Recognition: 2 theorem links
· Lean TheoremOSCAR: Orchestrated Self-verification and Cross-path Refinement
Pith reviewed 2026-05-13 21:41 UTC · model grok-4.3
The pith
Diffusion language models localize and correct their own hallucinations by measuring uncertainty across parallel denoising paths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
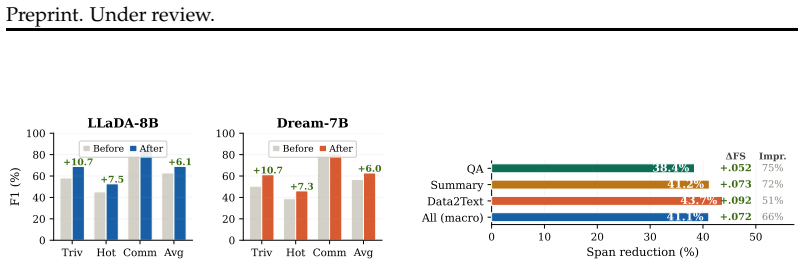
OSCAR operationalizes commitment uncertainty localization by running N parallel denoising chains with randomized reveal orders, computing cross-chain Shannon entropy to detect high-uncertainty positions before factually unreliable commitments propagate into self-consistent but incorrect outputs, and performing targeted remasking conditioned on retrieved evidence. This training-free process enhances generation quality by significantly reducing hallucinated content and improving factual accuracy on TriviaQA, HotpotQA, RAGTruth, and CommonsenseQA with LLaDA-8B and Dream-7B, while its native entropy-based uncertainty signal surpasses that of specialized trained detectors.
What carries the argument
Cross-chain Shannon entropy computed over parallel denoising trajectories with randomized reveal orders, used to localize commitment uncertainty for targeted remasking.
If this is right
- Localization and correction steps each add measurable quality gains that combine constructively.
- Uncertainty-guided remasking leads to more effective use of retrieved evidence during regeneration.
- The native entropy signal detects uncertainty more reliably than externally trained hallucination detectors.
- Quality improvements remain stable when the number of parallel chains is varied across 4, 8, and 16.
Where Pith is reading between the lines
- The same cross-path entropy idea could be tested on diffusion models fine-tuned for tasks beyond question answering to check whether the uncertainty signal remains useful.
- If the localization step works without evidence, diffusion models might need less external retrieval for basic factual consistency.
- Autoregressive models lack an equivalent native cross-chain signal, so the method highlights a structural difference in how the two model families expose uncertainty during generation.
Load-bearing premise
High cross-chain entropy on randomized reveal orders reliably identifies token positions where factually unreliable commitments are about to propagate into self-consistent but incorrect outputs.
What would settle it
A controlled test in which high-entropy positions are identified but remasking them produces no measurable drop in hallucination rate or rise in factual accuracy on the same prompts.
Figures



read the original abstract
Diffusion language models (DLMs) expose their denoising trajectories, offering a natural handle for inference-time control; accordingly, an ideal hallucination mitigation framework should intervene during generation using this model-native signal rather than relying on an externally trained hallucination classifier. Toward this, we formulate commitment uncertainty localization: given a denoising trajectory, identify token positions whose cross-chain entropy exceeds an unsupervised threshold before factually unreliable commitments propagate into self-consistent but incorrect outputs. We introduce a suite of trajectory-level assessments, including a cross-chain divergence-at-hallucination (CDH) metric, for principled comparison of localization methods. We also introduce OSCAR, a training-free inference-time framework operationalizing this formulation. OSCAR runs N parallel denoising chains with randomized reveal orders, computes cross-chain Shannon entropy to detect high-uncertainty positions, and then performs targeted remasking conditioned on retrieved evidence. Ablations confirm that localization and correction contribute complementary gains, robust across N in {4, 8, 16}. On TriviaQA, HotpotQA, RAGTruth, and CommonsenseQA using LLaDA-8B and Dream-7B, OSCAR enhances generation quality by significantly reducing hallucinated content and improving factual accuracy through uncertainty-guided remasking, which also facilitates more effective integration of retrieved evidence. Its native entropy-based uncertainty signal surpasses that of specialized trained detectors, highlighting an inherent capacity of diffusion language models to identify factual uncertainty that is not present in the sequential token commitment structure of autoregressive models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OSCAR, a training-free inference-time framework for diffusion language models. It runs N parallel denoising chains with randomized reveal orders, computes cross-chain Shannon entropy to localize high-uncertainty token positions before incorrect commitments propagate, and performs targeted remasking conditioned on retrieved evidence. The central claims are that this reduces hallucinated content and improves factual accuracy on TriviaQA, HotpotQA, RAGTruth, and CommonsenseQA (using LLaDA-8B and Dream-7B), that localization and correction contribute complementary gains, and that the native entropy signal surpasses specialized trained detectors.
Significance. If the entropy-to-factual-unreliability mapping holds, OSCAR would establish that diffusion language models have an inherent, training-free capacity to surface factual uncertainty via cross-chain trajectories, offering a native alternative to external classifiers and improving evidence integration in RAG settings. The training-free nature and use of model-native signals are clear strengths.
major comments (2)
- [Abstract] Abstract: the claim of 'significantly reducing hallucinated content and improving factual accuracy' is load-bearing yet unsupported by any quantitative results, error bars, threshold values, or CDH metric scores; without these, the magnitude of improvement and the assertion that the native signal surpasses trained detectors cannot be evaluated.
- [Formulation of commitment uncertainty localization] Formulation of commitment uncertainty localization and OSCAR description: the central assumption that high cross-chain entropy specifically flags factually unreliable token commitments (rather than syntactic ambiguity or non-factual uncertainty) lacks direct validation such as precision/recall of high-entropy positions against ground-truth hallucinated tokens; if this mapping does not hold, the superiority claim over trained detectors and the rationale for uncertainty-guided remasking are undermined.
minor comments (2)
- [Ablations] Ablations section: the statement that results are 'robust across N in {4, 8, 16}' should report the per-N performance deltas or standard deviations to allow readers to assess sensitivity.
- [Trajectory-level assessments] The cross-chain divergence-at-hallucination (CDH) metric is introduced as a key evaluation tool but would benefit from an explicit equation or pseudocode definition in the main text rather than only in supplementary material.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We provide detailed responses to each major comment and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'significantly reducing hallucinated content and improving factual accuracy' is load-bearing yet unsupported by any quantitative results, error bars, threshold values, or CDH metric scores; without these, the magnitude of improvement and the assertion that the native signal surpasses trained detectors cannot be evaluated.
Authors: We agree that the abstract should include quantitative support for its claims. In the revised manuscript we have added the key experimental results, including the magnitude of hallucination reductions and factual accuracy gains across the four datasets, error bars from multiple runs, the entropy threshold values employed, and the CDH scores showing superiority over trained detectors. These metrics were already reported in the experimental section and are now summarized in the abstract. revision: yes
-
Referee: [Formulation of commitment uncertainty localization] Formulation of commitment uncertainty localization and OSCAR description: the central assumption that high cross-chain entropy specifically flags factually unreliable token commitments (rather than syntactic ambiguity or non-factual uncertainty) lacks direct validation such as precision/recall of high-entropy positions against ground-truth hallucinated tokens; if this mapping does not hold, the superiority claim over trained detectors and the rationale for uncertainty-guided remasking are undermined.
Authors: We acknowledge the desirability of token-level precision/recall validation. However, the QA datasets used do not contain ground-truth token-level hallucination annotations, rendering such metrics infeasible without new labeling. We instead validate the mapping via the CDH metric, which directly quantifies cross-chain divergence at hallucination points in the final output, together with end-to-end factual accuracy gains and ablations showing complementary benefits from localization and remasking. The native entropy signal is shown to outperform trained detectors under the CDH evaluation. We have expanded the discussion section in the revision to clarify the distinction from syntactic ambiguity and to present additional supporting examples and analysis. revision: partial
Circularity Check
No significant circularity; training-free unsupervised procedure
full rationale
The paper presents OSCAR as a training-free inference-time method that runs parallel denoising chains, computes cross-chain Shannon entropy, applies an unsupervised threshold for localization, and performs evidence-conditioned remasking. No equations reduce the claimed hallucination reduction or accuracy gains to a fitted parameter defined by the target result. The CDH metric is introduced as an evaluation tool for comparing localization methods rather than a self-referential input. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing manner that collapses the derivation to its inputs by construction. The central claim rests on the empirical behavior of diffusion trajectories on external benchmarks (TriviaQA, HotpotQA, etc.) and remains self-contained.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of parallel chains N
- entropy threshold
axioms (1)
- domain assumption High cross-chain Shannon entropy indicates positions where factually unreliable commitments will propagate
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe formulate commitment uncertainty localization: given a denoising trajectory, identify token positions whose cross-chain entropy exceeds an unsupervised threshold
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearCross-chain Shannon entropy H×,i = −∑v ˆpi(v) log ˆpi(v)
Reference graph
Works this paper leans on
-
[1]
URLhttp://arxiv.org/abs/2402.03744. arXiv:2402.03744 [cs]. Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, June 2024. ISSN 1476-4687. doi: 10.1038/s41586-024-07421-0. URL https://www.nature.com/articles/ s41586-024-07421-0. Gautier Izacard, M...
-
[2]
URLhttps://openreview.net/forum?id=SKW10XJlAI. Andrey Malinin and Mark Gales. Uncertainty Estimation in Autoregressive Structured Prediction, February 2021. URL http://arxiv.org/abs/2002.07650. arXiv:2002.07650 [stat]. Potsawee Manakul, Ada Wang, and Mark J.F. Gales. SelfCheckGPT: Zero-Resource Black- Box Hallucination Detection for Generative Large Langu...
-
[3]
URLhttp://arxiv.org/abs/2603.16459. arXiv:2603.16459 [cs]. Jie Ren, Jiaming Luo, Yao Zhao, Kundan Krishna, Mohammad Saleh, Balaji Lakshmi- narayanan, and Peter J. Liu. Out-of-Distribution Detection and Selective Generation for Conditional Language Models, March 2023. URL http://arxiv.org/abs/2209.15558. arXiv:2209.15558 [cs]. Shirin Shoushtari, Yi Wang, X...
-
[4]
Association for Computational Linguistics. doi: 10.18653/v1/N19-1421. URL https://aclanthology.org/N19-1421/. S. M. Towhidul Islam Tonmoy, S. M. Mehedi Zaman, Vinija Jain, Anku Rani, Vipula Rawte, Aman Chadha, and Amitava Das. A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models, January 2024. URL http://arxiv.org/abs/240...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.