi Pan, Xingyao Wang, Graham Neubig, Navdeep Jaitly, Heng Ji, Alane Suhr, and Yizhe Zhang. Training software engineering agents and verifiers with SWE -gym. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=Cq1BNvHx74
work page 2025
-
[23]
YaRN: Efficient Context Window Extension of Large Language Models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. Yarn: Efficient context window extension of large language models, 2026. URL https://arxiv.org/abs/2309.00071
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [24]
-
[25]
Qwen3.5 : Towards native multimodal agents, February 2026
Qwen Team . Qwen3.5 : Towards native multimodal agents, February 2026. URL https://qwen.ai/blog?id=qwen3.5. Accessed: 2026-03-17
work page 2026
-
[26]
Sera: Soft-verified efficient repository agents, 2026
Ethan Shen, Danny Tormoen, Saurabh Shah, Ali Farhadi, and Tim Dettmers. Sera: Soft-verified efficient repository agents, 2026. URL https://arxiv.org/abs/2601.20789
-
[27]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. R1-searcher: Incentivizing the search capability in llms via reinforcement learning, 2025. URL https://arxiv.org/abs/2503.05592
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Huatong Song, Lisheng Huang, Shuang Sun, Jinhao Jiang, Ran Le, Daixuan Cheng, Guoxin Chen, Yiwen Hu, Zongchao Chen, Yiming Jia, Wayne Xin Zhao, Yang Song, Tao Zhang, and Ji-Rong Wen. Swe-master: Unleashing the potential of software engineering agents via post-training, 2026. URL https://arxiv.org/abs/2602.03411
-
[29]
Bugpilot: Complex bug generation for efficient learning of swe skills, 2025
Atharv Sonwane, Isadora White, Hyunji Lee, Matheus Pereira, Lucas Caccia, Minseon Kim, Zhengyan Shi, Chinmay Singh, Alessandro Sordoni, Marc-Alexandre Côté, and Xingdi Yuan. Bugpilot: Complex bug generation for efficient learning of swe skills, 2025. URL https://arxiv.org/abs/2510.19898
-
[30]
Swe-world: Building software engineering agents in docker-free environments, 2026
Shuang Sun, Huatong Song, Lisheng Huang, Jinhao Jiang, Ran Le, Zhihao Lv, Zongchao Chen, Yiwen Hu, Wenyang Luo, Wayne Xin Zhao, Yang Song, Hongteng Xu, Tao Zhang, and Ji-Rong Wen. Swe-world: Building software engineering agents in docker-free environments, 2026. URL https://arxiv.org/abs/2602.03419
-
[31]
Swe-lego: Pushing the limits of supervised fine-tuning for software issue resolving, 2026
Chaofan Tao, Jierun Chen, Yuxin Jiang, Kaiqi Kou, Shaowei Wang, Ruoyu Wang, Xiaohui Li, Sidi Yang, Yiming Du, Jianbo Dai, Zhiming Mao, Xinyu Wang, Lifeng Shang, and Haoli Bai. Swe-lego: Pushing the limits of supervised fine-tuning for software issue resolving, 2026. URL https://arxiv.org/abs/2601.01426
-
[32]
MiMo-V2-Flash Technical Report
Core Team, Bangjun Xiao, Bingquan Xia, Bo Yang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang Wang, Gang Xie, Hailin Zhang, Hanglong Lv, Hanyu Li, Heyu Chen, Hongshen Xu, Houbin Zhang, Huaqiu Liu, Jiangshan Duo, Jianyu Wei, Jiebao Xiao, Jinhao Dong, Jun Shi, Junhao Hu, Kainan Bao, Kang Zhou, Lei Li, Liang Zhao, Linghao Zhang,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, S. H. Cai, Yuan Cao, Y. Charles, H. S. Che, Cheng Chen, Guanduo Chen, Huarong Chen, Jia Chen, Jiahao Chen, Jianlong Chen, Jun Chen, Kefan Chen, Liang Chen, Ruijue Chen, Xinhao Chen, Yanru Chen, Yanxu Chen, Yicun Chen, Yimin Chen, Yingjiang Chen, Yuankun Chen, Yujie Chen, Yutian Chen, Zhirong Chen, Ziwei Chen...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Kimi Team, Yifan Bai, Yiping Bao, Y. Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Hao Ding, Mengnan Dong, Angang Du, Chenzhuang Du, Dikang Du, Yulun Du, Yu Fan, Yichen Feng, Kelin Fu, Bofei Gao, Chenxiao Gao, Hongcheng Gao, Peizhong Ga...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
SWE -dev: Building software engineering agents with training and inference scaling
Haoran Wang, Zhenyu Hou, Yao Wei, Jie Tang, and Yuxiao Dong. SWE -dev: Building software engineering agents with training and inference scaling. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Findings of the Association for Computational Linguistics: ACL 2025, pp.\ 3742--3761, Vienna, Austria, July 2025 a . Associat...
-
[36]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. Openhands: An open platform for AI soft...
work page 2025
-
[37]
Demystifying llm-based software engineering agents
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. Demystifying llm-based software engineering agents. Proc. ACM Softw. Eng., 2 0 (FSE), June 2025. doi:10.1145/3715754. URL https://doi.org/10.1145/3715754
-
[38]
SWE -fixer: Training open-source LLM s for effective and efficient G it H ub issue resolution
Chengxing Xie, Bowen Li, Chang Gao, He Du, Wai Lam, Difan Zou, and Kai Chen. SWE -fixer: Training open-source LLM s for effective and efficient G it H ub issue resolution. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Findings of the Association for Computational Linguistics: ACL 2025, pp.\ 1123--1139, Vienna, Aust...
-
[39]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
SWE -agent: Agent-computer interfaces enable automated software engineering
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R Narasimhan, and Ofir Press. SWE -agent: Agent-computer interfaces enable automated software engineering. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=mXpq6ut8J3
work page 2024
-
[41]
SWE -smith: Scaling data for software engineering agents
John Yang, Kilian Lieret, Carlos E Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. SWE -smith: Scaling data for software engineering agents. In The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025 b . URL https://openreview.net/forum...
work page 2025
-
[42]
Kimi-dev: Agentless training as skill prior for swe-agents, 2025 c
Zonghan Yang, Shengjie Wang, Kelin Fu, Wenyang He, Weimin Xiong, Yibo Liu, Yibo Miao, Bofei Gao, Yejie Wang, Yingwei Ma, Yanhao Li, Yue Liu, Zhenxing Hu, Kaitai Zhang, Shuyi Wang, Huarong Chen, Flood Sung, Yang Liu, Yang Gao, Zhilin Yang, and Tianyu Liu. Kimi-dev: Agentless training as skill prior for swe-agents, 2025 c . URL https://arxiv.org/abs/2509.23045
-
[43]
davinci-dev: Agent-native mid-training for software engineering, 2026
Ji Zeng, Dayuan Fu, Tiantian Mi, Yumin Zhuang, Yaxing Huang, Xuefeng Li, Lyumanshan Ye, Muhang Xie, Qishuo Hua, Zhen Huang, Mohan Jiang, Hanning Wang, Jifan Lin, Yang Xiao, Jie Sun, Yunze Wu, and Pengfei Liu. davinci-dev: Agent-native mid-training for software engineering, 2026. URL https://arxiv.org/abs/2601.18418
-
[44]
Skywork-swe: Unveiling data scaling laws for software engineering in llms, 2025
Liang Zeng, Yongcong Li, Yuzhen Xiao, Changshi Li, Chris Yuhao Liu, Rui Yan, Tianwen Wei, Jujie He, Xuchen Song, Yang Liu, and Yahui Zhou. Skywork-swe: Unveiling data scaling laws for software engineering in llms, 2025. URL https://arxiv.org/abs/2506.19290
-
[45]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.